

正解率は20%未満、GPT-4V/Geminiは漫画が読めない!初のオープンソース画像シーケンスベンチマーク

OpenAI の GPT-4V と Google の Gemini マルチモーダル大規模言語モデルは、産業界と学界から幅広い注目を集めています。これらのモデルは、複数のドメインにおけるビデオの深い理解を実証し、さまざまな観点からその可能性を実証します。これらの進歩は、汎用人工知能 (AGI) に向けた重要な一歩として広く認識されています。
しかし、GPT-4V が漫画の登場人物の行動さえ読み間違える可能性があると言ったら、聞いてみましょう: Yuanfang さん、どう思いますか?
このミニ コミック シリーズを見てみましょう:
 写真
写真
生物学的世界の最高の知性、つまり人間、つまり読者にそれを説明するように尋ねたら、おそらく次のように答えるでしょう:
 #写真
#写真
それでは見てみましょう ほら、機械界の最高知能、つまり GPT-4V がこのミニ漫画シリーズを見たら、このように説明するでしょうか?
 画像
画像
 写真
写真
 写真
写真
 写真
写真
 写真
写真
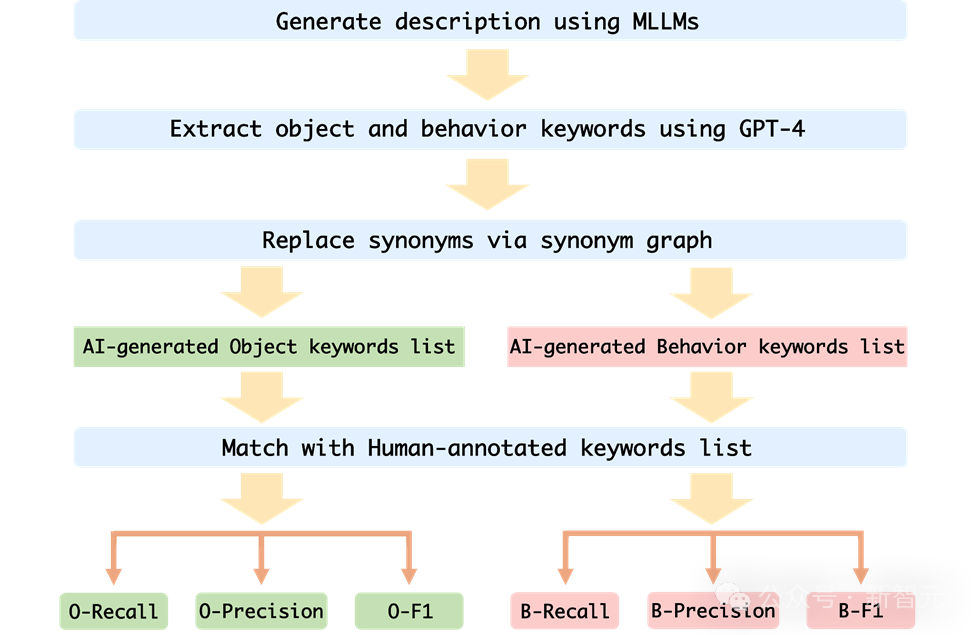
各 MLLM のパフォーマンスを自動的に評価するために、作成者は GPT-4 補助テスト方法を使用して評価します。
 写真
写真
1作成者は、画像シーケンスとプロンプト ワードを MLLM への入力として受け取り、対応する画像シーケンスに対応する説明を生成します;
2. GPT-4 に、AI が生成した画像内のオブジェクトと動作のキーワードを抽出するようリクエストします。 description;
3. AI が生成した物体キーワード リストと AI が生成した行動キーワード リストの 2 つのキーワード リストを取得します;
4. AI が生成した物体キーワード リストと行動キーワード リストを計算しますAIと人物 アノテーション付きキーワードテーブルの再現率、適合率、F1インデックス。
評価結果
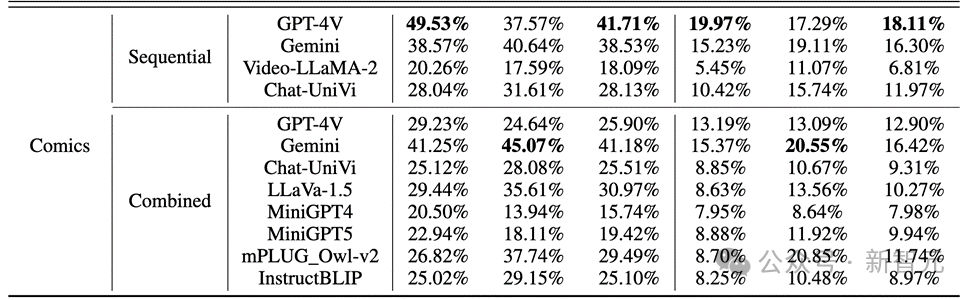
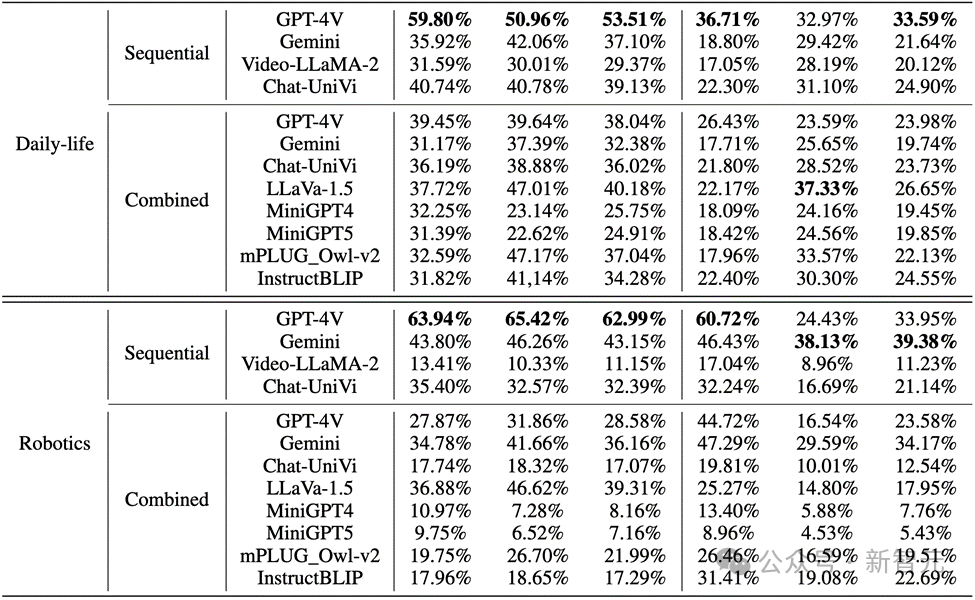
著者は、Mementos 上のシーケンス画像推論における MLLM のパフォーマンスを評価し、GPT4V や Gemini を含む 9 つの最新の MLLM で実験を行いました。
MLLM は、連続画像に対する MLLM の推論能力を評価するために、画像シーケンス内で発生するイベントを記述するように求められます。
その結果、以下の図に示すように、コミック データ セット内のキャラクターの動作に対する GPT-4V と Gemini の精度は 20% 未満であることがわかりました。
 #写真
#写真
 図
図
##1. 物体と幻覚行動との相互作用
この研究では、不正確な物体認識がその後の不正確な行動認識につながるという仮説を立てました。定量的分析とケーススタディは、物体の幻覚がある程度の幻覚行動を引き起こす可能性があることを示しています。たとえば、MLLM がシーンを誤ってテニス コートと認識した場合、イメージ シーケンスにはその動作が存在しないにもかかわらず、テニスをしているキャラクターが描写される可能性があります。
2. 幻覚行動に対する共起の影響
MLLM は、画像シーケンス推論で一般的な行動の組み合わせを生成する傾向があります。幻覚症状の問題を悪化させる。たとえば、ロボット工学ドメインからの画像を処理する場合、MLLM は、実際の動作が「引き出しの側面を掴む」ものであっても、ロボット アームが「ハンドルを掴んだ」後に引き出しを引っ張って開けると誤って説明する可能性があります。
3. 行動錯覚の雪だるま効果
画像シーケンスが進むにつれて、エラーが徐々に蓄積または強化されることがあります。これは雪だるま効果と呼ばれます。 。画像シーケンス推論では、エラーが早期に発生すると、これらのエラーがシーケンス内で蓄積および増幅され、オブジェクトおよびアクションの認識精度が低下する可能性があります。
例
写真
From As上の図からわかるように、MLLM が失敗する理由には、物体幻覚、物体幻覚と行動幻覚の相関関係、および同時発生する行動が含まれます。
たとえば、MLLM は、「テニスコート」という物体幻覚を経験した後、「テニスラケットを持っている」という行動的幻覚 (物体幻覚と行動的幻覚との相関関係) と「テニスをしているように見える」という共通の感覚を示しました。 「現在の行動。
 #写真
#写真
#写真
#ロボット アームの上記の一連の画像表示では、ロボット アームは次の位置に達します。ハンドルの隣では、MLLM はロボット アームがハンドルを握ったと誤って信じており、MLLM が画像シーケンス推論で一般的な行動の組み合わせを生成し、それによって幻覚を引き起こすことが証明されました。
写真
上記のケースでは、古いマスターが犬を抱いていません。MLLM エラーです。犬の散歩の際には犬をリードでつなぐことが義務付けられており、「犬の棒高跳び」は「噴水を作っている」と認識されている。
エラーの多さは、MLLM がコミック分野に不慣れであることを反映しています。2 次元アニメーションの分野では、MLLM は大幅な最適化と事前トレーニングを必要とする可能性があります。
付録では、著者が主要カテゴリごとに失敗事例を詳細に表示し、詳細な分析を行っています。
概要
近年、マルチモーダル大規模言語モデルは、さまざまな視覚言語タスクの処理において優れた機能を実証してきました。
GPT-4V や Gemini などのこれらのモデルは、画像に関連するテキストを理解して生成することができ、人工知能技術の開発を大きく促進します。
ただし、既存の MLLM ベンチマークは主に単一の静止画像に基づく推論に焦点を当てており、変化する世界を理解するには画像シーケンスからの推論が重要です。 。
この課題に対処するために、研究者らは、シーケンス画像推論における MLLM の機能を評価するための新しいベンチマーク「Mementos」を提案しました。
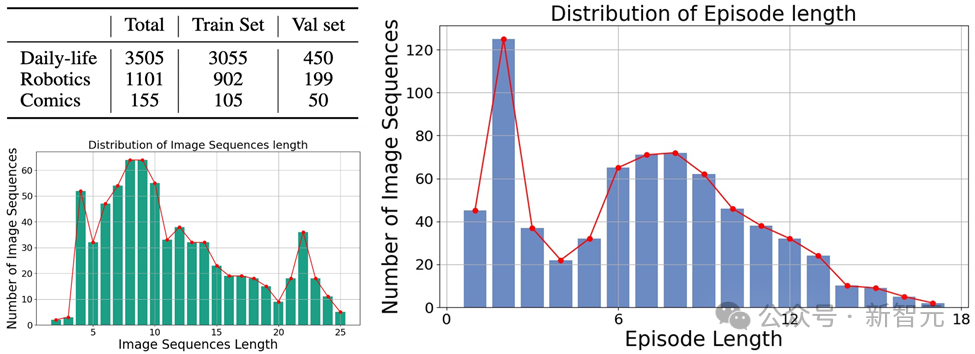
Mementos には、さまざまな長さの 4761 個の多様な画像シーケンスが含まれています。さらに、研究チームはMLLMの推論性能を評価するためにGPT-4補助手法も採用しました。
Mementos 上の 9 つの最新の MLLM (GPT-4V および Gemini を含む) の慎重な評価を通じて、この研究では、特定の画像シーケンスの動的情報を正確に記述するためにこれらのモデルが存在することがわかりました。 、多くの場合、物体とその動作の幻覚や誤った表現が生じます。
定量分析と事例研究により、MLLM におけるシーケンス画像推論に影響を与える 3 つの重要な要素が特定されます:
1. オブジェクトと行動の錯覚間の相関関係;
2. 同時発生する行動の影響;
3. 幻覚行動の累積的な影響。
この発見は、動的な視覚情報を処理するMLLMの能力を理解し、改善する上で非常に重要です。 Mementos ベンチマークは、現在の MLLM の限界を明らかにするだけでなく、将来の研究と改善の方向性も示します。
人工知能テクノロジーの急速な発展に伴い、マルチモーダル理解の分野における MLLM の応用は、より広範囲かつ詳細なものになるでしょう。 Mementos ベンチマークの導入は、この分野の研究を促進するだけでなく、これらの高度な AI システムが複雑で常に変化する世界をどのように処理し、理解するかを理解し、改善するための新しい視点を提供します。
参考資料:
https://github.com/umd-huanglab/Mementos
以上が正解率は20%未満、GPT-4V/Geminiは漫画が読めない!初のオープンソース画像シーケンスベンチマークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 トークン化を 1 つの記事で理解しましょう!
Apr 12, 2024 pm 02:31 PM
トークン化を 1 つの記事で理解しましょう!
Apr 12, 2024 pm 02:31 PM
言語モデルは、通常は文字列の形式であるテキストについて推論しますが、モデルへの入力は数値のみであるため、テキストを数値形式に変換する必要があります。トークン化は自然言語処理の基本タスクであり、特定のニーズに応じて、連続するテキスト シーケンス (文、段落など) を文字シーケンス (単語、フレーズ、文字、句読点など) に分割できます。その中の単位はトークンまたはワードと呼ばれます。以下の図に示す具体的なプロセスに従って、まずテキスト文がユニットに分割され、次に単一の要素がデジタル化され (ベクトルにマッピングされ)、次にこれらのベクトルがエンコード用のモデルに入力され、最後に下流のタスクに出力され、さらに最終結果を取得します。テキストセグメンテーションは、テキストセグメンテーションの粒度に応じて Toke に分割できます。
 二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
人型ロボット「アメカ」が第二世代にバージョンアップ!最近、世界移動通信会議 MWC2024 に、世界最先端のロボット Ameca が再び登場しました。会場周辺ではアメカに多くの観客が集まった。 GPT-4 の恩恵により、Ameca はさまざまな問題にリアルタイムで対応できます。 「ダンスをしましょう。」感情があるかどうか尋ねると、アメカさんは非常に本物そっくりの一連の表情で答えました。ほんの数日前、Ameca を支援する英国のロボット企業である EngineeredArts は、チームの最新の開発結果をデモンストレーションしたばかりです。ビデオでは、ロボット Ameca は視覚機能を備えており、部屋全体と特定のオブジェクトを見て説明することができます。最も驚くべきことは、彼女は次のこともできるということです。
 柔軟かつ高速な 5 本の指を備え、人間のタスクを自律的に完了する初のロボットが登場、大型モデルが仮想空間トレーニングをサポート
Mar 11, 2024 pm 12:10 PM
柔軟かつ高速な 5 本の指を備え、人間のタスクを自律的に完了する初のロボットが登場、大型モデルが仮想空間トレーニングをサポート
Mar 11, 2024 pm 12:10 PM
今週、OpenAI、Microsoft、Bezos、Nvidiaが投資するロボット企業FigureAIは、7億ドル近くの資金調達を受け、来年中に自立歩行できる人型ロボットを開発する計画であると発表した。そしてテスラのオプティマスプライムには繰り返し良い知らせが届いている。今年が人型ロボットが爆発的に普及する年になることを疑う人はいないだろう。カナダに拠点を置くロボット企業 SanctuaryAI は、最近新しい人型ロボット Phoenix をリリースしました。当局者らは、多くのタスクを人間と同じ速度で自律的に完了できると主張している。人間のスピードでタスクを自律的に完了できる世界初のロボットである Pheonix は、各オブジェクトを優しくつかみ、動かし、左右にエレガントに配置することができます。自律的に物体を識別できる
 AI はどのようにロボットをより自律的で順応性のあるものにすることができるのでしょうか?
Jun 03, 2024 pm 07:18 PM
AI はどのようにロボットをより自律的で順応性のあるものにすることができるのでしょうか?
Jun 03, 2024 pm 07:18 PM
産業オートメーション技術の分野では、人工知能 (AI) と Nvidia という無視できない 2 つの最近のホットスポットがあります。元のコンテンツの意味を変更したり、コンテンツを微調整したり、コンテンツを書き換えたり、続行しないでください。「それだけでなく、Nvidia はオリジナルのグラフィックス プロセッシング ユニット (GPU) に限定されていないため、この 2 つは密接に関連しています。」このテクノロジーはデジタル ツインの分野にまで広がり、新たな AI テクノロジーと密接に関係しています。「最近、NVIDIA は、Aveva、Rockwell Automation、Siemens などの大手産業オートメーション企業を含む多くの産業企業と提携に至りました。シュナイダーエレクトリック、Teradyne Robotics とその MiR および Universal Robots 企業も含まれます。最近、Nvidiahascoll
 2か月後、人型ロボットWalker Sが服をたたむことができるようになった
Apr 03, 2024 am 08:01 AM
2か月後、人型ロボットWalker Sが服をたたむことができるようになった
Apr 03, 2024 am 08:01 AM
Machine Power Report 編集者: Wu Xin 国内版の人型ロボット + 大型模型チームは、衣服を折りたたむなどの複雑で柔軟な素材の操作タスクを初めて完了しました。 OpenAIのマルチモーダル大規模モデルを統合したFigure01の公開により、国内同業者の関連動向が注目を集めている。つい昨日、中国の「ヒューマノイドロボットのナンバーワン株」であるUBTECHは、Baidu Wenxinの大型モデルと深く統合されたヒューマノイドロボットWalkerSの最初のデモを公開し、いくつかの興味深い新機能を示した。 Baidu Wenxin の大規模モデル機能の恩恵を受けた WalkerS は次のようになります。 Figure01 と同様に、WalkerS は動き回るのではなく、机の後ろに立って一連のタスクを完了します。人間の命令に従って服をたたむことができる
 未来を形作る 10 台の人型ロボット
Mar 22, 2024 pm 08:51 PM
未来を形作る 10 台の人型ロボット
Mar 22, 2024 pm 08:51 PM
以下の 10 種類の人型ロボットが私たちの未来を形作ります。 1. ASIMO: ホンダが開発した ASIMO は、最もよく知られている人型ロボットの 1 つです。身長 4 フィート、体重 119 ポンドの ASIMO には、高度なセンサーと人工知能機能が装備されており、複雑な環境をナビゲートし、人間と対話することができます。 ASIMO は多用途性を備えているため、障害を持つ人々の支援からイベントでのプレゼンテーションまで、さまざまなタスクに適しています。 2. Pepper: ソフトバンクロボティクスによって作成された Pepper は、人間の社会的パートナーになることを目指しています。表情豊かな顔と感情を認識する能力を備えた Pepper は、会話に参加したり、小売現場で手助けしたり、教育サポートを提供したりすることもできます。コショウ
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 大規模なモデルをクラウドにデプロイするための 3 つの秘密
Apr 24, 2024 pm 03:00 PM
大規模なモデルをクラウドにデプロイするための 3 つの秘密
Apr 24, 2024 pm 03:00 PM
コンピレーション|Xingxuan によって制作|51CTO テクノロジー スタック (WeChat ID: blog51cto) 過去 2 年間、私は従来のシステムよりも大規模言語モデル (LLM) を使用した生成 AI プロジェクトに多く関与してきました。サーバーレス クラウド コンピューティングが恋しくなってきました。そのアプリケーションは、会話型 AI の強化から、さまざまな業界向けの複雑な分析ソリューションやその他の多くの機能の提供まで多岐にわたります。多くの企業は、パブリック クラウド プロバイダーが既製のエコシステムをすでに提供しており、それが最も抵抗の少ない方法であるため、これらのモデルをクラウド プラットフォームにデプロイしています。ただし、安くはありません。クラウドは、スケーラビリティ、効率、高度なコンピューティング機能 (オンデマンドで利用可能な GPU) などの他の利点も提供します。パブリック クラウド プラットフォームでの LLM の展開については、あまり知られていない側面がいくつかあります
