

UCLA中国人が新たな自動演奏機構を提案! LLM はそれ自体をトレーニングし、その効果は GPT-4 専門家の指導よりも優れています。

合成データは、大規模な言語モデルの進化において最も重要な基礎となっています。
昨年末、一部のネチズンは、元 OpenAI チーフサイエンティストのイリヤ氏が、LLM の開発にはデータのボトルネックはなく、合成データでほとんどの問題を解決できると繰り返し述べていたことを明らかにしました。 。
 写真
写真
NVIDIA のシニア サイエンティストであるジム ファン氏は、最新の論文群を研究した結果、合成データは従来のデータと組み合わせることで得られると信じていると結論付けました。ゲームおよび画像生成テクノロジーにより、LLM は大きな自己進化を実現できます。
 写真
写真
この方法を正式に提案した論文は、UCLA の中国チームによって書かれました。
 写真
写真
論文アドレス: https://www.php.cn/link/236522d75c8164f90a85448456e1d1aa
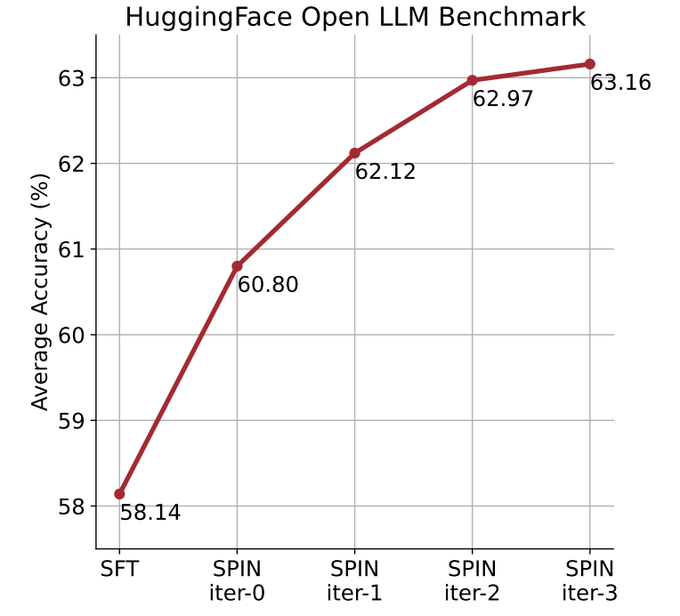
彼らは、自動再生メカニズム (SPIN) を使用して合成データを生成し、新しいデータセットに依存せずに自己微調整メソッドを通じて、Open LLM Leaderboard Benchmark の弱い LLM の平均スコアを生成しました。 58.14.から63.16に改善されました。
研究者らは、自己演奏による SPIN と呼ばれる自己微調整手法を提案しました - LLM とその以前の反復バージョン 対立を行い、徐々に改善していきます言語モデルのパフォーマンス。
 図
図
こうすることで、人間による注釈付きの追加データや高レベル言語モデルからのフィードバックは必要なくなります。モデルの自己進化を完了します。
メインモデルと相手モデルのパラメータは全く同じです。 2 つの異なるバージョンで自分自身と対戦してください。
ゲームのプロセスは次の式で要約できます:
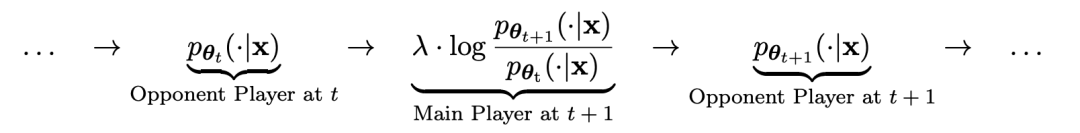 写真
写真
セルフプレイ トレーニング方法を要約すると、その考え方は大まかに次のとおりです。
メイン モデルをトレーニングして、相手モデルによって生成された応答と人間のターゲットの応答を区別することにより、相手モデルは、反復のラウンドによって得られる言語モデルであり、目標は、できるだけ区別できない応答を生成することです。
t回目の反復で得られた言語モデルパラメータをθtとすると、t回目の反復ではθtを相手プレイヤーとして微調整する監視用のデータセット内の各プロンプト x に対して、θt を使用して応答 y' を生成します。
次に、教師付き微調整データセット内の人間の応答 y から y' を区別できるように、新しい言語モデル パラメーター θt 1 を最適化します。これにより、段階的なプロセスが形成され、目標の応答分布に徐々に近づくことができます。
ここで、メイン モデルの損失関数は、y と y' の間の関数値の差を考慮して、対数損失を採用します。
KL 発散正則化を相手モデルに追加して、モデル パラメーターが大きく逸脱しないようにします。
具体的な敵対ゲームのトレーニング目標を式 4.7 に示します。理論分析から、言語モデルの応答分布がターゲットの応答分布と等しい場合、最適化プロセスは収束することがわかります。
ゲーム後に生成された合成データをトレーニングに使用し、その後 SPIN を使用して自己微調整を行うと、LLM のパフォーマンスを効果的に向上させることができます。
 図
図
しかし、最初の微調整データを再度微調整するだけでは、パフォーマンスが低下します。
SPIN には初期モデル自体と既存の微調整されたデータ セットのみが必要なので、LLM は SPIN を通じてそれ自体を改善できます。
特に、SPIN は、DPO 経由で追加の GPT-4 設定データを使用してトレーニングされたモデルよりも優れたパフォーマンスを発揮します。
 写真
写真
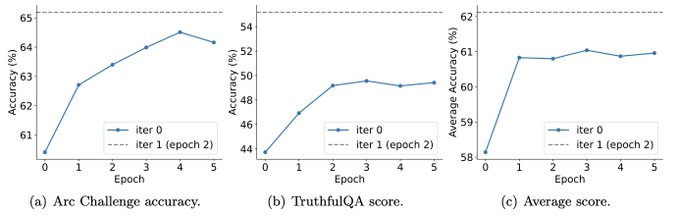
また、実験では、反復トレーニングの方が、より多くのエポックでトレーニングするよりも効果的にモデルのパフォーマンスを向上できることも示しています。
 写真
写真
1 回の反復のトレーニング期間を延長しても、SPIN のパフォーマンスは低下しませんが、限界に達します。 。
反復回数が増えるほど、SPIN の効果がより明らかになります。
この論文を読んだ後、ネチズンはため息をつきました:
合成データは大規模言語モデルの開発と大規模言語モデルの研究を支配するでしょう読者の皆様には大変朗報となります!
 写真
写真
セルフプレイにより、LLM は継続的に改善できます
具体的には、研究者らが開発した SPIN システムは、相互に影響を与える 2 つのモデルが相互に促進し合うシステムです。
前の反復 t の LLM (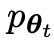 で示される) は、手動で注釈が付けられた SFT データセット内のプロンプト x に対する応答 y を生成するために研究者によって使用されます。 。
で示される) は、手動で注釈が付けられた SFT データセット内のプロンプト x に対する応答 y を生成するために研究者によって使用されます。 。
次の目標は、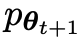 生成された応答 y と生成された応答 y を区別できる新しい LLM
生成された応答 y と生成された応答 y を区別できる新しい LLM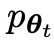 を見つけることです。人間による応答y'。
を見つけることです。人間による応答y'。
このプロセスは 2 プレイヤー ゲームとして見ることができます:
メイン プレイヤーまたは新しい LLM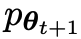 対戦相手プレイヤーの応答と人間が生成した応答を区別するようにしてください。一方、対戦相手または古い LLM
対戦相手プレイヤーの応答と人間が生成した応答を区別するようにしてください。一方、対戦相手または古い LLM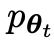 が生成した応答は、人間が注釈を付けた SFT データセット内のデータと可能な限り類似しています。
が生成した応答は、人間が注釈を付けた SFT データセット内のデータと可能な限り類似しています。
#古い 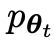
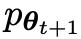 優先
優先  ' を微調整することによって取得された新しい LLMの応答により、
' を微調整することによって取得された新しい LLMの応答により、 とより一貫性のある分布
とより一貫性のある分布 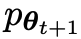 が得られます。
が得られます。
次の反復では、新しく取得した LLM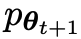 が応答生成された対戦相手となり、自己再生プロセスの目標は、LLM が最終的に # に収束することです。
が応答生成された対戦相手となり、自己再生プロセスの目標は、LLM が最終的に # に収束することです。 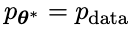 ##、最も強力な LLM は、以前に生成された応答のバージョンと人間が生成したバージョンを区別できなくなります。
##、最も強力な LLM は、以前に生成された応答のバージョンと人間が生成したバージョンを区別できなくなります。
研究者らは、モデルの主な目標を区別することである 2 人用ゲームを設計しました。 LLM によって生成された応答と人間が生成した応答。同時に、敵の役割は、人間の応答と区別できない応答を生成することです。研究者のアプローチの中心となるのは、一次モデルのトレーニングです。
まず、LLM の応答と人間の応答を区別するためにメイン モデルをトレーニングする方法を説明します。
研究者らのアプローチの中核はセルフゲーム メカニズムです。このメカニズムでは、メイン プレーヤーと対戦相手はどちらも同じ LLM に属しますが、異なる反復に属します。
より具体的には、対戦相手は前の反復の古い LLM であり、主役は現在の反復で学習する新しい LLM です。反復 t 1 には、(1) メイン モデルのトレーニング、(2) 相手モデルの更新の 2 つのステップが含まれます。
マスター モデルのトレーニング
まず、研究者はマスター プレーヤーが LLM を区別できるようにトレーニングする方法を説明します。反応も人間の反応も。積分確率尺度 (IPM) に触発されて、研究者らは次の目的関数を定式化しました。モデル
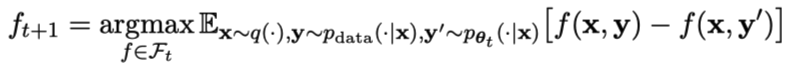 敵対的モデルの目標は、マスター モデルの p データと区別できない応答を生成する、より優れた LLM を見つけることです。
敵対的モデルの目標は、マスター モデルの p データと区別できない応答を生成する、より優れた LLM を見つけることです。
SPIN はベンチマークのパフォーマンスを効果的に向上させます
研究者は HuggingFace Open LLM Leaderboard を広範なツールとして使用していますSPIN の有効性を証明するための評価。
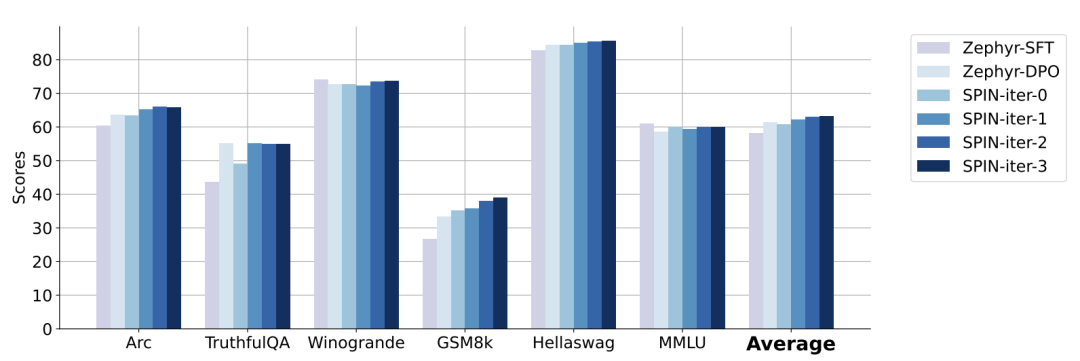
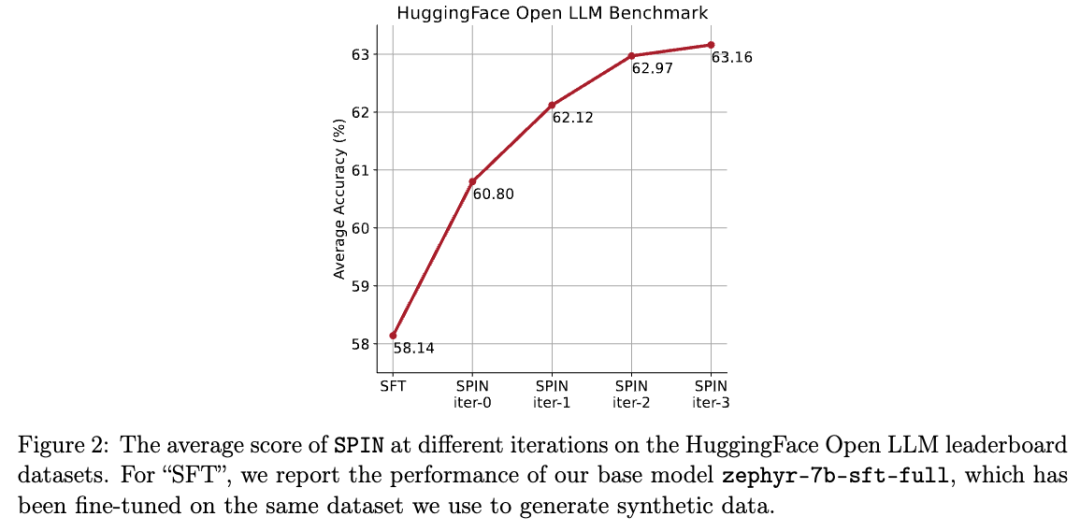
以下の図では、研究者らは、0 ~ 3 回の反復後に SPIN によって微調整されたモデルのパフォーマンスをベース モデル zephyr-7b-sft-full と比較しました。
研究者は、SPIN が SFT データセットをさらに活用することで、モデルのパフォーマンスを向上させるという重要な結果を示していることを観察できます。このデータセットでは、ベース モデルはすでに完全に微調整されてテストされています。
反復 0 では、モデル応答が zephyr-7b-sft-full から生成され、研究者らは平均スコアが全体的に 2.66% 向上したことを観察しました。
この改善は、TruthfulQA ベンチマークと GSM8k ベンチマークで特に顕著であり、それぞれ 5% と 10% 以上の増加がありました。
反復 1 では、研究者は反復 0 の LLM モデルを使用して、アルゴリズム 1 で概説したプロセスに従って、SPIN に対する新しい応答を生成しました。
この反復により、平均 1.32% のさらなる強化がもたらされます。これは、Arc Challenge および TruthfulQA ベンチマークで特に顕著です。
その後の反復では、さまざまなタスクが段階的に改善される傾向が続きました。同時に、反復 t 1 での改善は当然小さくなります。
写真
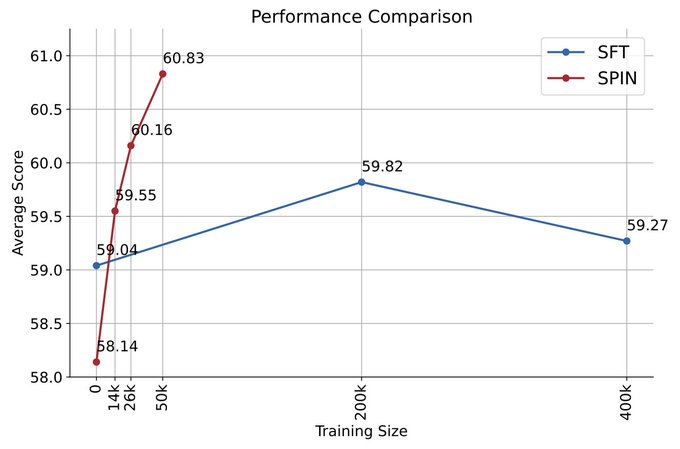
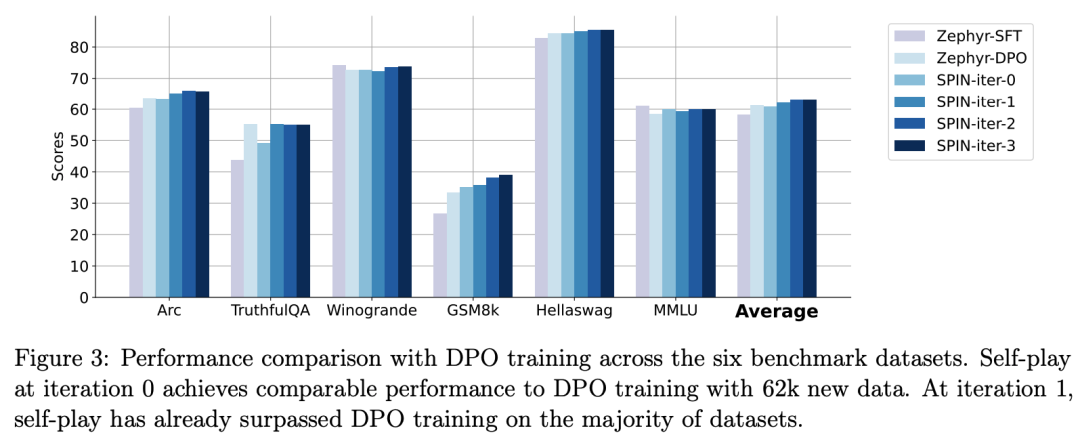
zephyr-7b-beta は以下から導出されます。 zephyr-7b- sft-full から派生したモデルは、DPO を使用して約 62,000 の優先データでトレーニングされます。
研究者らは、DPO では好みを決定するために人間の入力または高水準言語モデルのフィードバックが必要なため、データ生成プロセスにかなりのコストがかかると指摘しています。
 対照的に、研究者の SPIN は初期モデル自体のみを必要とします。
対照的に、研究者の SPIN は初期モデル自体のみを必要とします。
さらに、新しいデータソースを必要とする DPO とは異なり、研究者のアプローチは既存の SFT データセットを最大限に活用しています。
次の図は、反復 0 と 1 での SPIN トレーニングと DPO トレーニングのパフォーマンスの比較を示しています (50k SFT データを使用)。
 写真
写真
研究者らは、DPO が新しいソースからのより多くのデータを利用しているにもかかわらず、既存の SFT データに基づく SPIN が最初の反復 1 から変化していることを観察できます。 , SPINはDPOのパフォーマンスをも上回り、ランキングベンチマークテストでもSPINはDPOを上回りました。
#参考:
以上がUCLA中国人が新たな自動演奏機構を提案! LLM はそれ自体をトレーニングし、その効果は GPT-4 専門家の指導よりも優れています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7807
7807
 15
1645
14
1402
52
1300
25
1236
29
15
1645
14
1402
52
1300
25
1236
29

 カリフォルニア工科大学の中国人がAIを使って数学的証明を覆す!タオ・ゼシュアンの衝撃を5倍にスピードアップ、数学的ステップの80%が完全に自動化
Apr 23, 2024 pm 03:01 PM
カリフォルニア工科大学の中国人がAIを使って数学的証明を覆す!タオ・ゼシュアンの衝撃を5倍にスピードアップ、数学的ステップの80%が完全に自動化
Apr 23, 2024 pm 03:01 PM
テレンス・タオなど多くの数学者に賞賛されたこの正式な数学ツール、LeanCopilot が再び進化しました。ちょうど今、カリフォルニア工科大学のアニマ・アナンドクマール教授が、チームが LeanCopilot 論文の拡張版をリリースし、コードベースを更新したと発表しました。イメージペーパーのアドレス: https://arxiv.org/pdf/2404.12534.pdf 最新の実験では、この Copilot ツールが数学的証明ステップの 80% 以上を自動化できることが示されています。この記録は、以前のベースラインのイソップよりも 2.3 倍優れています。そして、以前と同様に、MIT ライセンスの下でオープンソースです。写真の彼は中国人の少年、ソン・ペイヤンです。
 Groq Llama 3 70B をローカルで使用するためのステップバイステップ ガイド
Jun 10, 2024 am 09:16 AM
Groq Llama 3 70B をローカルで使用するためのステップバイステップ ガイド
Jun 10, 2024 am 09:16 AM
翻訳者 | Bugatti レビュー | Chonglou この記事では、GroqLPU 推論エンジンを使用して JanAI と VSCode で超高速応答を生成する方法について説明します。 Groq は AI のインフラストラクチャ側に焦点を当てているなど、誰もがより優れた大規模言語モデル (LLM) の構築に取り組んでいます。これらの大型モデルがより迅速に応答するためには、これらの大型モデルからの迅速な応答が鍵となります。このチュートリアルでは、GroqLPU 解析エンジンと、API と JanAI を使用してラップトップ上でローカルにアクセスする方法を紹介します。この記事では、これを VSCode に統合して、コードの生成、コードのリファクタリング、ドキュメントの入力、テスト ユニットの生成を支援します。この記事では、独自の人工知能プログラミングアシスタントを無料で作成します。 GroqLPU 推論エンジン Groq の概要
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 「人間 + RPA」から「人間 + 生成 AI + RPA」へ、LLM は RPA と人間とコンピューターのインタラクションにどのような影響を与えるのでしょうか?
Jun 05, 2023 pm 12:30 PM
「人間 + RPA」から「人間 + 生成 AI + RPA」へ、LLM は RPA と人間とコンピューターのインタラクションにどのような影響を与えるのでしょうか?
Jun 05, 2023 pm 12:30 PM
画像出典@visualchinesewen|Wang Jiwei 「人間 + RPA」から「人間 + 生成 AI + RPA」へ、LLM は RPA の人間とコンピューターのインタラクションにどのような影響を与えますか?別の観点から見ると、人間とコンピューターの相互作用の観点から、LLM は RPA にどのような影響を与えるのでしょうか?プログラム開発やプロセス自動化における人間とコンピューターの対話に影響を与える RPA も、LLM によって変更される予定ですか? LLM は人間とコンピューターの相互作用にどのような影響を与えますか?生成 AI は RPA と人間とコンピューターのインタラクションをどのように変えるのでしょうか?詳細については、次の記事をご覧ください: 大規模モデルの時代が到来し、LLM に基づく生成 AI が RPA の人間とコンピューターのインタラクションを急速に変革しています。生成 AI は人間とコンピューターのインタラクションを再定義し、LLM は RPA ソフトウェア アーキテクチャの変化に影響を与えています。 RPA がプログラム開発と自動化にどのような貢献をしているかを尋ねると、答えの 1 つは人間とコンピューターの相互作用 (HCI、h) を変えたことです。
 Plaud、NotePin AI ウェアラブル レコーダーを 169 ドルで発売
Aug 29, 2024 pm 02:37 PM
Plaud、NotePin AI ウェアラブル レコーダーを 169 ドルで発売
Aug 29, 2024 pm 02:37 PM
Plaud Note AI ボイスレコーダー (Amazon で 159 ドルで購入可能) を開発した企業 Plaud が新製品を発表しました。 NotePin と呼ばれるこのデバイスは AI メモリ カプセルとして説明されており、Humane AI Pin と同様にウェアラブルです。ノートピンは
 大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
Llama3 に関しては、新しいテスト結果が発表されました。大規模モデル評価コミュニティ LMSYS は、Llama3 が 5 位にランクされ、英語カテゴリでは GPT-4 と同率 1 位にランクされました。このリストは他のベンチマークとは異なり、モデル間の 1 対 1 の戦いに基づいており、ネットワーク全体の評価者が独自の提案とスコアを作成します。最終的に、Llama3 がリストの 5 位にランクされ、GPT-4 と Claude3 Super Cup Opus の 3 つの異なるバージョンが続きました。英国のシングルリストでは、Llama3 がクロードを追い抜き、GPT-4 と並びました。この結果について、Meta の主任科学者 LeCun 氏は非常に喜び、リツイートし、
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
人型ロボット「アメカ」が第二世代にバージョンアップ!最近、世界移動通信会議 MWC2024 に、世界最先端のロボット Ameca が再び登場しました。会場周辺ではアメカに多くの観客が集まった。 GPT-4 の恩恵により、Ameca はさまざまな問題にリアルタイムで対応できます。 「ダンスをしましょう。」感情があるかどうか尋ねると、アメカさんは非常に本物そっくりの一連の表情で答えました。ほんの数日前、Ameca を支援する英国のロボット企業である EngineeredArts は、チームの最新の開発結果をデモンストレーションしたばかりです。ビデオでは、ロボット Ameca は視覚機能を備えており、部屋全体と特定のオブジェクトを見て説明することができます。最も驚くべきことは、彼女は次のこともできるということです。
