
 テクノロジー周辺機器
AI
テレンス・タオはそれを見て彼を専門家と呼んだ! Google などは LLM を使用して定理を自動的に証明し、カンファレンスで優秀な論文を受賞しました。コンテキストが完全であればあるほど、証明はより優れたものになります。
テクノロジー周辺機器
AI
テレンス・タオはそれを見て彼を専門家と呼んだ! Google などは LLM を使用して定理を自動的に証明し、カンファレンスで優秀な論文を受賞しました。コンテキストが完全であればあるほど、証明はより優れたものになります。
テレンス・タオはそれを見て彼を専門家と呼んだ! Google などは LLM を使用して定理を自動的に証明し、カンファレンスで優秀な論文を受賞しました。コンテキストが完全であればあるほど、証明はより優れたものになります。

Transformer のスキル ツリーはますます強力になっています。
マサチューセッツ大学、Google、イリノイ大学アーバナシャンペーン校 (UIUC) の研究者らは最近、完全な定理を自動的に生成するという目標を達成することに成功した論文を発表しました。証拠。

論文アドレス: https://arxiv.org/pdf/2303.04910.pdf
これBaldur (北欧神話のトールの兄弟) にちなんで名付けられたこの研究は、Transformer が完全な証明を生成できることを初めて実証し、モデルに追加のコンテキストを提供することでモデルの以前の証明を改善できることも示しました。
この論文は、2023 年 12 月に ESEC/FSE (ACM European Joint Conference on Software Engineering and Symposium on Fundamentals of Software Engineering) で発表され、Outstanding Paper Award を受賞しました。
#誰もが知っているように、ソフトウェアにはバグが避けられず、平均的なアプリケーションや Web サイトではそれほど大きな問題を引き起こすことはありません。ただし、暗号化プロトコル、医療機器、スペースシャトルなどの重要なシステムの背後にあるソフトウェアについては、バグがないことを確認する必要があります。
- 一般的なコード レビューとテストではこの保証は得られないため、正式な検証が必要です。
形式的検証について、ScienceDirect の説明は次のとおりです:
形式モデルを使用して記述されたシステムの動作が、指定されたプロパティを満たします。これも形式モデルを使用して記述されます。
は、形式モデルによって記述されたシステムの動作が指定されたプロパティを満たしているかどうかを数学的にチェックするプロセスを指します。
簡単に言うと、数学的解析手法を使用してアルゴリズム エンジンを通じてモデルを構築し、テスト対象の設計の状態空間の徹底的な解析と検証を実行します。
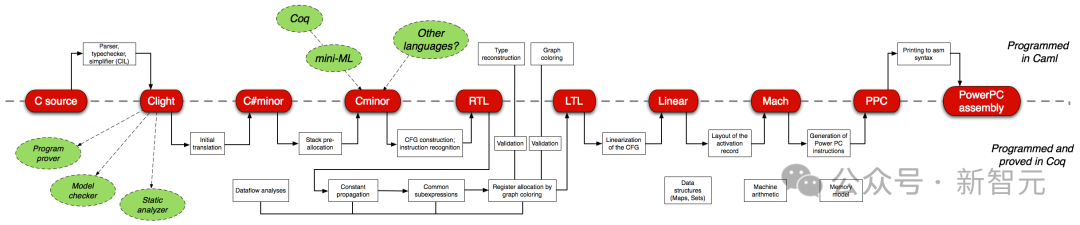
正式なソフトウェア検証は、ソフトウェア エンジニアにとって最も困難なタスクの 1 つです。たとえば、Coq 対話型定理証明器で検証された C コンパイラである CompCert は、ユビキタスな GCC や LLVM などで使用される唯一のコンパイラです。
ただし、手動による形式的検証 (証明の作成) のコストは非常に膨大です。C コンパイラの証明は、コンパイラ コード自体の証明の 3 倍以上です。
したがって、形式的な検証自体は「労働集約的」な作業であり、研究者らは自動化された方法も模索しています。
Coq や Isabelle などの証明アシスタントは、一度に 1 つの証明ステップを予測するようにモデルをトレーニングし、そのモデルを使用して可能な証明空間を検索します。
Baldur はこの記事で、この分野における大規模言語モデルの機能、自然言語テキストとコードのトレーニング、証明の微調整機能を初めて紹介しました。
Baldur は、一度に 1 ステップずつではなく、定理の完全な証明を一度に生成できます。
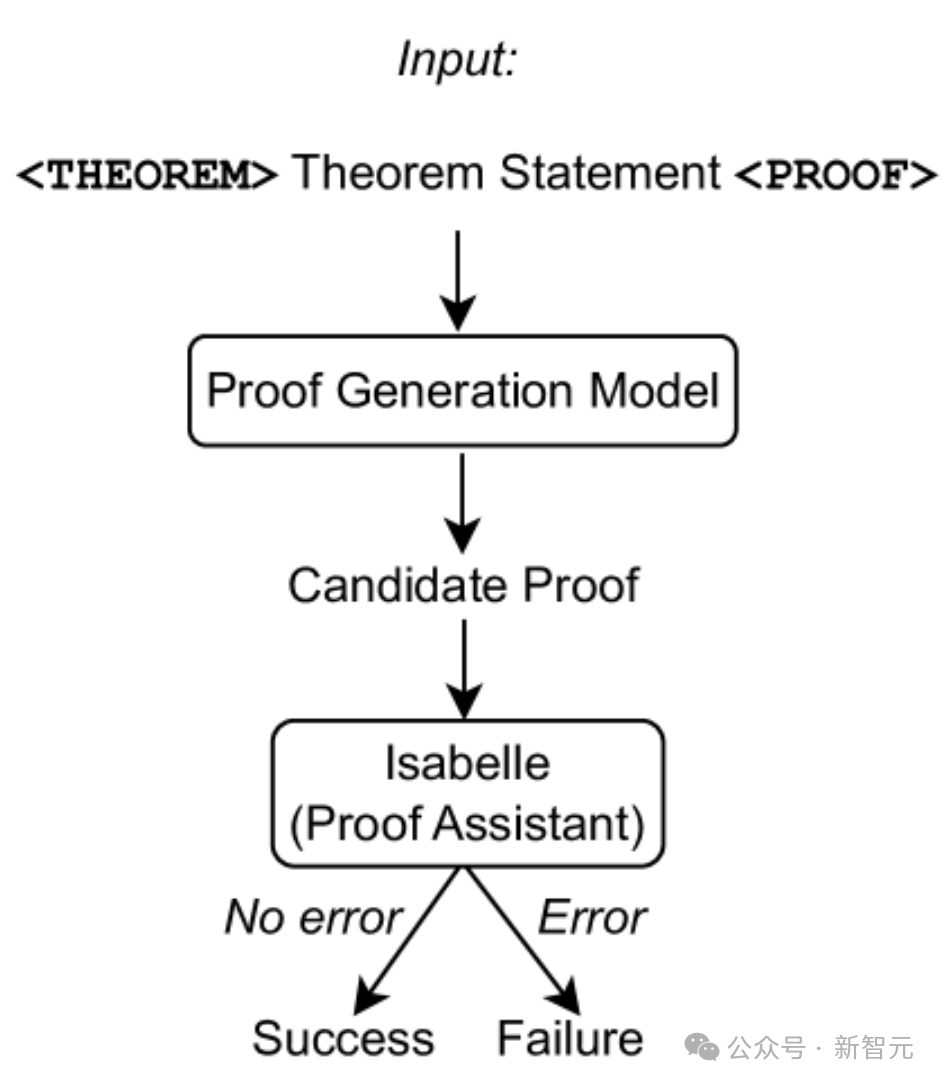
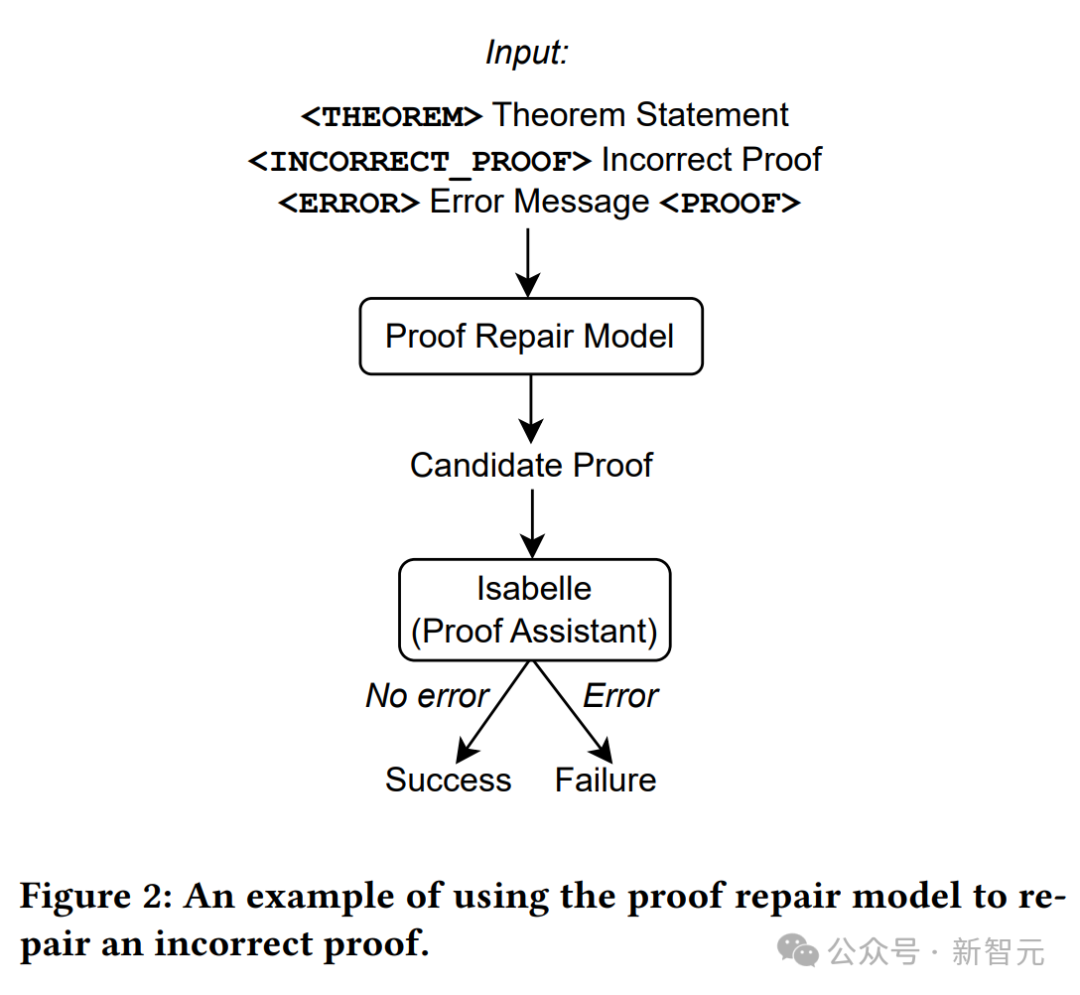
#上の図に示すように、証明生成モデルへの入力として定理ステートメントのみを使用し、モデルから証明試行を抽出します。イザベルを使用して証明検査を実行します。
イザベルがエラーなしで証明の試みを受け入れた場合、証明は成功します。そうでない場合は、別の証明の試みが証明生成モデルから抽出されます。
Baldur は、6336 個の Isabelle/HOL 定理とその証明のベンチマークで評価され、完全な証明の生成、修復、コンテキストの追加の有効性を経験的に実証しています。
さらに、このツールが Baldur と呼ばれている理由は、現在最良の自動プルーフ生成ツールが Thor と呼ばれているためかもしれません。
Thor は、より小さな言語モデルと、証明の次のステップを予測するために可能な証明の空間を検索する方法を組み合わせて使用することで、より高い証明率 (57%) を持っていますが、Baldur の利点は、完全な証拠。

しかし、トールとバルダーの兄弟も協力することができ、証明率が 66% 近くまで高まる可能性があります。
完全な証明を自動的に生成
Baldur は、科学論文や数学を含む Web ページで使用される Google の大規模言語モデルである Minerva を利用しています。証明と定理に関するデータに基づいてトレーニングされ、微調整されました。
Baldur は、証明結果をチェックする定理証明アシスタントの Isabelle と協力できます。定理ステートメントが与えられたとき、Baldur はほぼ 41% の確率で完全な証明を生成することができました。
Baldur のパフォーマンスをさらに向上させるために、研究者はモデルに追加のコンテキスト情報 (他の定義や理論文書の定理ステートメントなど) を提供しました。これにより校正率は 47.5% に増加します。
これは、Baldur がコンテキストを取得し、それを使用して新しい正しい証明を予測できることを意味します。これは、関連するメソッドとコードを理解している場合にそうする可能性が高いプログラマーと同様です。プログラムのバグ。
例は次のとおりです (fun_sum_commute 定理):

この定理は、Formal Proof Archives の Polynomials と呼ばれるプロジェクトから来ています。
手動で証明を書く場合、セットが有限であるか有限でないという 2 つのケースが区別されます。

つまり、モデルの入力は定理ステートメントであり、ターゲットの出力はこの手動で書かれた証明です。
Baldur はここで帰納法の必要性を認識し、infinite_finite_induct と呼ばれる特別な帰納法を適用しました。これは人間が書いた証明と同じ一般的なアプローチに従いますが、より簡潔です。
帰納法が必要なため、イザベルが使用するスレッジハンマーはデフォルトではこの定理を証明できません。
トレーニング
プルーフ生成モデルをトレーニングするために、研究者は新しいプルーフ生成データセットを構築しました。
既存のデータセットには単一の証明ステップの例が含まれており、各トレーニング サンプルには証明の状態 (入力) と適用される次の証明ステップ (目標) が含まれています。
単一の証明ステップを含むデータセットがあるとすると、証明全体を一度に予測するようにモデルをトレーニングするために、新しいデータセットを作成する必要があります。
研究者らは、データセットから各定理の証明ステップを抽出し、それらを連結して元の証明を再構築しました。
#修理の証明
# 上記の fun_sum_commute を例として取り上げます。

Baldur が最初に生成した証明の試みは、証明チェッカーで失敗しました。
Baldur は帰納法を適用しようとしましたが、最初に証明を 2 つの場合 (有限集合と無限集合) に分解することができませんでした。イザベルは次のエラー メッセージを返します:

これらの文字列から証明修復トレーニングの例を導き出すために、ここでは、定理ステートメント、失敗した証明試行、およびエラー メッセージが、人間が作成した正しいコードを使用して入力として連結されます。ターゲットとしての証拠。
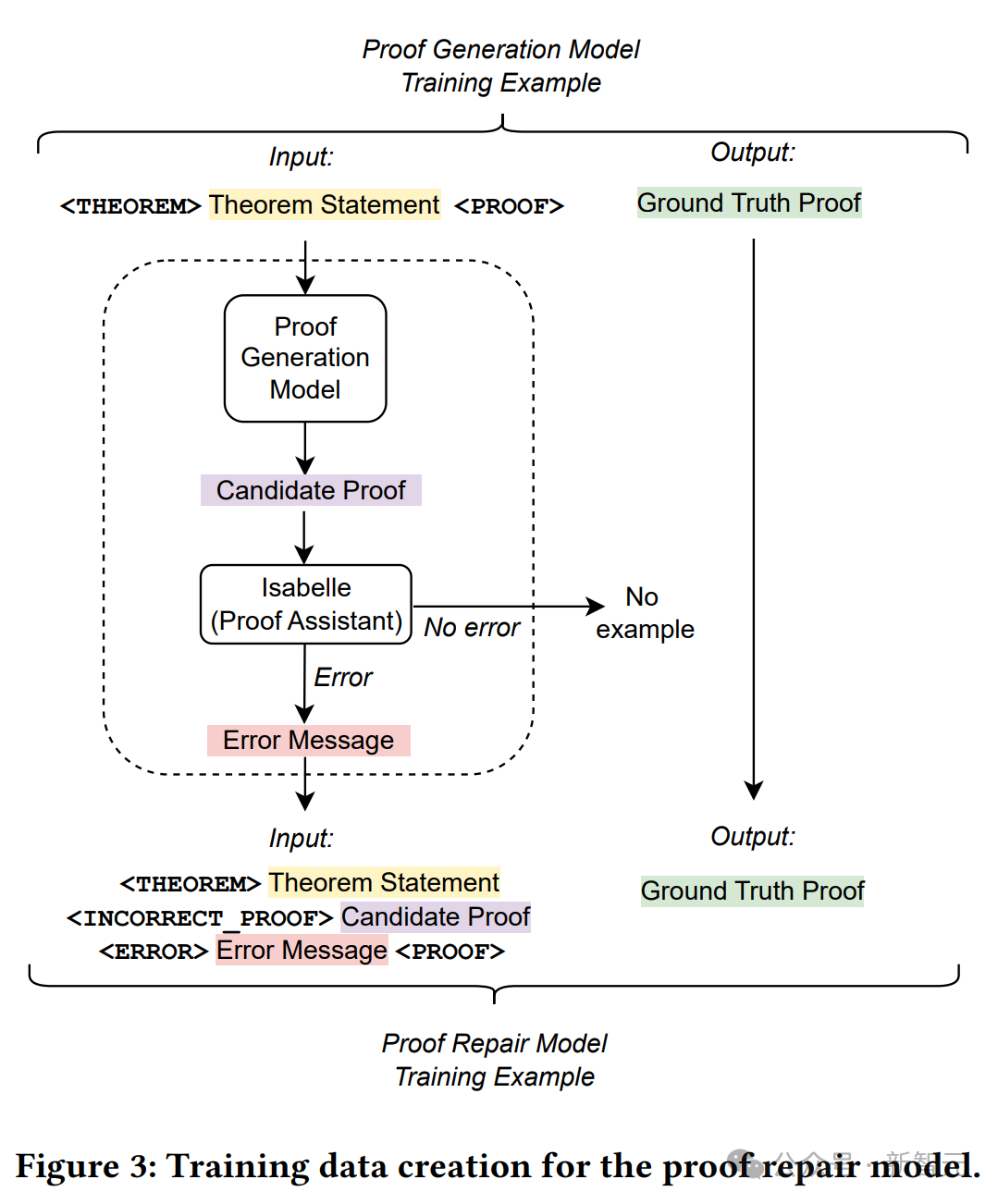
#上の図は、トレーニング データの作成プロセスを詳しく示しています。
証明生成モデルを使用して、元のトレーニング セットの各質問に対して温度 0 の証明をサンプリングします。
Proofing Assistant を使用して、失敗したすべての校正とそのエラー メッセージを記録し、新しい校正/修正トレーニング セットの構築に進みます。
元のトレーニング サンプルごとに、定理ステートメント、証明生成モデルによって生成された (間違った) 候補証明、および対応するエラー メッセージを連結して、新しいトレーニング サンプル シーケンスの入力を取得します。 。
#コンテキストの追加
追加のコンテキストとして、定理ステートメントの前に理論ファイルの行を追加します。たとえば、下の図は次のようになります。

Baldur のコンテキスト付き証明生成モデルは、この追加情報を利用できます。 fun_sum_commute の定理ステートメントに出現する文字列は、このコンテキストでも再び出現するため、それらを囲む追加情報は、モデルがより適切な予測を行うのに役立ちます。
コンテキストは、ステートメント (定理、定義、証明) または自然言語の注釈です。
LLM の利用可能な入力長を活用するために、研究者らはまず、同じ理論ファイルから最大 50 個のステートメントを追加しました。
トレーニング中、これらのステートメントはすべて最初にトークン化され、次にシーケンスの左側が入力長に合わせて切り詰められます。
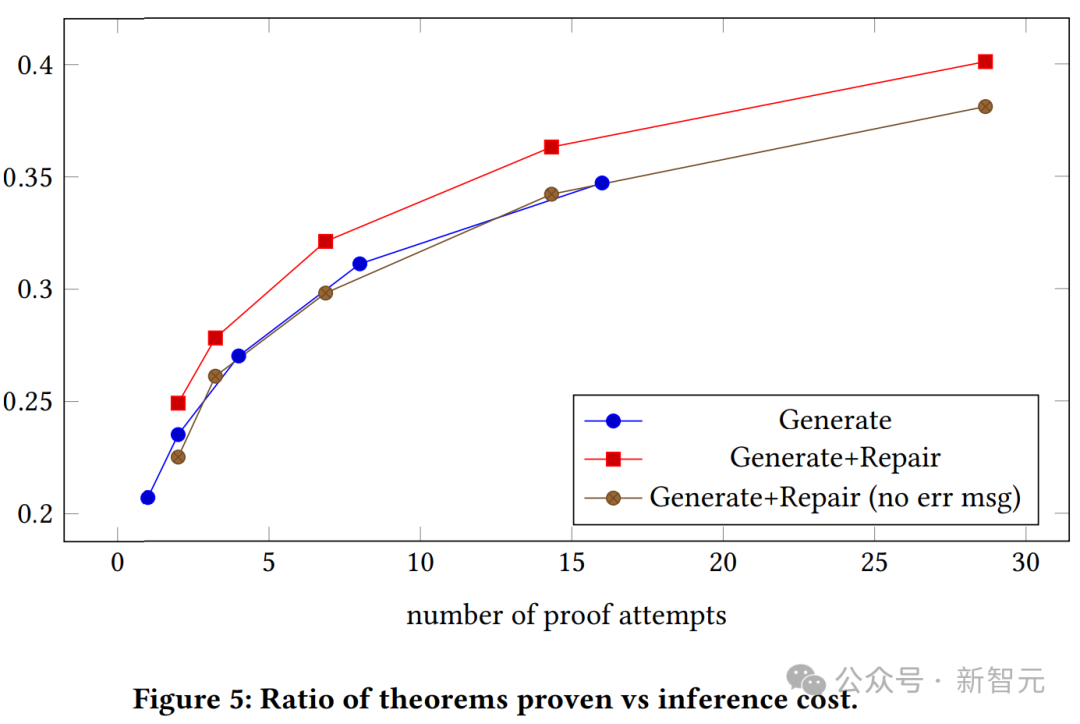
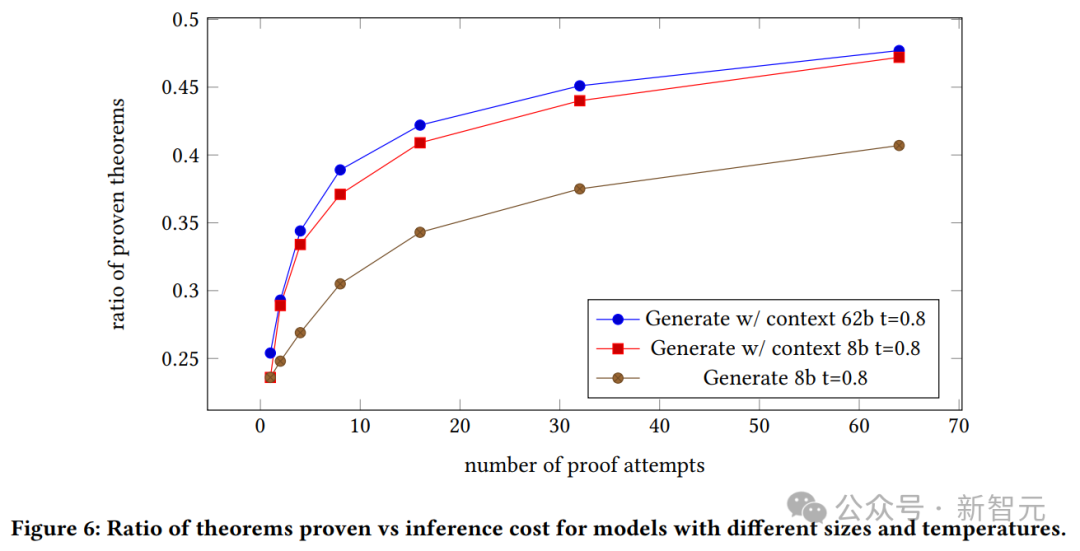
生成されたモデルの証明成功率、8B モデルと 62B モデルのコンテキストと証明試行回数の関係も確認できます。
コンテキストを含む 62B は、生成モデルがコンテキストを含む 8B モデルよりも優れていることを証明します。
ただし、著者らはここで、これらの実験にはコストがかかるため、ハイパーパラメーターを調整することができず、最適化すれば 62B モデルのパフォーマンスが向上する可能性があることを強調しています。
以上がテレンス・タオはそれを見て彼を専門家と呼んだ! Google などは LLM を使用して定理を自動的に証明し、カンファレンスで優秀な論文を受賞しました。コンテキストが完全であればあるほど、証明はより優れたものになります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7552
7552
 15
1382
52
83
11
22
95
15
1382
52
83
11
22
95

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CENTOSでのZookeeperパフォーマンスチューニングは、ハードウェア構成、オペレーティングシステムの最適化、構成パラメーターの調整、監視、メンテナンスなど、複数の側面から開始できます。特定のチューニング方法を次に示します。SSDはハードウェア構成に推奨されます。ZookeeperのデータはDISKに書き込まれます。十分なメモリ:頻繁なディスクの読み取りと書き込みを避けるために、Zookeeperに十分なメモリリソースを割り当てます。マルチコアCPU:マルチコアCPUを使用して、Zookeeperが並行して処理できるようにします。
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
SSHサービスを再起動するコマンドは次のとおりです。SystemCTL再起動SSHD。詳細な手順:1。端子にアクセスし、サーバーに接続します。 2。コマンドを入力します:SystemCtl RestArt SSHD; 3.サービスステータスの確認:SystemCTLステータスSSHD。
