

史上初の 100% オープンソースの大規模モデルが登場!コード/重み/データセット/トレーニングプロセス全体の記録破りの開示、AMDがトレーニング可能

長年にわたり、言語モデルは自然言語処理 (NLP) テクノロジーの中核でした。このモデルの背後にある莫大な商業的価値を考慮して、最新鋭モデルの技術的な詳細は公開されていません。
真に完全にオープンソースの大規模モデルが登場しました。
アレン人工知能研究所、ワシントン大学、イェール大学、ニューヨーク大学、カーネギーメロン大学の研究者らは、最近協力して重要な研究成果を発表しました。 AI オープンソース コミュニティにとって重要なマイルストーンです。
彼らは、大規模なモデルをゼロからトレーニングする過程で、ほぼすべてのデータと情報をオープンソース化する予定です。
#用紙: https://allenai.org/olmo/olmo-paper.pdf
重量: https://huggingface.co/allenai/OLMo-7B
コード: https://github.com/allenai/OLMo
データ: https://huggingface.co/datasets/allenai/dolma
評価: https://github.com/allenai/OLMo-Eval
適応: https://github.com/allenai/open-instruct

#トレーニングとモデリング:
これには、完全なモデルの重み、トレーニング コード、トレーニング ログ、アブレーション 研究、トレーニング メトリック、および推論コードが含まれます。事前トレーニング コーパス:
最大 3T トークンとこれらを生成するコードを含む事前トレーニング オープンソース コーパストレーニングデータ。モデル パラメーター:
同時に、モデル推論に使用されるコード、トレーニング プロセスのさまざまな指標、トレーニング ログも提供されます。
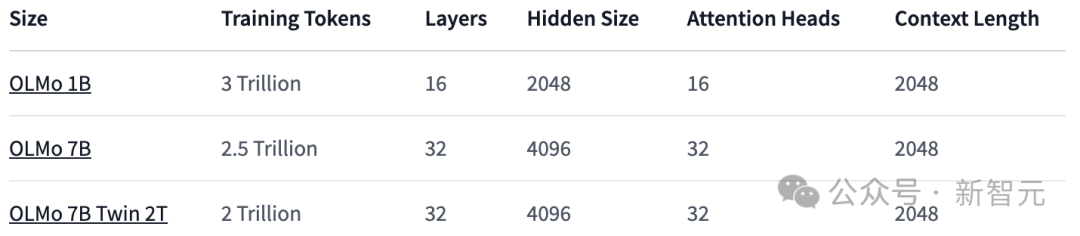
#7B: OLMo 7B、OLMo 7B (アニーリングなし)、OLMo 7B-2T、OLMo-7B-Twin-2T
は、開発プロセス中に一連の評価ツールを公開します。これには、各モデル トレーニング プロセス ポイントの 1000 ステップごとに含まれる 500 を超えるチェックが含まれます。評価コードも同様です。
すべてのデータは、Apache 2.0 での使用がライセンスされています (商用利用は無料)。
このような徹底的なオープンソースは、オープンソース コミュニティのパターンを設定するようです - 将来的には、私のようにオープンソースをやらない場合、自分がオープンソースモデルであるとは言わないでください。
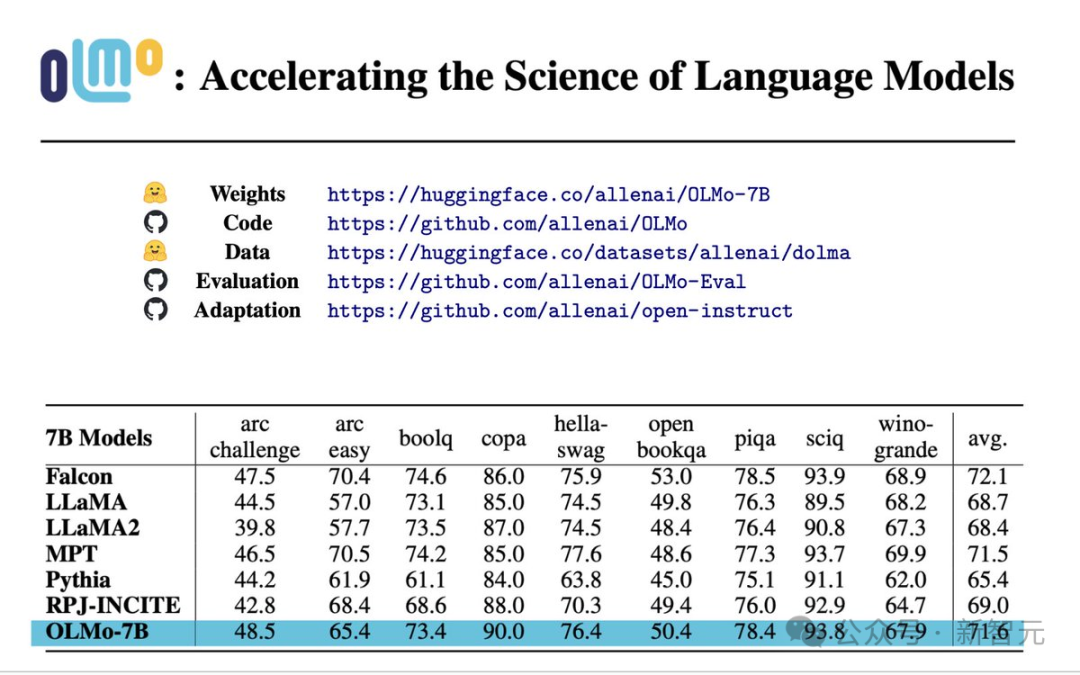
パフォーマンス評価
コア評価結果から、OLMo-7B は類似のオープンソース モデルよりわずかに優れています。
最初の 9 件の評価のうち、OLMo-7B は 8 件で上位 3 に入り、そのうち 2 件は他のすべてのモデルを上回りました。
多くの生成タスクや読解タスク (truthfulQA など) では、OLMo-7B は Llama 2 を上回りますが、一部の一般的な質問と回答タスク (MMLU や Big-bench Hard など) では、OLMo-7B は Llama 2 を上回ります。 )、パフォーマンスは悪くなります。
最初の 9 つのタスクは、事前トレーニング済みモデルに対する研究者の内部評価基準ですが、次の 3 つのタスクは、HuggingFace Open LLM ランキングを向上させるために追加されます
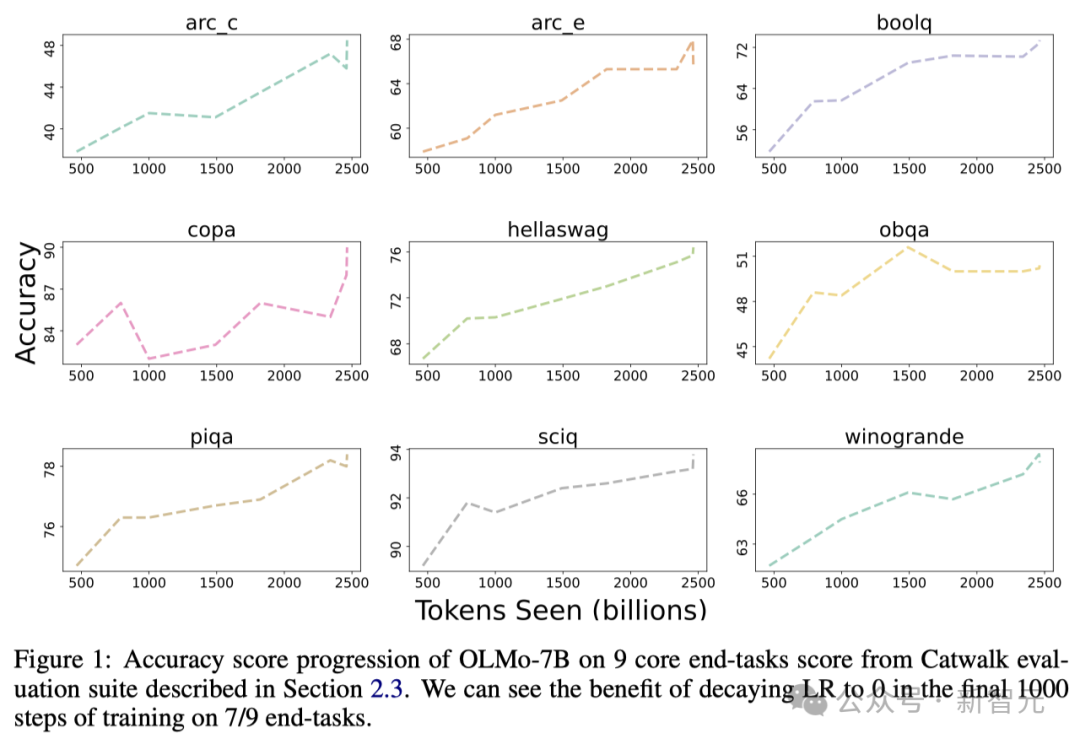
# #以下の図は、9つのコアタスクの精度の変化傾向を示しています。
OBQA を除いて、OLMo-7B がトレーニングのために受け取るデータが増えるにつれて、ほぼすべてのタスクの精度が上昇傾向を示しています。
一方、OLMo 1B およびその類似モデルのコア評価結果は、OLMo がそれらと同等のレベルにあることを示しています。
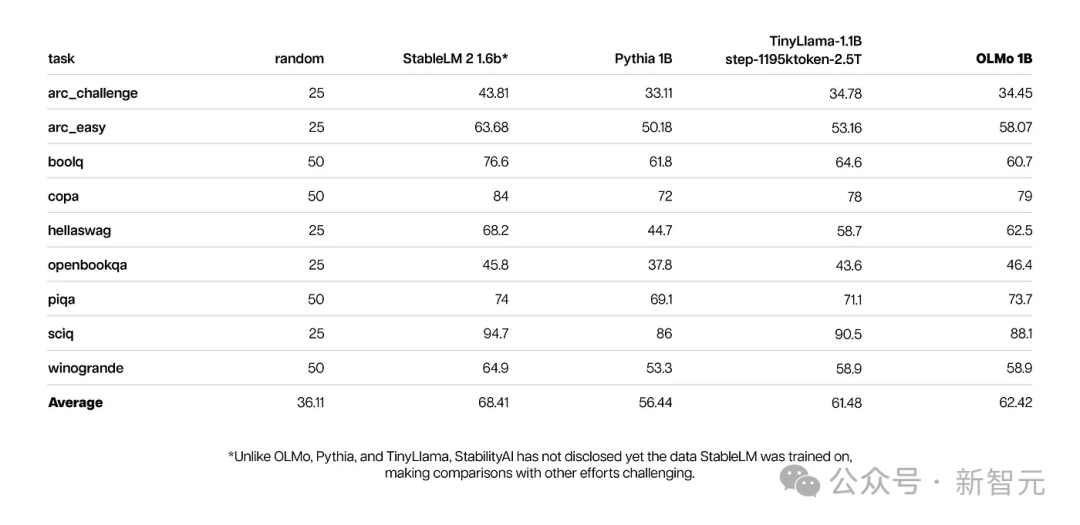
研究者らは、Allen AI Institute の Paloma、ベンチマーク、およびアクセス可能なチェックポイントを使用して、言語を予測するモデルの能力とモデル サイズ要因との関係を分析しました。 (トレーニングされたトークンの数など)。
OLMo-7B は主流モデルと同等の性能を持っていることがわかります。このうち、1 バイトあたりのビット数 (Bits per Byte) は小さいほど優れています。
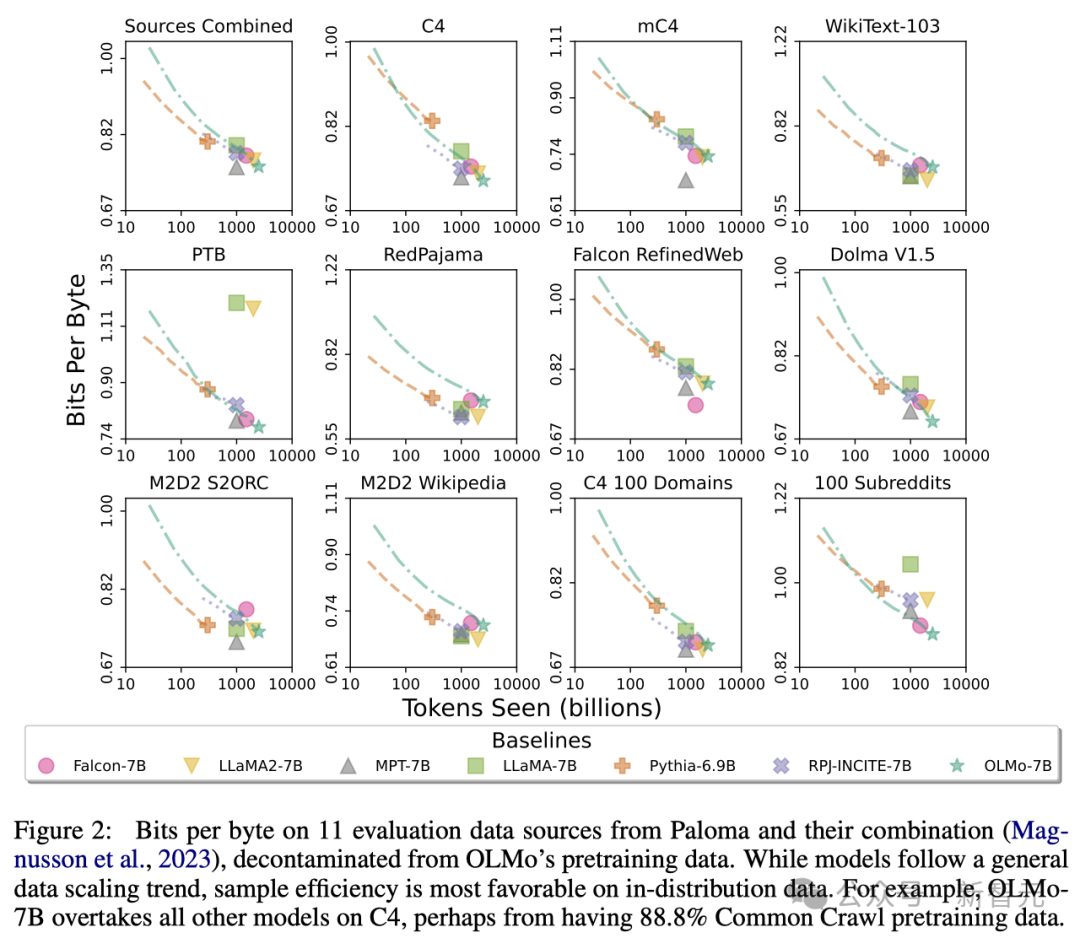
これらの分析を通じて、研究者らは、さまざまなデータ ソースを処理するモデルの効率が大きく異なり、主にモデルのトレーニング データに依存することを発見しました。データの類似性と評価。
特に、OLMo-7B は、主に Common Crawl (C4 など) に基づくデータ ソースで優れたパフォーマンスを発揮します。
ただし、OLMo-7B は、WikiText-103、M2D2 S2ORC、M2D2 Wikipedia など、Web スクレイピング テキストとほとんど関係のないデータ ソースでは他のモデルよりも効率が低くなります。
RedPajama の評価も同様の傾向を反映しています。おそらく、その 7 つのフィールドのうち 2 つだけが Common Crawl から派生しており、パロマの各データ ソースの各フィールドの評価には同じ重みが与えられているためです。
Wikipedia や arXiv 論文などの厳選されたデータ ソースが提供する異種データは、Web スクレイピング テキストよりもはるかに少ないことを考慮すると、事前トレーニング データセットが拡大し続ける中、これらの理解を維持することで、効率的な言語配布が可能になります。より困難。
モデル アーキテクチャに関して、チームはデコーダのみの Transformer アーキテクチャに基づいており、PaLM とLlama で使用される SwiGLU アクティベーション関数、Rotated Position Embedding (RoPE) の導入、GPT-NeoX-20B のバイト ペア エンコーディング (BPE) ベースのトークナイザーの改良により、モデル出力内の個人を特定できる情報が削減されました。
さらに、モデルの安定性を確保するために、研究者はバイアス項を使用しませんでした (これは PaLM と同じです)。
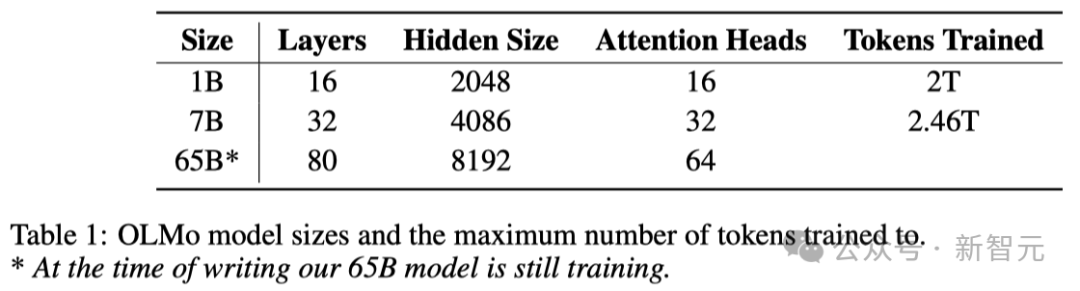
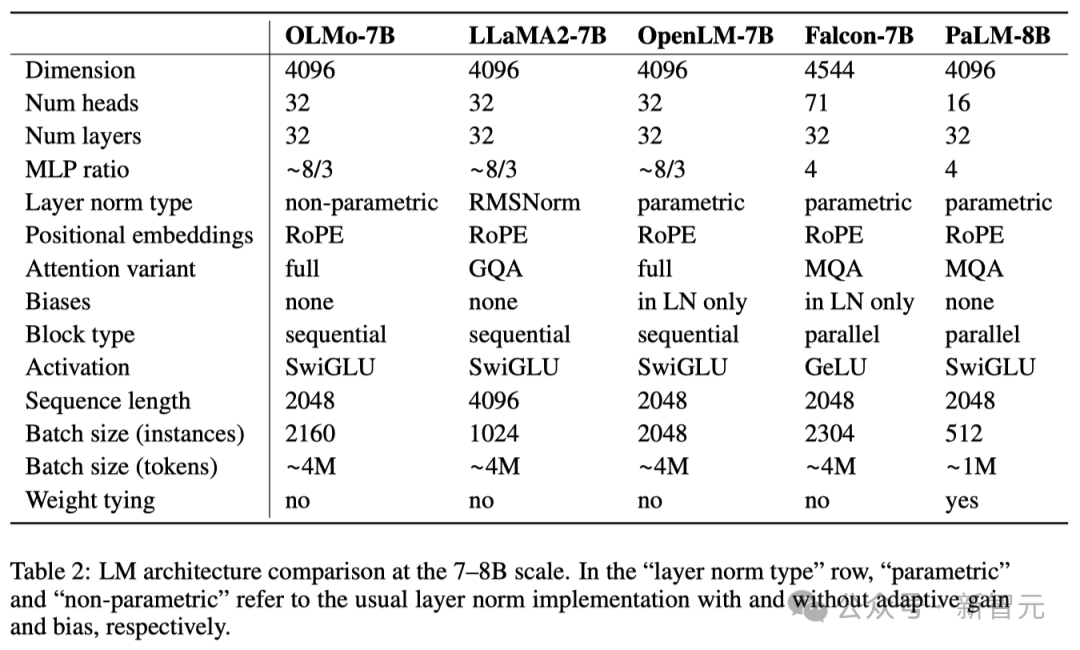
以下の表に示すように、研究者は 1B と 7B の 2 つのバージョンをリリースしており、65B バージョンも間もなく発売する予定です。
以下の表は、同様の規模の他のモデルとの 7B アーキテクチャのパフォーマンスを詳しく示しています。
事前トレーニング データ セット: Dolma
研究者はモデル パラメーターの取得において一定の進歩を遂げましたが、しかし、現在のオープンソース コミュニティにおける事前トレーニング データ セットのオープン性は十分とは言えません。
以前の事前トレーニング データは、モデルのオープン ソースでは (クローズド ソース モデルはもちろんのこと) 公開されていないことがよくあります。
そして、これらのデータに関する文書には、研究を再現したり関連研究を完全に理解するために重要な詳細が十分に欠けていることがよくあります。
この状況により、言語モデルの研究がより困難になります。たとえば、トレーニング データがモデルの機能とその制限にどのような影響を与えるかを理解することが困難になります。
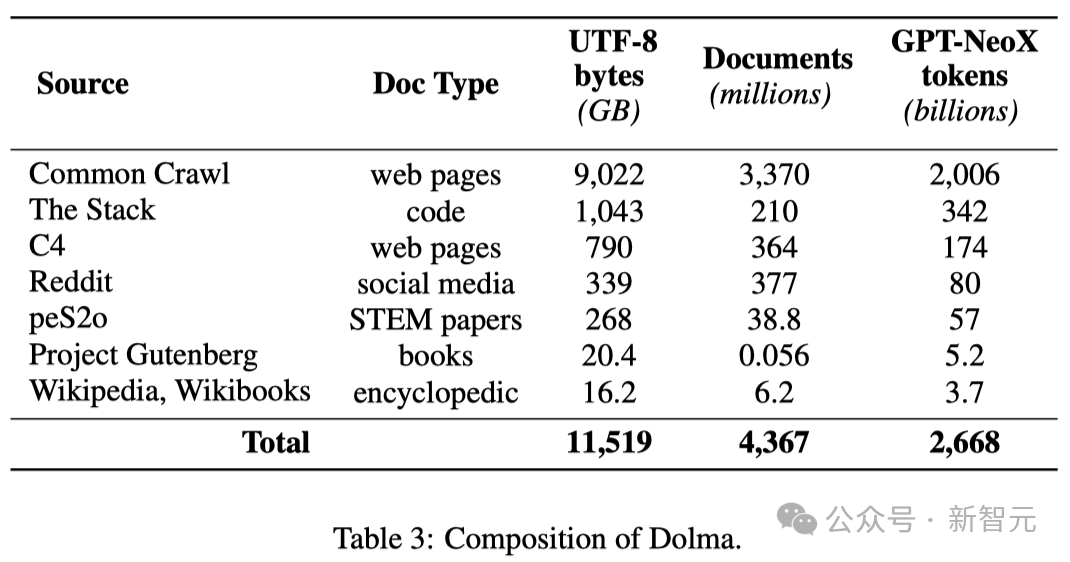
言語モデルの事前トレーニング分野におけるオープン研究を促進するために、研究者は事前トレーニング データセット Dolma を構築し、公開しました。
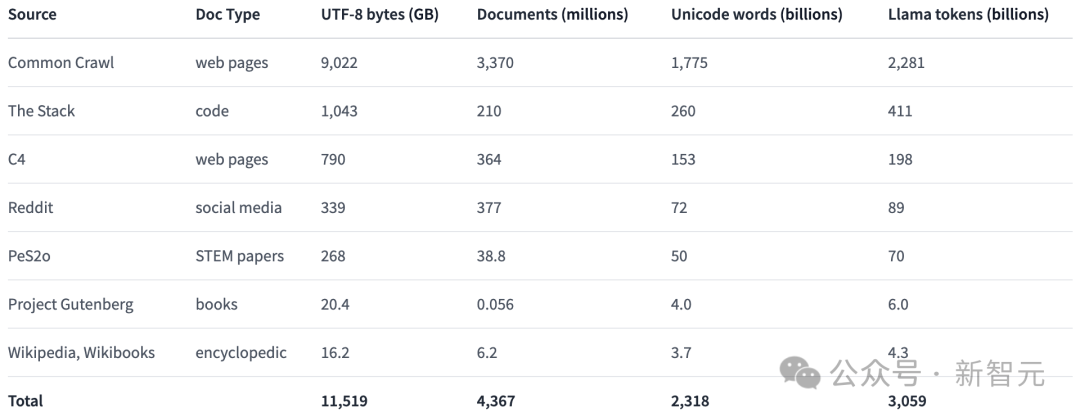
これは、7 つの異なるデータ ソースから取得された 3 兆のトークンを含む、多様なマルチソース コーパスです。
これらのデータ ソースは、大規模な言語モデルの事前トレーニングで一般的に使用される一方で、一般の人々もアクセスできます。
以下の表は、さまざまなデータ ソースからのデータ量の概要を示しています。
Dolma の構築プロセスには、言語フィルタリング、品質フィルタリング、コンテンツ フィルタリング、重複排除、マルチソース ミキシング、トークン化の 6 つのステップが含まれます。
Dolma を照合して最終的に公開するプロセス中、研究者は各データ ソースからのドキュメントが独立していることを確認しました。
彼らはまた、Dolma をさらに研究し、結果を再現し、トレーニング前のコーパスの並べ替えを簡素化するのに役立つ一連の効率的なデータ並べ替えツールをオープンソース化しました。
さらに、研究者はデータセット分析を容易にするために WIMBD ツールをオープンソース化しました。

#ネットワーク データ処理プロセス

コード処理プロセス
トレーニング OLMo分散トレーニング フレームワーク
研究者らは、PyTorch の FSDP フレームワークと ZeRO オプティマイザー戦略を使用してモデルをトレーニングしました。このアプローチでは、モデルの重みとそれに対応するオプティマイザー状態を複数の GPU に分割することで、メモリ使用量を効果的に削減します。
このテクノロジーにより、最大 7B のサイズのモデルを処理する場合、研究者は GPU あたり 4096 トークンのマイクロバッチ サイズを処理して、より効率的なトレーニングを行うことができます。
OLMo-1B および 7B モデルの場合、研究者はグローバル バッチ サイズを約 400 万トークン (2048 個のデータ インスタンス、各インスタンスには 2048 個のトークンのシーケンスが含まれる) に固定しました。
現在トレーニング中の OLMo-65B モデルについて、研究者らはバッチ サイズのウォームアップ戦略を採用し、約 200 万トークン (1024 データ インスタンス) から開始し、その後 100B トークンを追加するたびに開始しました。最終的に約 16M トークン (8192 データ インスタンス) に達するまで、バッチ サイズを 2 倍にします。
モデル トレーニングを高速化するために、研究者らは、FSDP と PyTorch の内部構成を通じて使用される混合精度トレーニング テクノロジを使用しました。アンプモジュールを使用して実装されます。
このメソッドは、トレーニング プロセスの安定性を確保するために、いくつかの主要な計算ステップ (softmax 関数など) が常に最高の精度で実行されるように特別に設計されています。
一方、他のほとんどの計算では、bfloat16 と呼ばれる半精度形式を使用して、メモリ使用量を削減し、計算効率を高めます。
特定の構成では、モデルの重みとオプティマイザーの状態が各 GPU に最大の精度で保存されます。
モデルの順伝播と逆伝播を実行するとき、つまりモデルの出力を計算して重みを更新するときのみ、各 Transformer モジュール内の重みは一時的に bfloat16 に変換されます。フォーマット。
さらに、勾配更新が GPU 間で同期される場合、トレーニングの品質を確保するために最高の精度で更新も実行されます。
オプティマイザー
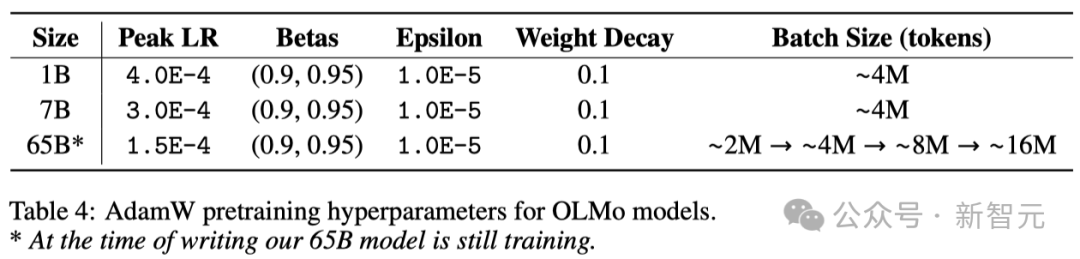
研究者らは、AdamW オプティマイザーを使用してモデル パラメーターを調整しました。
モデルのサイズに関係なく、研究者はトレーニングの最初の 5,000 ステップ (約 210 億トークンの処理) 内で学習率を徐々に高めます。このプロセスは学習率ウォームアップと呼ばれます。
ウォームアップが完了すると、学習率は最大学習率の 10 分の 1 に低下するまで、徐々に直線的に減少します。
さらに、研究者はモデル パラメーターの勾配をクリップして、L1 ノルムの合計が 1.0 を超えないようにします。
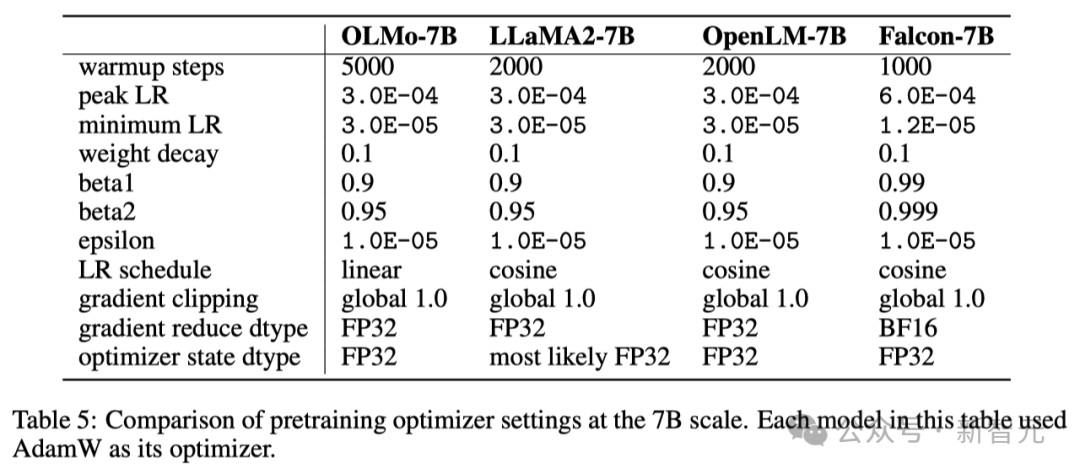
以下の表では、研究者は、AdamW オプティマイザーを使用して、7B モデル スケールでのオプティマイザー構成を他の最近の大規模言語モデルと比較しています。
データセット
研究者たちは、オープン データ セット Dolma の 2T トークン サンプルを使用して、トレーニングデータセット。
研究者らは各文書のトークンを接続し、各文書の末尾に特別な EOS トークンを追加し、これらのトークンを 2048 個のグループに分割してトレーニング サンプルを作成しました。
これらのトレーニング サンプルは、各トレーニング中に同じ方法でランダムにシャッフルされます。研究者らは、誰でも各トレーニング バッチの特定のデータ順序と構成を復元できるツールも提供しています。
研究者がリリースしたすべてのモデルは、少なくとも 1 ラウンド (2T トークン) でトレーニングされています。これらのモデルの一部は、データに対して 2 回目のトレーニングを実行することによってさらにトレーニングされましたが、ランダム シャッフル順序は異なりました。
以前の研究によると、この方法で少量のデータを再利用した場合の影響は最小限です。
NVIDIA と AMD は両方とも「YES」を望んでいます!
コード ベースが NVIDIA と AMD GPU の両方で効率的に実行できるようにするために、研究者はモデルのトレーニングとテスト用に 2 つの異なるクラスターを選択しました。
研究者らは、LUMI スーパーコンピューターを使用して、最大 256 ノードを展開し、各ノードには 4 つの AMD MI250X GPU が搭載されており、各 GPU には 128 GB のメモリと 800 Gbps のデータ転送速度が備わっています。
MosaicML (Databricks) のサポートにより、研究者は 27 ノードを使用しました。各ノードには 8 つの NVIDIA A100 GPU が搭載されており、各 GPU は 40 GB のメモリと 800 Gbps のデータ転送速度を備えています。
研究者らはトレーニング効率を向上させるためにバッチ サイズを微調整しましたが、2T トークンの評価を完了した後、2 つのクラスターのパフォーマンスにほとんど差はありませんでした。
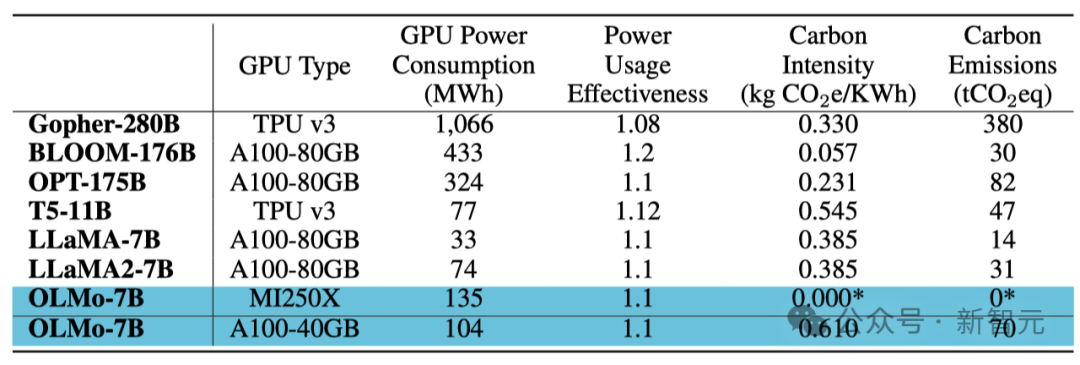
トレーニングのエネルギー消費
概要
これまでのほとんどのモデルとは異なり、モデル 重みと推論コードのモデルは異なります 研究者らは、トレーニング データ、トレーニングおよび評価コード、トレーニング ログ、実験結果、重要な発見、重みとバイアスの記録などを含む OLMo のすべてのコンテンツをオープンソース化しました。
さらに、チームは、命令の最適化とさまざまな種類の強化学習 (RLHF) を通じて OLMo を改善する方法を研究しています。これらの微調整されたコード、データ、および微調整されたモデルもオープンソースになります。
研究者は、OLMo とそのフレームワークの継続的なサポートと開発、オープン言語モデル (LM) の開発の促進、オープンな研究コミュニティの発展の支援に取り組んでいます。この目的を達成するために、研究者らは、OLMo ファミリを充実させるために、さまざまなスケール、複数のモダリティ、データセット、セキュリティ対策、評価方法のモデルをさらに導入する予定です。
彼らは、今後も徹底したオープンソースの取り組みを続けることで、オープンソース研究コミュニティの力を強化し、新たなイノベーションの波を引き起こすことを望んでいます。
チーム紹介
王义中 (王义中)

王义中はワシントンです。同大学のポール G. アレン コンピュータ サイエンス アンド エンジニアリング スクールの博士課程の学生で、Hannaneh Hajishirzi 氏と Noah Smith 氏が指導しています。同時に、アレン人工知能研究所で非常勤研究インターンも務めています。
以前は、Meta AI、Microsoft Research、Baidu NLP でインターンをしていました。以前は北京大学で修士号を取得し、上海交通大学で学士号を取得しました。
彼の研究方向は、自然言語処理、機械学習、大規模言語モデル (LLM) です。
#- LLM の適応性: 指示に従うことができるモデルをより効率的に構築および評価するにはどうすればよいでしょうか?これらのモデルを微調整する際にはどのような要素を考慮する必要がありますか?また、それらはモデルの一般化可能性にどのような影響を与えるのでしょうか?どのタイプの監視が効果的かつ拡張可能ですか?
#- LLM の継続学習: 事前トレーニングと微調整の境界はどこですか?どのようなアーキテクチャと学習戦略により、LLM は事前トレーニング後にも進化し続けることができますか?モデル内の既存の知識は新しく学習した知識とどのように相互作用するのでしょうか?#- 大規模合成データの応用: 今日、生成モデルがデータを迅速に生成するとき、このデータはモデル開発、さらにはインターネットや社会全体にどのような影響を与えるのでしょうか?多様で高品質なデータを大規模に生成できるようにするにはどうすればよいでしょうか?このデータを人間が生成したデータと区別できるでしょうか?
Yuling Gu
 Yuling Gu は、アレン人工知能研究所の Aristo チームのメンバーです。 (AI2) 研究者。
Yuling Gu は、アレン人工知能研究所の Aristo チームのメンバーです。 (AI2) 研究者。
2020 年に、彼女はニューヨーク大学 (NYU) で学士号を取得しました。彼女はコンピューター サイエンスの専攻に加えて、言語学、心理学、哲学を組み合わせた学際的な専攻である言語と心も副専攻しました。その後、彼女はワシントン大学 (UW) で修士号を取得しました。
彼女は、機械学習テクノロジーと認知科学理論の統合と応用に熱意を持っています。
以上が史上初の 100% オープンソースの大規模モデルが登場!コード/重み/データセット/トレーニングプロセス全体の記録破りの開示、AMDがトレーニング可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7543
7543
 15
1381
52
83
11
21
87
15
1381
52
83
11
21
87

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
