

Nature サブジャーナルに掲載された、ウォータールー大学のチームが「量子コンピューター + 大規模言語モデル」の現在と将来についてコメント

今日の量子コンピューティング デバイスをシミュレートする際の重要な課題の 1 つは、量子ビット間の複雑な相関関係を学習してエンコードする能力です。機械学習言語モデルに基づいた新興テクノロジーは、量子状態を学習する独自の能力を実証しました。
最近、ウォータールー大学の研究者らは、「Nature Computational Science」に「量子シミュレーションのための言語モデル」というタイトルの展望記事を発表し、量子コンピューターの構築における言語モデルの役割を強調しました。この点における重要な貢献を明らかにし、量子の優位性をめぐる将来の競争における潜在的な役割を探ります。この記事では、量子コンピューティングの分野における言語モデルの独自の価値に焦点を当て、量子システムの複雑さと精度に対処するために言語モデルを使用できることに注目します。研究者らは、言語モデルを使用することで、量子アルゴリズムのパフォーマンスをよりよく理解して最適化でき、量子コンピューターの開発に新しいアイデアを提供できると考えています。この記事はまた、量子の優位性をめぐる競争における言語モデルの潜在的な役割を強調し、言語モデルは量子コンピューターの開発を加速するのに役立ち、実用的な問題の解決で成果が期待できると主張しています。
論文リンク: https://www.nature.com/articles/s43588-023-00578-0
量子コンピューターは成熟し始めており、そして最近、多くのデバイスが量子の利点を持っていると主張しています。機械学習技術の急速な台頭など、古典的コンピューティング機能の継続的な開発により、量子戦略と古典的戦略の間の相互作用をめぐる多くの刺激的なシナリオが生まれました。機械学習が量子コンピューティング スタックに急速に統合され続けるにつれて、将来、量子テクノロジーを強力な方法で変革できるだろうかという疑問が生じます。
現在の量子コンピューターが直面している主な課題の 1 つは、量子の状態を学習することです。最近出現した生成モデルは、量子状態の学習の問題を解決するための 2 つの一般的な戦略を提供します。
図: 自然言語およびその他の分野の生成モデル。 (出典: 論文) 
まず、量子コンピューターの出力を表すデータセットを使用してデータ駆動型学習を実行することで、従来の最尤法を採用できます。第 2 に、量子ビット間の相互作用の知識を利用して代理損失関数を定義する、量子状態に対する物理学的なアプローチを使用できます。
いずれの場合も、量子ビット数 N の増加により、量子状態空間 (ヒルベルト空間) のサイズが指数関数的に増大します。これは次元の呪いと呼ばれます。したがって、拡張モデルで量子状態を表現するために必要なパラメーターの数と、最適なパラメーター値を見つける計算効率に大きな課題があります。この問題を克服するには、人工ニューラル ネットワーク生成モデルが非常に適したソリューションです。
言語モデルは、非常に複雑な言語の問題を解決するための強力なアーキテクチャとなっている、特に有望な生成モデルです。スケーラビリティにより、量子コンピューティングの問題にも適しています。現在、産業用言語モデルが数兆のパラメータ範囲に移行しているため、拡張量子コンピューティングなどのアプリケーションや、量子物質、材料、およびその基本的な理論的理解など、物理学において同様の大規模モデルが何を達成できるのか疑問に思うのは自然なことです。装置。
図: 量子物理学の問題とその変分公式。 (出典: 論文) 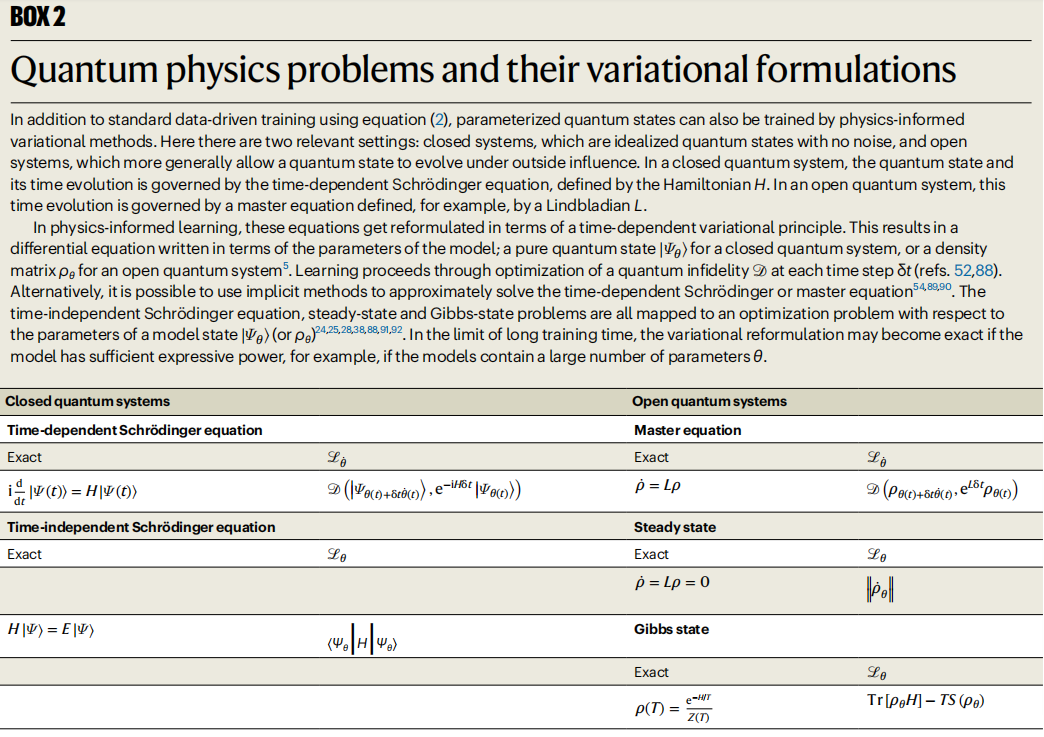
量子コンピューティングの自己回帰モデル
言語モデルは、自然言語データから確率分布を推測するように設計された生成モデルです。生成モデルのタスクは、コーパス内に出現する単語間の確率的関係を学習し、一度に 1 トークンずつ新しいフレーズを生成できるようにすることです。主な困難は、単語間の複雑な依存関係をすべてモデル化することにあります。
同様の課題が量子コンピューターにも当てはまります。量子コンピューターでは、もつれなどの非局所的な相関が量子ビット間に非常に重要な依存関係を引き起こす可能性があります。したがって、興味深い問題は、産業界で開発された強力な自己回帰アーキテクチャを、強相関量子システムの問題解決にも適用できるかどうかです。
図: テキストと量子ビット シーケンスの自己回帰戦略。 (出典: 論文)
RNN 波動関数
RNN は、RNN ユニットの出力が前の出力に依存するような反復接続を含むニューラル ネットワークです。 2018 年以来、RNN の使用は急速に拡大し、量子システムを理解する上で最も困難なさまざまなタスクをカバーするようになりました。
これらのタスクに適した RNN の主な利点は、本質的に非局所的な量子もつれなど、量子ビット間の非常に重要な相関を学習してエンコードできることです。
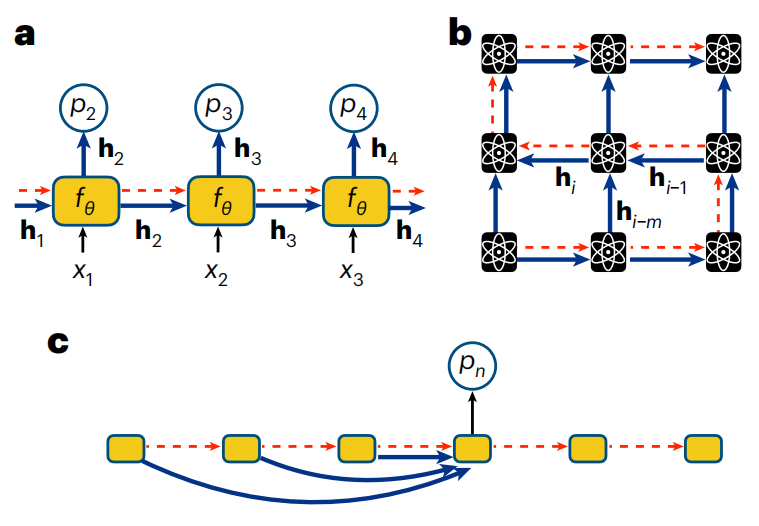
#図: 量子ビット シーケンスの RNN。 (出典: 論文)
物理学者は、量子コンピューティングに関連するさまざまな革新的な用途に RNN を使用してきました。 RNN は、量子ビット測定から量子状態を再構築するタスクに使用されてきました。 RNN は、量子システムのダイナミクスをシミュレートするために使用することもできます。これは、量子コンピューティングの最も有望なアプリケーションの 1 つと考えられており、したがって、量子の利点を定義する上で重要なタスクです。 RNN は、フォールトトレラントな量子コンピューターの開発における重要な要素であるニューラル誤り訂正デコーダーを構築するための戦略として使用されてきました。さらに、RNN はデータ駆動型および物理学にヒントを得た最適化を活用できるため、量子シミュレーションでの革新的な用途が増えています。
物理学者コミュニティは、量子優位の時代に直面するますます複雑になる計算タスクを達成するために RNN を使用することを期待して、積極的に RNN を開発し続けています。 RNN の多くの量子タスクにおけるテンソル ネットワークとの計算上の競争力は、量子ビット測定データの値を活用する本来の能力と相まって、RNN が量子コンピューター上で複雑なタスクをシミュレートする際に将来的にも重要な役割を果たし続けることを示唆しています。
Transformer Quantum State
#RNN は長年にわたって自然言語タスクで大きな成功を収めてきましたが、最近では次の理由により業界での地位を失いつつあります。 Transformer へ セルフアテンション メカニズムの影に隠れていますが、Transformer は、今日の大規模言語モデル (LLM) エンコーダ/デコーダ アーキテクチャの重要なコンポーネントです。
トランスフォーマーのスケーリングの成功と、トランスフォーマーが言語タスクで示す自明ではない創発現象によって提起される重要な疑問は、長い間物理学者を魅了してきました。物理学者にとって、スケーリングの達成は主要な目標です。量子コンピューティングの研究。
本質的に、Transformer は単純な自己回帰モデルです。ただし、隠れベクトルを通じて相関関係を暗黙的にエンコードする RNN とは異なり、Transformer モデルによって出力される条件付き分布は、自己回帰特性に関するシーケンス内の他のすべての変数に明示的に依存します。これは、因果的遮蔽の自己注意メカニズムによって実現されます。
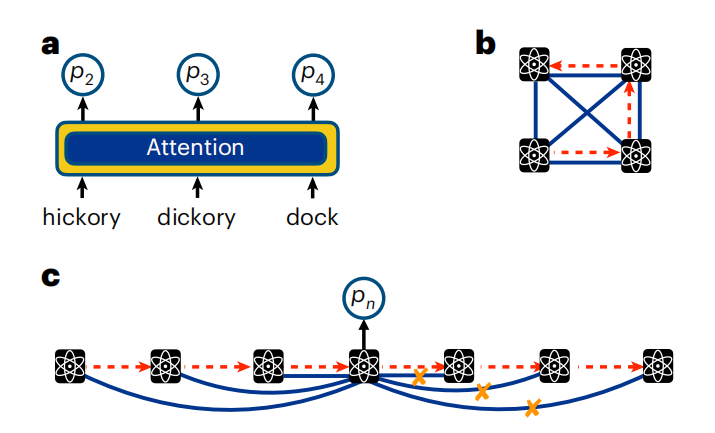
図: テキストと量子ビットのシーケンスに注目してください。 (出典: 論文)
言語データと同様、量子システムにおけるアテンションは、量子ビットの測定値を取得し、それらを一連のパラメーター化された関数を通じて変換することによって計算されます。これらのパラメーター化された関数の束をトレーニングすることにより、Transformer は量子ビット間の依存関係を学習できます。アテンション メカニズムを使用すると、(RNN の場合のように) 伝達される隠れ状態の幾何学形状を量子ビットの物理的配置に関連付ける必要がなくなります。
このアーキテクチャを活用することで、数十億または数兆のパラメータを持つトランスフォーマーをトレーニングできます。
データ駆動型学習と物理学に触発された学習を組み合わせたハイブリッド 2 段階最適化は、現世代の量子コンピューターにとって重要であり、Transformer は今日の量子コンピューターで発生する問題を軽減することが実証されています。不完全な出力データのエラーは、将来真にフォールト トレラントなハードウェアの開発をサポートする堅牢なエラー修正プロトコルの基礎となる可能性があります。
量子物理学におけるトランスフォーマーに関する研究の範囲は急速に拡大し続けていますが、一連の興味深い疑問が残っています。
量子コンピューティングのための言語モデルの将来
物理学者による言語モデルの研究は短期間しか行われていませんが、言語モデルは将来性を示しています。量子コンピューティングへの応用により、この分野の幅広い課題に対して目覚ましい成功を収めています。これらの結果は、多くの有望な将来の研究の方向性を示しています。
量子物理学における言語モデルのもう 1 つの重要な使用例は、データではなく、ハミルトニアンまたはリンドブラディアンの基本的な量子ビット相互作用の知識を通じて最適化する能力に由来します。
最後,語言模型透過資料驅動和變分驅動最佳化的結合,開啟了混合訓練的新領域。這些新興的策略為減少錯誤提供了新的途徑,並顯示對變異模擬的強大改進。由於生成模型最近已被改編為量子糾錯解碼器,混合訓練可能為未來實現容錯量子電腦的聖杯邁出了重要一步。這表明,量子電腦和在其輸出中訓練的語言模型之間即將出現良性循環。
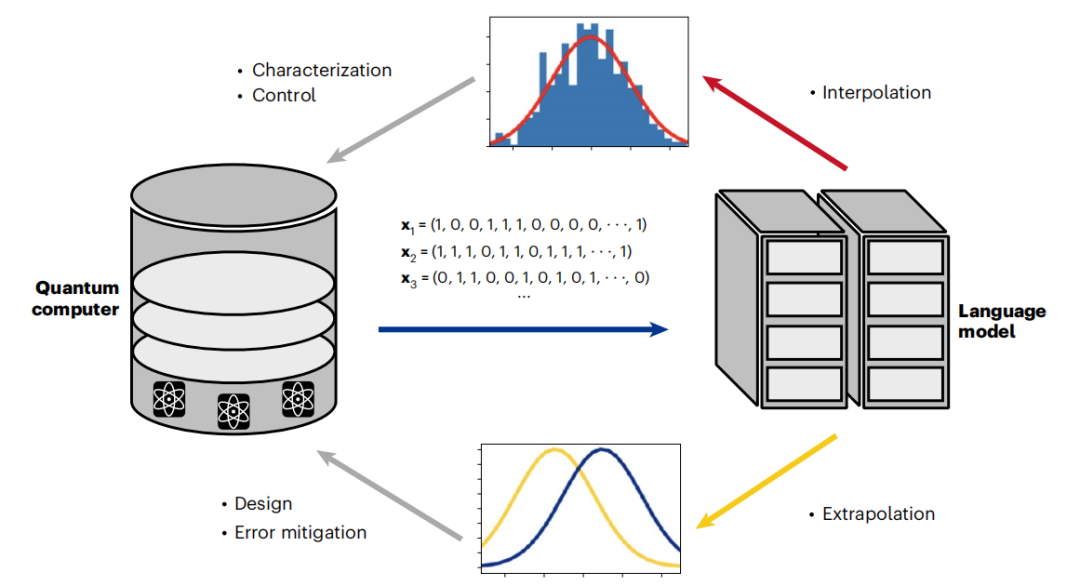
圖示:語言模型透過良性循環實現量子運算的擴展。 (資料來源:論文)
展望未來,將語言模型領域與量子運算連結起來的最令人興奮的機會在於它們展示規模和湧現的能力。
如今,隨著 LLM 湧現特性的展示,一個新的領域已經被突破,提出了許多引人注目的問題。如果有足夠的訓練數據,LLM 是否能夠學習量子電腦的數位副本?控制堆疊中包含語言模型,將如何影響量子電腦的特性與設計?如果尺度夠大,LLM 能否顯示超導等宏觀量子現象的出現?
當理論學家思考這些問題時,實驗和計算物理學家已經開始認真地將語言模型應用於當今量子電腦的設計、表徵和控制中。當我們跨越量子優勢的門檻時,我們也進入了擴展語言模型的新領域。雖然很難預測量子電腦和 LLM 的碰撞將如何展開,但顯而易見的是,這些技術相互作用所帶來的根本轉變已經開始。
以上がNature サブジャーナルに掲載された、ウォータールー大学のチームが「量子コンピューター + 大規模言語モデル」の現在と将来についてコメントの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7494
7494
 15
1377
52
77
11
19
48
15
1377
52
77
11
19
48

 mysqlデータテーブルフィールド操作ガイドの追加、変更、削除方法ガイド
Apr 11, 2025 pm 05:42 PM
mysqlデータテーブルフィールド操作ガイドの追加、変更、削除方法ガイド
Apr 11, 2025 pm 05:42 PM
MySQLのフィールド操作ガイド:フィールドを追加、変更、削除します。フィールドを追加:table table_nameを変更するcolumn_name data_type [not null] [default default_value] [プライマリキー] [auto_increment]フィールドの変更:column_name data_typeを変更するcolumn_name data_type [not null] [default default_value] [プライマリキー]
 Oracleデータベーステーブルの整合性の制約は何ですか?
Apr 11, 2025 pm 03:42 PM
Oracleデータベーステーブルの整合性の制約は何ですか?
Apr 11, 2025 pm 03:42 PM
Oracleデータベースの整合性の制約により、以下を含むデータの精度を確保できます。NULL:NULL値は禁止されています。一意:単一のヌル値を許可する一意性を保証します。一次キー:一次キーの制約、一意を強化し、ヌル値を禁止します。外部キー:テーブル間の関係を維持する、外部キーはプライマリテーブルのプライマリキーを参照します。チェック:条件に応じて列の値を制限します。
 MySQLデータベースのネストされたクエリインスタンスの詳細な説明
Apr 11, 2025 pm 05:48 PM
MySQLデータベースのネストされたクエリインスタンスの詳細な説明
Apr 11, 2025 pm 05:48 PM
ネストされたクエリは、1つのクエリに別のクエリを含める方法です。これらは主に、複雑な条件を満たし、複数のテーブルを関連付け、要約値または統計情報を計算するデータを取得するために使用されます。例には、平均賃金を超える従業員を見つけること、特定のカテゴリの注文を見つけること、各製品の総注文量の計算が含まれます。ネストされたクエリを書くときは、サブ征服を書き、結果を外側のクエリ(エイリアスまたは条項として参照)に書き込み、クエリパフォーマンスを最適化する必要があります(インデックスを使用)。
 Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
この記事では、Debian SystemsでApacheのログ形式をカスタマイズする方法について説明します。次の手順では、構成プロセスをガイドします。ステップ1:Apache構成ファイルにアクセスするDebianシステムのメインApache構成ファイルは、/etc/apache2/apache2.confまたは/etc/apache2/httpd.confにあります。次のコマンドを使用してルートアクセス許可を使用して構成ファイルを開きます。sudonano/etc/apache2/apache2.confまたはsudonano/etc/apache2/httpd.confステップ2:検索または検索または
 オラクルは何をしますか
Apr 11, 2025 pm 06:06 PM
オラクルは何をしますか
Apr 11, 2025 pm 06:06 PM
Oracleは、世界最大のデータベース管理システム(DBMS)ソフトウェア会社です。その主な製品には、次の機能が含まれます。リレーショナルデータベース管理システム(Oracle Database)開発ツール(Oracle Apex、Oracle Visual Builder)ミドルウェア(Oracle Weblogic Server、Oracle SOA Suite)Cloud Service(Oracle Cloud Infrastructure)Cloud ServiceおよびBusiness Intelligence(Oracle Analytics Cloud、Oracle Essbase)Blockchain(Oracle Blockchain Pla
 Oracleデータベース用のシステム開発ツールは何ですか?
Apr 11, 2025 pm 03:45 PM
Oracleデータベース用のシステム開発ツールは何ですか?
Apr 11, 2025 pm 03:45 PM
Oracleデータベース開発ツールには、SQL*Plusだけでなく、次のツールも含まれます。PL/SQL開発者:有料ツール、コード編集、デバッグ、およびデータベース管理機能を提供し、PL/SQLコードの強調表示と自動完成をサポートします。 Toad for Oracle:PL/SQL開発者のような機能を提供する有料ツール、および追加のデータベースパフォーマンス監視とSQL最適化機能。 SQL開発者:Oracleの公式無料ツール。コード編集、デバッグ、データベース管理の基本的な機能を提供し、予算が限られている開発者に適しています。 Datagrip:ジェットブレイン
 MongoDBインデックスを並べ替える方法
Apr 12, 2025 am 08:45 AM
MongoDBインデックスを並べ替える方法
Apr 12, 2025 am 08:45 AM
ソートインデックスは、特定のフィールドによるコレクション内のドキュメントのソートを許可するMongoDBインデックスの一種です。ソートインデックスを作成すると、追加のソート操作なしでクエリ結果をすばやく並べ替えることができます。利点には、クイックソート、オーバーライドクエリ、およびオンデマンドソートが含まれます。構文はdb.collection.createIndex({field:< sort and gt;})、where< sort and> IS 1(昇順)または-1(降順注文)です。また、複数のフィールドをソートするマルチフィールドソートインデックスを作成することもできます。
 Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログは、メモリリークの問題を診断するための鍵です。 Tomcatログを分析することにより、メモリの使用状況とガベージコレクション(GC)の動作に関する洞察を得ることができ、メモリリークを効果的に見つけて解決できます。 Tomcatログを使用してメモリリークをトラブルシューティングする方法は次のとおりです。1。GCログ分析最初に、詳細なGCロギングを有効にします。 Tomcatの起動パラメーターに次のJVMオプションを追加します:-xx:printgcdetails-xx:printgcdateStamps-xloggc:gc.logこれらのパラメーターは、GCタイプ、リサイクルオブジェクトサイズ、時間などの情報を含む詳細なGCログ(GC.log)を生成します。分析GC.LOG
