

Linux パイプと FIFO アプリケーション ノート

######概要######
パイプの最も一般的な場所は、次のようなシェル内です。 リーリー 上記のコマンドを実行するために、シェルは ls
とwc
をそれぞれ実行する 2 つのプロセスを作成します (fork() と exec を介して)。 ( ) 完了)、次のように:
上の図からわかるように、パイプラインは一連の水道管とみなすことができ、データをあるプロセスから別のプロセスに流すことができます。これがパイプラインの名前の由来でもあります。
上の図からわかるように、2 つのプロセスがパイプに接続されているため、書き込みプロセス
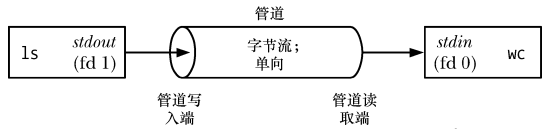 はその標準出力 (ファイル記述子は 1) を受信パイプの書き込みセグメントに接続します。 , 読み取りプロセス
はその標準出力 (ファイル記述子は 1) を受信パイプの書き込みセグメントに接続します。 , 読み取りプロセス wc
は、標準入力 (ファイル記述子 0) をパイプの読み取り側に接続します。実際、これら 2 つのプロセスはパイプの存在を認識しておらず、標準のファイル記述子からデータを読み書きするだけです。シェルがその作業を実行する必要があります。
パイプはバイト ストリームです
パイプからデータを読み取るプロセスは、書き込みプロセスによってパイプに書き込まれたブロックのサイズに関係なく、任意のサイズのブロックを読み取ることができます。
パイプを介して渡されるデータはシーケンシャルです。パイプから読み取られたバイトの順序は、パイプに書き込まれた順序とまったく同じです。パイプ内でlseek()
を使用してランダム化することはできませんデータへのアクセス- 個別メッセージの概念をパイプラインに実装する必要がある場合は、この作業をアプリケーションで完了する必要があります。これは可能ですが、その必要がある場合は、メッセージ キューやデータグラム ソケットなどの他の IPC メカニズムを使用することをお勧めします。
-
パイプからデータを読み取る
パイプの書き込み側が閉じている場合、パイプからデータを読み取るプロセスは、パイプ内の残りのデータをすべて読み取った後、ファイルの終わりを確認します(つまり、
read() は 0 を返します)。 。
パイプは一方通行です
パイプライン内のデータの送信方向は一方向です。パイプの一端は書き込みに使用され、もう一端は読み取りに使用されます。
他の一部の UNIX 実装、特に System V リリース 4 から進化したものでは、パイプは双方向です (いわゆるストリーム パイプ)。双方向パイプはどの UNIX 標準でも規定されていないため、双方向パイプを提供する実装であっても、このセマンティクスに依存しないことが最善です。代わりに、UNIX ドメイン ストリーム ソケット ペア (socketpair() システム コールで作成) を使用できます。これは標準の双方向通信メカニズムを提供し、そのセマンティクスはストリーム パイプと同等です。
PIPE_BUF バイト以下の書き込みがアトミックであることを保証します
複数のプロセスが同じパイプに書き込む場合、一度に書き込むデータ量が PIPE_BUF バイトを超えなければ、書き込まれたデータが互いに混在しないことが保証されます。
SUSv3 では、PIPE_BUF が少なくとも _POSIX_PIPE_BUF(512) である必要があります。実装では、PIPE_BUF (<limits.h></limits.h> 内) を定義するか、fpathconf(fd,_PC_PIPE_BUF) への呼び出しを許可して、アトミックな書き込み操作の実際の上限を返す必要があります (SHOULD)。 PIPE_BUF は UNIX 実装によって異なります。たとえば、FreeBSD 6.0 ではその値は 512 バイト、Tru64 5.1 ではその値は 4096 バイト、Solaris 8 ではその値は 5120 バイトです。 Linux では、PIPE_BUF の値は 4096 です。
-
パイプに書き込まれるデータ ブロックのサイズが PIPE_BUF バイトを超えると、カーネルは送信のためにデータをいくつかの小さなフラグメントに分割し、リーダーがパイプからのデータを消費するときに後続のデータを追加することがあります (
write()##) #すべてのデータがパイプに書き込まれるまで呼び出しはブロックされます)
1 つのプロセスのみがパイプにデータを書き込む場合 (通常の場合)、PIPE_BUF の値は重要ではありません - ただし、複数の書き込みプロセスがある場合、大きなデータ ブロックの書き込みは任意のサイズのセグメント (PIPE_BUF バイトよりも小さい可能性があります) に分割され、他のプロセスによって書き込まれたデータと重複する可能性があります
write() は必要に応じてブロックされます。書き込まれたデータが PIPE_BUF バイトより大きい場合、write() はパイプ全体を満たすためにできるだけ多くのデータを転送し、読み取りプロセスによってパイプからデータが削除されるまでブロックします。このようなブロッキング write() がシグナル ハンドラーによって中断された場合、呼び出しはブロックが解除され、パイプに正常に転送されたバイト数が返されますが、これは書き込み要求されたバイト数よりも少なくなります。入力されたバイト数 (いわゆる部分書き込み)。
パイプの容量には制限があります
パイプは実際にはカーネル メモリ内に維持されるバッファですが、このバッファの記憶容量には制限があります。パイプがいっぱいになると、リーダーがパイプからデータを削除するまで、その後のパイプへの書き込みはブロックされます。SUSv3 はパイプラインのストレージ容量を指定しません。 2.6.11 より前の Linux カーネルでは、パイプのストレージ容量はシステム ページ サイズと一致します (たとえば、x86-32 では 4096 バイト)。Linux 2.6.11 以降では、パイプのストレージ容量は 65,536 です。バイト。他の UNIX 実装上のパイプのストレージ機能は異なる場合があります。
一般来讲,一个应用程序无需知道管道的实际存储能力。如果需要防止写者进程阻塞,那么从管道中读取数据的进程应该被设计成以尽可能快的速度从管道中读取数据。
创建和使用管道
#include int pipe(int fd[2]);
-
pipe()创建一个新管道 -
成功的调用在数组
fd中返回两个打开的文件描述符,一个表示管道的读取端fd[0],一个表示管道的写入端fd[1]
调用 pipe() 函数时,首先在内核中开辟一块缓冲区用于通信,它有一个读端和一个写端,然后通过 fd 参数传出给用户进程两个文件描述符,fd[0] 指向管道的读端,fd[1] 指向管道的写段。
不要用 fd[0] 写数据,也不要用 fd[1] 读数据,其行为未定义的,但在有些系统上可能会返回 -1 表示调用失败。数据只能从 fd[0] 中读取,数据也只能写入到fd[1],不能倒过来。
与所有文件描述符一样,可以使用 read() 和 write() 系统调用来在管道上执行 IO,一旦向管道的写入端写入数据之后立即就能从管道的读取端读取数据。管道上的 read() 调用会读取的数据量为所请求的字节数与管道中当前存在的字节数两者之间的较小值。当管道为空时,读取操作阻塞。
パイプ上で stdio 関数 (printf()、scanf() など) を使用することもできます。最初に fdopen()# を使用するだけで済みます。 ## を取得するには、filedes の記述子に対応するファイル ストリームだけで十分です。ただし、これを行う場合は、stdio バッファリングの問題に対処する必要があります。
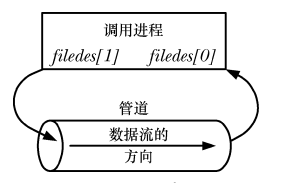 パイプは、血縁関係でのプロセス内通信に使用できます (子プロセスは親プロセスのファイル記述子のコピーを継承します):
パイプは、血縁関係でのプロセス内通信に使用できます (子プロセスは親プロセスのファイル記述子のコピーを継承します):
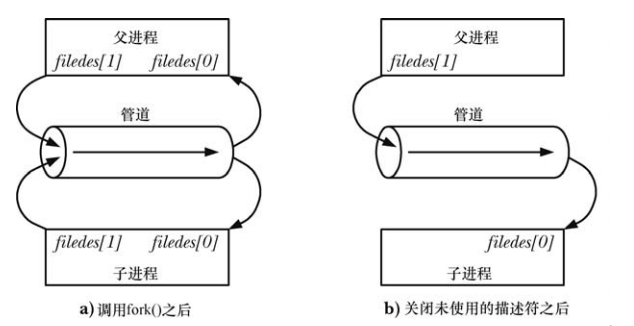 単一のパイプを全二重として使用したり、対応する読み取り/書き込みエンドを閉じずに半二重として使用したりすることはお勧めできません。デッドロックが発生する可能性があります。2 つのプロセスが試行すると、デッドロックが発生する可能性があります。パイプからデータを読み取る場合、どのプロセスが最初に正常に読み取るかを判断することは不可能であり、その結果、2 つのプロセスがデータを求めて競合します。この競合状態の発生を防ぐには、何らかの同期メカニズムを使用する必要があります。この時点で、デッドロックの問題を考慮する必要があります。両方のプロセスが空のパイプからデータを読み取ろうとしたり、満杯のパイプにデータを書き込もうとしたりするとデッドロックが発生する可能性があるためです。
単一のパイプを全二重として使用したり、対応する読み取り/書き込みエンドを閉じずに半二重として使用したりすることはお勧めできません。デッドロックが発生する可能性があります。2 つのプロセスが試行すると、デッドロックが発生する可能性があります。パイプからデータを読み取る場合、どのプロセスが最初に正常に読み取るかを判断することは不可能であり、その結果、2 つのプロセスがデータを求めて競合します。この競合状態の発生を防ぐには、何らかの同期メカニズムを使用する必要があります。この時点で、デッドロックの問題を考慮する必要があります。両方のプロセスが空のパイプからデータを読み取ろうとしたり、満杯のパイプにデータを書き込もうとしたりするとデッドロックが発生する可能性があるためです。 双方向のデータ フローが必要な場合は、各方向に 1 つずつ、2 つのパイプを作成できます。
パイプを使用すると、関連するプロセス間の通信が可能になります
実際、パイプは、パイプが、子プロセス。
未使用のパイプ ファイル記述子を閉じます
未使用のパイプ ファイル記述子を閉じることは、プロセスがファイル記述子の制限を使い果たさないようにするためだけではありません。
パイプからデータを読み取るプロセスは、保持しているパイプの書き込み記述子を閉じるため、他のプロセスが出力を完了して書き込み記述子を閉じると、リーダーはファイルの終わりを確認できるようになります。一方、読み取りプロセスがパイプの書き込み側を閉じない場合、他のプロセスが書き込み記述子を閉じた後、リーダーはパイプ内のすべてのデータを読み取ったとしてもファイルの終わりを認識できません。現時点では、カーネルは少なくとも 1 つのパイプ書き込み記述子が開いていることを認識しているため、read()
がブロックされます。
当一个进程视图向一个管道中写入数据但没有任何进程拥有该管道的打开着的读取描述符时,内核会向写入进程发送一个 SIGPIPE 信号,默认情况下,这个信号将会杀死进程,但进程可以选择忽略或者设置信号处理器,这样 write() 将因为 EPIPE 错误而失败。收到 SIGPIPE 信号和得到 EPIPE 错误对于标识管道的状态是有意义的,这就是为什么需要关闭管道的未使用读取描述符的原因。如果写入进程没有关闭管道的读取端,那么即使在其他进程已经关闭了管道的读取端之后,写入进程仍然能够向管道写入数据,最后写入进程会将数据充满整个管道,后续的写入请求会将永远阻塞。
使用管道连接过滤器
当管道被创建之后,为管道的两端分配的文件描述符是可用描述符中数值最小的两个,由于通常情况下,进程已经使用了描述符 0,1,2,因此会为管道分配一些数值更大的描述符。如果需要使用管道连接两个过滤器(即从 stdin 读取和写入到 stdout),使得一个程序的标准输出被重定向到管道中,就需要采用复制文件描述符技术。
int pfd[2]; pipe(pfd); close(STDOUT_FILENO); dup2(pfd[1],STDOUT_FILENO);
上面这些调用的最终结果是进程的标准输出被绑定到管道的写入端,而对应的一组调用可以用来将进程的标准的输入绑定到管道的读取端上。
通过管道与 shell 命令进行通信: popen()
#include FILE *popen (const char *command, const char *mode);
-
pipe()和close()是最底层的系统调用,它的进一步封装是popen()和pclose() -
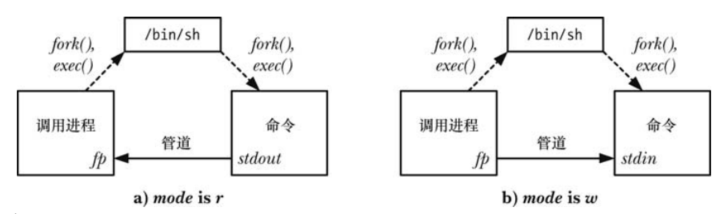
popen()函数创建了一个管道,然后创建了一个子进程来执行 shell,而 shell 又创建了一个子进程来执行command字符串 -
mode参数是一个字符串: -
-
它确定调用进程是从管道中读取数据(
mode是r)还是将数据写入到管道中(mode是w) -
由于管道是向的,因此无法在执行的
command中进行双向通信 -
mode的取值确定了所执行的命令的标准输出是连接到管道的写入端还是将其标准输入连接到管道的读取端
-
它确定调用进程是从管道中读取数据(
-
popen()在成功时会返回可供stdio库函数使用的文件流指针。当发生错误时,popen()会返回NULL并设置errno以标示出发生错误的原因 -
在
popen()调用之后,调用进程使用管道来读取command的输出或使用管道向其发送输入。与使用pipe()创建的管道一样,当从管道中读取数据时,调用进程在command关闭管道的写入端之后会看到文件结束;当向管道写入数据时,如果command已经关闭了管道的读取端,那么调用进程就会收到SIGPIPE信号并得到EPIPE错误
#include int pclose ( FILE * stream);
-
一旦IO结束之后可以使用
pclose()函数关闭管道并等待子进程中的 shell 终止(不应该使用fclose()函数,因为它不会等待子进程。) -
pclose()成功すると、子プロセス内のシェルの終了ステータス (つまり、シェルがシグナルによって強制終了されない限り、シェルによって実行された最後のコマンドの終了ステータス) が返されます。 -
system()と同様に、シェルが実行できない場合、pclose()は_exit(127)# を呼び出すことによって、子プロセスのシェルと同様の値を返します。 ## 同じを終了するには# 別のエラーが発生した場合、 pclose() - は -1 を返します。発生する可能性のあるエラーの 1 つは、終了ステータスを取得できないことです。
が system() と同じである必要があります。つまり、内部的にはwaitpid () シグナル ハンドラーによって通話が中断された後、通話を自動的に再開します。
system()
popen() は特権プロセスでは決して使用しないでください。
popen
-
利点: Linux ではすべてのパラメータ展開がシェルによって行われます。したがって、
commandコマンドを開始する前に、プログラムはまずcommand文字列を分析するためにシェルを開始します。さまざまなシェル拡張 (ワイルドカードなど) を使用できるため、## を使用できるようになります。 #popen()非常に複雑なシェル コマンドの呼び出し
欠点: - popen()
呼び出しごとに、要求されたプログラムだけでなくシェルも起動する必要があります。つまり、各popen()は 2 つのプロセスを開始します。从效率和资源的角度看,<code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin: 0 2px;font-family: Operator Mono, Consolas, Monaco, Menlo, monospace;color: #009688">popen()函数的调用比正常方式要慢一些
pipe()` VS `popen()
-
pipe()是一个底层调用,popen()是一个高级的函数 -
pipe()单纯的创建管道,而popen()创建管道的同时fork()子进程 -
popen()在两个进程中传递数据时需要调用 shell 来解释请求命令;pipe()在两个进程中传递数据不需要启动 shell 来解释请求命令,同时提供了对读写数据的更多控制(popen()必须时 shell 命令,pipe()则无硬性要求) -
popen()函数是基于文件流(FILE)工作的,而pipe()是基于文件描述符工作的,所以在使用pipe()后,数据必须要用底层的read()和write()调用来读取和发送
管道和 stdio 缓冲
由于 popen() 调用返回的文件流指针没有引用一个终端,因此 stdio 库会对这种流应用块缓冲。这意味着当 mode 的值为 w 来调用 popen() 时,默认情况下只有当 stdio 缓冲区被充满或者使用 pclose() 关闭了管道之后才会被发送到管道的另一端的子进程。在很多情况下,这种处理方式是不存在问题的。ただし、子プロセスがパイプからデータをすぐに受信できるようにする必要がある場合は、fflush() を定期的に呼び出すか、setbuf(fp, NULL) 呼び出しを使用して、標準入出力バッファリングを無効にします。この手法は、pipe() システム コールを使用してパイプを作成し、その後 fdopen() を使用してパイプの書き込み側に対応する stdio ストリームを取得するときにも使用できます
popen() を呼び出すプロセスがパイプから読み取っている場合 (つまり、mode が r である場合)、物事はそれほど単純ではありません。この場合、子プロセスが stdio ライブラリを使用している場合、明示的に fflush() または setbuf() を呼び出さない限り、その出力は子プロセスによってのみ埋められます。 fclose() が呼び出されるまで、呼び出しプロセスは stdio バッファを使用できません。 (pipe() を使用して作成されたパイプから読み取り、もう一方の端に書き込むプロセスが stdio ライブラリを使用している場合にも、同じルールが適用されます。) これが問題である場合、考えられる対策は次のとおりです。子プロセスで実行されているプログラムのソース コードを変更して setbuf() または fflush() への呼び出しを含めることができない限り、取得できるものは比較的限られています。
ソース コードを変更できない場合は、疑似ターミナルを使用してパイプを置き換えることができます。擬似端末は、プロセスに対して端末として見える IPC チャネルです。その結果、stdio ライブラリはバッファ内のデータを 1 行ずつ出力します。
名前付きパイプ (FIFO)
上記のパイプラインはプロセス間通信を実現しますが、いくつかの制限があります:
- 匿名パイプは、血のつながりのあるプロセス間でのみ通信できます
- 1 つのプロセスが書き込みを可能にし、別のプロセスが読み取りを可能にすることしかできません。両方を同時に行う必要がある場合は、パイプを再度開く必要があります
任意の 2 つのプロセス間の通信を可能にするために、名前付きパイプ (名前付きパイプまたは FIFO) が提案されています。
- FIFO 与管道的区别:FIFO 在文件系统中拥有一个名称,并且其打开方式与打开一个普通文件一样,能够实现任何两个进程之间通信。而匿名管道对于文件系统是不可见的,它仅限于在父子进程之间的通信
-
一旦打开了 FIFO,就能在它上面使用与操作管道和其他文件的系统调用一样的 IO 系统调用
read(),write(),close()。与管道一样,FIFO 也有一个写入端和读取端,并且总是遵循先进先出的原则,即第一个进来的数据会第一个被读走 - 与管道一样,当所有引用 FIFO 的描述符都关闭之后,所有未被读取的数据都将被丢弃
-
使用
mkfifo命令可以在 shell 中创建一个 FIFO:
mkfifo [-m mode] pathname
-
pathname是创建的 FIFO 的名称,-m选项指定权限mode,其工作方式与chmod命令一样 -
fstat()和stat()函数会在stat结构的st_mode字段返回S_IFIFO,使用ls -l列出文件时,FIFO 文件在第一列的类型为p,ls -F会在 FIFO 路径名后面附加管道符|
#include #include int mkfifo(const char *pathname,mode_t mode);
-
mode参数指定了新 FIFO 的权限,这些权限会按照进程的umask值来取掩码 - 一旦创建了 FIFO,任何进程都能够打开它,只要它通过常规的文件权限检测
-
使用 FIFO 时唯一明智的做法是在两端分别设置一个读取进程和一个写入进程。这样在默认情况下,打开一个 FIFO 以便读取数据(
open() O_RDONLY标记)将会阻塞直到另一个进程打开 FIFO 以写入数(open() O_WRONLY标记)为止。相应地,打开一个 FIFO 以写入数据将会阻塞直到另一个进程打开 FIFO 以读取数据为止。换句话说,打开一个 FIFO 会同步读取进程和写入进程。如果一个 FIFO 的另一端已经打开(可能是因为一对进程已经打开了 FIFO 的两端),那么open()调用会立即成功。
在大多数 Unix 实现上(包含 Linux),当打开一个 FIFO 时可以通过指定 O_RDWR 标记来绕过打开 FIFO 时的阻塞行为。这样,open() 会立即返回,但无法使用返回的文件描述符在 FIFO 上读取和写入数据。这种做法破坏了 FIFO 的 IO 模型,SUSv3 明确指出以 O_RDWR 标记打开一个 FIFO 的结果是未知的,因此出于可移植性的原因,开发人员不应该使用这项技术。对于那些需要避免在打开 FIFO 时发生阻塞的需求,open() 的 O_NONBLOCK 标记提供了一种标准化的方法来完成这个任务:
open(const char *path, O_RDONLY | O_NONBLOCK); open(const char *path, O_WRONLY | O_NONBLOCK);
在打开一个 FIFO 时避免使用 O_RDWR 标记还有另外一个原因,当采用那种方式调用 open() 之后,调用进程在从返回的文件描述符中读取数据时永远都不会看到文件结束,因为永远都至少存在一个文件描述符被打开着以等待数据被写入 FIFO,即进程从中读取数据的那个描述符。
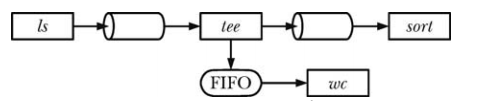
使用 FIFO 和 tee 创建双重管道线
shell 管道线的其中一个特征是它们是线性的,管道线中的每个进程都能读取前一个进程产生的数据并将数据发送到其后一个进程中,使用 FIFO 就能够在管道线中创建子进程,这样除了将一个进程的输出发送给管道线中的后面一个进程之外,还可以复制进程的输出并将数据发送到另一个进程中,要完成这个任务就需要使用 tee 命令,它将其从标准输入中读取到的数据复制两份并输出:一份写入标准输出,另一份写入到通过命令行参数指定的文件中。
mkfifo myfifo wc -l
非阻塞 IO
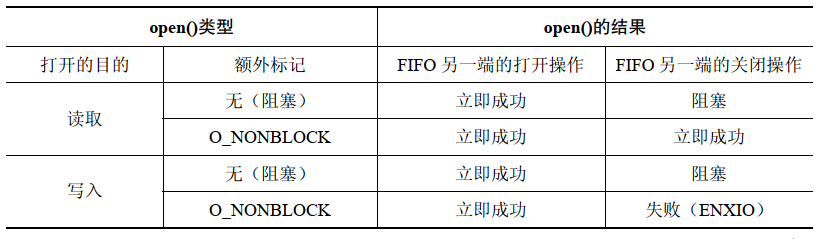
当一个进程打开一个 FIFO 的一端时,如果 FIFO 的另一端还没有被打开,那么该进程会被阻塞。但有些时候阻塞并不是期望的行为,而这可以通过在调用 open() 时指定 O_NONBLOCK 标记来实现。
如果 FIFO 的另一端已经被打开,那么 O_NONBLOCK 对 open() 调用不会产生任何影响,它会像往常一样立即成功地打开 FIFO。只有当 FIFO 的另一端还没有被打开的时候 O_NONBLOCK 标记才会起作用,而具体产生的影响则依赖于打开 FIFO 是用于读取还是用于写入的:
-
如果打开 FIFO 是为了读取,并且 FIFO 的写入端当前已经被打开,那么
open()调用会立即成功(就像 FIFO 的另一端已经被打开一样) -
如果打开 FIFO 是为了写入,并且还没有打开 FIFO 的另一端来读取数据,那么
open()调用会失败,并将errno设置为ENXIO
为读取而打开 FIFO 和为写入而打开 FIFO 时 O_NONBLOCK 标记所起的作用不同是有原因的。当 FIFO 的另一个端没有写者时打开一个 FIFO 以便读取数据是没有问题的,因为任何试图从 FIFO 读取数据的操作都不会返回任何数据。但当试图向没有读者的 FIFO 中写入数据时将会导致 SIGPIPE 信号的产生以及 write() 返回 EPIPE 错误。
在 FIFO 上调用 open() 的语义总结如下:
在打开一个 FIFO 时,使用 O_NOBLOCK 标记存在两个目的:
-
它允许单个进程打开一个 FIFO 的两端,这个进程首先会在打开 FIFO 时指定
O_NOBLOCK标记以便读取数据,接着打开 FIFO 以便写入数据 - 它防止打开两个 FIFO 的进程之间产生死锁
例如,下面的情况将会发生死锁:

非阻塞 read() 和 write()
O_NONBLOCK 标记不仅会影响 open() 的语义,而且还会影响——因为在打开的文件描述中这个标记仍然被设置着——后续的 read() 和 write() 调用的语义。
有些时候需要修改一个已经打开的 FIFO(或另一种类型的文件)的 O_NONBLOCK 标记的状态,具体存在这个需求的场景包括以下几种:
-
使用
O_NONBLOCK打开了一个 FIFO 但需要后续的read()和write()在阻塞模式下运行 -
需要启用从
pipe()返回的一个文件描述符的非阻塞模式。更一般地,可能需要更改从除open()调用之外的其他调用中,如每个由 shell 运行的新程序中自动被打开的三个标准描述符的其中一个或socket()返回的文件描述符,取得的任意文件描述符的非阻塞状态 -
出于一些应用程序的特殊需求,需要切换一个文件描述符的
O_NONBLOCK设置的开启和关闭状态
当碰到上面的需求时可以使用 fcntl() 启用或禁用打开着的文件的 O_NONBLOCK 状态标记。通过下面的代码(忽略的错误检查)可以启用这个标记:
int flags; flags = fcntl(fd, F_GETFL); flags != O_NONBLOCK; fcntl(fd, F_SETFL, flags);
通过下面的代码可以禁用这个标记:
flags = fcntl(fd, F_GETFL); flags &= ~O_NONBLOCK; fcntl(fd, F_SETFL, flags);
管道和 FIFO 中 read() 和 write() 的语义
FIFO 上的 read() 操作:
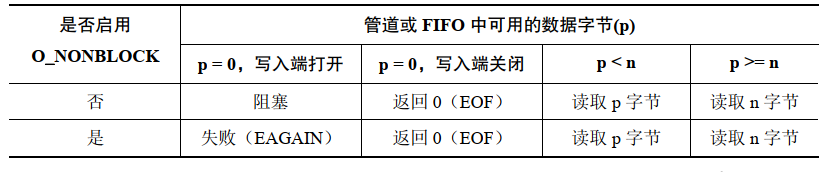
只有当没有数据并且写入端没有被打开时阻塞和非阻塞读取之间才存在差别。在这种情况下,普通的 read() 会被阻塞,而非阻塞 read() 会失败并返回 EAGAIN 错误。
当 O_NONBLOCK 标记与 PIPE_BUF 限制共同起作用时 O_NONBLOCK 标记对象管道或 FIFO 写入数据的影响会变得复杂。
FIFO 上的 write() 操作:
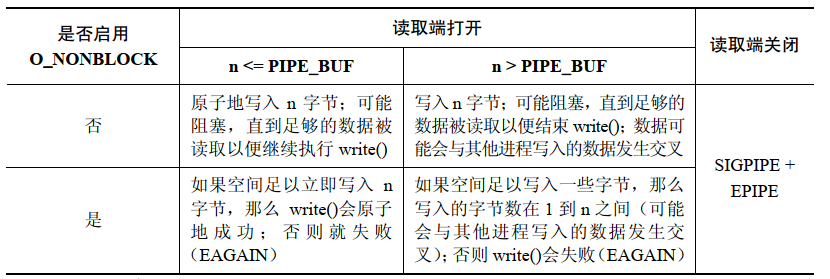
-
O_NONBLOCKフラグにより、データをすぐに転送できない場合、パイプまたは FIFO のwrite()が失敗します (エラーEAGAINが発生します)。これは、PIPE_BUFバイトを書き込んだ後、パイプまたは FIFO に十分なスペースがない場合、カーネルが操作をすぐに完了できず、部分的な書き込みができないため、write()が失敗することを意味します。PIPE_BUFバイト # を超えない書き込み操作のアトミック性要件に違反することなく実行される
-
一度に書き込まれるデータ量が
PIPE_BUFバイトを超える場合、書き込み操作をアトミックにする必要はありません。したがって、write()は、パイプまたは FIFO を満たすためにできるだけ多くのバイトを転送 (部分的に書き込み) します。この場合、write()から返される値は実際に転送されたバイト数であり、呼び出し元は残りのバイトの書き込みを再試行する必要があります。しかし、パイプまたは FIFO がいっぱいで 1 バイトも転送できない場合、write()は失敗し、EAGAINエラー を返します。
以上がLinux パイプと FIFO アプリケーション ノートの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7333
7333
 9
1627
14
1351
46
1262
25
1209
29
9
1627
14
1351
46
1262
25
1209
29

 Deepseek Webバージョンの入り口Deepseek公式ウェブサイトの入り口
Feb 19, 2025 pm 04:54 PM
Deepseek Webバージョンの入り口Deepseek公式ウェブサイトの入り口
Feb 19, 2025 pm 04:54 PM
DeepSeekは、Webバージョンと公式Webサイトの2つのアクセス方法を提供する強力なインテリジェント検索および分析ツールです。 Webバージョンは便利で効率的であり、公式ウェブサイトは包括的な製品情報、ダウンロードリソース、サポートサービスを提供できます。個人であろうと企業ユーザーであろうと、DeepSeekを通じて大規模なデータを簡単に取得および分析して、仕事の効率を向上させ、意思決定を支援し、イノベーションを促進することができます。
 DeepSeekをインストールする方法
Feb 19, 2025 pm 05:48 PM
DeepSeekをインストールする方法
Feb 19, 2025 pm 05:48 PM
DeepSeekをインストールするには、Dockerコンテナ(最も便利な場合は、互換性について心配する必要はありません)を使用して、事前コンパイルパッケージ(Windowsユーザー向け)を使用してソースからコンパイル(経験豊富な開発者向け)を含む多くの方法があります。公式文書は慎重に文書化され、不必要なトラブルを避けるために完全に準備します。
 Bitget公式ウェブサイトのインストール(2025初心者ガイド)
Feb 21, 2025 pm 08:42 PM
Bitget公式ウェブサイトのインストール(2025初心者ガイド)
Feb 21, 2025 pm 08:42 PM
Bitgetは、スポット取引、契約取引、デリバティブなど、さまざまな取引サービスを提供する暗号通貨交換です。 2018年に設立されたこのExchangeは、シンガポールに本社を置き、安全で信頼性の高い取引プラットフォームをユーザーに提供することに取り組んでいます。 Bitgetは、BTC/USDT、ETH/USDT、XRP/USDTなど、さまざまな取引ペアを提供しています。さらに、この取引所はセキュリティと流動性について評判があり、プレミアム注文タイプ、レバレッジド取引、24時間年中無休のカスタマーサポートなど、さまざまな機能を提供します。
 OUYI OKXインストールパッケージが直接含まれています
Feb 21, 2025 pm 08:00 PM
OUYI OKXインストールパッケージが直接含まれています
Feb 21, 2025 pm 08:00 PM
世界をリードするデジタル資産交換であるOuyi Okxは、安全で便利な取引体験を提供するために、公式のインストールパッケージを開始しました。 OUYIのOKXインストールパッケージは、ブラウザに直接インストールでき、ユーザー向けの安定した効率的な取引プラットフォームを作成できます。インストールプロセスは、簡単で理解しやすいです。
 gate.ioインストールパッケージを無料で入手してください
Feb 21, 2025 pm 08:21 PM
gate.ioインストールパッケージを無料で入手してください
Feb 21, 2025 pm 08:21 PM
Gate.ioは、インストールパッケージをダウンロードしてデバイスにインストールすることで使用できる人気のある暗号通貨交換です。インストールパッケージを取得する手順は次のとおりです。Gate.ioの公式Webサイトにアクセスし、「ダウンロード」をクリックし、対応するオペレーティングシステム(Windows、Mac、またはLinux)を選択し、インストールパッケージをコンピューターにダウンロードします。スムーズなインストールを確保するために、インストール中に一時的にウイルス対策ソフトウェアまたはファイアウォールを一時的に無効にすることをお勧めします。完了後、ユーザーはGATE.IOアカウントを作成して使用を開始する必要があります。
 OUYI Exchangeダウンロード公式ポータル
Feb 21, 2025 pm 07:51 PM
OUYI Exchangeダウンロード公式ポータル
Feb 21, 2025 pm 07:51 PM
OKXとしても知られるOUYIは、世界をリードする暗号通貨取引プラットフォームです。この記事では、OUYIの公式インストールパッケージのダウンロードポータルを提供します。これにより、ユーザーはさまざまなデバイスにOUYIクライアントをインストールすることが容易になります。このインストールパッケージは、Windows、Mac、Android、およびiOSシステムをサポートします。インストールが完了した後、ユーザーはOUYIアカウントに登録またはログインし、暗号通貨の取引を開始し、プラットフォームが提供するその他のサービスを楽しむことができます。
 gate.io公式ウェブサイト登録インストールパッケージリンク
Feb 21, 2025 pm 08:15 PM
gate.io公式ウェブサイト登録インストールパッケージリンク
Feb 21, 2025 pm 08:15 PM
Gate.ioは、広範なトークン選択、低い取引手数料、ユーザーフレンドリーなインターフェイスで知られる高く評価されている暗号通貨取引プラットフォームです。高度なセキュリティ機能と優れたカスタマーサービスにより、Gate.ioは、信頼できる便利な暗号通貨取引環境をトレーダーに提供します。 gate.ioに参加する場合は、リンクをクリックして公式登録インストールパッケージをダウンロードして、暗号通貨取引の旅を開始してください。
 ubuntuにnginxでphpmyadminをインストールする方法は?
Feb 07, 2025 am 11:12 AM
ubuntuにnginxでphpmyadminをインストールする方法は?
Feb 07, 2025 am 11:12 AM
このチュートリアルは、既存のApacheサーバーに沿って、潜在的にubuntuシステムにnginxとphpmyAdminをインストールおよび構成することをガイドします。 Nginxのセットアップをカバーし、Apacheとの潜在的なポートの競合を解決し、Mariadbをインストールします(
