

現在IT担当者が担っているのは、企業における運用サポートの役割の特徴。運用保守管理は皆さん大変だと思いますが、日々面倒で高負荷、高リスクの運用保守業務を担っていますが、事業計画に関しては「透明化」されています。そしてキャリア開発。業界には「お金を使うだけの人には発言権はない」「」という冗談めいた格言があります。
#AI ラージ モデル アプリケーションの普及に伴い、データは企業の重要な資産であり競争力の中核となっています。近年、企業データの規模は急速に拡大しており、ペタバイトレベルから数百ペタバイトレベルまで指数関数的に増加しています。データの種類も、データベースに基づく構造化データから、ファイル、ログ、ビデオなどに基づく半構造化データおよび非構造化データへと徐々に進化してきました。ビジネス部門のニーズを満たすには、データ ストレージを分類して図書館のようにアクセスできる必要があり、より安全で信頼性の高いストレージ方法も必要です。
IT 担当者はもはや、IT リソースの構築と管理、および機器の安定性の確保を担当する単なる受動的な役割を担うものではありません。
IT 担当者の新たな使命は、高品質のデータ サービスを提供し、データを使いやすくし、ビジネス部門を支援することに進化しました。データを上手に活用しましょう!

インフラストラクチャ管理の場合、業界で一般的なアプローチは、AIOps テクノロジーを使用して、専門家によるシステムと知識を通じて、面倒な手動の日常運用と保守をツールを使用した自動実行に変えることです。 インテリジェントな機能マップなどを使用すると、システムの危険性を事前に発見し、障害を自動的に修復できます。生成 AI テクノロジーの普及後、最近ではインテリジェントな顧客サービスや対話型の運用保守などの新しいアプリケーションが登場しています。
##データ管理の観点では、業界には I#nformatica## などの大手企業があります。 #、IBM など。代表的なプロフェッショナル DataOps ソフトウェア サプライヤーは、データ統合、データ ラベリング、データ分析、データ最適化、データ マーケット、その他の機能をサポートし、データ アナリスト、BI アナリスト、データ サイエンティスト、その他のビジネス チームにサービスを提供します。 著者の調査によると、ほとんどの企業ではインフラストラクチャの運用保守管理とデータ管理が現在分離されており、異なるチームによって管理されていることがわかりました。責任があり、ツール プラットフォーム間には効果的な連携がありません。ビジネスデータはストレージなどのITインフラに保存されており、統合する必要がありますが、実際の管理は両者の乖離が大きく、両チームの言語すら一致していないため、通常、いくつかのデメリットが生じます。
1
) 異なるソースからのデータ: 異なるチームに属し、異なるツールを使用するため、ビジネス チームは通常、元のデータを分析および処理するために、ETL およびその他の方法を通じてデータ管理プラットフォームにコピーをコピーします。これはストレージ容量の無駄を引き起こすだけでなく、データの不整合や適時でないデータ更新などの問題を引き起こし、データ分析の精度に影響を与えます。2
) 地域を越えたコラボレーションの難しさ: 現在、エンタープライズ データ センターは複数の都市に展開されています。現在、レプリケーションは主に DataOps ソフトウェアを介してホスト層で実行されますが、このデータ送信方法は非効率であるだけでなく、送信プロセス中にセキュリティ、コンプライアンス、プライバシーなどの重大な危険が潜んでいます。3
) 不十分なシステム最適化: 現在、最適化は通常、インフラストラクチャ リソースの利用に基づいています。データのレイアウトを認識して全体的な最適化を達成することは不可能 データ ストレージのコストは依然として高止まりしており、限られた予算の増加とデータ スケールの指数関数的な増加との間の矛盾が、企業のデータ資産の蓄積を制限する主要な矛盾となっています。IT担当者よ、「インフラ」と「データ」の2つのチャネルを開拓し、デジタルインテリジェンスのフライホイールをスタートさせよう
まず、グローバル ファイルの統合ビューを実現します。
グローバル ファイル システム、統合メタデータ管理、その他のテクノロジを利用して、さまざまな地域、さまざまなデータ センター、さまざまな種類の機器にあるデータの統一されたグローバル ビューを形成します。これに基づいて、ホット、ウォーム、コールド、繰り返し、有効期限などの次元に応じてグローバルな最適化戦略を策定し、ストレージ デバイスに送信して実行することで、グローバルな最適化を実現できます。ストレージ層のレプリケーションに基づく圧縮や暗号化などのテクノロジーは、通常、数十倍の高速データ移動を実現し、効率とセキュリティの両方を保証できます。2 番目に、大量の非構造化データからデータ ディレクトリを自動的に生成します。 メタデータ、拡張メタデータなどを通じてデータ ディレクトリ サービスを自動的に生成し、カテゴリごとにデータを効率的に管理します。ビジネスチームは、干し草の山の中の針のように手動でデータを検索するのではなく、カタログに基づいて、分析および処理の条件を満たすデータを自動的に抽出できます。著者の調査によると、AI 認識アルゴリズムによるデータ アノテーションのテクノロジは比較的成熟しているため、オープン フレームワークを使用して、さまざまなシナリオに合わせて AI アルゴリズムを統合し、ファイル コンテンツを自動的に分析して多様なタグを形成し、それらを強化されたメタデータとして使用して、パフォーマンスを向上させることができます。データ管理機能。 同時に、データがデバイス間を流れるときは、データ主権やコンプライアンス プライバシーなどの問題について特別な考慮を払う必要があります。 ストレージ デバイス内のデータは、自動的に分類、プライバシーの格付け、分散化、ドメインへの分割などが行われる必要があります。管理ソフトウェアは、データのアクセス、使用、フロー、その他のポリシーを統一して管理し、漏洩を回避する必要があります。機密情報と個人データの保護、これらは将来のデータ要素取引シナリオの基本要件になります。たとえば、データがストレージ デバイスから流出する場合、ポリシー要件を満たしているかどうかを判断するために、まずコンプライアンス、個人プライバシーなどを確認する必要があります。そうしないと、企業は重大な法的および規制上のリスクに直面することになります。 #リファレンス アーキテクチャは次のとおりです: によると、著者は調査を実施し、専門家に相談した結果、Huawei Storage や NetApp などの業界の大手ストレージ ベンダーが、統合ストレージとデータ管理のための製品ソリューションをリリースしていることを発見しました。今後さらに多くのベンダーがこれをサポートすると信じています。未来。 機器やデータは両手でつかみ、両手の力が強くなければなりません。 AI時代ではIT人材はより重要な役割を果たすことができます。 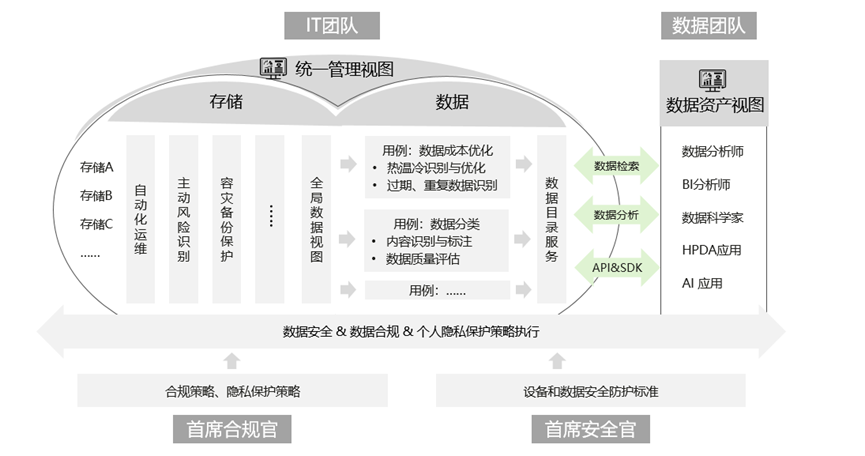
以上が新しい IT の運用と保守管理には、インフラストラクチャとデータの両方に多大な労力が必要ですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



