

「セマンティックセグメンテーションの最適化と評価」の問題を3つの論文で解決します!ルーベン/清華/オックスフォードなどが共同で新しい手法を提案

セマンティック セグメンテーション モデルを最適化するために一般的に使用される損失関数には、Soft Jaccard 損失、Soft Dice 損失、Soft Tversky 損失などがあります。ただし、これらの損失関数はソフト ラベルと互換性がないため、ラベルの平滑化、知識の蒸留、半教師あり学習、複数のアノテーターなどの一部の重要なトレーニング手法をサポートできません。これらのトレーニング手法は、セマンティック セグメンテーション モデルのパフォーマンスと堅牢性を向上させるために非常に重要であるため、これらのトレーニング手法の適用をサポートするには、損失関数のさらなる研究と最適化が必要です。
一方、セマンティックセグメンテーションの評価指標としてよく使われるのが、mAccやmIoUなどです。ただし、これらの指標はより大きなオブジェクトを優先するため、モデルの安全性能評価に重大な影響を与えます。
これらの問題を解決するために、ルーヴェン大学と清華大学の研究者は最初に JDT 損失を提案しました。 JDT 損失は、Jaccard メトリック損失、ダイス セミメトリック損失、および互換性のある Tversky 損失を含む元の損失関数を微調整したものです。 JDT 損失は、ハード ラベルを処理する場合の元の損失関数と同等であり、ソフト ラベルにも完全に適用できます。この改善により、モデルのトレーニングがより正確かつ安定しました。
研究者らは、ラベルの平滑化、知識の蒸留、半教師あり学習、および複数のアノテーターという 4 つの重要なシナリオで JDT 損失を適用することに成功しました。これらのアプリケーションは、モデルの精度とキャリブレーションを向上させるための JDT 損失の力を実証します。
 写真
写真
紙のリンク: https://arxiv.org/pdf/2302.05666.pdf
 写真
写真
紙のリンク: https://arxiv.org/pdf/2303.16296.pdf
さらに、研究者らはきめ細かい評価指標も提案した。これらのきめ細かい評価メトリクスは、大規模なオブジェクトに対する偏りが少なく、より豊富な統計情報を提供し、モデルとデータセットの監査に貴重な洞察を提供できます。
さらに、研究者らは広範なベンチマーク調査を実施し、単一の指標に基づいていない評価の必要性を強調し、きめ細かい指標の最適化におけるニューラル ネットワーク構造と JDT 損失の重要な役割を発見しました。
 写真
写真
紙のリンク: https://arxiv.org/pdf/2310.19252.pdf
コードリンク: https://github.com/zifuwanggg/JDTLosses
既存の損失関数
Jaccard Index と Dice Score はセットで定義されているため、そうではありません指示可能。それらを微分可能にするために、現在 2 つの一般的なアプローチがあります。1 つは、Soft Jaccard loss (SJL)、Soft Dice loss (SDL)、Soft Tversky など、セットと対応するベクトルの Lp モジュールの間の関係を使用するものです。損失 (STL)。
セットのサイズを対応するベクトルの L1 モジュールとして書き込み、2 つのセットの共通部分を 2 つの対応するベクトルの内積として書き込みます。もう 1 つは、Jaccard Index のサブモジュール プロパティを使用して、Lovasz-Softmax 損失 (LSL) などの集合関数で Lovasz 展開を行うことです。
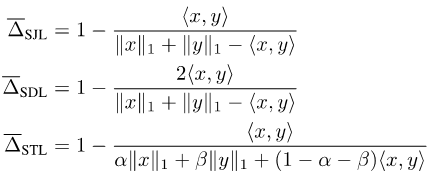 図
図
これらの損失関数は、ニューラル ネットワークの出力 x が連続ベクトルであることを前提としています。 , ラベル y は離散バイナリ ベクトルです。ラベルがソフト ラベルの場合、つまり y が離散バイナリ ベクトルではなく連続ベクトルである場合、これらの損失関数は互換性がなくなります。
SJL を例として、単純な単一ピクセルの状況を考えてみましょう。
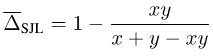 Picture
Picture
y > 0 の場合、SJL は x = 1 のときに最小化され、x = 0 のときに最大化されることがわかります。損失関数は x = y のときに最小化される必要があるため、これは明らかに不合理です。
ソフト ラベルと互換性のある損失関数
元の損失関数をソフト ラベルと互換性のあるものにするためには、2 つの集合の交差と和集合を計算する必要があります。 2 つのセット間の対称的な違いを紹介します。
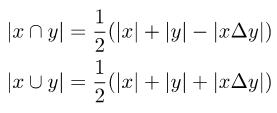 写真
写真
2 つのセットは、2 つの対応するベクトル間の差分の L1 モジュールとして記述することができます:
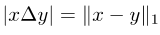 写真
写真
上記をまとめると、JDT 損失が提案されました。これらは、SJL のバリアントである Jaccard Metric loss (JML)、SDL のバリアントである Dice Semimetric loss (DML)、および STL のバリアントである Compare Tversky loss (CTL) です。
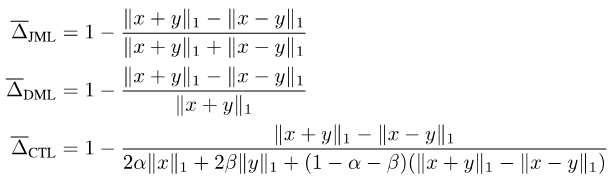 写真
写真
JDT 損失の性質
JDT 損失が原因であることを証明しました。以下のプロパティの一部。
プロパティ 1: JML はメトリックであり、DML はセミメトリックです。
プロパティ 2: y がハード ラベルの場合、JML は SJL と同等、DML は SDL と同等、CTL は STL と同等です。
プロパティ 3: y がソフト ラベルの場合、JML、DML、および CTL はすべてソフト ラベルと互換性があります。つまり、x = y ó f(x, y) = 0 となります。
プロパティ 1 により、これらは Jaccard メトリック損失およびダイス セミメトリック損失とも呼ばれます。プロパティ 2 は、トレーニングにハード ラベルのみが使用される一般的なシナリオでは、JDT 損失を直接使用して、変更を加えることなく既存の損失関数を置き換えることができることを示しています。
JDT loss の使用方法
JDT loss を使用する際に多くの実験を行い、注意点をまとめました。
注 1: 評価指標に基づいて、対応する損失関数を選択します。評価指標が Jaccard Index の場合は JML を選択し、評価指標が Dice Score の場合は DML を選択し、偽陽性と偽陰性に異なる重みを与えたい場合は CTL を選択します。次に、きめの細かい評価指標を最適化する場合、それに応じて JDT 損失も変更する必要があります。
注 2: JDT 損失とピクセルレベルの損失関数 (クロスエントロピー損失、焦点損失など) を組み合わせます。この記事では、一般に 0.25CE 0.75JDT が適切な選択であることがわかりました。
注 3: トレーニングには短いエポックを使用するのが最善です。 JDT 損失を追加した後は、通常、クロス エントロピー損失トレーニングのエポックの半分だけが必要になります。
注 4: 複数の GPU で分散トレーニングを実行する場合、GPU 間で追加の通信がないと、JDT 損失により詳細な評価メトリクスが誤って最適化され、その結果、効果が悪化します。従来の mIoU で。
注 5: 極端なカテゴリの不均衡なデータセットでトレーニングする場合、JDL 損失はカテゴリごとに個別に計算され、平均化されるため、トレーニングが不安定になる可能性があることに注意してください。
実験結果
実験では、クロス エントロピー損失のベースラインと比較して、JDT 損失を追加すると、ハード ラベルを使用してトレーニングするときにモデルの精度を効果的に向上できることが証明されました。 。ソフトラベルを導入することで、モデルの精度とキャリブレーションをさらに向上させることができます。
 図
図
トレーニング中に JDT 損失項を追加するだけで、この記事はセマンティック セグメンテーションを達成しました。蒸留、半教師あり学習、マルチアノテーター SOTA。
 画像] [画像
画像] [画像
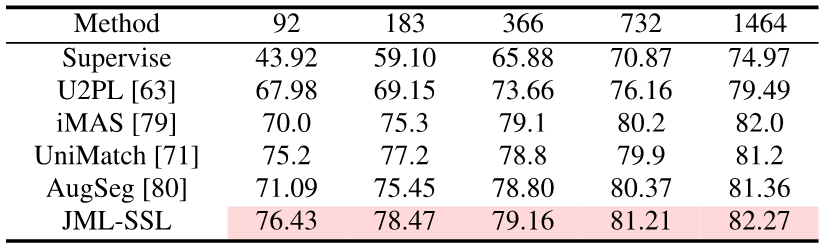 画像
画像
既存の評価指標 セマンティック セグメンテーションはピクセル レベルの分類タスクであるため、各ピクセルの精度、つまり全体的なピクセル単位の精度 (Acc) を計算できます。ただし、Acc が多数派のカテゴリに偏るため、PASCAL VOC 2007 では、各カテゴリのピクセル精度を個別に計算し、それを平均する評価指標、平均ピクセル単位精度 (mAcc) を採用しています。
セマンティック セグメンテーションはピクセル レベルの分類タスクであるため、各ピクセルの精度、つまり全体的なピクセル単位の精度 (Acc) を計算できます。ただし、Acc が多数派のカテゴリに偏るため、PASCAL VOC 2007 では、各カテゴリのピクセル精度を個別に計算し、それを平均する評価指標、平均ピクセル単位精度 (mAcc) を採用しています。
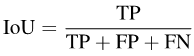 写真
写真
mIoUD を計算するには、まずカテゴリごとにデータ全体のすべての I 写真の真偽をカウントする必要があります。セットポジティブ (TP)、偽ポジティブ (FP)、および偽ネガティブ (FN):
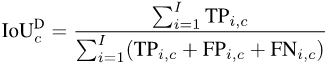 ##図
##図
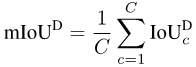 Picture
Picture

きめ細かい評価指標
mIoUD の問題を解決するために、私たちは細かい評価指標を提案します。 -粒度の高い評価指標。これらのメトリクスは各写真の IoU を個別に計算するため、大きなサイズのオブジェクトの優先度を効果的に減らすことができます。
mIoUI
カテゴリ c ごとに、各写真 i の IoU を計算します。
写真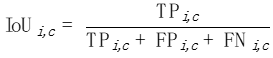
次に、各写真 i について、この写真に含まれているすべてのカテゴリを平均します :
写真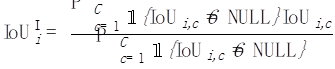
最後に、すべての写真の値を平均します:
写真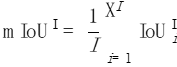
mIoUC
同様に、各写真 i の各カテゴリ c の IoU を計算した後、 、各カテゴリ c が表示されるすべての写真を平均することができます。
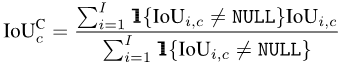
最後に、すべての写真の値を平均します。カテゴリ:
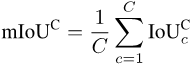
すべてのカテゴリがすべての写真に表示されるわけではないため、カテゴリと写真の組み合わせによっては NULL 値が発生する場合があります。下図のように、 が表示されます。 mIoUI を計算する場合、最初にカテゴリが平均化され、次に写真が平均化されます。一方、mIoUC が計算される場合、最初に写真が平均化され、次にカテゴリが平均化されます。
結果として、mIoUI は頻繁に出現するカテゴリ (下図の C1 など) に偏る可能性があり、これは一般に良くありません。しかしその一方で、mIoUI を計算する場合、各写真には IoU 値があるため、モデルとデータセットの監査と分析を行うのに役立ちます。
#写真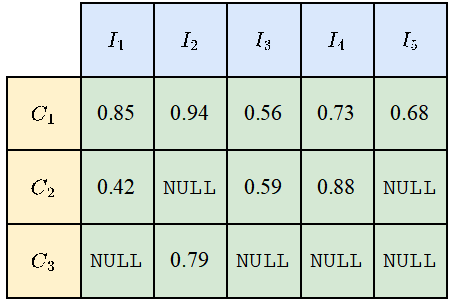
##セキュリティに細心の注意を払う一部のアプリケーション シナリオでは、最悪の場合のセグメンテーションの品質をより重視することがよくあります。きめの細かいインジケーターの利点の 1 つは、対応する最悪の場合のインジケーターを計算できることです。 mIoUC を例に挙げると、同様の方法で mIoUI の対応する最悪の場合の指標を計算することもできます。
各カテゴリ c について、まず、そのカテゴリ c に含まれているすべての写真 (そのような写真が存在すると仮定して) の IoU 値を昇順に並べ替えます。次に、q を 1 や 5 などの小さな数に設定します。次に、並べ替えられた写真の上位 Ic * q% のみを使用して、最終値を計算します。
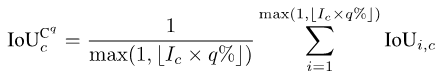 #Pictures
#Pictures
各クラス c の値を取得した後、前と同様にクラスごとに平均して、mIoUC の最悪の指標を取得できます。
実験結果
12 のデータセットで 15 のモデルをトレーニングし、次の現象を発見しました。
現象 1: すべての評価指標で最高の結果を達成できるモデルはありません。それぞれの評価指標は着目するところが異なるため、複数の評価指標を同時に考慮して総合的に評価する必要があります。
現象 2: 一部のデータ セットには、ほとんどすべてのモデルが非常に低い IoU 値を達成する原因となる写真がいくつかあります。これは、一部には非常に小さなオブジェクトや明暗の強いコントラストなど、写真自体が非常に難しいためであり、また、これらの写真のラベルに問題があるためでもあります。したがって、きめ細かい評価メトリクスは、モデル監査 (モデルが間違いを犯すシナリオの発見) とデータセット監査 (間違ったラベルの発見) の実施に役立ちます。
現象 3: ニューラル ネットワークの構造は、きめ細かい評価指標の最適化において重要な役割を果たします。一方で、ASPP (DeepLabV3 および DeepLabV3 で採用) などの構造によってもたらされる受容野の改善は、モデルが大きなサイズのオブジェクトを認識するのに役立ち、それによって mIoUD の値が効果的に向上します。エンコーダとデコーダ 長い接続 (UNet と DeepLabV3 で採用) により、モデルが小さなサイズのオブジェクトを認識できるようになり、それによってきめの細かい評価指標の値が向上します。
現象 4: 最悪の場合の指標の値は、対応する平均指標の値よりも大幅に低くなります。次の表は、複数のデータセットにおける DeepLabV3-ResNet101 の mIoUC と対応するワーストケースのインジケーター値を示しています。将来的に検討する価値のある問題は、最悪の指標の下でモデルのパフォーマンスを向上させるために、ニューラル ネットワークの構造と最適化方法をどのように設計すべきかということです。
 図
図
現象 5: 損失関数は、きめの細かい評価指標の役割を最適化するために重要です。次の表の (0, 0, 0) に示すように、クロス エントロピー損失ベンチマークと比較すると、評価指標が細分化されると、対応する損失関数を使用すると、細分化された評価指標でのモデルのパフォーマンスが大幅に向上します。たとえば、ADE20K では、JML とクロス エントロピーの間の mIoUC 損失の差は 7% を超えます。
 写真
写真
今後の作業
JDT の損失をセマンティクスの損失としてのみ考慮しましたセグメンテーションのための関数ですが、従来の分類タスクなどの他のタスクにも適用できます。
第二に、JDT 損失はラベル空間でのみ使用されますが、特徴空間内の任意の 2 つのベクトル間の距離を最小化するために、たとえば Lp モジュールを置き換えるために使用できると考えられます。そしてコサイン距離。
参考文献:
https://arxiv.org/pdf/2302.05666.pdf
https://arxiv.org/pdf/ 2303.16296 .pdf
https://arxiv.org/pdf/2310.19252.pdf
以上が「セマンティックセグメンテーションの最適化と評価」の問題を3つの論文で解決します!ルーベン/清華/オックスフォードなどが共同で新しい手法を提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7343
7343
 9
1627
14
1352
46
1265
25
1214
29
9
1627
14
1352
46
1265
25
1214
29

 よく使用される 10 個の損失関数の説明と Python コードの実装
Apr 13, 2023 am 09:37 AM
よく使用される 10 個の損失関数の説明と Python コードの実装
Apr 13, 2023 am 09:37 AM
損失関数とは何ですか?損失関数は、モデルがデータにどの程度適合しているかを測定するアルゴリズムです。損失関数は、実際の測定値と予測値の差を測定する方法です。損失関数の値が大きいほど予測は不正確であり、損失関数の値が小さいほど予測は真の値に近づきます。損失関数は、個々の観測値 (データ ポイント) ごとに計算されます。すべての損失関数の値を平均する関数はコスト関数と呼ばれますが、損失関数は 1 つのサンプルに対するものであり、コスト関数はすべてのサンプルに対するものであると理解すると簡単です。損失関数と測定基準 一部の損失関数は、評価測定基準としても使用できます。ただし、損失関数と指標には異なる目的があります。それでも
 国内のオープンソース MoE 指標が爆発的に増加: GPT-4 レベルの機能、API 価格はわずか 1%
May 07, 2024 pm 05:34 PM
国内のオープンソース MoE 指標が爆発的に増加: GPT-4 レベルの機能、API 価格はわずか 1%
May 07, 2024 pm 05:34 PM
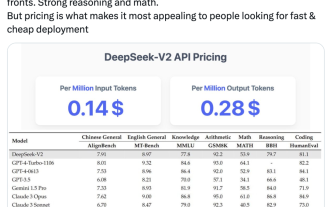
最新の国内大規模オープンソース MoE モデルは、デビュー直後から人気を集めています。 DeepSeek-V2 のパフォーマンスは GPT-4 レベルに達しますが、オープンソースで商用利用は無料で、API 価格は GPT-4-Turbo のわずか 1% です。そのため、公開されるとすぐに大きな話題を呼びました。公開されているパフォーマンス指標から判断すると、DeepSeekV2 の包括的な中国語機能は多くのオープンソース モデルの機能を上回っています。同時に、GPT-4Turbo や Wenkuai 4.0 などのクローズド ソース モデルも第一段階にあります。総合的な英語力もLLaMA3-70Bと同じ第一段階にあり、同じくMoEであるMixtral8x22Bを上回っています。また、知識、数学、推論、プログラミングなどでも優れたパフォーマンスを示します。 128K コンテキストをサポートします。これをイメージしてください
 Java で実装されたセマンティック セグメンテーションおよびビデオ コンセプト検出テクノロジとビデオ コンテンツ理解におけるアプリケーション
Jun 18, 2023 pm 07:51 PM
Java で実装されたセマンティック セグメンテーションおよびビデオ コンセプト検出テクノロジとビデオ コンテンツ理解におけるアプリケーション
Jun 18, 2023 pm 07:51 PM
今日のデジタルビデオ時代において、ビデオコンテンツ理解技術は、ビデオの推奨、ビデオ検索、ビデオの自動アノテーションなど、さまざまな分野で重要な役割を果たしています。その中で、セマンティック セグメンテーションとビデオ コンセプト検出テクノロジは、ビデオ コンテンツ理解の 2 つの主要な側面です。この記事では、Java 実装の観点から開始し、セマンティック セグメンテーションとビデオ コンセプト検出テクノロジの基本概念と、実際のアプリケーションにおけるその価値を紹介します。 1. セマンティック セグメンテーション テクノロジ セマンティック セグメンテーション テクノロジは、コンピュータ ビジョンの分野における重要な研究方向であり、その目的は画像またはビデオのピクセル レベルの分析を実行することです。
 よく使用される損失関数と Python の実装例
Apr 26, 2023 pm 01:40 PM
よく使用される損失関数と Python の実装例
Apr 26, 2023 pm 01:40 PM
損失関数とは何ですか?損失関数は、モデルがデータにどの程度適合しているかを測定するアルゴリズムです。損失関数は、実際の測定値と予測値の差を測定する方法です。損失関数の値が大きいほど予測は不正確であり、損失関数の値が小さいほど予測は真の値に近づきます。損失関数は、個々の観測値 (データ ポイント) ごとに計算されます。すべての損失関数の値を平均する関数をコスト関数と呼びますが、損失関数は 1 つのサンプルに対するものであり、コスト関数はすべてのサンプルに対するものであると理解すると簡単です。損失関数と測定基準 一部の損失関数は、評価測定基準としても使用できます。ただし、損失関数と指標には異なる目的があります。測定ですが、
 セマンティック セグメンテーションにおけるピクセル レベルの精度の問題
Oct 09, 2023 am 08:13 AM
セマンティック セグメンテーションにおけるピクセル レベルの精度の問題
Oct 09, 2023 am 08:13 AM
セマンティック セグメンテーションは、画像内の各ピクセルを特定のセマンティック カテゴリに割り当てることを目的とした、コンピューター ビジョンの分野における重要なタスクです。セマンティック セグメンテーションでは、ピクセル レベルの精度が重要な指標であり、モデルによる各ピクセルの分類が正確であるかどうかを測定します。しかし、実際のアプリケーションでは、精度が低いという問題に直面することがよくあります。この記事では、セマンティック セグメンテーションにおけるピクセル レベルの精度の問題について説明し、いくつかの具体的なコード例を示します。まず、セマンティック セグメンテーションの基本原理を理解する必要があります。一般的に使用されるセマンティック セグメンテーション モデルには FCN が含まれます
 アルトコイン市場は「爆発的な反発」を迎えようとしているのか?これら3つの指標に注意を払うだけで十分です
Jun 03, 2024 pm 05:15 PM
アルトコイン市場は「爆発的な反発」を迎えようとしているのか?これら3つの指標に注意を払うだけで十分です
Jun 03, 2024 pm 05:15 PM
3つのテクニカル指標を注意深く監視している仮想通貨トレーダーらは、アルトコイン市場は現在「信じられないほどの段階」にあり、歴史が繰り返されるなら間もなく「爆発的な上昇局面」に入る可能性があると述べている。仮想通貨アナリストのMikybullCrypto氏は、5月11日の投稿で6万6600倍のフォロワーに対し、「アルトコインの時価総額は現在、歴史的には爆発的な上昇が続くであろう信じられない段階にある」と語った。過去 30 日間の仮想通貨恐怖と貪欲指数の 24 ポイントの大幅な低下に反映されています。現在(&ldq)
 メトリクスから実践へ: PHPDepend でソフトウェア メトリクスを測定して PHP コードを改善する方法
Sep 15, 2023 am 09:33 AM
メトリクスから実践へ: PHPDepend でソフトウェア メトリクスを測定して PHP コードを改善する方法
Sep 15, 2023 am 09:33 AM
メトリクスから実践へ: PHPDepend を使用してソフトウェア メトリクスを測定し、PHP コードを改善する方法 はじめに: ソフトウェア開発プロセスでは、コード品質の評価が非常に重要です。さまざまなソフトウェア指標を測定することで、コードの品質とパフォーマンスをより深く理解し、コードを改善するための適切な措置を講じることができます。この記事では、PHPDepend ツールを使用して PHP コードのさまざまな指標を測定する方法を紹介し、特定のコード例を使用して、測定結果に基づいてコードを改善する方法を示します。 PHP コードのメトリクス測定PHPDep
 技術稼働指標制度を徹底解説
Jun 08, 2023 pm 06:43 PM
技術稼働指標制度を徹底解説
Jun 08, 2023 pm 06:43 PM
はじめに テクノロジー運用指標に関しては、テクノロジー担当者なら誰でも、トランザクション量、応答時間、応答率、成功率などをいくつか挙げることができます。これらの指標は、業務領域における作業の定量的な評価です。しかし、テクノロジー運用の全体的なレベルを評価するには、テクノロジー運用の指標システムを確立し、全体的な情報を取得し、その情報を運用の開発を推進し、組織の目標を達成するために使用する必要があります。建設目標と位置付け G 銀行は、管理者に多面的かつ洗練された業務管理分析フレームワークを提供するために、科学技術業務の可観測性指標システムを確立し、これを出発点としてセンターの業務管理能力、意思決定を向上させています。レベルもサービスの質も。指標システムの構築は、実際のビジネス シナリオに焦点を当て、定量化可能、比較可能、アクション指向、複数のシナリオに適応可能であるという 4 つの原則に従っています。
