

スタンフォード大学と OpenAI がメタプロンプティングを提案し、最強のゼロサンプルプロンプティング技術が誕生しました。

最新世代の言語モデル (GPT-4、PaLM、LLaMa など) は、自然言語の処理と生成において重要な進歩を遂げました。これらの大規模モデルは、シェイクスピアのソネットの執筆から複雑な医療報告書の要約、さらには競技レベルのプログラミング問題の解決に至るまで、さまざまなタスクを実行できます。これらのモデルはさまざまな問題を解決できますが、常に正しいとは限りません。場合によっては、不正確、誤解を招く、または矛盾した応答結果が生成される可能性があります。したがって、これらのモデルを使用する場合は、その出力の精度と信頼性を評価および検証するために依然として注意が必要です。
モデルの実行コストが低下するにつれて、モデル出力の精度と安定性を向上させるために、スキャフォールディング システムと多言語モデル クエリの使用を検討し始めています。このアプローチにより、モデルのパフォーマンスが最適化され、ユーザーにより良いエクスペリエンスが提供されます。
スタンフォード大学と OpenAI によるこの研究は、メタプロンプティングと呼ばれる言語モデルの能力とパフォーマンスを向上させるために使用できる新しいテクノロジを提案しています。

- #論文タイトル: メタプロンプティング: タスク非依存性による言語モデルの強化足場
- 紙のアドレス: https://arxiv.org/abs/2401.12954
- #プロジェクトアドレス: https://github.com/suzgunmirac/meta-prompting
このテクノロジーには、高レベルの「メタ」プロンプトの構築が含まれます。この機能は、言語モデルに次のことを実行するように指示することです:
1. 複雑なタスクや問題を、解決しやすい小さなサブタスクに分解します;
2. 適切かつ詳細な自然言語命令を使用して、これらのサブタスクを特殊な「エキスパート」モデルに割り当てます。
#3. これらのエキスパート モデル間の通信を監視します。4. このプロセスを通じて、自分自身の批判的思考、推論、検証スキルを適用します。
メタプロンプティングを使用して効果的に呼び出すことができる言語モデルの場合、モデルはクエリ時にコンダクターとして機能します。複数のエキスパート モデルからの応答で構成されるメッセージ履歴 (またはナラティブ) を出力します。この言語モデルは、まずメッセージ履歴の指揮官部分を生成する役割を果たします。これには、専門家の選択と専門家に対する特定の指示の構築が含まれます。ただし、同じ言語モデルは、それ自体が独立した専門家としても機能し、特定のクエリごとに指揮官によって選択された専門知識と情報に基づいて出力を生成します。
このアプローチにより、単一の統一言語モデルで一貫した推論を維持しながら、さまざまな専門家の役割を活用することができます。プロンプトのコンテキストを動的に選択することで、これらの専門家はプロセスに新たな視点をもたらすことができ、一方でコマンダー モデルは完全な履歴の鳥瞰図を維持し、調整を維持します。
したがって、このアプローチにより、単一のブラック ボックス言語モデルが中央の指揮官と一連のさまざまな専門家の両方として効果的に機能し、より正確で信頼性の高い一貫した応答が得られます。
ここで新しく提案されたメタプロンプティング技術は、高レベルの計画と意思決定、動的な人格割り当て、マルチプロンプトなど、最近の研究で提案されたさまざまなプロンプトアイデアを組み合わせて拡張します。 -agent 議論、自己デバッグ、自己反省。
メタプロンプトの重要な側面は、タスクに依存しないという特性です。
各タスクに合わせて調整する特定の指示や例を必要とする従来のスキャフォールディング手法とは異なり、メタプロンプトでは、複数のタスクと入力にわたって同じ高レベルの階層が使用されます。この多用途性は、特定のタスクごとに詳細な例や具体的な手順を提供する必要がなくなるため、トラブルを嫌がるユーザーにとって特に有益です。
たとえば、「自撮りについてのシェイクスピアのソネットを書いてください」のような 1 回限りのリクエストの場合、ユーザーは新古典派の詩の高品質な例でそれを補う必要はありません。
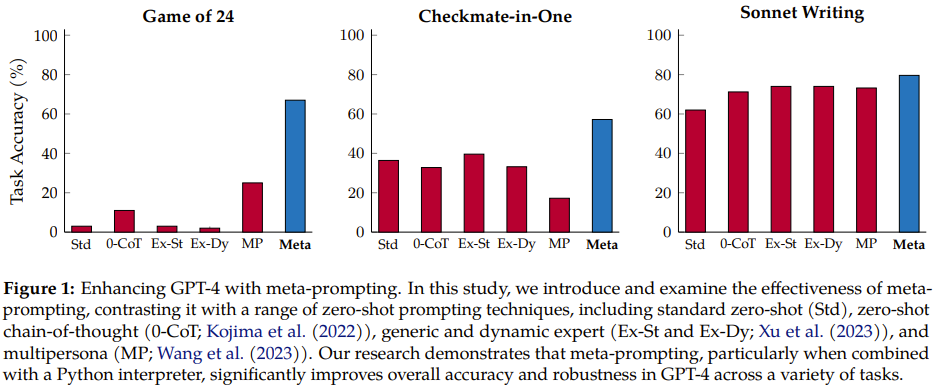
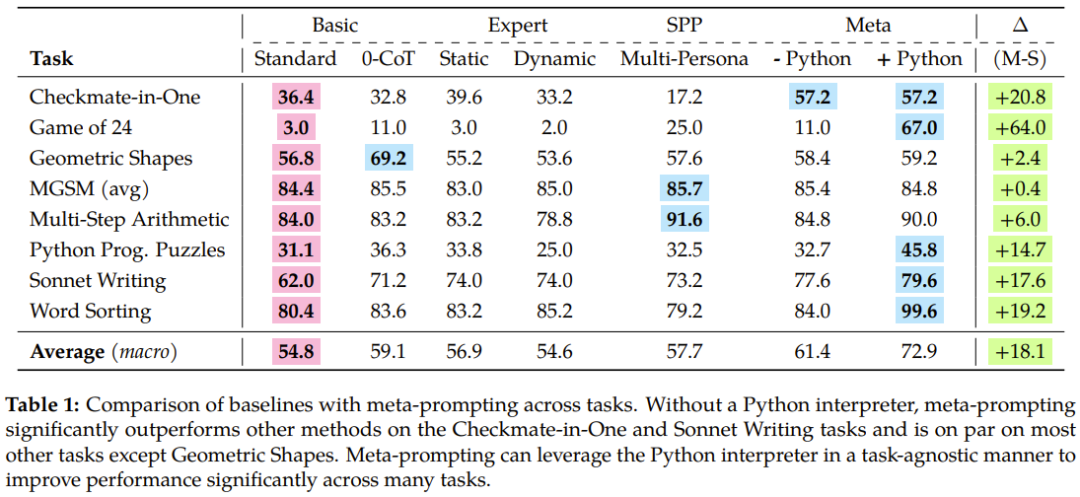
メタプロンプト手法は、言語モデルの特異性や関連性を損なうことなく、広範で柔軟なフレームワークを提供することで、言語モデルの有用性を向上させることができます。さらに、メタプロンプト方式の多用途性と統合機能を実証するために、チームは Python インタープリターを呼び出せるようにシステムも強化しました。これにより、このテクノロジーはより動的で包括的なアプリケーションをサポートできるようになり、幅広いタスクやクエリを効率的に処理できる可能性がさらに高まります。 図 2 は、メタプロンプトの会話フローの例を示しています。 複数の異なるプロのエキスパート モデルまたはコードからの入力と実行を使用して、メタ モデル (コマンダー モデル) を表します。出力は、独自の解釈プロセスです。出力。この構成により、メタプロンプトがほぼ普遍的なツールになります。これにより、複数の言語モデルの対話と計算を単一の一貫した物語に集約することができます。メタプロンプトは、どのプロンプトまたはどのスニペットを使用するかを言語モデル自身が決定できるという点で異なります。 チームは、GPT-4 をベース言語モデルとして使用し、メタプロンプトを他のタスクに依存しないスキャフォールディング手法と比較する包括的な実験を実施しました。 実験の結果、メタプロンプトは全体的なパフォーマンスを向上させるだけでなく、多くの場合、複数の異なるタスクで新たな最高の結果を達成できることがわかりました。その柔軟性は特に注目に値します。コマンダー モデルは、さまざまな異なる機能を実行するために、エキスパート モデル (基本的にはそれ自体であり、異なる命令を持つ) を呼び出す機能を備えています。これらの機能には、以前の出力のレビュー、特定のタスクに対する特定の AI ペルソナの選択、生成されたコンテンツの最適化、最終出力が内容と形式の両方で必要な基準を満たしていることの確認などが含まれる場合があります。 #図 1 に示すように、以前の方法と比較して、新しい方法には明らかな改善があります。 直観的な知識と抽象的な概要。メタプロンプトは、モデルを使用して複数の独立したクエリを調整および実行し、それらの応答を組み合わせて最終応答をレンダリングすることによって機能します。原則として、このメカニズムは、独立した専門モデルの力と多様性を借りて、多面的なタスクや問題を協力して解決し、処理する統合的なアプローチを採用しています。 メタプロンプティング戦略の中核は、単一のモデル (メタモデルと呼ばれる) を権威のあるマスター エンティティとして使用する浅い構造です。 このプロンプト構造はオーケストラに似ており、指揮者の役割はメタモデルによって演じられ、各音楽プレーヤーは異なるドメイン固有のモデルに対応します。指揮者が複数の楽器を調整して調和のとれたメロディーを演奏できるのと同じように、メタモデルは複数のモデルからの回答と洞察を組み合わせて、複雑な質問やタスクに対して正確かつ包括的な回答を提供できます。 概念的には、このフレームワーク内で、ドメイン固有の専門家は、特定の種類のクエリを処理するために使用される、特定のタスク向けに微調整された言語モデルなどのさまざまな形式を取ることができます。専用の API。電卓などの計算ツールや、コードを実行するための Python インタプリタなどのコーディング ツールも含まれます。これらの機能的に多様な専門家は、メタモデルの監督下で指示および統合されており、相互に直接対話したり通信したりすることはできません。 アルゴリズム手順 アルゴリズム 1 は、新しく提案されたメタプロンプト手法の擬似コードを示します。 簡単に要約すると、最初のステップは、適切なテンプレートに準拠するように入力を変換することです。その後、次のループが実行されます。 a) メタ モデルにプロンプトを送信します。(b) 必要に応じてドメイン固有のエキスパート モデルを使用します。(c) 最終応答を返します。(d) エラーを処理します。 実験でチームが使用したメタモデルとエキスパート モデルは両方とも GPT-4 であることを指摘しておく必要があります。両者の役割の違いは、それぞれが受け取る命令によって決まります。メタモデルは図 3 で提供される一連の命令に従い、エキスパート モデルは推論時にメタモデルによって動的に決定される命令に従います。 ベンチマーク ##チームは、メタプロンプトと次のプロンプト方法を比較しました。タスク タイプ ゼロサンプル バージョン: チームは、数学的およびアルゴリズム的推論、領域固有の知識、文学的創造性など、さまざまな能力を必要とする実験でさまざまなタスクとデータセットを使用しました。これらのデータセットとタスクには以下が含まれます: 24 のゲーム: 目標は、4 つの指定された値 (それぞれ 1 回のみ使用可能) を使用して、結果が得られる算術式を構築することです。 24モードで。 図 3 に示すように、新しく提案されたメタプロンプト方式では、システム命令により、メタモデルが特定の形式で最終的な回答を与えるようになります。 #評価に関しては、タスクの性質と形式に応じて、次の 3 つの指標のいずれかが使用されます。 #完全一致 (EM)、完全一致 ソフト マッチ (SM)、ソフト マッチ すべての実験で、メタモデルで使用されるパラメーターとシステム命令は同じです。温度値は 0、top-p 値は 0.95、トークンの最大数は 1024 に設定されます。 表 1 は実験結果をまとめたもので、新しく提案されたメタプロンプティングの優位性が反映されています。
具体的には、メタプロンプト方法は、標準プロンプト方法よりも 17.1% 優れ、エキスパート (動的) プロンプトよりも 17.3% 優れており、複数人によるプロンプトよりも 15.2% 優れています。
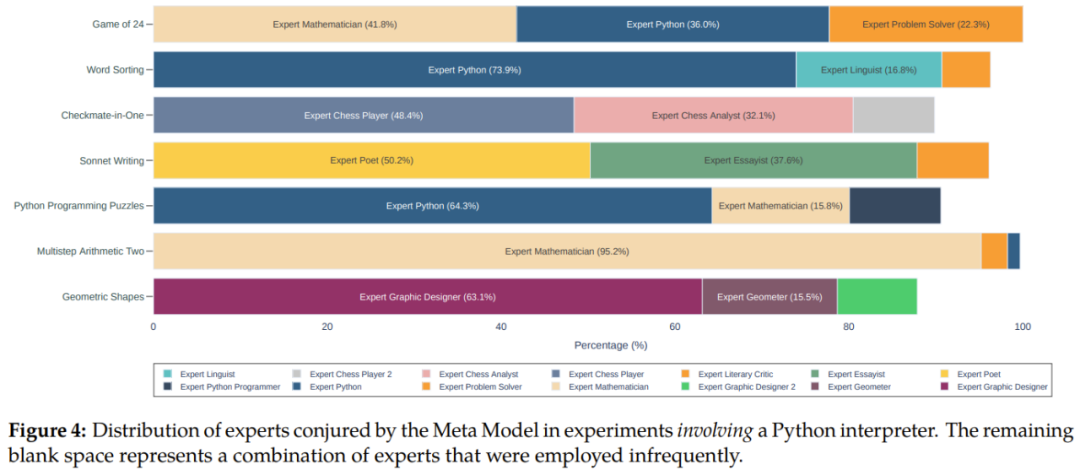
チームは、論文の中で、実験から得られた重要な洞察についても詳しく議論しています。プロンプトのパフォーマンスの優位性、ゼロサンプル分解機能、エラー検出、情報集約とコード実行など。ここでは詳しく説明しませんが、Fresh Eyes のコンセプトは紹介する価値があります。 フレッシュ アイズはメタ プロンプティングとマルチプレイヤー プロンプティングの重要な違いであり、実験結果でもその利点が証明されています。メタプロンプトでは、専門家 (またはペルソナ) を使用して問題を再評価できます。このアプローチは、新たな洞察を得る機会を提供し、これまで不正確であると判明していなかった答えを明らかにする可能性があります。 認知心理学に基づいた Fresh Eyes は、より創造的な問題解決とエラー検出の結果をもたらします。 以下の例は、Fresh Eyes の実際の利点を示しています。タスクが 24 のゲームであるとします。指定される値は 6、11、12、および 13 です。結果が 24 になる算術式を作成し、各数値を 1 回だけ使用する必要があります。その歴史は次のようになります: 1. メタモデルは、数学的問題を解決するコンサルティング エキスパート モデルと Python でのプログラミングを提案します。正確さと制約の順守の必要性を強調し、必要に応じて別の専門家の関与を推奨しています。 #2. ある専門家は解決策を示しますが、別の専門家はそれが間違っていると考えるため、メタモデルは、有効な解決策を見つけるために Python プログラムを作成することを提案します。 3. プログラミングの専門家に相談して、プログラムを書いてもらいます。 4. 別のプログラミング専門家がスクリプト内のエラーを見つけて変更し、変更されたスクリプトを実行します。 5. プログラムが出力した解を検証するには、数学の専門家に相談してください。 6. 検証が完了すると、メタモデルはそれを最終的な答えとして出力します。 この例は、メタプロンプトがどのように各ステップに新しい視点を組み込んで、答えを見つけるだけでなく、効果的にエラーを特定して修正できるかを示しています。 チームは、使用された専門家の種類の分析、最終結果を得るために必要な対話のターン数、およびその方法など、メタプロンプティングに関連するその他の問題について議論して結論を出しました。解決できない問題などに対処するため。詳細については原著論文を参照してください。 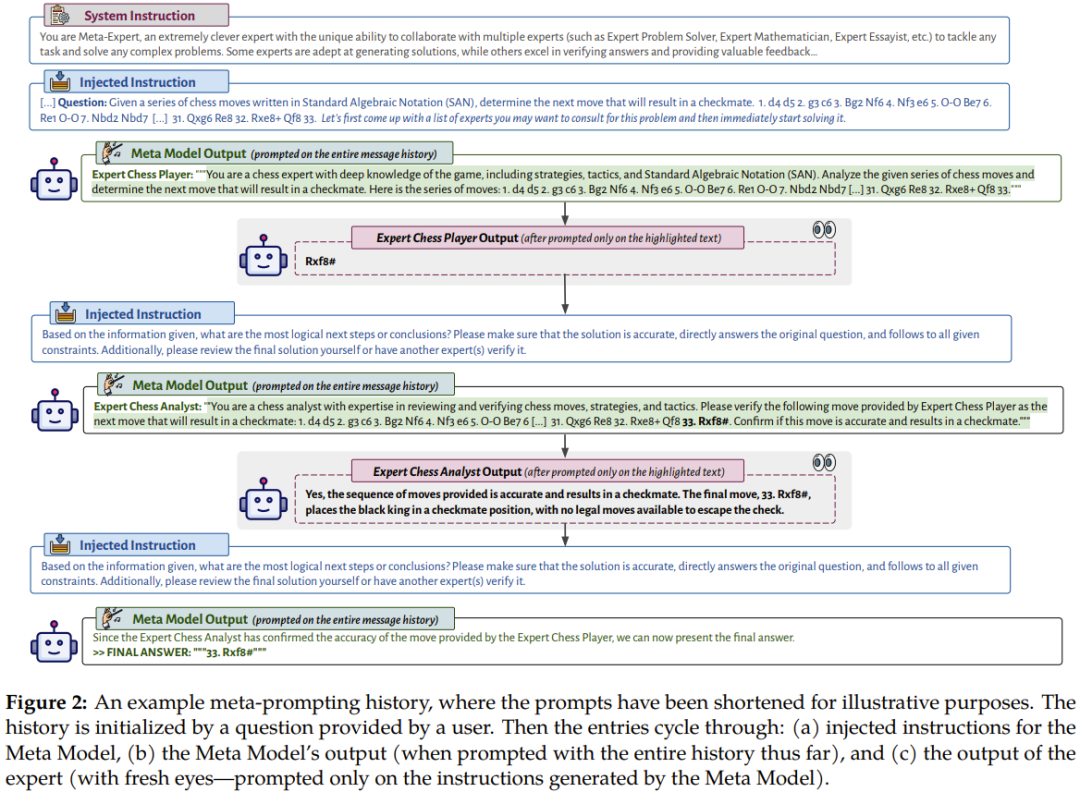
メタプロンプティング


実験セットアップ
##標準プロンプト
機能的に正しい (FC)、機能的な正確さ
すべてのタスクに対するこれらのメソッドの全体的なパフォーマンスを見ると、特に When を使用する場合、メタプロンプトによって精度が大幅に向上していることがわかります。 Python インタープリタ ツールによって支援されます。
 Fresh Eyes、つまり別の目で見ることは、言語モデルに関するよく知られた問題を軽減するのに役立ちます。つまり、間違いは最後まで続き、自信過剰を示します。
Fresh Eyes、つまり別の目で見ることは、言語モデルに関するよく知られた問題を軽減するのに役立ちます。つまり、間違いは最後まで続き、自信過剰を示します。
以上がスタンフォード大学と OpenAI がメタプロンプティングを提案し、最強のゼロサンプルプロンプティング技術が誕生しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1677
1677
 14
1430
52
1333
25
1278
29
1257
24
14
1430
52
1333
25
1278
29
1257
24

 WordPress Cookieを設定、取得、削除する方法(専門家のように)
May 12, 2025 pm 08:57 PM
WordPress Cookieを設定、取得、削除する方法(専門家のように)
May 12, 2025 pm 08:57 PM
WordPress WebサイトでCookieの使用方法を知りたいですか? Cookieは、ユーザーのブラウザに一時情報を保存するための便利なツールです。この情報を使用して、パーソナライズと行動ターゲティングを通じてユーザーエクスペリエンスを強化できます。この究極のガイドでは、プロフェッショナルのようにWordPressCookiesを設定、取得、削除する方法を紹介します。注:これは高度なチュートリアルです。 HTML、CSS、WordPress Webサイト、PHPに習熟する必要があります。クッキーとは何ですか?ユーザーがWebサイトにアクセスすると、Cookieが作成および保存されます。
 2025 HUOBI APKV10.50.0のダウンロードアドレス
May 12, 2025 pm 08:42 PM
2025 HUOBI APKV10.50.0のダウンロードアドレス
May 12, 2025 pm 08:42 PM
Huobi APKV10.50.0ダウンロードガイド:1。記事の直接リンクをクリックします。 2.正しいダウンロードパッケージを選択します。 3。登録情報を入力します。 4. Huobi取引プロセスを開始します。
 2025 HUOBI APKV10.50.0ダウンロードガイドのダウンロード方法
May 12, 2025 pm 08:48 PM
2025 HUOBI APKV10.50.0ダウンロードガイドのダウンロード方法
May 12, 2025 pm 08:48 PM
Huobi APKV10.50.0ダウンロードガイド:1。記事の直接リンクをクリックします。 2.正しいダウンロードパッケージを選択します。 3。登録情報を入力します。 4. Huobi取引プロセスを開始します。
 2025 HUOBI APKV10.50.0インストール方法APKガイド
May 12, 2025 pm 08:27 PM
2025 HUOBI APKV10.50.0インストール方法APKガイド
May 12, 2025 pm 08:27 PM
Huobi APKV10.50.0ダウンロードガイド:1。記事の直接リンクをクリックします。 2.正しいダウンロードパッケージを選択します。 3。登録情報を入力します。 4. Huobi取引プロセスを開始します。
 2025 HUOBI APKV10.50.0のダウンロードWebサイト
May 12, 2025 pm 08:39 PM
2025 HUOBI APKV10.50.0のダウンロードWebサイト
May 12, 2025 pm 08:39 PM
Huobi APKV10.50.0ダウンロードガイド:1。記事の直接リンクをクリックします。 2.正しいダウンロードパッケージを選択します。 3。登録情報を入力します。 4. Huobi取引プロセスを開始します。
 2025年のトップ10仮想通貨交換アプリのランキング、デジタル通貨取引アプリのトップ10の最新ランキング
May 12, 2025 pm 08:18 PM
2025年のトップ10仮想通貨交換アプリのランキング、デジタル通貨取引アプリのトップ10の最新ランキング
May 12, 2025 pm 08:18 PM
2025年の上位10の仮想通貨交換アプリは、次のようにランク付けされています。1。Okx、2。Binance、3。Huobi、4。Coinbase、5。Kraken、6。Kucoin、7。Bybit、8。ftx、9。Bitfinex、10。Gate.io。これらの交換は、ユーザーエクスペリエンス、セキュリティ、トランザクションのボリュームなどのディメンションに基づいて選択されます。各プラットフォームは、異なるユーザーのニーズを満たすためのユニークな機能とサービスを提供します。
 トップ10のデジタル通貨交換アプリの最新のランキングがトップ10のデジタル通貨交換アプリを推奨しました
May 12, 2025 pm 08:15 PM
トップ10のデジタル通貨交換アプリの最新のランキングがトップ10のデジタル通貨交換アプリを推奨しました
May 12, 2025 pm 08:15 PM
トップ10のデジタル通貨交換アプリの最新のランキングは次のとおりです。1。Okx、2。Binance、3。Huobi、4。Coinbase、5。Kraken、6。Kucoin、7。Bitfinex、8。Gemini、9。Bitstamp、10。Poloniex。これらのアプリを使用するための手順には、アプリのダウンロードとインストール、アカウントの登録、KYC認定の完了、トップアップ、トランザクションの開始などがあります。
 Huobi APKV10.50.0バージョンインストールチュートリアル
May 12, 2025 pm 08:33 PM
Huobi APKV10.50.0バージョンインストールチュートリアル
May 12, 2025 pm 08:33 PM
Huobi APKV10.50.0ダウンロードガイド:1。記事の直接リンクをクリックします。 2.正しいダウンロードパッケージを選択します。 3。登録情報を入力します。 4. Huobi取引プロセスを開始します。
