

7B オープンソース数学モデルは、中国のチームが作成した数十億の GPT-4 を破る

7B オープン ソース モデル、数学的能力は 1,000 億規模の GPT-4 を超えます。
そのパフォーマンスはオープンソース モデルの限界を突破したと言え、アリババ同義の研究者ですらスケーリング則が破綻しているのではないかと嘆いていました。

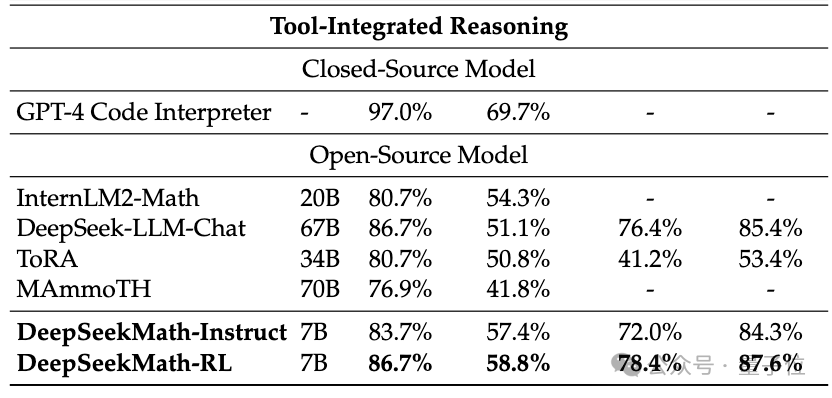
外部ツールを使用せずに、競技レベルの MATH データ セットで 51.7% の精度を達成できます。
オープンソース モデルの中で、このデータセットで半分の精度を達成したのは初めてであり、GPT-4 の初期バージョンと API バージョンをも上回っています。
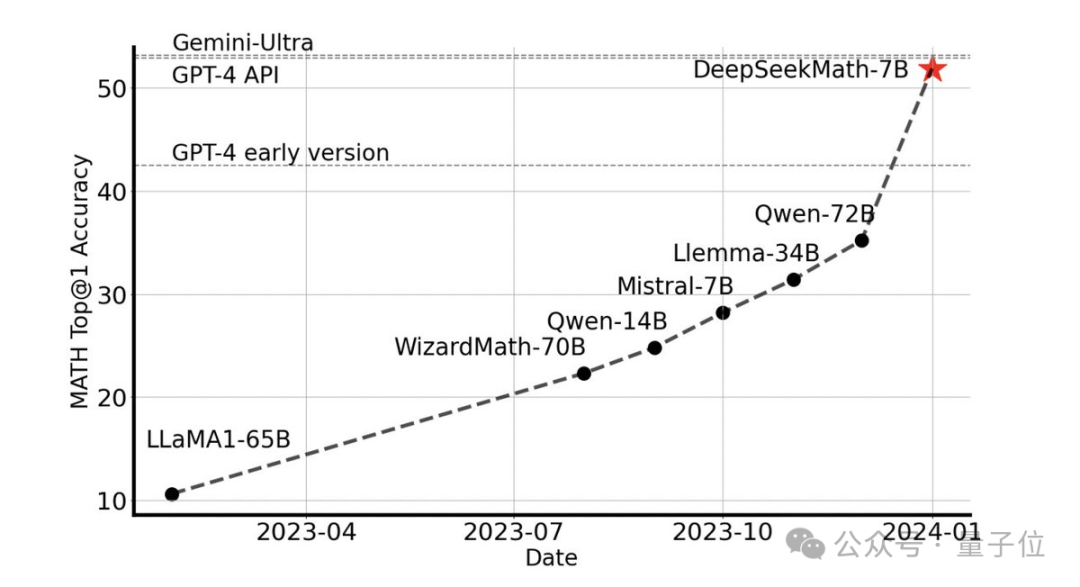
このパフォーマンスはオープンソース コミュニティ全体に衝撃を与え、Stability AI の創設者 Emad Mostaque 氏は、研究開発チームを「印象的」であり、「可能性が過小評価されている」と賞賛しました。
これは、ディープサーチチームの最新のオープンソース 7B 大規模数学モデル DeepSeekMath です。
7B モデルが群衆に勝つ
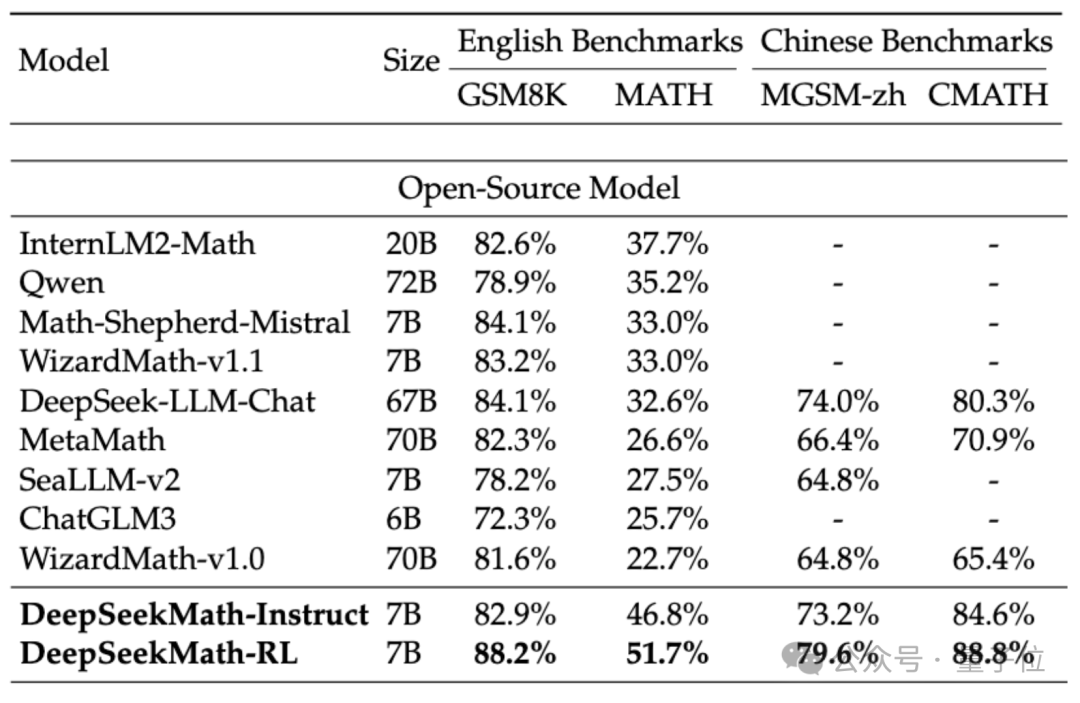
DeepSeekMath の数学的能力を評価するために、研究チームは中国語 (MGSM-zh、CMATH) English ( GSM8K、MATH )バイリンガル データ セットがテストされました。
補助ツールを使用せず、思考連鎖のプロンプトのみに依存する (CoT) により、DeepSeekMath のパフォーマンスは、70B の大規模数学モデル MetaMATH を含む他のオープンソース モデルを上回りました。
同社が発売した67Bの一般的な大型モデルと比較して、DeepSeekMathの結果も大幅に向上しました。
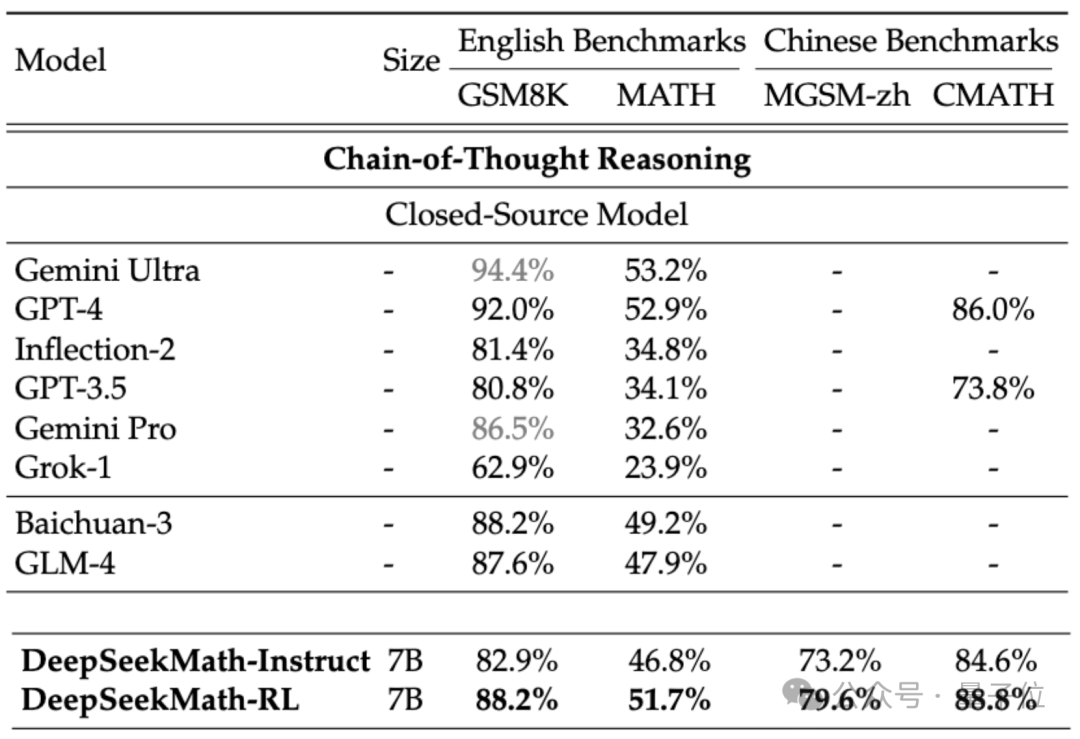
クローズドソース モデルを考慮すると、DeepSeekMath はいくつかのデータ セットで Gemini Pro と GPT-3.5 を上回り、中国の CMATH では GPT-4 を上回りました。数学もそれに近いです。
しかし、漏洩した仕様によると、GPT-4 は数千億のパラメーターを持つ巨大な存在であるのに対し、DeepSeekMath には 7B パラメーターしかないことに注意する必要があります。
ツール (Python) が支援として使用できる場合、競技難易度 (MATH) での DeepSeekMath のパフォーマンスデータセットはまだ良好であり、さらに 7 パーセントポイント増加する可能性があります。
では、DeepSeekMath の優れたパフォーマンスの背後にはどのようなテクノロジが適用されているのでしょうか?
コード モデルに基づいて構築
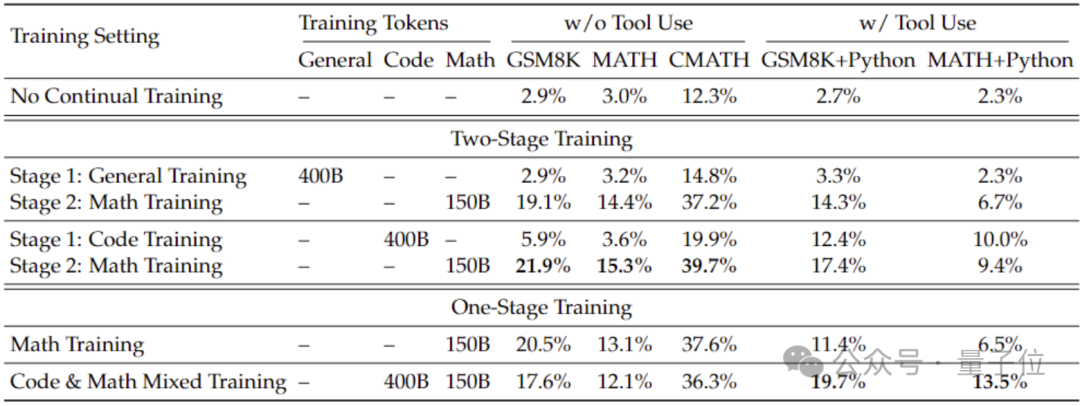
一般的なモデルよりも優れた数学的機能を得るために、研究チームはコード モデル DeepSeek-Coder-v1.5 を使用して初期化しました。
チームは、2 段階のトレーニング設定でも 1 段階のトレーニング設定でも、一般的なデータ トレーニングと比較して、コード トレーニングによりモデルの数学的能力を向上させることができることを発見したためです。
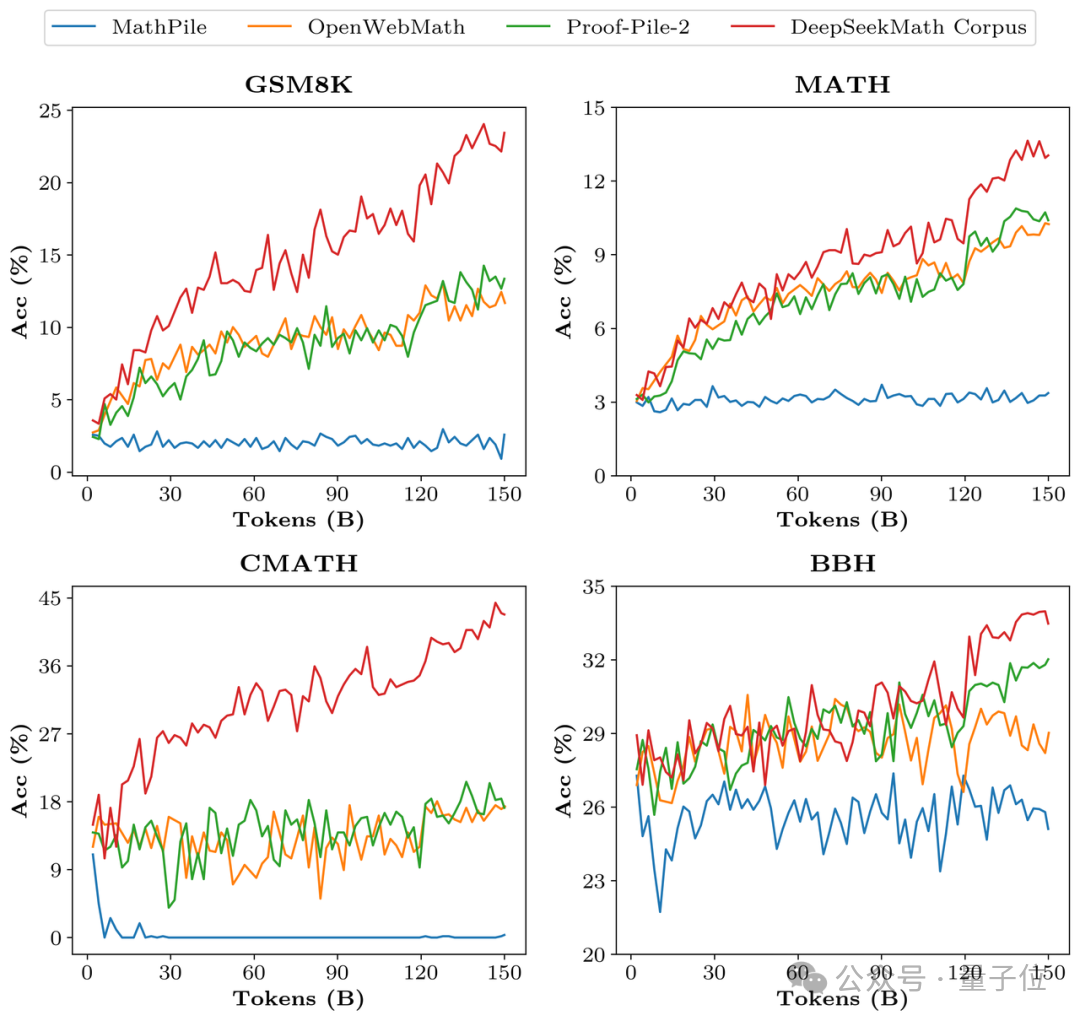
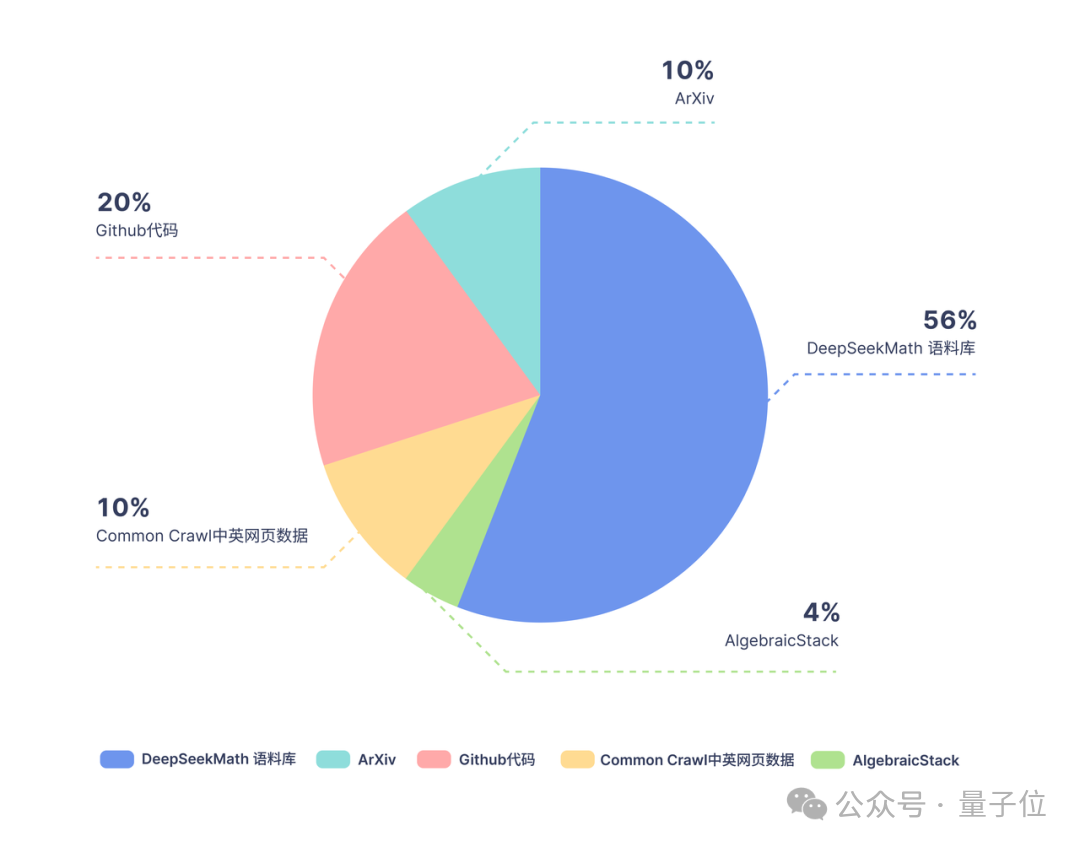 # # トレーニング データに関しては、DeepSeekMath は Common Crawl から抽出された 120B の高品質数学ウェブページ データを使用して DeepSeekMath Corpus を取得しており、総データ量はオープン ソース データ セット OpenWebMath の 9 倍です。
# # トレーニング データに関しては、DeepSeekMath は Common Crawl から抽出された 120B の高品質数学ウェブページ データを使用して DeepSeekMath Corpus を取得しており、総データ量はオープン ソース データ セット OpenWebMath の 9 倍です。
データ収集プロセスは反復的に実行され、4 回の反復の後、研究チームは 3,500 万以上の数学的 Web ページを収集し、トークンの数は 1,200 億に達しました。
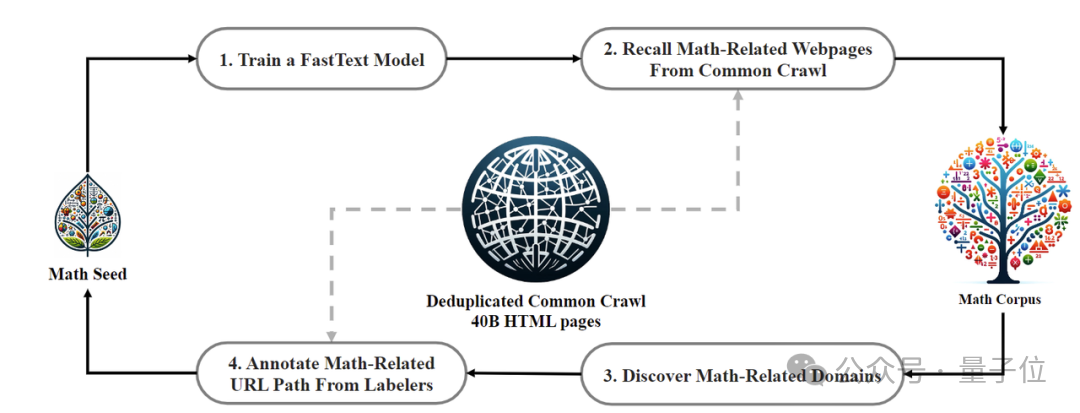 トレーニング データにテスト セットのコンテンツが含まれていないことを確認するためです
トレーニング データにテスト セットのコンテンツが含まれていないことを確認するためです
、研究チームも特別にフィルタリングしました。 DeepSeekMath Corpus のデータ品質を検証するために、研究チームは MathPile などの複数のデータセットを使用して 1,500 億のトークンを学習させ、その結果、Corpus は複数の数学的ベンチマークで大幅に優れていました。
 調整段階で、研究チームはまず、中国語と英語の数学ガイド付き教師あり微調整
調整段階で、研究チームはまず、中国語と英語の数学ガイド付き教師あり微調整
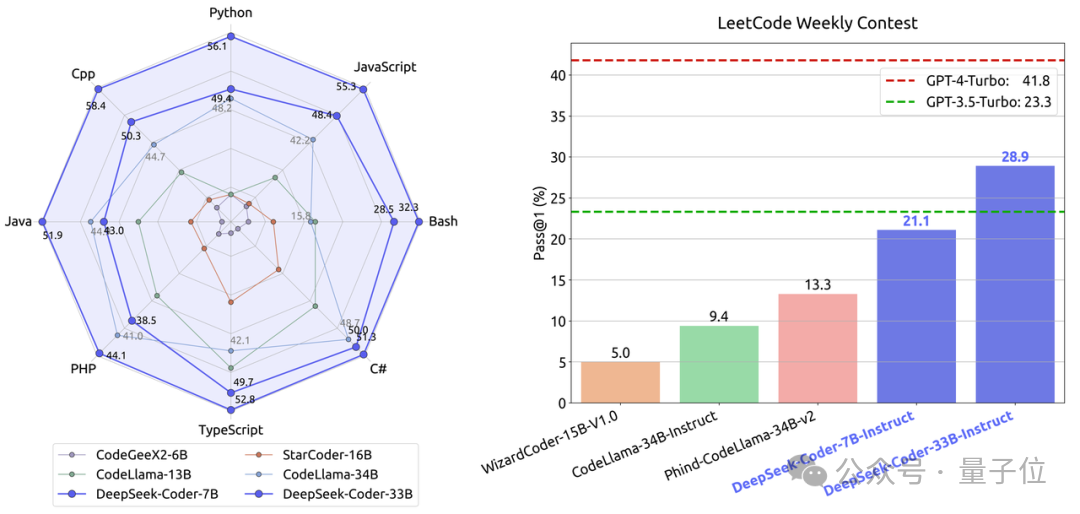
データセット 776,000 個のサンプルを構築しました。 CoT、PoT、ツール統合型推論とその他の 3 つの形式。 強化学習 (RL) ステージでは、研究チームは「グループベースの相対ポリシー最適化」 (Group Relative Policy Optimization、GRPO) アルゴリズムと呼ばれる効率的な手法を使用しました。 GRPO は、Proximal Policy Optimization (PPO) のバリエーションであり、その過程で、従来の価値関数がグループベースの相対報酬推定値に置き換えられ、複雑さを軽減できます。トレーニング プロセス、計算およびメモリの要件。 同時に、GRPO は反復プロセスを通じてトレーニングされ、報酬モデルはポリシー モデルの出力に基づいて継続的に更新され、ポリシーの継続的な改善が保証されます。 DeepSeekMath を立ち上げた徹底調査チームは、国内のオープンソース MoE モデルの「トッププレイヤー」です。オープンソースモデル。 以前、チームは国内初のオープンソース MoE モデル DeepSeek MoE を発表し、その 7B バージョンは同規模の高密度モデル Llama 2 を 40% の計算量で破りました。 一般的なモデルとして、コーディングおよび数学的タスクにおける DeepSeek MoE のパフォーマンスはすでに非常に優れており、リソース消費は非常に低いです。 コードに関しては、チームが立ち上げた DeepSeek-Coder のプログラミング能力は、同規模のオープンソース ベンチマークである CodeLllama を上回っています。 同時に、GPT-3.5-Turbo にも打ち勝ち、GPT-4-Turbo に最も近いオープン ソース コード モデルになりました。 前述したように、今回リリースされた DeepSeekMath も Coder をベースに構築されています。 X では、すでに MoE バージョンの Coder と Math を楽しみにしている人もいます。 論文アドレス: https://arxiv.org/abs/2402.03300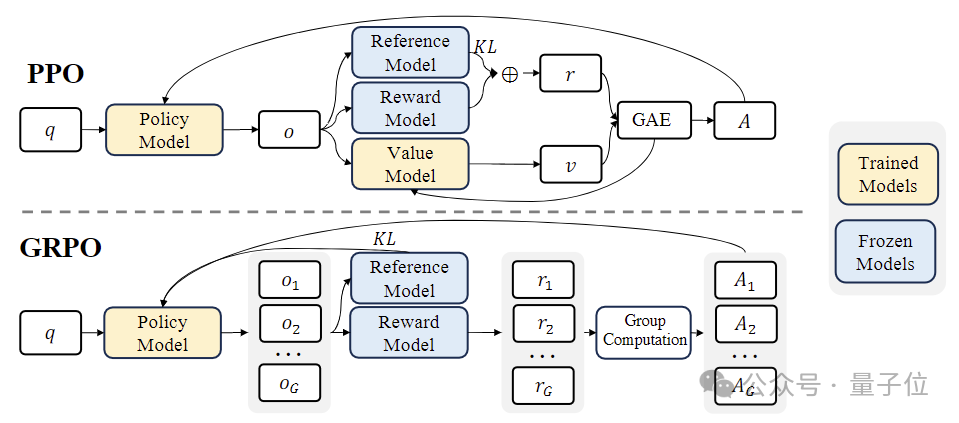
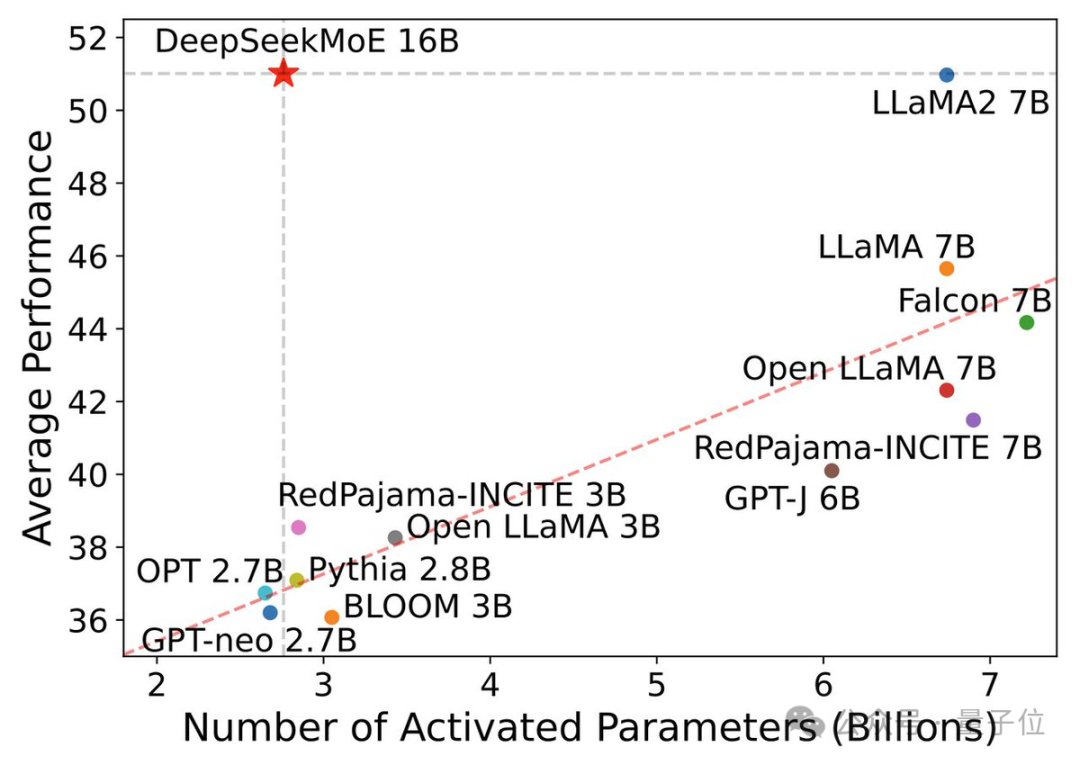
国内初のオープンソース MoE モデルを立ち上げました

以上が7B オープンソース数学モデルは、中国のチームが作成した数十億の GPT-4 を破るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7725
7725
 15
1643
14
1397
52
1290
25
1233
29
15
1643
14
1397
52
1290
25
1233
29

 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
 ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
暗号通貨交換を選択するための提案:1。流動性の要件については、優先度は、その順序の深さと強力なボラティリティ抵抗のため、Binance、gate.ioまたはokxです。 2。コンプライアンスとセキュリティ、Coinbase、Kraken、Geminiには厳格な規制の承認があります。 3.革新的な機能、Kucoinのソフトステーキング、Bybitのデリバティブデザインは、上級ユーザーに適しています。
 通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
2025年のレバレッジド取引、セキュリティ、ユーザーエクスペリエンスで優れたパフォーマンスを持つプラットフォームは次のとおりです。1。OKX、高周波トレーダーに適しており、最大100倍のレバレッジを提供します。 2。世界中の多通貨トレーダーに適したバイナンス、125倍の高いレバレッジを提供します。 3。Gate.io、プロのデリバティブプレーヤーに適し、100倍のレバレッジを提供します。 4。ビットゲットは、初心者やソーシャルトレーダーに適しており、最大100倍のレバレッジを提供します。 5。Kraken、安定した投資家に適しており、5倍のレバレッジを提供します。 6。Altcoinエクスプローラーに適したBybit。20倍のレバレッジを提供します。 7。低コストのトレーダーに適したKucoinは、10倍のレバレッジを提供します。 8。ビットフィネックス、シニアプレイに適しています
 通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
初心者に適した暗号通貨データプラットフォームには、Coinmarketcapと非小さいトランペットが含まれます。 1。CoinMarketCapは、初心者と基本的な分析のニーズに合わせて、グローバルなリアルタイム価格、市場価値、取引量のランキングを提供します。 2。小さい引用は、中国のユーザーが低リスクの潜在的なプロジェクトをすばやくスクリーニングするのに適した中国フレンドリーなインターフェイスを提供します。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
