

OccNeRF: LIDAR データの監視はまったく必要ありません

以前書いた&筆者の個人的要約
近年、自動運転分野における 3D 乗員予測タスクは、その独特な特徴から学界や産業界で広く研究されています。利点に焦点を当てます。このタスクは、周囲環境の 3D 構造を再構築することにより、自動運転の計画とナビゲーションのための詳細な情報を提供します。ただし、現在の主流の方法のほとんどは、ネットワーク トレーニングを監視するために、LiDAR 点群に基づいて生成されたラベルに依存しています。 最近の OccNeRF 研究で、著者らはパラメータ化された占有フィールドと呼ばれる自己監視型マルチカメラ占有予測方法を提案しました。この方法は、屋外シーンにおける境界の無さの問題を解決し、サンプリング戦略を再編成します。次に、ボリューム レンダリング (ボリューム レンダリング) テクノロジーによって、占有フィールドがマルチカメラ デプス マップに変換され、マルチフレームの測光一貫性 (測光誤差) によって管理されます。 さらに、この方法は、事前にトレーニングされた公開語彙意味セグメンテーション モデルを利用して 2D 意味ラベルを生成し、職業フィールドに意味情報を与えます。このオープンレキシコンのセマンティック セグメンテーション モデルは、シーン内のさまざまなオブジェクトをセグメント化し、各オブジェクトにセマンティック ラベルを割り当てることができます。これらのセマンティック ラベルを占有フィールドと組み合わせることで、モデルは環境をより深く理解し、より正確な予測を行うことができます。 要約すると、OccNeRF メソッドは、パラメーター化された占有フィールド、ボリューム レンダリング、およびマルチフレームのフォトメトリック一貫性とオープンボキャブラリーのセマンティック セグメンテーション モデルを組み合わせて使用することにより、自動運転シナリオにおける高精度の占有予測を実現します。この手法により、自動運転システムにより多くの環境情報が提供され、自動運転の安全性・信頼性の向上が期待されます。

- 論文リンク: https://arxiv.org/pdf/2312.09243.pdf
- コードリンク: https://github.com /LinShan-Bin/OccNeRF
OccNeRF 問題の背景
近年、人工知能技術の急速な発展に伴い、人工知能技術の進歩は大きく進んでいます。自動運転の分野。 3D 認識は自動運転の基礎であり、その後の計画や意思決定に必要な情報を提供します。従来の方法では、LIDAR は正確な 3D データを直接キャプチャできますが、センサーのコストが高く、スキャンポイントがまばらなため、実用化は制限されています。対照的に、画像ベースの 3D センシング方法は低コストで効果的であるため、ますます注目を集めています。マルチカメラ 3Dオブジェクト検出は、しばらくの間、3Dシーン理解タスクの主流でしたが、現実世界の無限のカテゴリに対応できず、データロングテール分布の影響##の影響を受けます。
3D 占有予測は、マルチビュー入力を通じて周囲のシーンのジオメトリを直接再構築することで、これらの欠点を十分に補うことができます。既存の手法のほとんどはモデル設計とパフォーマンスの最適化に焦点を当てており、LiDAR 点群によって生成されたラベルに依存してネットワーク トレーニングを監視しますが、これは画像ベースのシステムでは利用できません。言い換えれば、トレーニング データを収集するには高価なデータ収集車両を使用する必要があり、LiDAR 点群支援アノテーションがなければ大量の実データが無駄になるため、3D 占有予測の開発がある程度制限されます。したがって、自己監視型 3D 占有予測を探求することは、非常に価値のある方向性です。OccNeRF アルゴリズムの詳細説明
次の図は、OccNeRF メソッドの基本プロセスを示しています。モデルはマルチカメラ画像
を入力として受け取り、最初に 2D バックボーンを使用して N 個の写真の特徴を抽出し、次に単純な投影と双線形補間 ( で) を通じて 3D 特徴を直接取得します。パラメーター化された空間 (以下))、最後に 3D CNN ネットワークを通じて 3D 特徴を最適化し、予測結果を出力します。モデルをトレーニングするために、OccNeRF メソッドはボリューム レンダリングを通じて現在のフレームの深度マップを生成し、前後のフレームを導入して測光損失を計算します。より多くのタイミング情報を導入するために、OccNeRF は占有フィールドを使用してマルチフレーム深度マップをレンダリングし、損失関数を計算します。同時に、OccNeRF は 2D セマンティック マップも同時にレンダリングし、Open Lexicon Semantic Segmentation Model によって管理されます。
パラメータ化された占有フィールド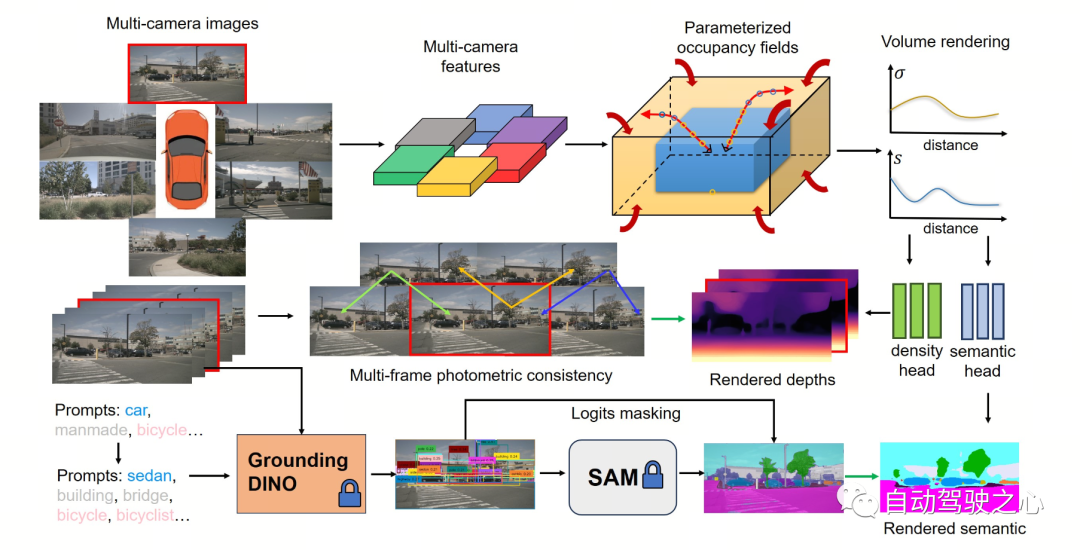
知覚範囲のギャップを解決するために提案されています
これ質問。理論的には、カメラは無限の距離にある物体を捉えることができますが、以前の占有予測モデルはより近い空間 (たとえば、40 m 以内) のみを考慮していました。教師あり手法では、モデルは教師信号に基づいて遠くの物体を無視することを学習できますが、教師なし手法では、近くの空間のみが依然として考慮されている場合、画像内に多数の範囲外の物体が存在するとマイナスの影響が生じます。最適化プロセスへの影響。影響。これに基づいて、OccNeRF はパラメーター化された占有フィールドを採用して、無制限の範囲の屋外シーンをモデル化します。
OccNeRF のパラメータ化空間は内部と外部に分かれています。内部空間は元の座標の線形マッピングであり、高解像度が維持されますが、外部空間は無限の範囲を表します。具体的には、OccNeRF は 3D 空間内の点の 座標に次の変更を加えます:
ここで、 は 座標です。 # は内部空間に対応する境界値を示す調整可能なパラメータであり、 も内部空間が占める割合を示す調整可能なパラメータです。パラメータ化された占有フィールドを生成する場合、OccNeRF は最初にパラメータ化された空間でサンプリングし、逆変換を通じて元の座標を取得し、次に元の座標を画像平面に投影し、最後にサンプリングと 3 次元畳み込みを通じて占有フィールドを取得します。
マルチフレーム深度推定占有ネットワークをトレーニングするために、OccNeRF はボリューム レンダリングを使用して占有を深度マップに変換し、測光損失関数を通じてそれを監視することを選択します。サンプリング戦略は、深度マップをレンダリングするときに重要です。パラメータ化された空間で、奥行きや視差に基づいて均一にサンプリングすると、サンプリング ポイントが内部空間または外部空間で不均一に分布し、最適化プロセスに影響を及ぼします。したがって、OccNeRF は、カメラの中心が原点に近いという前提の下で、パラメータ化された空間内で均一に直接サンプリングすることを提案します。さらに、OccNeRF はトレーニング中にマルチフレーム深度マップをレンダリングおよび監視します。 下の図は、パラメータ化された空間表現を使用する利点を視覚的に示しています。 (3 行目はパラメータ化された空間を使用し、2 行目は使用しません。)
cue word 最適化 で、nuScenes 内の曖昧なカテゴリを正確な説明に置き換えます。 OccNeRF では、プロンプト ワードを最適化するために 3 つの戦略が使用されます。曖昧な単語の置換 (自動車はセダンに置き換えられます)、単語間のマルチワード (人工物は建物、看板、橋に置き換えられます)、および追加情報の導入 (自転車は自転車、自転車に置き換えられます)。 2 つ目は、SAM によって与えられるピクセルごとの信頼度ではなく、Grounding DINO の検出フレームの信頼度 に基づいてカテゴリを決定することです。 OccNeRF によって生成されるセマンティック ラベル効果は次のとおりです。
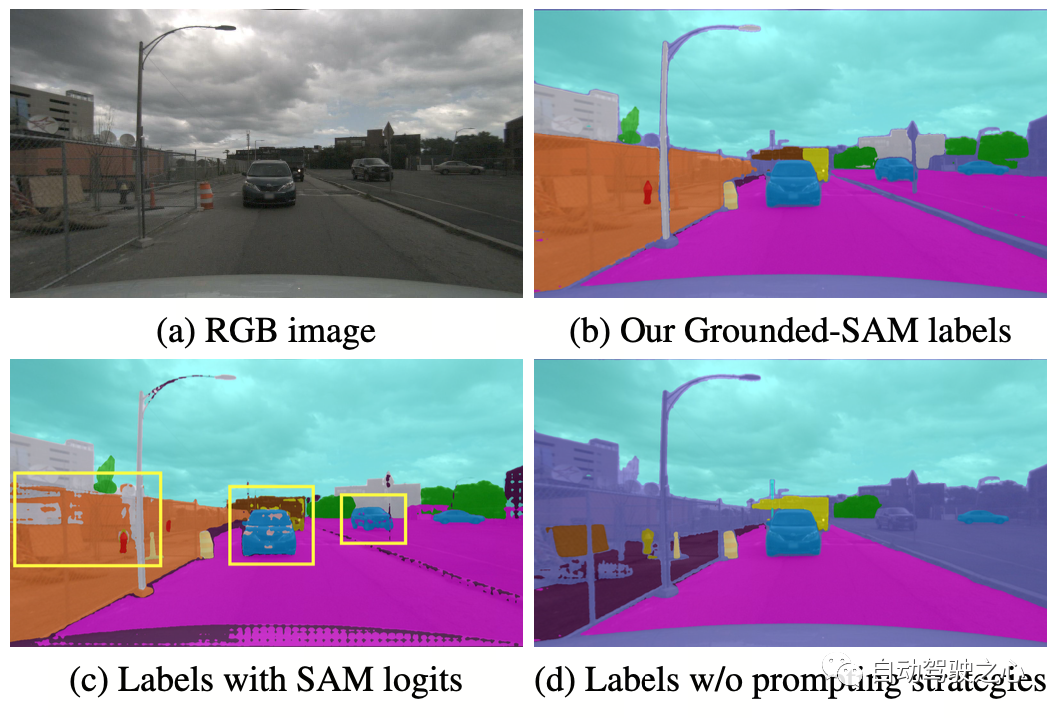
OccNeRF は nuScenes で実験を実施し、主に多くの実験を完了しました。パースペクティブの自己監視型深度推定および 3D 占有予測タスク。
マルチビュー自己教師あり深度推定
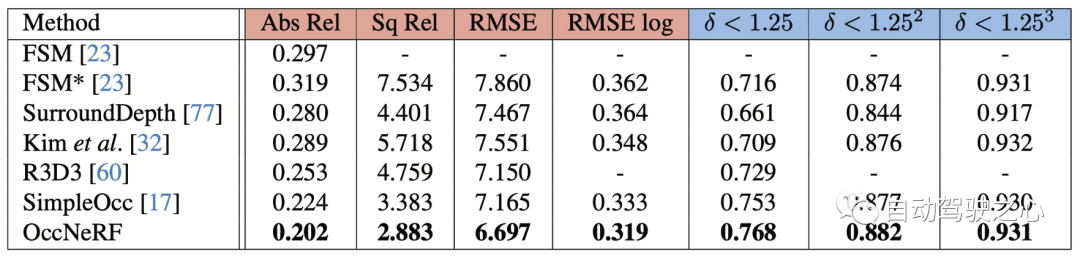
OccNeRF の nuScenes でのマルチビュー自己教師あり深度推定のパフォーマンスを以下の表に示します。 3D モデリングに基づく OccNeRF は、2D 手法を大幅に上回り、SimpleOcc も上回っていることがわかります。これは主に、OccNeRF が屋外シーン向けにモデル化する無制限の空間範囲によるものです。
 論文内のいくつかの視覚化は次のとおりです:
論文内のいくつかの視覚化は次のとおりです:
 3D 占有率予測
3D 占有率予測
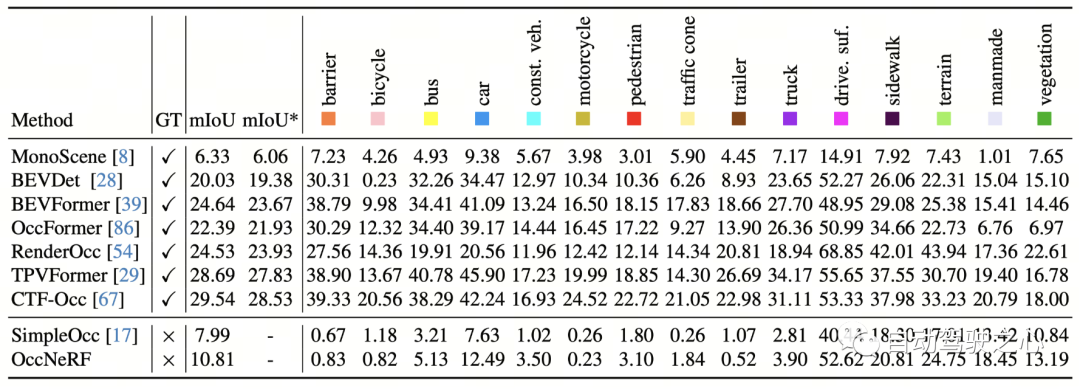
OccNeRF in nuScenes 3D 占有予測のパフォーマンスを以下の表に示します。 OccNeRF は注釈付きデータをまったく使用しないため、そのパフォーマンスは依然として教師ありメソッドよりも遅れています。ただし、走行可能な路面や人工物などの一部のカテゴリでは、教師あり手法と同等のパフォーマンスを達成しています。
 # 記事内の視覚化の一部は次のとおりです:
# 記事内の視覚化の一部は次のとおりです:
 #概要
#概要
多くの自動車メーカーが LiDAR センサーを廃止しようとしている現在、ラベルのない数千の画像データをどのように活用するかが重要な問題です。そして、OccNeRF は私たちに貴重な試みをもたらしてくれました。
元のリンク: https://mp.weixin.qq.com/s/UiYEeauAGVtT0c5SB2tHEA
以上がOccNeRF: LIDAR データの監視はまったく必要ありませんの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7802
7802
 15
1645
14
1402
52
1300
25
1236
29
15
1645
14
1402
52
1300
25
1236
29

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
原題: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving 論文リンク: https://arxiv.org/pdf/2402.02519.pdf コードリンク: https://github.com/HKUST-Aerial-Robotics/SIMPL 著者単位: 香港科学大学DJI 論文のアイデア: この論文は、自動運転車向けのシンプルで効率的な動作予測ベースライン (SIMPL) を提案しています。従来のエージェントセントとの比較
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
