

ラージ オブジェクトからメモリを解放する


php Xiaobian Yuzi は、メモリ使用量を最適化するテクニック、つまり大きなオブジェクトからメモリを解放するテクニックを紹介します。開発プロセスでは、大きな配列や大きなデータベース クエリ結果などの大きなオブジェクトを作成することがよくありますが、これらのオブジェクトは多くのメモリ リソースを消費します。これらのオブジェクトの使用が完了したら、適時にメモリを解放するのが良いプログラミング習慣です。この記事では、アプリケーションのパフォーマンスと効率を向上させるために、ラージ オブジェクトからメモリを解放する方法を説明します。
質問内容
わからないことがありました。皆さんも助けていただければ幸いです。
###リソース:###https://medium.com/@chaewonkong/solve-memory-leak-issues-in-go-http-clients-ba0b04574a83
- https://www.golinuxcloud.com/golang-garbage-collector/
- いくつかの記事で、大きなスライスとマップ (これはすべての参照型に当てはまると思います) を
に設定することで、gc ジョブが必要なくなった後、簡素化できると読みました。これは私が読んだ例の 1 つです:
リーリー
私の理解では、関数
が完了すると、data 変数はスコープ外になり、基本的に存在しなくなります。次に、gc は []byte スライス (data が指すスライス) への参照がないことを確認し、メモリをクリアします。
を nil に設定する ガベージ コレクションを改善するにはどうすればよいですか?
###ありがとう!
他の人がすでに指摘しているように、戻る前に
data = nilを設定しても、gc 側では何も変わりません。 go コンパイラーは最適化を適用し、golang のガベージ コレクターはさまざまな段階で動作します。最も簡単に言うと (多くの省略と簡略化が行われていますが)、
data = nil を設定し、基礎となるスライスへの参照をすべて削除しても、参照されなくなったメモリのアトミック スタイルの解放はトリガーされません。スライスが参照されなくなると、そのスライスとしてマークが付けられ、関連付けられたメモリは次のスキャンまで解放されません。
ガベージ コレクションは難しい問題です。その主な理由は、ガベージ コレクションは、すべてのユースケースに対して最良の結果を生み出す最適な解決策がある種類の問題ではないからです。 Go ランタイムは長年にわたって大幅に進化しており、重要な作業はランタイム ガベージ コレクターで行われます。その結果、まれに、単純な somevar = nil によって、顕著な違いどころか、小さな違いが生じることがあります。
ガベージ コレクション (または一般的なランタイム メモリ管理) に関連するランタイム オーバーヘッドに影響を与える可能性のある、単純な経験則タイプのヒントを探している場合は、この文が漠然とその 1 つをカバーしているように見えることはわかっています。質問: ###
大きなスライスとマッピングを設定することで gc の作業を簡素化できることが提案されています
これにより、コードを分析するときに重要な結果が得られる可能性があります。処理する必要がある大量のデータを読み取る場合、または他の種類のバッチ操作を実行してスライスを返す必要がある場合、次のような内容を記述することは珍しくありません。 リーリー
コードを次のように変更することで簡単に最適化できます。リーリー
最初の実装では、len
とcap
を使用して 0 のスライスを作成します。初めてappend を呼び出すと、スライスの現在の容量を超えるため、ランタイムがメモリを割り当てます。 こちらで説明されているように、新しい容量の計算は非常に簡単で、メモリが割り当てられ、データが割り当てられてコピーされます。
リーリー
基本的に、追加するスライスがいっぱいになったときに append を呼び出すたびに (つまり、len ==
)、利用可能なホールドを割り当てることになります。 : (len 1) * 2 要素の新しいスライス。最初の例では、data が len および cap == 0 で始まることがわかっているので、これが何を意味するかを見てみましょう。
リーリー
スライス内のデータ構造が大きい場合 (つまり、多数の入れ子構造、多数の間接参照など)、この頻繁な再割り当てとコピーは非常にコストがかかる可能性があります。コードにこれらのループが多数含まれている場合、pprof にループが表示され始めます (gcmalloc の呼び出しに多くの時間が費やされるようになります)。さらに、15 個の入力値を処理している場合、データ スライスは次のようになります:
リーリー
これは、必要な値が 15 個だけの場合に 30 個の値にメモリを割り当て、そのメモリを徐々に大きくなる 4 つのチャンクに割り当て、再割り当てのたびにデータをコピーすることを意味します。
一度割り当てられるため、再割り当てやコピーは必要なく、返されたスライスはメモリ領域の半分を占有します。この意味で、最初に大きなメモリ ブロックを割り当てて、後で必要となる増分割り当てとコピー呼び出しの数を減らし、全体的なランタイム コストを削減します。
<h2 id="如果我不知道需要多少内存怎么办">如果我不知道需要多少内存怎么办</h2>
<p>这是一个公平的问题。这个例子并不总是适用。在这种情况下,我们知道需要多少个元素,并且可以相应地分配内存。有时,世界并不是这样运作的。如果您不知道最终需要多少数据,那么您可以:</p>
<ol>
<li>做出有根据的猜测:gc 很困难,而且与您不同的是,编译器和 go 运行时缺乏模糊逻辑,人们必须提出现实、合理的猜测。有时它会像这样简单:“嗯,我从该数据源获取数据,我们只存储最后 n 个元素,所以最坏的情况下,我将处理 n 个元素” em>,有时它有点模糊,例如:您正在处理包含 sku、产品名称和库存数量的 csv。您知道 sku 的长度,可以假设库存数量为 1 到 5 位数字之间的整数,产品名称平均为 2-3 个单词长。英文单词的平均长度为 6 个字符,因此您可以粗略地了解 csv 行由多少字节组成:假设 sku == 10 个字符,80 个字节,产品描述 2.5 * 6 * 8 = 120 个字节,以及 ~ 4 个字节表示库存计数 + 2 个逗号和一个换行符,平均预期行长度为 207 个字节,为了谨慎起见,我们将其称为 200。统计输入文件,将其大小(以字节为单位)除以 200,您应该对行数有一个可用的、稍微保守的估计。在该代码末尾添加一些日志记录,比较上限与估计值,然后您可以相应地调整您的预测计算。</li>
<li>分析您的代码。有时,您会发现自己正在开发新功能或全新项目,而您没有历史数据可以依靠进行猜测。在这种情况下,您可以简单地猜测,运行一些测试场景,或者启动一个测试环境来提供您的代码生产数据版本并分析代码。当您正在主动分析一两个切片/映射的内存使用/运行时成本时,我必须强调<strong>这是优化</strong>。仅当这是瓶颈或明显问题时(例如,运行时内存分配阻碍了整体分析),您才应该在这方面花费时间。在绝大多数情况下,这种级别的优化将牢牢地属于微优化的范畴。 <strong>坚持80-20原则</strong>
</li>
</ol>
<h1 id="回顾">回顾</h1>
<p>不,将一个简单的切片变量设置为 nil 在 99% 的情况下不会产生太大影响。创建和附加到地图/切片时,更可能产生影响的是通过使用 <code>make() + 指定合理的 cap 值来减少无关分配。其他可以产生影响的事情是使用指针类型/接收器,尽管这是一个需要深入研究的更复杂的主题。现在,我只想说,我一直在开发一个代码库,该代码库必须对远远超出典型 uint64 范围的数字进行操作,不幸的是,我们必须能够以更精确的方式使用小数比 float64 将允许。我们通过使用像 holiman/uint256 这样的东西解决了 uint64 问题,它使用指针接收器,并解决shopspring/decimal 的十进制问题,它使用值接收器并复制所有内容。在花费大量时间优化代码之后,我们已经达到了使用小数时不断复制值的性能影响已成为问题的地步。看看这些包如何实现加法等简单操作,并尝试找出哪个操作成本更高:
// original a, b := 1, 2 a += b // uint256 version a, b := uint256.NewUint(1), uint256.NewUint(2) a.Add(a, b) // decimal version a, b := decimal.NewFromInt(1), decimal.NewFromInt(2) a = a.Add(b)
这些只是我在最近的工作中花时间优化的几件事,但从中得到的最重要的一点是:
过早的优化是万恶之源
当您处理更复杂的问题/代码时,您需要花费大量精力来研究切片或映射的分配周期,因为潜在的瓶颈和优化需要付出很大的努力。您可以而且可以说应该采取措施避免过于浪费(例如,如果您知道所述切片的最终长度是多少,则设置切片上限),但您不应该浪费太多时间手工制作每一行,直到该代码的内存占用尽可能小。成本将是:代码更脆弱/更难以维护和阅读,整体性能可能会恶化(说真的,你可以相信 go 运行时会做得很好),大量的血、汗和泪水,以及急剧下降在生产力方面。
以上がラージ オブジェクトからメモリを解放するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7318
7318
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 Xiaohonshu でメモリをクリーニングする詳細な手順
Apr 26, 2024 am 10:43 AM
Xiaohonshu でメモリをクリーニングする詳細な手順
Apr 26, 2024 am 10:43 AM
1. 小紅書を開き、右下隅の「自分」をクリックします。 2. 設定アイコンをクリックし、「一般」をクリックします。 3. 「キャッシュのクリア」をクリックします。
 Deepseekをローカルで微調整する方法
Feb 19, 2025 pm 05:21 PM
Deepseekをローカルで微調整する方法
Feb 19, 2025 pm 05:21 PM
Deepseekクラスモデルのローカル微調整は、コンピューティングリソースと専門知識が不十分であるという課題に直面しています。これらの課題に対処するために、次の戦略を採用できます。モデルの量子化:モデルパラメーターを低精度の整数に変換し、メモリフットプリントを削減します。小さなモデルを使用してください。ローカルの微調整を容易にするために、より小さなパラメーターを備えた前提型モデルを選択します。データの選択と前処理:高品質のデータを選択し、適切な前処理を実行して、モデルの有効性に影響を与えるデータ品質の低下を回避します。バッチトレーニング:大規模なデータセットの場合、メモリオーバーフローを回避するためにトレーニングのためにバッチにデータをロードします。 GPUでの加速:独立したグラフィックカードを使用して、トレーニングプロセスを加速し、トレーニング時間を短縮します。
 Huawei端末のメモリが足りない場合の対処法(メモリ不足の問題を解決する実践的な方法)
Apr 29, 2024 pm 06:34 PM
Huawei端末のメモリが足りない場合の対処法(メモリ不足の問題を解決する実践的な方法)
Apr 29, 2024 pm 06:34 PM
ファーウェイ携帯電話のメモリ不足は、モバイルアプリケーションやメディアファイルの増加に伴い、多くのユーザーが直面する一般的な問題となっています。ユーザーが携帯電話のストレージ容量を最大限に活用できるように、この記事では、Huawei 携帯電話のメモリ不足の問題を解決するためのいくつかの実用的な方法を紹介します。 1. キャッシュのクリーンアップ: 履歴レコードと無効なデータを削除してメモリ領域を解放し、アプリケーションによって生成された一時ファイルをクリアします。 Huawei携帯電話の設定で「ストレージ」を見つけ、「キャッシュのクリア」をクリックし、「キャッシュのクリア」ボタンを選択してアプリケーションのキャッシュファイルを削除します。 2. 使用頻度の低いアプリケーションをアンインストールする: メモリ領域を解放するには、使用頻度の低いアプリケーションをいくつか削除します。電話画面の上部にドラッグし、削除したいアプリケーションの「アンインストール」アイコンを長押しして、確認ボタンをクリックするとアンインストールが完了します。 3.モバイルアプリへ
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
 電話機内の他のファイルは何ですか?
Apr 07, 2024 pm 09:20 PM
電話機内の他のファイルは何ですか?
Apr 07, 2024 pm 09:20 PM
携帯電話のストレージに表示される「その他」とは何ですか? 携帯電話のストレージの「その他」には、携帯電話のシステム ファイルの 2 つの部分が含まれています。携帯電話にソフトウェアをダウンロードするときに自動的に生成されるファイル。携帯電話のストレージの「その他の」部分が占有しているメモリをクリアする方法: 携帯電話に属するシステム ファイルには通常、保護機能が組み込まれているため、クリアすることはできません。携帯電話の容量における分類は、主に携帯電話のキャッシュ ファイルであり、次のカテゴリに分類されます。 キャッシュ ディレクトリ フォルダ パス: c: システム キャッシュ。定期的にクリアできます。一時ディレクトリ内のすべての一時フォルダーをクリアすることをお勧めします。簡単に理解すると、その他は電話機が認識できないファイルの種類です。携帯電話が異なれば、さらにはソフトウェア環境も異なります。さらに、プログラムのキャッシュは別のものであるかのように扱われます。携帯電話のその他
 Edge ブラウザがメモリを大量に消費する場合の対処方法 Edge ブラウザがメモリを大量に消費する場合の対処方法
May 09, 2024 am 11:10 AM
Edge ブラウザがメモリを大量に消費する場合の対処方法 Edge ブラウザがメモリを大量に消費する場合の対処方法
May 09, 2024 am 11:10 AM
1. まず、Edge ブラウザに入り、右上隅にある 3 つの点をクリックします。 2. 次に、タスクバーの[拡張機能]を選択します。 3. 次に、不要なプラグインを閉じるかアンインストールします。
 わずか 250 ドルで、Hugging Face のテクニカル ディレクターが Llama 3 を段階的に微調整する方法を教えます
May 06, 2024 pm 03:52 PM
わずか 250 ドルで、Hugging Face のテクニカル ディレクターが Llama 3 を段階的に微調整する方法を教えます
May 06, 2024 pm 03:52 PM
Meta が立ち上げた Llama3、MistralAI が立ち上げた Mistral および Mixtral モデル、AI21 Lab が立ち上げた Jamba など、おなじみのオープンソースの大規模言語モデルは、OpenAI の競合相手となっています。ほとんどの場合、モデルの可能性を最大限に引き出すには、ユーザーが独自のデータに基づいてこれらのオープンソース モデルを微調整する必要があります。単一の GPU で Q-Learning を使用して、大規模な言語モデル (Mistral など) を小規模な言語モデルに比べて微調整することは難しくありませんが、Llama370b や Mixtral のような大規模なモデルを効率的に微調整することは、これまで課題として残されています。 。したがって、HuggingFace のテクニカル ディレクター、Philipp Sch 氏は次のように述べています。
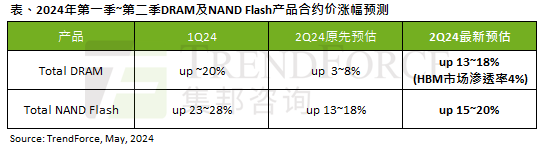 AIの波の影響は明らかで、トレンドフォースは今四半期のDRAMメモリとNANDフラッシュメモリの契約価格の上昇予測を上方修正した。
May 07, 2024 pm 09:58 PM
AIの波の影響は明らかで、トレンドフォースは今四半期のDRAMメモリとNANDフラッシュメモリの契約価格の上昇予測を上方修正した。
May 07, 2024 pm 09:58 PM
TrendForceの調査レポートによると、AIの波はDRAMメモリとNANDフラッシュメモリ市場に大きな影響を与えています。 5 月 7 日のこのサイトのニュースで、TrendForce は本日の最新調査レポートの中で、同庁が今四半期 2 種類のストレージ製品の契約価格の値上げを拡大したと述べました。具体的には、TrendForce は当初、2024 年第 2 四半期の DRAM メモリの契約価格が 3 ~ 8% 上昇すると予測していましたが、現在は NAND フラッシュ メモリに関しては 13 ~ 18% 上昇すると予測しています。 18%、新しい推定値は 15% ~ 20% ですが、eMMC/UFS のみが 10% 増加しています。 ▲画像出典 TrendForce TrendForce は、同庁は当初、今後も継続することを期待していたと述べた。
