

CSVをバイト単位で読み取る


php エディタ Xigua では、CSV ファイルをバイト単位で読み込む方法を紹介します。 CSV は、表形式データの保存と交換によく使用される一般的なデータ形式です。従来の方法では、ファイル操作関数を使用して CSV ファイルを 1 行ずつ読み取り、配列またはオブジェクトとして保存します。ただし、CSV ファイルをバイト単位で読み取ることで、大規模なデータ セットをより効率的に処理でき、メモリ使用量の点でより経済的になります。このメソッドは、fopen 関数を使用してファイルをバイナリ モードで開き、fread 関数を使用してファイルの内容を読み取ることで実装できます。読み取られたバイトは、データ分析および操作のために配列またはその他のデータ構造にさらに処理できます。この方法により、PHP の機能を活用して CSV ファイルを処理し、データ処理の効率を向上させることができます。
質問内容
csvファイルを2Dバイトスライスに読み込むときに、奇妙な動作が発生しました。最初の 42 行は問題ありませんが、余分な行末がデータに挿入されているようで、事態が混乱します:
最初の 42 回の最初の行:
リーリー最初の行を 43 行の後に追加します:
リーリー問題を再現するための最小限のコード:
リーリー私が使用した CSV:
リーリーrow[][]byte には行ごとの CSV データが含まれると予想していました
回避策
すでに提案されているように、本当に encoding/csv を使用する必要があります。 #####。
言い換えれば、問題の原因は
bytes() 関数の上の godoc: にあります。
リーリー
したがって、その後の
の呼び出しでは、返されたバイト スライスが変更される可能性があります。これを回避するには、 のようなバイトスライスをコピーする必要があります。
リーリー
以上がCSVをバイト単位で読み取るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1662
1662
 14
1419
52
1313
25
1262
29
1235
24
14
1419
52
1313
25
1262
29
1235
24

 Huawei端末のメモリが足りない場合の対処法(メモリ不足の問題を解決する実践的な方法)
Apr 29, 2024 pm 06:34 PM
Huawei端末のメモリが足りない場合の対処法(メモリ不足の問題を解決する実践的な方法)
Apr 29, 2024 pm 06:34 PM
ファーウェイ携帯電話のメモリ不足は、モバイルアプリケーションやメディアファイルの増加に伴い、多くのユーザーが直面する一般的な問題となっています。ユーザーが携帯電話のストレージ容量を最大限に活用できるように、この記事では、Huawei 携帯電話のメモリ不足の問題を解決するためのいくつかの実用的な方法を紹介します。 1. キャッシュのクリーンアップ: 履歴レコードと無効なデータを削除してメモリ領域を解放し、アプリケーションによって生成された一時ファイルをクリアします。 Huawei携帯電話の設定で「ストレージ」を見つけ、「キャッシュのクリア」をクリックし、「キャッシュのクリア」ボタンを選択してアプリケーションのキャッシュファイルを削除します。 2. 使用頻度の低いアプリケーションをアンインストールする: メモリ領域を解放するには、使用頻度の低いアプリケーションをいくつか削除します。電話画面の上部にドラッグし、削除したいアプリケーションの「アンインストール」アイコンを長押しして、確認ボタンをクリックするとアンインストールが完了します。 3.モバイルアプリへ
 Beyond CompareでCSVファイルを比較する詳しい操作方法
Apr 22, 2024 am 11:52 AM
Beyond CompareでCSVファイルを比較する詳しい操作方法
Apr 22, 2024 am 11:52 AM
BeyondCompare ソフトウェアをインストールした後、比較する CSV ファイルを選択し、ファイルを右クリックして、展開されたメニューで [比較] オプションを選択します。テキスト比較セッションがデフォルトで開きます。テキスト比較セッション ツールバーをクリックすると、それぞれ [すべて [、] 相違点 [、[同じ]] ボタンが表示され、ファイルの相違点をより直観的かつ正確に表示できます。方法 2: テーブル比較モードで BeyondCompare を開き、テーブル比較セッションを選択して、セッション操作インターフェイスを開きます。 [ファイルを開く]ボタンをクリックし、比較するCSVファイルを選択します。テーブル比較セッション操作インターフェースのツールバーにある不等号 [≠] ボタンをクリックすると、ファイル間の差異が表示されます。
 Xiaohonshu でメモリをクリーニングする詳細な手順
Apr 26, 2024 am 10:43 AM
Xiaohonshu でメモリをクリーニングする詳細な手順
Apr 26, 2024 am 10:43 AM
1. 小紅書を開き、右下隅の「自分」をクリックします。 2. 設定アイコンをクリックし、「一般」をクリックします。 3. 「キャッシュのクリア」をクリックします。
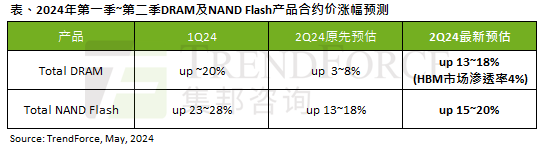 AIの波の影響は明らかで、トレンドフォースは今四半期のDRAMメモリとNANDフラッシュメモリの契約価格の上昇予測を上方修正した。
May 07, 2024 pm 09:58 PM
AIの波の影響は明らかで、トレンドフォースは今四半期のDRAMメモリとNANDフラッシュメモリの契約価格の上昇予測を上方修正した。
May 07, 2024 pm 09:58 PM
TrendForceの調査レポートによると、AIの波はDRAMメモリとNANDフラッシュメモリ市場に大きな影響を与えています。 5 月 7 日のこのサイトのニュースで、TrendForce は本日の最新調査レポートの中で、同庁が今四半期 2 種類のストレージ製品の契約価格の値上げを拡大したと述べました。具体的には、TrendForce は当初、2024 年第 2 四半期の DRAM メモリの契約価格が 3 ~ 8% 上昇すると予測していましたが、現在は NAND フラッシュ メモリに関しては 13 ~ 18% 上昇すると予測しています。 18%、新しい推定値は 15% ~ 20% ですが、eMMC/UFS のみが 10% 増加しています。 ▲画像出典 TrendForce TrendForce は、同庁は当初、今後も継続することを期待していたと述べた。
 navicat でクエリされたデータをエクスポートする方法
Apr 24, 2024 am 04:15 AM
navicat でクエリされたデータをエクスポートする方法
Apr 24, 2024 am 04:15 AM
Navicat でクエリ結果をエクスポートする: クエリを実行します。クエリ結果を右クリックし、[データのエクスポート] を選択します。必要に応じてエクスポート形式を選択します: CSV: フィールド区切り文字はカンマです。 Excel: Excel 形式を使用したテーブル ヘッダーが含まれます。 SQL スクリプト: クエリ結果を再作成するために使用される SQL ステートメントが含まれています。エクスポート オプション (エンコード、改行など) を選択します。エクスポート先とファイル名を選択します。 「エクスポート」をクリックしてエクスポートを開始します。
 Edge ブラウザがメモリを大量に消費する場合の対処方法 Edge ブラウザがメモリを大量に消費する場合の対処方法
May 09, 2024 am 11:10 AM
Edge ブラウザがメモリを大量に消費する場合の対処方法 Edge ブラウザがメモリを大量に消費する場合の対処方法
May 09, 2024 am 11:10 AM
1. まず、Edge ブラウザに入り、右上隅にある 3 つの点をクリックします。 2. 次に、タスクバーの[拡張機能]を選択します。 3. 次に、不要なプラグインを閉じるかアンインストールします。
 Deepseekをローカルで微調整する方法
Feb 19, 2025 pm 05:21 PM
Deepseekをローカルで微調整する方法
Feb 19, 2025 pm 05:21 PM
Deepseekクラスモデルのローカル微調整は、コンピューティングリソースと専門知識が不十分であるという課題に直面しています。これらの課題に対処するために、次の戦略を採用できます。モデルの量子化:モデルパラメーターを低精度の整数に変換し、メモリフットプリントを削減します。小さなモデルを使用してください。ローカルの微調整を容易にするために、より小さなパラメーターを備えた前提型モデルを選択します。データの選択と前処理:高品質のデータを選択し、適切な前処理を実行して、モデルの有効性に影響を与えるデータ品質の低下を回避します。バッチトレーニング:大規模なデータセットの場合、メモリオーバーフローを回避するためにトレーニングのためにバッチにデータをロードします。 GPUでの加速:独立したグラフィックカードを使用して、トレーニングプロセスを加速し、トレーニング時間を短縮します。
 わずか 250 ドルで、Hugging Face のテクニカル ディレクターが Llama 3 を段階的に微調整する方法を教えます
May 06, 2024 pm 03:52 PM
わずか 250 ドルで、Hugging Face のテクニカル ディレクターが Llama 3 を段階的に微調整する方法を教えます
May 06, 2024 pm 03:52 PM
Meta が立ち上げた Llama3、MistralAI が立ち上げた Mistral および Mixtral モデル、AI21 Lab が立ち上げた Jamba など、おなじみのオープンソースの大規模言語モデルは、OpenAI の競合相手となっています。ほとんどの場合、モデルの可能性を最大限に引き出すには、ユーザーが独自のデータに基づいてこれらのオープンソース モデルを微調整する必要があります。単一の GPU で Q-Learning を使用して、大規模な言語モデル (Mistral など) を小規模な言語モデルに比べて微調整することは難しくありませんが、Llama370b や Mixtral のような大規模なモデルを効率的に微調整することは、これまで課題として残されています。 。したがって、HuggingFace のテクニカル ディレクター、Philipp Sch 氏は次のように述べています。
