

Linux グループのスケジューリングの簡単な分析

Linux システムは、マルチタスクの同時実行をサポートするオペレーティング システムであり、複数のプロセスを同時に実行できるため、システムの使用率と効率が向上します。ただし、Linux システムが最適なパフォーマンスを達成するには、そのプロセス スケジューリング方法を理解し、習得する必要があります。プロセス スケジューリングとは、複数のタスクの同時実行を実現するために、特定のアルゴリズムと戦略に基づいてプロセッサ リソースをさまざまなプロセスに動的に割り当てるオペレーティング システムの機能を指します。 Linux システムには多くのプロセス スケジューリング方法があり、その 1 つがグループ スケジューリングです。グループ スケジューリングは、異なるプロセス グループが一定の割合でプロセッサ リソースを共有できるようにするグループ ベースのプロセス スケジューリング方法であり、それによって公平性と効率のバランスを実現します。この記事では、グループ スケジューリングの原理、実装、構成、利点と欠点など、Linux グループ スケジューリング方法を簡単に分析します。
cgroup とグループのスケジューリング
Linux カーネルは、プロセスのグループ化と、さまざまなリソースをグループごとに分割することをサポートできる制御グループ機能 (cgroup、Linux 2.6.24 以降) を実装しています。たとえば、グループ 1 には CPU が 30%、ディスク IO が 50%、グループ 2 には CPU が 10%、ディスク IO が 20% などとなります。詳細については、cgroup 関連の記事を参照してください。
cgroup はさまざまな種類のリソースの分割をサポートしており、CPU リソースもそのうちの 1 つであり、グループ スケジューリングにつながります。
Linux カーネルでは、従来のスケジューラはプロセスに基づいてスケジュールされます。ユーザー A と B が主にプログラムのコンパイルに使用されるマシンを共有しているとします。 A と B が CPU リソースを公平に共有できることを期待できますが、ユーザー A が make -j8 (8 スレッドの並列 make) を使用し、ユーザー B が make を直接使用した場合 (make プログラムがデフォルトの優先順位を使用すると仮定して)、ユーザー A の make プログラムはユーザー B の 8 倍のプロセス数が生成されるため、ユーザー B の (およそ) 8 倍の CPU を占有します。スケジューラはプロセスに基づいているため、ユーザー A が持つプロセスが多いほど、スケジュールされる可能性が高くなり、CPU に対する競争力が高くなります。
ユーザー A と B が CPU を公平に共有できるようにするにはどうすればよいですか?グループ スケジューリングを使用すると、これを行うことができます。ユーザー A とユーザー B が属するプロセスはそれぞれ 1 つのグループに分けられ、スケジューラはまず 2 つのグループから 1 つのグループを選択し、選択したグループから実行するプロセスを選択します。 2 つのグループが選択される確率が同じである場合、ユーザー A と B はそれぞれ CPU の約 50% を占有することになります。
関連するデータ構造
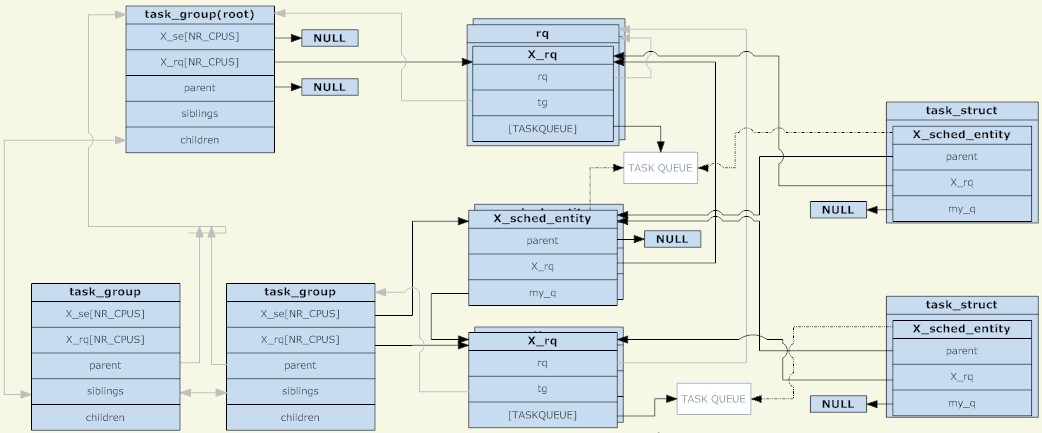
Linux カーネルでは、task_group 構造を使用してグループ スケジュール グループを管理します。既存のすべての task_group はツリー構造 (cgroup のディレクトリ構造に対応) を形成します。
task_group には、任意のスケジューリング カテゴリ (具体的には、リアルタイム プロセスと通常のプロセス) のプロセスを含めることができるため、task_group は、スケジューリング戦略ごとに一連のスケジューリング構造を提供する必要があります。ここで説明する一連のスケジューリング構造には、主に、スケジューリング エンティティと実行キューの 2 つの部分が含まれます (どちらも CPU ごとに共有されます)。スケジューリング エンティティは実行キューに追加されます。task_group の場合、そのスケジューリング エンティティは親 task_group の実行キューに追加されます。
スケジューリング エンティティのようなものはなぜ存在するのでしょうか?スケジュールされたオブジェクトには task_group と task の 2 つのタイプがあるため、それらを表すには抽象構造が必要です。スケジューリング エンティティが task_group を表す場合、その my_q フィールドは、このスケジューリング グループに対応する実行キューを指します。それ以外の場合、my_q フィールドは NULL で、スケジューリング エンティティはタスクを表します。スケジューリング エンティティの my_q の反対は、親ノードの実行キューであり、このスケジューリング エンティティが配置される実行キューです。
したがって、スケジューリング エンティティと実行キューは別のツリー構造を形成し、その非リーフ ノードのそれぞれが task_group のツリー構造に対応し、リーフ ノードが特定のタスクに対応します。非 TASK_RUNNING 状態のプロセスが実行キューに入れられないのと同様に、グループ内に TASK_RUNNING 状態のプロセスが存在しない場合、このグループ (対応するスケジューリング エンティティ) は上位レベルの実行キューに入れられません。明確に言うと、スケジューリング グループが作成される限り、それに対応する task_group は task_group で構成されるツリー構造に必ず存在し、それに対応するスケジューリング エンティティが実行キューとスケジューリング エンティティで構成されるツリー構造に存在するかどうかは、このグループには TASK_RUNNING 状態のプロセスがあります。
ルート ノードとしての task_group にはスケジューリング エンティティがありません。スケジューラは常に実行キューから開始して次のスケジューリング エンティティを選択します (ルート ノードは最初に選択される必要があり、他に候補がないため、ルート ノードはノードにはスケジューリング エンティティは必要ありません)。ルート ノード task_group に対応する実行キューは、rq 構造にパッケージ化されます。これには、特定の実行キューに加えて、いくつかのグローバル統計情報およびその他のフィールドも含まれます。
スケジューリングが発生すると、スケジューラはルート task_group の実行キューからスケジューリング エンティティを選択します。このスケジューリング エンティティが task_group を表す場合、スケジューラは、このグループに対応する実行キューからスケジューリング エンティティを選択し続ける必要があります。この再帰は、プロセスが選択されるまで続きます。ルートタスクグループの実行キューが空でない限り、再帰的にプロセスは必ず見つかります。 task_group に対応する実行キューが空の場合、対応するスケジューリング エンティティはその親ノードに対応する実行キューに追加されないためです。
最後に、task_group の場合、そのスケジューリング エンティティと実行キューは CPU ごとに共有され、スケジューリング エンティティ (task_group に対応) は同じ CPU に対応する実行キューにのみ追加されます。タスクの場合、スケジューリング エンティティのコピーは 1 つだけあります (CPU ごとに分割されていません)。スケジューラの負荷分散機能により、スケジューリング エンティティ (タスクに対応) が異なる CPU に対応する実行キューから移動される場合があります。
グループ スケジュール ポリシー
グループ スケジューリングの主要なデータ構造は明らかにされましたが、ここにはまだ非常に重要な問題が残っています。タスクには対応する優先度 (静的優先度または動的優先度) があり、スケジューラは優先度に基づいて実行キュー内のプロセスを選択することがわかっています。したがって、task_group と task は両方ともスケジュール エンティティに抽象化され、同じスケジュールを受け入れるため、task_group の優先順位はどのように定義すべきでしょうか?この質問には、特にスケジューリング カテゴリ (スケジューリング カテゴリが異なれば優先順位の定義も異なります)、具体的には rt (リアルタイム スケジューリング) と cfs (完全に公平なスケジューリング) によって答える必要があります。
リアルタイム プロセスのグループ スケジューリング
記事「Linux プロセス スケジューリングの簡単な分析」からわかるように、リアルタイム プロセスは、CPU にリアルタイム要件があるプロセスです。その優先順位は特定のタスクに関連しており、次によって完全に定義されます。ユーザー。スケジューラは常に、実行する最も優先度の高いリアルタイム プロセスを選択します。
グループのスケジューリングに関しては、グループの優先度は「グループ内で最も優先度の高いプロセスの優先度」として定義されます。たとえば、グループ内に優先度 10、20、および 30 のプロセスが 3 つある場合、グループの優先度は 10 になります (値が小さいほど優先度は高くなります)。
グループの優先順位はこのように定義され、興味深い現象が生じます。タスクがエンキューまたはデキューされるときは、すべての祖先ノードが最初にデキューされてから、下から上に再エンキューされる必要があります。グループ ノードの優先順位はその子ノードに依存するため、タスクのエンキューとデキューはその祖先ノードのそれぞれに影響します。
したがって、スケジューラがルート ノードの task_group からスケジューリング エンティティを選択すると、正しいパスに沿って TASK_RUNNING 状態にあるすべてのリアルタイム プロセスの中で最も高い優先度を常に見つけることができます。この実装は自然なことのように思えますが、よく考えてみると、このようにリアルタイム プロセスをグループ化することにどのような意味があるのでしょうか。グループ化するかどうかに関係なく、スケジューラが行うべきことは、「TASK_RUNNING 状態にあるすべてのリアルタイム プロセスの中で最も優先度の高いものを選択する」ことです。ここに何かが足りないようです...
次に、Linux システムに 2 つの proc ファイル、/proc/sys/kernel/sched_rt_period_us および /proc/sys/kernel/sched_rt_runtime_us を導入する必要があります。この 2 つのファイルでは、sched_rt_period_us を期間とする期間内では、すべてのリアルタイム プロセスの実行時間の合計が sched_rt_runtime_us を超えないよう規定しています。これら 2 つのファイルのデフォルト値は 1 秒と 0.95 秒で、1 秒ごとが 1 サイクルであることを意味します。このサイクルでは、すべてのリアルタイム プロセスの合計実行時間は 0.95 秒を超えず、残りは少なくとも 0.05 秒です。秒は通常のプロセスのために予約されます。言い換えれば、リアルタイム プロセスが占有する CPU の割合は 95% に過ぎません。この 2 つのファイルが登場する前は、リアルタイム プロセスの実行時間に制限はなく、常に TASK_RUNNING 状態のリアルタイム プロセスがあった場合、通常のプロセスは実行できませんでした。 sched_rt_runtime_us は sched_rt_period_us と同等です。
sched_rt_runtime_us と sched_rt_period_us という 2 つの変数があるのはなぜですか? CPU使用率を表す変数を直接使うことはできないのでしょうか?これは、音声プログラムが 20 ミリ秒ごとに音声パケットを送信したり、ビデオ プログラムが 40 ミリ秒ごとにフレームをリフレッシュしたりするなど、多くのリアルタイム プロセスが実際に定期的に何かを実行しているためだと思います。期間は重要であり、マクロ CPU 占有率を使用するだけでは、リアルタイム プロセスのニーズを正確に記述することはできません。
リアルタイム プロセスのグループ化により、sched_rt_runtime_us および sched_rt_period_us の概念が拡張されます。各 task_group には独自の sched_rt_runtime_us および sched_rt_period_us があり、独自のグループ内のプロセスは、最大でも sched_rt_period_us の期間内で sched_rt_runtime_us のみを実行できるようになります。 CPU 占有率は sched_rt_runtime_us/sched_rt_period_us です。
ルート ノードの task_group の場合、その sched_rt_runtime_us および sched_rt_period_us は、上記の 2 つの proc ファイルの値と等しくなります。 task_group ノードの場合、TASK_RUNNING 状態に n 個のスケジューリング サブグループと m 個のプロセスがあり、その CPU 占有率が A、これらの n 個のサブグループの CPU 占有率が B であると仮定すると、B は A 以下でなければなりません。 、A-B の残りの CPU 時間は、TASK_RUNNING 状態の m 個のプロセスに割り当てられます。 (各スケジューリング グループのサイクル値が異なる可能性があるため、ここで説明するのは CPU 占有率です。)
sched_rt_runtime_us および sched_rt_period_us のロジックを実装するために、カーネルがプロセスの実行時間を更新するとき (定期的なクロック割り込みによってトリガーされる時間更新など)、対応するランタイムをカーネルのスケジューリング エンティティに追加します。現在のプロセスとそのすべての祖先ノード。スケジューリング エンティティが sched_rt_runtime_us で制限された時間に達すると、対応する実行キューから削除され、対応する rt_rq がスロットル状態に設定されます。この状態では、rt_rq に対応するスケジューリング エンティティは再び実行キューに入りません。各 rt_rq は、sched_rt_period_us のタイミング周期で周期タイマーを維持します。タイマーがトリガーされるたびに、対応するコールバック関数が rt_rq の実行時間から sched_rt_period_us 単位値を減算し (ただし、実行時間を 0 以上に保ちます)、rt_rq をスロットル状態から復元します。
別の質問がありますが、前述したように、デフォルトでは、システム内のリアルタイム プロセスの実行時間は 1 秒あたり 0.95 秒を超えません。リアルタイムプロセスによる実際のCPU要求が0.95秒未満(0秒以上0.95秒未満)の場合、残りの時間は通常のプロセスに割り当てられます。また、リアルタイム プロセスの CPU 要求が 0.95 秒を超える場合、リアルタイム プロセスは 0.95 秒しか実行できず、残りの 0.05 秒は他の通常のプロセスに割り当てられます。しかし、この 0.05 秒間、通常のプロセスが CPU を使用する必要がない場合 (TASK_RUNNING 状態を持たない通常のプロセス) はどうなるでしょうか?この場合、通常の処理はCPUの需要がないので、リアルタイム処理は0.95秒以上実行できるでしょうか?できません。残りの 0.05 秒では、カーネルはリアルタイム プロセスに CPU を使用させるのではなく、CPU をアイドル状態に保ちます。 sched_rt_runtime_us と sched_rt_period_us は非常に必須であることがわかります。
最後に、複数の CPU の問題がありますが、前述したように、各 task_group について、そのスケジューリング エンティティと実行キューが CPU ごとに維持されます。 sched_rt_runtime_us と sched_rt_period_us はスケジューリング エンティティに作用するため、システム内に N 個の CPU がある場合、リアルタイム プロセスが占有する実際の CPU の上限は N*sched_rt_runtime_us/sched_rt_period_us になります。つまり、デフォルトの制限は 1 秒であるにもかかわらず、リアルタイム プロセスは 0.95 秒しか実行できません。ただし、リアルタイム プロセスの場合、CPU に 2 つのコアがある場合でも、CPU の 100% を占有する要求 (無限ループの実行など) を満たすことができます。したがって、このリアルタイム プロセスによって占有される CPU の 100% は 2 つの部分で構成される必要があるのは当然です (各 CPU は 1 つの部分を占有しますが、95% を超えないようにします)。しかし実際には、CPU 間のプロセス移行によって引き起こされるコンテキストの切り替えやキャッシュの無効化などの一連の問題を回避するために、ある CPU 上のスケジューリング エンティティは、別の CPU 上の対応するスケジューリング エンティティから時間を借りることができます。その結果、巨視的には sched_rt_runtime_us の制限を満たすだけでなく、プロセスの移行も回避されます。
通常プロセスのグループスケジューリング
記事の冒頭で、2 人のユーザー A と B は、プロセス数が異なっていても均等に CPU 要求を共有できると述べましたが、上記のリアルタイム プロセスのグループ スケジューリング戦略はそうではないようです。実際、これはプロセスのグループ スケジューリングが行う一般的な処理です。
リアルタイム プロセスと比較すると、通常のプロセスのグループ スケジューリングはそれほど特殊ではありません。グループはプロセスとほぼ同じエンティティとして扱われ、グループ自体に静的な優先度があり、スケジューラによってその優先度が動的に調整されます。グループの場合、グループ内のプロセスの優先度はグループの優先度に影響しません。これらのプロセスの優先度は、スケジューラによってグループが選択された場合にのみ考慮されます。
グループの優先順位を設定するために、各 task_group には share パラメーターがあります (前述の 2 つのパラメーター sched_rt_runtime_us および sched_rt_period_us と並行して)。共有は優先順位ではなく、スケジューリング エンティティの重みです (これが CFS スケジューラーの役割です)。この重みと優先順位の間には 1 対 1 の対応関係があります。通常のプロセスの優先度も、対応するスケジューリングエンティティの重みに変換されるため、シェアは優先度を表すと言えます。
シェアのデフォルト値は、通常のプロセスのデフォルト優先度に対応する重みと同じです。したがって、デフォルトでは、グループとプロセスは CPU を均等に共有します。
#########例######### (環境: ubuntu 10.04、カーネル 2.6.32、Intel Core2 デュアルコア)
CPU リソースを分割するだけの cgroup をマウントし、2 つのサブグループ grp_a と grp_b を作成します。
リーリー
3 つのシェルをそれぞれ開き、最初のシェルに grp_a を結合し、最後の 2 つに grp_b を結合します。
kouu@kouu-one:~/test/rtproc$ cat ttt.sh
echo $1 > /dev/cgroup/cpu/$2/tasks
ログイン後にコピー
(为什么要用ttt.sh来写cgroup下的tasks文件呢?因为写这个文件需要root权限,当前shell没有root权限,而sudo只能赋予被它执行的程序的root权限。其实sudo sh,然后再在新开的shell里面执行echo操作也是可以的。)
kouu@kouu-one:~/test1$ echo $$
6740
kouu@kouu-one:~/test1$ sudo sh ttt.sh $$ grp_a
kouu@kouu-one:~/test2$ echo $$
9410
kouu@kouu-one:~/test2$ sudo sh ttt.sh $$ grp_b
kouu@kouu-one:~/test3$ echo $$
9425
kouu@kouu-one:~/test3$ sudo sh ttt.sh $$ grp_b
ログイン後にコピー
kouu@kouu-one:~/test/rtproc$ cat ttt.sh echo $1 > /dev/cgroup/cpu/$2/tasks
(为什么要用ttt.sh来写cgroup下的tasks文件呢?因为写这个文件需要root权限,当前shell没有root权限,而sudo只能赋予被它执行的程序的root权限。其实sudo sh,然后再在新开的shell里面执行echo操作也是可以的。) kouu@kouu-one:~/test1$ echo $$ 6740 kouu@kouu-one:~/test1$ sudo sh ttt.sh $$ grp_a kouu@kouu-one:~/test2$ echo $$ 9410 kouu@kouu-one:~/test2$ sudo sh ttt.sh $$ grp_b kouu@kouu-one:~/test3$ echo $$ 9425 kouu@kouu-one:~/test3$ sudo sh ttt.sh $$ grp_b
回到cgroup目录下,确认这几个shell都被加进去了:
kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/tasks 6740 kouu@kouu-one:/dev/cgroup/cpu$ cat grp_b/tasks 9410 9425
现在准备在这三个shell下同时执行一个死循环的程序(a.out),为了避免多CPU带来的影响,将进程绑定到第二个核上:
#define _GNU_SOURCE
\#include
int main()
{
cpu_set_t set;
CPU_ZERO(&set);
CPU_SET(1, &set);
sched_setaffinity(0, sizeof(cpu_set_t), &set);
while(1);
return 0;
}
编译生成a.out,然后在前面的三个shell中分别运行。三个shell分别会fork出一个子进程来执行a.out,这些子进程都会继承其父进程的cgroup分组信息。然后top一下,可以观察到属于grp_a的a.out占了50%的CPU,而属于grp_b的两个a.out各占25%的CPU(加起来也是50%):
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 19854 kouu 20 0 1616 328 272 R 50 0.0 0:11.69 ./a.out 19857 kouu 20 0 1616 332 272 R 25 0.0 0:05.73 ./a.out 19860 kouu 20 0 1616 332 272 R 25 0.0 0:04.68 ./a.out ......
接下来再试试实时进程,把a.out程序改造如下:
#define _GNU_SOURCE
\#include
int main()
{
int prio = 50;
sched_setscheduler(0, SCHED_FIFO, (struct sched_param*)&prio);
while(1);
return 0;
}
然后设置grp_a的rt_runtime值:
kouu@kouu-one:/dev/cgroup/cpu$ sudo sh \# echo 300000 > grp_a/cpu.rt_runtime_us \# exit kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/cpu.rt_* 1000000 300000
现在的配置是每秒为一个周期,属于grp_a的实时进程每秒种只能执行300毫秒。运行a.out(设置实时进程需要root权限),然后top看看:
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... Cpu(s): 31.4%us, 0.7%sy, 0.0%ni, 68.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28324 root -51 0 1620 332 272 R 60 0.0 0:06.49 ./a.out ......
可以看到,CPU虽然闲着,但是却不分给a.out程序使用。由于双核的原因,a.out实际的CPU占用是60%而不是30%。
其他
前段时间,有一篇“200+行Kernel补丁显著改善Linux桌面性能”的新闻比较火。这个内核补丁能让高负载条件下的桌面程序响应延迟得到大幅度降低。其实现原理是,自动创建基于TTY的task_group,所有进程都会被放置在它所关联的TTY组中。通过这样的自动分组,就将桌面程序(Xwindow会占用一个TTY)和其他终端或伪终端(各自占用一个TTY)划分开了。终端上运行的高负载程序(比如make -j64)对桌面程序的影响将大大减少。(根据前面描述的普通进程的组调度的实现可以知道,如果一个任务给系统带来了很高的负载,只会影响到与它同组的进程。这个任务包含一个或是一万个TASK_RUNNING状态的进程,对于其他组的进程来说是没有影响的。)
本文浅析了linux组调度的方法,包括组调度的原理、实现、配置和优缺点等方面。通过了解和掌握这些知识,我们可以深入理解Linux进程调度的高级知识,从而更好地使用和优化Linux系统。
以上がLinux グループのスケジューリングの簡単な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7501
7501
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54

 Linuxは実際に何に適していますか?
Apr 12, 2025 am 12:20 AM
Linuxは実際に何に適していますか?
Apr 12, 2025 am 12:20 AM
Linuxは、サーバー、開発環境、埋め込みシステムに適しています。 1.サーバーオペレーティングシステムとして、Linuxは安定して効率的であり、多くの場合、高電流アプリケーションの展開に使用されます。 2。開発環境として、Linuxは効率的なコマンドラインツールとパッケージ管理システムを提供して、開発効率を向上させます。 3.埋め込まれたシステムでは、Linuxは軽量でカスタマイズ可能で、リソースが限られている環境に適しています。
 LinuxでDockerを使用:包括的なガイド
Apr 12, 2025 am 12:07 AM
LinuxでDockerを使用:包括的なガイド
Apr 12, 2025 am 12:07 AM
LinuxでDockerを使用すると、開発と展開の効率が向上する可能性があります。 1。Dockerのインストール:スクリプトを使用して、ubuntuにDockerをインストールします。 2.インストールの確認:sudodockerrunhello-worldを実行します。 3。基本的な使用法:NginxコンテナDockerrun-Namemy-Nginx-P8080を作成します:80-Dnginx。 4。高度な使用法:カスタム画像を作成し、DockerFileを使用してビルドして実行します。 5。最適化とベストプラクティス:マルチステージビルドとドッケルコンポスを使用して、DockerFilesを作成するためのベストプラクティスに従ってください。
 Apacheを始める方法
Apr 13, 2025 pm 01:06 PM
Apacheを始める方法
Apr 13, 2025 pm 01:06 PM
Apacheを開始する手順は次のとおりです。Apache(コマンド:sudo apt-get install apache2または公式Webサイトからダウンロード)をインストールします(linux:linux:sudo systemctl start apache2; windows:apache2.4 "serviceを右クリックして「開始」を右クリック) (オプション、Linux:Sudo SystemCtl
 Apache80ポートが占有されている場合はどうすればよいですか
Apr 13, 2025 pm 01:24 PM
Apache80ポートが占有されている場合はどうすればよいですか
Apr 13, 2025 pm 01:24 PM
Apache 80ポートが占有されている場合、ソリューションは次のとおりです。ポートを占有するプロセスを見つけて閉じます。ファイアウォールの設定を確認して、Apacheがブロックされていないことを確認してください。上記の方法が機能しない場合は、Apacheを再構成して別のポートを使用してください。 Apacheサービスを再起動します。
 DebianのNginx SSLパフォーマンスを監視する方法
Apr 12, 2025 pm 10:18 PM
DebianのNginx SSLパフォーマンスを監視する方法
Apr 12, 2025 pm 10:18 PM
この記事では、Debianシステム上のNginxサーバーのSSLパフォーマンスを効果的に監視する方法について説明します。 Nginxexporterを使用して、NginxステータスデータをPrometheusにエクスポートし、Grafanaを介して視覚的に表示します。ステップ1:NGINXの構成最初に、NGINX構成ファイルのSTUB_STATUSモジュールを有効にして、NGINXのステータス情報を取得する必要があります。 NGINX構成ファイルに次のスニペットを追加します(通常は/etc/nginx/nginx.confにあるか、そのインクルードファイルにあります):location/nginx_status {stub_status
 Oracleの監視を開始する方法
Apr 12, 2025 am 06:00 AM
Oracleの監視を開始する方法
Apr 12, 2025 am 06:00 AM
Oracleリスナーを開始する手順は次のとおりです。Windowsのリスナーステータス(LSNRCTLステータスコマンドを使用)を確認し、LinuxとUNIXのOracle Services Managerで「TNSリスナー」サービスを開始し、LSNRCTL Startコマンドを使用してリスナーを起動してLSNRCTLステータスコマンドを実行してリスナーを確認します。
 Debianシステムでリサイクルビンをセットアップする方法
Apr 12, 2025 pm 10:51 PM
Debianシステムでリサイクルビンをセットアップする方法
Apr 12, 2025 pm 10:51 PM
この記事では、デビアンシステムでリサイクルビンを構成する2つの方法を紹介します:グラフィカルインターフェイスとコマンドライン。方法1:Nautilusグラフィカルインターフェイスを使用して、ファイルマネージャーを開きます。デスクトップまたはアプリケーションメニューでNautilusファイルマネージャー(通常は「ファイル」と呼ばれる)を見つけて起動します。リサイクルビンを見つけてください:左ナビゲーションバーのリサイクルビンフォルダーを探してください。見つからない場合は、「他の場所」または「コンピューター」をクリックして検索してみてください。リサイクルビンプロパティの構成:「リサイクルビン」を右クリックし、「プロパティ」を選択します。プロパティウィンドウで、次の設定を調整できます。最大サイズ:リサイクルビンで使用可能なディスクスペースを制限します。保持時間:リサイクルビンでファイルが自動的に削除される前に保存を設定します
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
