

nodejsのcrawler_node.jsでキャプチャしたデータが文字化けする問題のまとめ

1. 非 UTF-8 ページの処理.
1. 背景
Windows-1251 エンコード
たとえば、ロシアの Web サイト: https://vk.com/cciinniikk
このエンコーディングを見つけるのは恥ずかしい

ここで主に説明するのは、Windows-1251 (cp1251) エンコーディングと utf-8 エンコーディングの問題です。gbk などの他のエンコーディングは考慮されません~
2. 解決策
1.
js ネイティブ エンコーディング変換を使用する
しかし、まだ方法が見つかりません..
utf-8 から window-1251 であれば問題ありませんhttp://stackoverflow.com/questions/2696481/encoding-conversation-utf-8-to-1251-in-javascript
var DMap = {0: 0, 1: 1, 2: 2, 3: 3, 4: 4, 5: 5, 6: 6, 7: 7, 8: 8, 9: 9, 10: 10, 11: 11, 12: 12, 13: 13, 14: 14, 15: 15, 16: 16, 17: 17, 18: 18, 19: 19, 20: 20, 21: 21, 22: 22, 23: 23, 24: 24, 25: 25, 26: 26, 27: 27, 28: 28, 29: 29, 30: 30, 31: 31, 32: 32, 33: 33, 34: 34, 35: 35, 36: 36, 37: 37, 38: 38, 39: 39, 40: 40, 41: 41, 42: 42, 43: 43, 44: 44, 45: 45, 46: 46, 47: 47, 48: 48, 49: 49, 50: 50, 51: 51, 52: 52, 53: 53, 54: 54, 55: 55, 56: 56, 57: 57, 58: 58, 59: 59, 60: 60, 61: 61, 62: 62, 63: 63, 64: 64, 65: 65, 66: 66, 67: 67, 68: 68, 69: 69, 70: 70, 71: 71, 72: 72, 73: 73, 74: 74, 75: 75, 76: 76, 77: 77, 78: 78, 79: 79, 80: 80, 81: 81, 82: 82, 83: 83, 84: 84, 85: 85, 86: 86, 87: 87, 88: 88, 89: 89, 90: 90, 91: 91, 92: 92, 93: 93, 94: 94, 95: 95, 96: 96, 97: 97, 98: 98, 99: 99, 100: 100, 101: 101, 102: 102, 103: 103, 104: 104, 105: 105, 106: 106, 107: 107, 108: 108, 109: 109, 110: 110, 111: 111, 112: 112, 113: 113, 114: 114, 115: 115, 116: 116, 117: 117, 118: 118, 119: 119, 120: 120, 121: 121, 122: 122, 123: 123, 124: 124, 125: 125, 126: 126, 127: 127, 1027: 129, 8225: 135, 1046: 198, 8222: 132, 1047: 199, 1168: 165, 1048: 200, 1113: 154, 1049: 201, 1045: 197, 1050: 202, 1028: 170, 160: 160, 1040: 192, 1051: 203, 164: 164, 166: 166, 167: 167, 169: 169, 171: 171, 172: 172, 173: 173, 174: 174, 1053: 205, 176: 176, 177: 177, 1114: 156, 181: 181, 182: 182, 183: 183, 8221: 148, 187: 187, 1029: 189, 1056: 208, 1057: 209, 1058: 210, 8364: 136, 1112: 188, 1115: 158, 1059: 211, 1060: 212, 1030: 178, 1061: 213, 1062: 214, 1063: 215, 1116: 157, 1064: 216, 1065: 217, 1031: 175, 1066: 218, 1067: 219, 1068: 220, 1069: 221, 1070: 222, 1032: 163, 8226: 149, 1071: 223, 1072: 224, 8482: 153, 1073: 225, 8240: 137, 1118: 162, 1074: 226, 1110: 179, 8230: 133, 1075: 227, 1033: 138, 1076: 228, 1077: 229, 8211: 150, 1078: 230, 1119: 159, 1079: 231, 1042: 194, 1080: 232, 1034: 140, 1025: 168, 1081: 233, 1082: 234, 8212: 151, 1083: 235, 1169: 180, 1084: 236, 1052: 204, 1085: 237, 1035: 142, 1086: 238, 1087: 239, 1088: 240, 1089: 241, 1090: 242, 1036: 141, 1041: 193, 1091: 243, 1092: 244, 8224: 134, 1093: 245, 8470: 185, 1094: 246, 1054: 206, 1095: 247, 1096: 248, 8249: 139, 1097: 249, 1098: 250, 1044: 196, 1099: 251, 1111: 191, 1055: 207, 1100: 252, 1038: 161, 8220: 147, 1101: 253, 8250: 155, 1102: 254, 8216: 145, 1103: 255, 1043: 195, 1105: 184, 1039: 143, 1026: 128, 1106: 144, 8218: 130, 1107: 131, 8217: 146, 1108: 186, 1109: 190}
function UnicodeToWin1251(s) {
var L = []
for (var i=0; i<s.length; i++) {
var ord = s.charCodeAt(i)
if (!(ord in DMap))
throw "Character "+s.charAt(i)+" isn't supported by win1251!"
L.push(String.fromCharCode(DMap[ord]))
}
return L.join('')
}これは良いアイデアです。Dmap が実際に保存するのは、window-1251 エンコーディングと Unicode の間のマッピング関係です。
だから私は逆のことを計画しただけです
しかし、逆に、charCodeAt メソッドは Unicode に対してのみ有効であることがわかりました。他のエンコーディングのコード セグメントを掘り出すにはどうすればよいでしょうか。 私はnodejsを使用しているので、対応するモジュールの使用を検討します
2.
nodejs モジュール iconv-lite のインストールと使用方法については、https://www.npmjs.com/package/iconv-lite
を参照してください。使用方法に応じて、同様の方法で使用する必要があります
var iconv = require('iconv-lite');
var Buffer = require('buffer').Buffer;
// Convert from an encoded windows-1251 to utf-8
//这个str1应该是http.get 或request等请求返回的数据
//请求的时候要带参数,不然就会出错
//除了基本的参数之外 要注意记得使用 encoding: 'binary'这个参数
//比如
str1 = 'ценности ни в ';
//把获取到的数据 转换成Buffer,记得格式使用 binary
//binary在各编码直接穿梭无阻~
var buf = new Buffer(str1,'binary');
var str2 = iconv.decode(buf, 'win1251');
//str2就被转换出来了,默认是转成 Unicode格式,估计这也是iconv-lite的初衷吧
console.log(str2);
3.
nodejs モジュール iconv のインストールと使用の手順は、https://github.com/bnoordhuis/node-iconv
で参照できます。(実際、本質はnode-gypをインストールすることです。これまで公式の手順をよく読んでいませんでした)
一般に、単純に使用しただけでは、コードは依然として文字化けします。形式は пїЅпїЅпїЅпїЅ пїЅпїЅпїЅпїЅпїЅпїЅ пїЅпїЅпїЅпїЅпїЅпїЅ пїЅпї です。 Ѕ
http://stackoverflow.com/questions/8693400/nodejs-convertinf-from-windows-1251-to-utf-8
解決策は、読み取ったデータをバイナリ エンコーディング: binary (デフォルトのエンコーディングは utf-8) に変換することです
request({
uri: website_url,
method: 'GET',
encoding: 'binary'
}, function (error, response, body) {
body = new Buffer(body, 'binary');
conv = new iconv.Iconv('WINDOWS-1251', 'utf8');
body = conv.convert(body).toString();
}
});--> さらに、iconv の使用にはいくつかの環境依存関係が必要です。https://github.com/TooTallNate/node-gyp

それで:
まず、python の対応するバージョン (2.7 など)
のサポートが必要です。2 番目に、コンパイル ツールのサポートが必要です (ほとんどのエラーは Windows で発生します)
これと同様のエラー
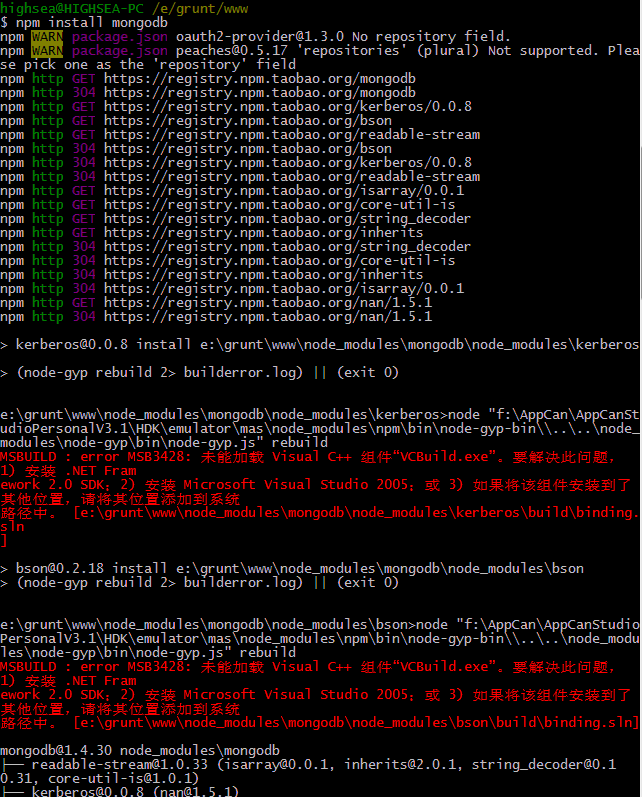
ノード、特定のバージョン以降がない場合、vs2005 コンパイル ツールがデフォルトで使用されます (したがって、エラー メッセージの解決策は通常、vs2005 とフレームワーク sdk2.0 に従うことになります)
問題の解決策:
1. Visual Studio 2010 をインストールします
2. vs コンパイルツールのバージョンを指定します (vs2012 の場合は 2012)
(自動的に指定される場合もあるので、このコマンドは必ずしも必要ではありません npm config set msvs_version 2010 --global)

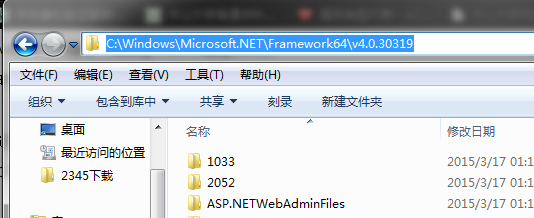
3. それでもフレームワーク SDK が見つからないというメッセージが表示される場合は、そのインストール パスをシステム環境変数のパスに追加できます
(2010 は sdk4.0 バージョンに対応し、2008 sdj3.5 2012 sdk4.5 と同様?)
もう 1 つ覚えておくべきことは、環境変数は最初の変数のみを読み取るということです。
たとえば、以前に SDK2.0 のパスをシステム環境変数に設定したことがある場合、ここで SDK4.0 のパスを追加して設定すると、最初のパスのみが機能します
それで:
または前のものを削除します
または追加したいパスをその前に置きます
2. Gzip ページの処理
ブラウザがページにアクセスするのは正常ですが、返されたときにシミュレートされたリクエストが文字化けしている場合があります。Content-Encoding: gzip がある場合は、ブラウザからリクエストされたレスポンス情報を確認できます。ページが gzip で圧縮されていることが原因である可能性が高いため、
をリクエストするときに次のパラメータを追加する必要があります。gzip:true
以上がこの記事の全内容です。皆さんに気に入っていただければ幸いです。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99

 Linuxで中国語の文字化けを解決する方法
Feb 21, 2024 am 10:48 AM
Linuxで中国語の文字化けを解決する方法
Feb 21, 2024 am 10:48 AM
Linux の中国語の文字化け問題は、中国語の文字セットとエンコーディングを使用する場合によく見られる問題です。文字化けは、ファイルのエンコード設定が正しくない、システム ロケールがインストールまたは設定されていない、端末の表示設定エラーなどが原因で発生する可能性があります。この記事では、いくつかの一般的な回避策を紹介し、具体的なコード例を示します。 1. ファイルのエンコード設定を確認します。ファイルのエンコードを表示するには file コマンドを使用します。ターミナルで file コマンドを使用して、ファイルのエンコードを表示します: file-ifilename。出力に「charset」がある場合
 Tomcat 起動時に文字化けしたコードを解決する方法
Dec 26, 2023 pm 05:21 PM
Tomcat 起動時に文字化けしたコードを解決する方法
Dec 26, 2023 pm 05:21 PM
Tomcat 起動時の文字化けの解決策: 1. Tomcat の conf 設定ファイルを変更する; 2. システム言語を変更する; 3. コマンド ライン ウィンドウのエンコードを変更する; 4. Tomcat サーバーの設定を確認する; 5. プロジェクトのエンコードを確認する; 6. ログを確認するファイル; 7 、他の解決策を試してください。詳細な導入: 1. Tomcat の conf 構成ファイルを変更し、Tomcat の conf ディレクトリを開き、「logging.properties」ファイルなどを見つけます。
 Windows10で中国語が文字化けする問題を解決する方法
Jan 16, 2024 pm 02:21 PM
Windows10で中国語が文字化けする問題を解決する方法
Jan 16, 2024 pm 02:21 PM
Windows 10では文字化けが多発しております。多くの場合、この背後にある理由は、オペレーティング システムが一部の文字セットのデフォルト サポートを提供していないか、設定された文字セット オプションにエラーがあることです。適切な薬を処方するために、実際の操作手順を以下で詳しく分析します。 Windows 10 の文字化けコードを解決する方法 1. 設定を開いて「時刻と言語」を見つけます 2. 次に「言語」を見つけます 3. 「言語設定の管理」を見つけます 4. ここで「システム地域設定の変更」をクリックします 5. 図のようにボックスをチェックしますそして、「必ず確認してください」をクリックします。
 dllファイルを開くときに文字化けする問題を解決する編集方法
Jan 06, 2024 pm 07:53 PM
dllファイルを開くときに文字化けする問題を解決する編集方法
Jan 06, 2024 pm 07:53 PM
多くのユーザーがコンピュータを使用していると、拡張子が dll のファイルがたくさんあることに気づきますが、そのファイルの開き方が分からないユーザーも多いので、知りたい方は以下を参照してください。 dll ファイルを開いて編集するには: 1. 「exescope」というソフトウェアをダウンロードし、インストールします。 2. 次に、dll ファイルを右クリックし、[exescope でリソースを編集] を選択します。 3. ポップアップ エラー プロンプト ボックスで [OK] をクリックします。 4. 次に、右側のパネルで、各グループの前にある「+」記号をクリックして、グループに含まれるコンテンツを表示します。 5. 表示したい dll ファイルをクリックし、「ファイル」をクリックして「エクスポート」を選択します。 6. そうすれば、次のことができます
 filezillaの文字化けを解決する方法
Nov 20, 2023 am 10:16 AM
filezillaの文字化けを解決する方法
Nov 20, 2023 am 10:16 AM
filezilla の文字化けの解決策は次のとおりです: 1. エンコード設定を確認する; 2. ファイル自体を確認する; 3. サーバー構成を確認する; 4. 他の転送ツールを試す; 5. ソフトウェアのバージョンを更新する; 6. ネットワークの問題を確認する; 7 . 技術サポートを求めてください。 FileZillaの文字化け問題を解決するには、多方面から始めて徐々に原因を究明し、それに応じた対策を講じて修復する必要があります。
 win11のメモ帳の文字化け問題を解決する
Jan 05, 2024 pm 03:11 PM
win11のメモ帳の文字化け問題を解決する
Jan 05, 2024 pm 03:11 PM
友人の中には、メモ帳を開こうと思っていますが、Win11 のメモ帳が文字化けしていることに気づき、どうすればよいかわかりませんが、実際には、通常は地域と言語を変更するだけで十分です。 Win11 メモ帳が文字化けする: 最初のステップ、検索機能を使用し、「コントロール パネル」を検索して開きます。 2 番目のステップ、時計と地域の下の [日付、時刻、または数値形式の変更] をクリックします。 3 番目のステップ、カードの上にある [管理] オプションをクリックします。 4 番目のステップでは、下の [システムの地域設定の変更] をクリックし、5 番目のステップでは、現在のシステムの地域設定を [中国語 (簡体字、中国)] に変更し、[OK] をクリックして保存します。
 Python クローラーを学ぶのにどれくらい時間がかかりますか
Oct 25, 2023 am 09:44 AM
Python クローラーを学ぶのにどれくらい時間がかかりますか
Oct 25, 2023 am 09:44 AM
Python クローラーの学習にかかる時間は人によって異なり、個人の学習能力、学習方法、学習時間、経験などの要因によって異なります。 Python クローラーを学習するには、テクノロジー自体を学習するだけでなく、優れた情報収集スキル、問題解決スキル、チームワーク スキルも必要です。継続的な学習と実践を通じて、徐々に優れた Python クローラー開発者に成長していきます。
 Oracleに中国語データをインポートする際の文字化けの問題を解決するにはどうすればよいですか?
Mar 10, 2024 am 09:54 AM
Oracleに中国語データをインポートする際の文字化けの問題を解決するにはどうすればよいですか?
Mar 10, 2024 am 09:54 AM
タイトル: 中国語データを Oracle にインポートする際の文字化けの問題を解決する方法とコード例。中国語データを Oracle データベースにインポートすると、文字化けが頻繁に発生します。これは、データベースの文字セット設定が間違っているか、インポート中のエンコード変換の問題が原因である可能性があります。プロセス。 。この問題を解決するには、インポートされた中国語データが正しく表示されるようにするためのいくつかの方法を講じることができます。以下に、いくつかの解決策と具体的なコード例を示します。 1. データベースの文字セット設定を確認します。 Oracle データベースでは、文字セット設定は次のとおりです。
