

Linux パイプは実際どのくらい高速になるのでしょうか?

この記事の著者は、サンプル プログラムを使用して、Linux パイプでのデータの読み取りおよび書き込みのプロセスを最適化することでパフォーマンスを向上させる方法を示しています。最終的に、スループットは初期の 3.5 GiB/s から 65 GiB/s に増加しました。これはほんの小さな例ですが、ゼロコピー操作、リングバッファ、ページングと仮想メモリ、同期オーバーヘッドなど、多くの知識ポイントが含まれます。この記事では、Linux カーネルにおけるスプライシング、ページング、仮想メモリ アドレス マッピングなどの概念をソース コード レベルから分析します。この記事では、パイプラインの読み取りおよび書き込みパフォーマンスの最適化に焦点を当て、これらの概念を浅いものから深いものまでレイヤーごとに紹介しており、高パフォーマンスのアプリケーションや Linux カーネルの開発者にとって有益であると信じています。
この記事では、テスト プログラムの繰り返し最適化を通じて、Linux での Unix パイプラインの実装について学びます。スループットが約 3.5 GiB/s の単純なプログラムから始めて、徐々にパフォーマンスを 20 倍向上させます。パフォーマンスの向上は、Linux のパフォーマンス ツール プロファイラーを使用して確認されます。コードは GitHub (https://github.com/bitonic/pipes-speed-test) で入手できます。
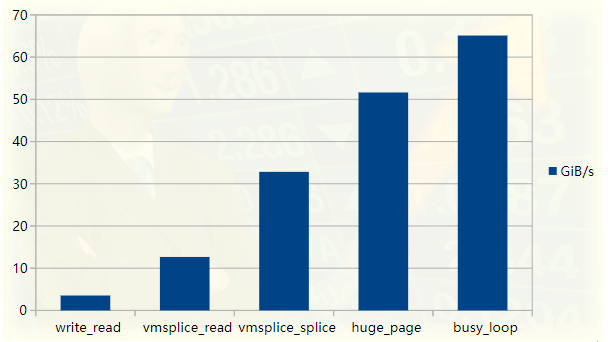
パイプライン テスト プログラムのパフォーマンス グラフ
この記事は、高度に最適化された FizzBuzz プログラムについて読んだことに触発されました。私のラップトップでは、プログラムは約 35GiB/s で出力をパイプにプッシュします。私たちの最初の目標はこの速度を達成することであり、最適化プロセスの各ステップについて説明します。また、少なくとも私のマシンでは、ボトルネックは実際には IO ではなく計算出力であるため、FizzBuzz では必要のないパフォーマンスの向上も追加されます。
次のように進めます:
- まず、パイプライン ベンチマークの低速バージョン;
- パイプラインが内部でどのように実装されているか、またパイプラインからの読み取りと書き込みが遅い理由を説明します;
- vmsplice および splice システム コールを使用して、一部の (すべてではない) 低速リンクをバイパスする方法を説明します。
- Linux ページングについて説明し、巨大ページを使用して高速バージョンを実装する;
- 最終的な最適化のためにポーリングの代わりにビジー ループを使用します;
- 要約
ステップ 4 は Linux カーネルの最も重要な部分であるため、この記事で説明されている他のトピックに精通している場合でも、興味深い内容になる可能性があります。この主題に詳しくない読者は、C 言語の基本的な知識しか持っていないことを前提としています。
1.最初の遅いバージョンに挑戦します
まず、StackOverflow の投稿ルールに従って、伝説的な FizzBuzz プログラムのパフォーマンスをテストしてみましょう:
リーリーpv は「パイプ ビューア」の略で、パイプを流れるデータのスループットを測定するためのシンプルなツールです。 36GiB/s で出力を生成する fizzbuzz を示します。
fizzbuzz は、メモリへの安価なアクセスと最小限の IO オーバーヘッドの間で適切なバランスを実現するために、L2 キャッシュと同じ大きさのブロックに出力を書き込みます。
私のマシンでは、L2 キャッシュは 256KiB です。この記事では引き続き 256KiB ブロックを出力しますが、「計算」は行いません。基本的に、適切なバッファ サイズでパイプに書き込むプログラムのスループットの上限を測定したいと考えています。
fizzbuzz は pv を使用して速度を測定します。セットアップは少し異なります。パイプラインの両端でプログラムを実行し、パイプラインからのデータのプッシュおよびプルに関連するコードを完全に制御できるようにします。
コードは私の Pipes-speed-test 担当者から入手できます。 write.cpp は書き込みを実装し、read.cpp は読み取りを実装します。 write は同じ 256KiB を繰り返し書き込み続け、read は 10GiB のデータを読み取った後に終了し、スループットを GiB/s で出力します。どちらの実行可能プログラムも、動作を変更するためのさまざまなコマンド ライン オプションを受け入れます。
パイプからの読み取りと書き込みの最初のテストでは、fizzbuzz と同じバッファ サイズを使用して書き込みおよび読み取りシステム コールを使用します。以下に書き込み側のコードを示します:
リーリー簡潔にするために、このコードと後続のコード スニペットではすべてのエラー チェックが省略されています。 memset は出力を確実に印刷できるようにすることに加えて、後で説明する別の役割も果たします。
すべての作業は書き込み呼び出しを通じて行われ、残りの作業はバッファ全体が書き込まれることを確認することです。読み取り側は非常に似ていますが、データを buf に読み取り、十分なデータが読み取られたときに終了する点が異なります。
ビルド後、ライブラリ内のコードは次のように実行できます:
リーリー「X」で満たされた同じ 256KiB バッファに 40960 回書き込み、スループットを測定します。迷惑なことに、fizzbuzz よりも 10 倍遅いです。パイプにバイトを書き込むだけで、他の作業は行いません。書き込みと読み取りを使用しても、これよりもはるかに高速化できないことがわかりました。
2.問題の記述
プログラムの実行に費やされた時間を調べるには、perf を使用できます:
リーリー-g オプションは、コール グラフを記録するように perf に指示します。これにより、上から下までどこに時間がかかっているかを確認できるようになります。
パフォーマンス レポートを使用して、どこに時間が費やされているかを確認できます。以下は、書き込み時間がどこに費やされるかを詳しく示す、軽く編集されたスニペットです:
% perf report -g --symbol-filter=write - 48.05% 0.05% write libc-2.33.so [.] __GI___libc_write - 48.04% __GI___libc_write - 47.69% entry_SYSCALL_64_after_hwframe - do_syscall_64 - 47.54% ksys_write - 47.40% vfs_write - 47.23% new_sync_write - pipe_write + 24.08% copy_page_from_iter + 11.76% __alloc_pages + 4.32% schedule + 2.98% __wake_up_common_lock 0.95% _raw_spin_lock_irq 0.74% alloc_pages 0.66% prepare_to_wait_event
47% 的时间花在了 pipe_write 上,也就是我们在向管道写入时,write 所干的事情。这并不奇怪——我们花了大约一半的时间进行写入,另一半时间进行读取。
在 pipe_write中,3/4 的时间用于复制或分配页面(copy_page_from_iter和__alloc_page)。如果我们已经对内核和用户空间之间的通信是如何工作的有所了解,就会知道这有一定道理。不管怎样,要完全理解发生了什么,我们必须首先理解管道如何工作。
3. 管道是由什么构成?
在 include/linux/pipe_fs_i.h 中可以找到定义管道的数据结构,fs/pipe.c 中有对其进行的操作。
Linux 管道是一个环形缓冲区,保存对数据写入和读取的页面的引用:
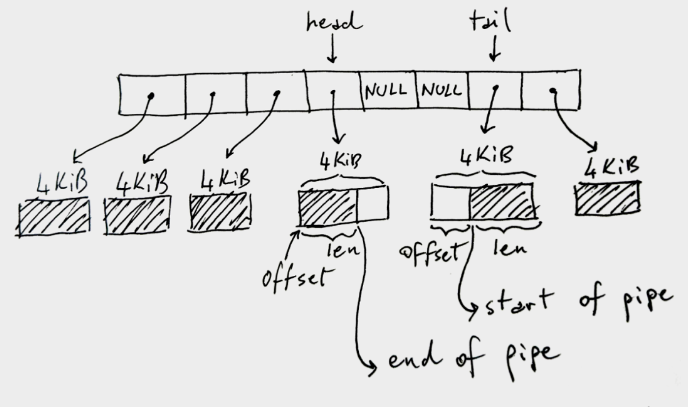
上图中的环形缓冲区有 8 个槽位,但可能或多或少,默认为 16 个。x86-64 架构中每个页面大小是 4KiB,但在其他架构中可能有所不同。这个管道总共可以容纳 32KiB 的数据。这是一个关键点:每个管道都有一个上限,即它在满之前可以容纳的数据总量。
图中的阴影部分表示当前管道数据,非阴影部分表示管道中的空余空间。
有点反直觉,head 存储管道的写入端。也就是说,写入程序将写入 head 指向的缓冲区,如果需要移动到下一个缓冲区,则相应地增加 head。在写缓冲区中,len 存储我们在其中写了多少。
相反,tail 存储管道的读取端:读取程序将从那里开始使用管道。offset 指示从何处开始读取。
注意,tail 可以出现在 head 之后,如图中所示,因为我们使用的是循环/环形缓冲区。还要注意,当我们没有完全填满管道时,一些槽位可能没有使用——中间的 NULL 单元。如果管道已满(页面中没有NULL和可用空间),write 将被阻塞。如果管道为空(全 NULL),则 read 将被阻塞。
下面是 pipe_fs_i.h 中 C 数据结构的节略版本:
struct pipe_inode_info {
unsigned int head;
unsigned int tail;
struct pipe_buffer *bufs;
};
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
};
这里我们省略了许多字段,也还没有解释 struct page 中存什么,但这是理解如何从管道进行读写的关键数据结构。
4. 读写管道
现在让我们回到 pipe_write 的定义,尝试理解前面显示的 perf 输出。pipe_write 工作原理简要说明如下:
1.如果管道已满,等待空间并重新启动;
2.如果 head 当前指向的缓冲区有空间,首先填充该空间;
3.当有空闲槽位,还有剩余的字节要写时,分配新的页面并填充它们,更新head。
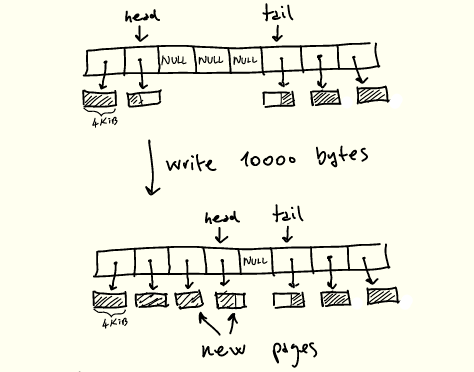
写入管道时的操作
上述操作被一个锁保护,pipe_write 根据需要获取和释放该锁。
pipe_read 是 pipe_ write 的镜像,不同之处在于消费页面,完全读取页面后将其释放,并更新 tail。
因此,当前的处理过程形成了一个令人非常不快的状况:
- 每个页面复制两次,一次从用户内存复制到内核,另一次从内核复制到用户内存;
- 一次复制一个 4KiB 的页面,期间还与诸如读写之间的同步、页面分配与释放等其他操作交织在一起;
- 由于不断分配新页面,正在处理的内存可能不连续;
- 处理期间需要一直获取和释放管道锁。
在本机上,顺序 RAM 读取速度约为 16GiB/s:
% sysbench memory --memory-block-size=1G --memory-oper=read --threads=1 run ... 102400.00 MiB transferred (15921.22 MiB/sec)
考虑到上面列出的所有问题,与单线程顺序 RAM 速度相比,慢 4 倍便不足为怪。
调整缓冲区或管道大小以减少系统调用和同步开销,或者调整其他参数不会有多大帮助。幸运的是,有一种方法可以完全避免读写缓慢。
5. 用拼接进行改进
这种将缓冲区从用户内存复制到内核再复制回去,是需要进行快速 IO 的人经常遇到的棘手问题。一种常见的解决方案是将内核操作从处理过程中剔除,直接执行 IO 操作。例如,我们可以直接与网卡交互,并绕过内核以低延迟联网。
通常当我们写入套接字、文件或本例的管道时,首先写入内核中的某个缓冲区,然后让内核完成其工作。在管道的情况下,管道就是内核中的一系列缓冲区。如果我们关注性能,则所有这些复制都是不可取的。
幸好,当我们要在管道中移动数据时,Linux 包含系统调用以加快速度,而无需复制。具体而言:
- splice 将数据从管道移动到文件描述符,反之亦然;
- vmsplice 将数据从用户内存移动到管道中。
关键是,这两种操作都在不复制任何内容的情况下工作。
既然我们知道了管道的工作原理,就可以大概想象这两个操作是如何工作的:它们只是从某处“抓取”一个现有的缓冲区,然后将其放入管道环缓冲区,或者反过来,而不是在需要时分配新页面:
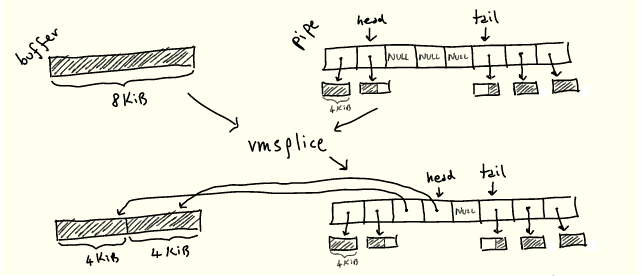
我们很快就会看到它是如何工作的。
6. Splicing 实现
我们用 vmsplice 替换 write。vmsplice 签名如下:
struct iovec {
void *iov_base; // Starting address
size_t iov_len; // Number of bytes
};
// Returns how much we've spliced into the pipe
ssize_t vmsplice(
int fd, const struct iovec *iov, size_t nr_segs, unsigned int flags
);
fd是目标管道,struct iovec *iov 是将要移动到管道的缓冲区数组。注意,vmsplice 返回“拼接”到管道中的数量,可能不是完整数量,就像 write 返回写入的数量一样。别忘了管道受其在环形缓冲区中的槽位数量的限制,而 vmsplice 不受此限制。
使用 vmsplice 时还需要小心一点。用户内存是在不复制的情况下移动到管道中的,因此在重用拼接缓冲区之前,必须确保读取端使用它。
为此,fizzbuzz 使用双缓冲方案,其工作原理如下:
- 将 256KiB 缓冲区一分为二;
- 将管道大小设置为 128KiB,相当于将管道的环形缓冲区设置为具有128KiB/4KiB=32 个槽位;
- 在写入前半个缓冲区或使用 vmsplice 将其移动到管道中之间进行选择,并对另一半缓冲区执行相同操作。
管道大小设置为 128KiB,并且等待 vmsplice 完全输出一个 128KiB 缓冲区,这就保证了当完成一次 vmsplic 迭代时,我们已知前一个缓冲区已被完全读取——否则无法将新的 128KiB 缓冲区完全 vmsplice 到 128KiB 管道中。
现在,我们实际上还没有向缓冲区写入任何内容,但我们将保留双缓冲方案,因为任何实际写入内容的程序都需要类似的方案。
我们的写循环现在看起来像这样:
int main() {
size_t buf_size = 1 'X', buf_size); // output Xs
char* bufs[2] = { buf, buf + buf_size/2 };
int buf_ix = 0;
// Flip between the two buffers, splicing until we're done.
while (true) {
struct iovec bufvec = {
.iov_base = bufs[buf_ix],
.iov_len = buf_size/2
};
buf_ix = (buf_ix + 1) % 2;
while (bufvec.iov_len > 0) {
ssize_t ret = vmsplice(STDOUT_FILENO, &bufvec, 1, 0);
bufvec.iov_base = (void*) (((char*) bufvec.iov_base) + ret);
bufvec.iov_len -= ret;
}
}
}
以下是使用 vmsplice 而不是 write 写入的结果:
% ./write --write_with_vmsplice | ./read 12.7GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
这使我们所需的复制量减少了一半,并且把吞吐量提高了三倍多,达到 12.7GiB/s。将读取端更改为使用 splice 后,消除了所有复制,又获得了 2.5 倍的加速:
% ./write --write_with_vmsplice | ./read --read_with_splice 32.8GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
7. 页面改进
接下来呢?让我们问 perf:
% perf record -g sh -c './write --write_with_vmsplice | ./read --read_with_splice' 33.4GiB/s, 256KiB buffer, 40960 iterations (10GiB piped) [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.305 MB perf.data (2413 samples) ] % perf report --symbol-filter=vmsplice - 49.59% 0.38% write libc-2.33.so [.] vmsplice - 49.46% vmsplice - 45.17% entry_SYSCALL_64_after_hwframe - do_syscall_64 - 44.30% __do_sys_vmsplice + 17.88% iov_iter_get_pages + 16.57% __mutex_lock.constprop.0 3.89% add_to_pipe 1.17% iov_iter_advance 0.82% mutex_unlock 0.75% pipe_lock 2.01% __entry_text_start 1.45% syscall_return_via_sysret
大部分时间消耗在锁定管道以进行写入(__mutex_lock.constprop.0)和将页面移动到管道中(iov_iter_get_pages)两个操作。关于锁定能改进的不多,但我们可以提高 iov_iter_get_pages 的性能。
顾名思义,iov_iter_get_pages 将我们提供给 vmsplice 的 struct iovecs 转换为 struct pages,以放入管道。为了理解这个函数的实际功能,以及如何加快它的速度,我们必须首先了解 CPU 和 Linux 如何组织页面。
8. 快速了解分页
如你所知,进程并不直接引用 RAM 中的位置:而是分配虚拟内存地址,这些地址被解析为物理地址。这种抽象被称为虚拟内存,我们在这里不介绍它的各种优势——但最明显的是,它大大简化了运行多个进程对同一物理内存的竞争。
无论何种情况下,每当我们执行一个程序并从内存加载/存储到内存时,CPU 都需要将虚拟地址转换为物理地址。存储从每个虚拟地址到每个对应物理地址的映射是不现实的。因此,内存被分成大小一致的块,叫做页面,虚拟页面被映射到物理页面:
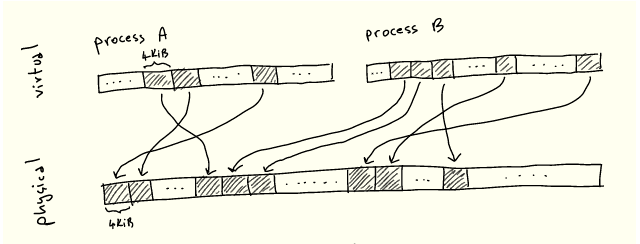
4KiB 并没有什么特别之处:每种架构都根据各种权衡选择一种大小——我们将很快将探讨其中的一些。
为了使这点更明确,让我们想象一下使用 malloc 分配 10000 字节:
void* buf = malloc(10000);
printf("%p\n", buf); // 0x6f42430
当我们使用它们时,我们的 10k 字节在虚拟内存中看起来是连续的,但将被映射到 3 个不必连续的物理页:
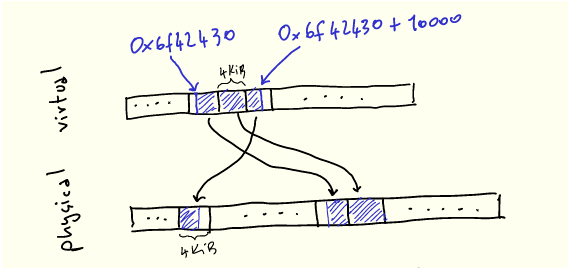
内核的任务之一是管理此映射,这体现在称为页表的数据结构中。CPU 指定页表结构(因为它需要理解页表),内核根据需要对其进行操作。在 x86-64 架构上,页表是一个 4 级 512 路的树,本身位于内存中。 该树的每个节点是(你猜对了!)4KiB 大小,节点内指向下一级的每个条目为 8 字节(4KiB/8bytes = 512)。这些条目包含下一个节点的地址以及其他元数据。
每个进程都有一个页表——换句话说,每个进程都保留了一个虚拟地址空间。当内核上下文切换到进程时,它将特定寄存器 CR3 设置为该树根的物理地址。然后,每当需要将虚拟地址转换为物理地址时,CPU 将该地址拆分成若干段,并使用它们遍历该树,以及计算物理地址。
为了减少这些概念的抽象性,以下是虚拟地址 0x0000f2705af953c0 如何解析为物理地址的直观描述:
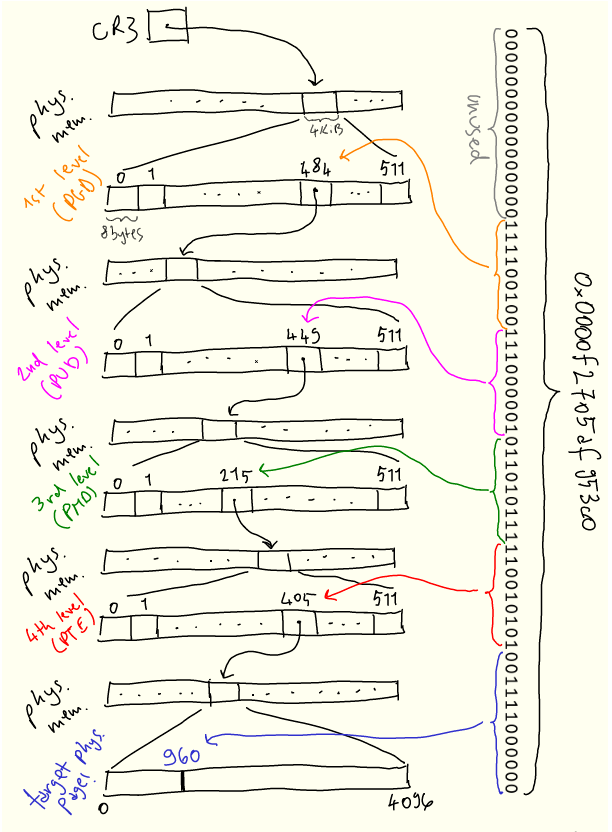
搜索从第一级开始,称为“page global directory”,或 PGD,其物理位置存储在 CR3 中。地址的前 16 位未使用。 我们使用接下来的 9 位 PGD 条目,并向下遍历到第二级“page upper directory”,或 PUD。
接下来的9位用于从 PUD 中选择条目。该过程在下面的两个级别上重复,即 PMD(“page middle directory”)和 PTE(“page table entry”)。PTE 告诉我们要查找的实际物理页在哪里,然后我们使用最后12位来查找页内的偏移量。
页面表的稀疏结构允许在需要新页面时逐步建立映射。每当进程需要内存时,内核将用新条目更新页表。
9. struct page 的作用
struct page 数据结构是这种机制的关键部分:它是内核用来引用单个物理页、存储其物理地址及其各种其他元数据的结构。例如,我们可以从 PTE 中包含的信息(上面描述的页表的最后一级)中获得 struct page。一般来说,它被广泛用于处理页面相关事务的所有代码。
在管道场景下,struct page 用于将其数据保存在环形缓冲区中,正如我们已经看到的:
struct pipe_inode_info {
unsigned int head;
unsigned int tail;
struct pipe_buffer *bufs;
};
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
};
然而,vmsplice 接受虚拟内存作为输入,而 struct page 直接引用物理内存。
因此我们需要将任意的虚拟内存块转换成一组 struct pages。这正是 iov_iter_get_pages 所做的,也是我们花费一半时间的地方:
ssize_t iov_iter_get_pages( struct iov_iter *i, // input: a sized buffer in virtual memory struct page **pages, // output: the list of pages which back the input buffers size_t maxsize, // maximum number of bytes to get unsigned maxpages, // maximum number of pages to get size_t *start // offset into first page, if the input buffer wasn't page-aligned );
struct iov_iter 是一种 Linux 内核数据结构,表示遍历内存块的各种方式,包括 struct iovec。在我们的例子中,它将指向 128KiB 的缓冲区。vmsplice 使用 iov_iter_get_pages 将输入缓冲区转换为一组 struct pages,并保存它们。既然已经知道了分页的工作原理,你可以大概想象一下 iov_iter_get_pages 是如何工作的,下一节详细解释它。
我们已经快速了解了许多新概念,概括如下:
- 现代 CPU 使用虚拟内存进行处理;
- 内存按固定大小的页面进行组织;
- CPU 使用将虚拟页映射到物理页的页表,把虚拟地址转换为物理地址;
- 内核根据需要向页表添加和删除条目;
- 管道是由对物理页的引用构成的,因此 vmsplice 必须将一系列虚拟内存转换为物理页,并保存它们。
10. 获取页的成本
在 iov_iter_get_pages 中所花费的时间,实际上完全花在另一个函数,get_user_page_fast 中:
% perf report -g --symbol-filter=iov_iter_get_pages - 17.08% 0.17% write [kernel.kallsyms] [k] iov_iter_get_pages - 16.91% iov_iter_get_pages - 16.88% internal_get_user_pages_fast 11.22% try_grab_compound_head
get_user_pages_fast 是 iov_iter_get_ pages 的简化版本:
int get_user_pages_fast( // virtual address, page aligned unsigned long start, // number of pages to retrieve int nr_pages, // flags, the meaning of which we won't get into unsigned int gup_flags, // output physical pages struct page **pages )
这里的“user”(与“kernel”相对)指的是将虚拟页转换为对物理页的引用。
为了得到 struct pages,get_user_pages_fast 完全按照 CPU 操作,但在软件中:它遍历页表以收集所有物理页,将结果存储在 struct pages 里。我们的例子中是一个 128KiB 的缓冲区和 4KiB 的页,因此 nr_pages = 32。get_user_page_fast 需要遍历页表树,收集 32 个叶子,并将结果存储在 32 个 struct pages 中。
get_user_pages_fast 还需要确保物理页在调用方不再需要之前不会被重用。这是通过在内核中使用存储在 struct page 中的引用计数来实现的,该计数用于获知物理页在将来何时可以释放和重用。get_user_pages_fast 的调用者必须在某个时候使用 put_page 再次释放页面,以减少引用计数。
最后,get_user_pages_fast 根据虚拟地址是否已经在页表中而表现不同。这就是 _fast 后缀的来源:内核首先将尝试通过遍历页表来获取已经存在的页表条目和相应的 struct page,这成本相对较低,然后通过其他更高成本的方法返回生成 struct page。我们在开始时memset内存的事实,将确保永远不会在 get_user_pages_fast 的“慢”路径中结束,因为页表条目将在缓冲区充满“X”时创建。
注意,get_user_pages 函数族不仅对管道有用——实际上它在许多驱动程序中都是核心。一个典型的用法与我们提及的内核旁路有关:网卡驱动程序可能会使用它将某些用户内存区域转换为物理页,然后将物理页位置传递给网卡,并让网卡直接与该内存区域交互,而无需内核参与。
11. 大体积页面
到目前为止,我们所呈现的页大小始终相同——在 x86-64 架构上为 4KiB。但许多 CPU 架构,包括 x86-64,都包含更大的页面尺寸。x86-64 的情况下,我们不仅有 4KiB 的页(“标准”大小),还有 2MiB 甚至 1GiB 的页(“巨大”页)。在本文的剩余部分中,我们只讨论2MiB的大页,因为 1GiB 的页相当少见,对于我们的任务来说纯属浪费。
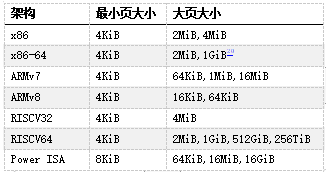
当今常用架构中的页大小,来自维基百科
大页的主要优势在于管理成本更低,因为覆盖相同内存量所需的页更少。此外其他操作的成本也更低,例如将虚拟地址解析为物理地址,因为所需要的页表少了一级:以一个 21 位的偏移量代替页中原来的12位偏移量,从而少一级页表。
这减轻了处理此转换的 CPU 部分的压力,因而在许多情况下提高了性能。但是在我们的例子中,压力不在于遍历页表的硬件,而在内核中运行的软件。
在 Linux 上,我们可以通过多种方式分配 2MiB 大页,例如分配与 2MiB 对齐的内存,然后使用 madvise 告诉内核为提供的缓冲区使用大页:
void* buf = aligned_alloc(1
切换到大页又给我们的程序带来了约 50% 的性能提升:
% ./write --write_with_vmsplice --huge_page | ./read --read_with_splice 51.0GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
然而,提升的原因并不完全显而易见。我们可能会天真地认为,通过使用大页, struct page 将只引用 2MiB 页,而不是 4KiB 页面。
遗憾的是,情况并非如此:内核代码假定 struct page 引用当前架构的“标准”大小的页。这种实现作用于大页(通常Linux称之为“复合页面”)的方式是,“头” struct page 包含关于背后物理页的实际信息,而连续的“尾”页仅包含指向头页的指针。
因此为了表示 2MiB 的大页,将有1个“头”struct page,最多 511 个“尾”struct pages。或者对于我们的 128KiB 缓冲区来说,有 31个尾 struct pages:
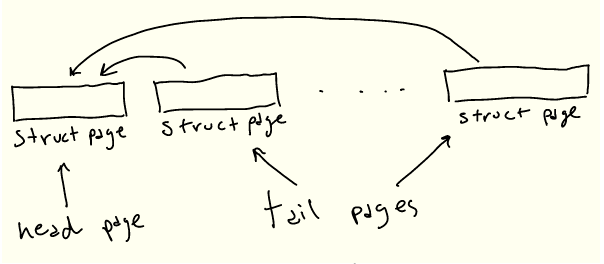
即使我们需要所有这些 struct pages,最后生成它的代码也会大大加快。找到第一个条目后,可以在一个简单的循环中生成后面的 struct pages,而不是多次遍历页表。这样就提高了性能!
12. Busy looping
我们很快就要完成了,我保证!再看一下 perf 的输出:
- 46.91% 0.38% write libc-2.33.so [.] vmsplice - 46.84% vmsplice - 43.15% entry_SYSCALL_64_after_hwframe - do_syscall_64 - 41.80% __do_sys_vmsplice + 14.90% wait_for_space + 8.27% __wake_up_common_lock 4.40% add_to_pipe + 4.24% iov_iter_get_pages + 3.92% __mutex_lock.constprop.0 1.81% iov_iter_advance + 0.55% import_iovec + 0.76% syscall_exit_to_user_mode 1.54% syscall_return_via_sysret 1.49% __entry_text_start
现在大量时间花费在等待管道可写(wait_for_space),以及唤醒等待管道填充内容的读程序(__wake_up_common_lock)。
为了避免这些同步成本,如果管道无法写入,我们可以让 vmsplice 返回,并执行忙循环直到写入为止——在用 splice 读取时做同样的处理:
... // SPLICE_F_NONBLOCK will cause `vmsplice` to return immediately // if we can't write to the pipe, returning EAGAIN ssize_t ret = vmsplice(STDOUT_FILENO, &bufvec, 1, SPLICE_F_NONBLOCK); if (ret
通过忙循环,我们的性能又提高了25%:
% ./write --write_with_vmsplice --huge_page --busy_loop | ./read --read_with_splice --busy_loop 62.5GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
13. 总结
通过查看 perf 输出和 Linux 源码,我们系统地提高了程序性能。在高性能编程方面,管道和拼接并不是真正的热门话题,而我们这里所涉及的主题是:零拷贝操作、环形缓冲区、分页与虚拟内存、同步开销。
尽管我省略了一些细节和有趣的话题,但这篇博文还是已经失控而变得太长了:
- 在实际代码中,缓冲区是分开分配的,通过将它们放置在不同的页表条目中来减少页表争用(FizzBuzz程序也是这样做的)。
- 记住,当使用 get_user_pages 获取页表条目时,其 refcount 增加,而 put_page 减少。如果我们为两个缓冲区使用两个页表条目,而不是为两个缓冲器共用一个页表条目的话,那么在修改 refcount 时争用更少。
- 通过用taskset将./write和./read进程绑定到两个核来运行测试。
- 资料库中的代码包含了我试过的许多其他选项,但由于这些选项无关紧要或不够有趣,所以最终没有讨论。
- 资料库中还包含get_user_pages_fast 的一个综合基准测试,可用来精确测量在用或不用大页的情况下运行的速度慢多少。
- 一般来说,拼接是一个有点可疑/危险的概念,它继续困扰着内核开发人员。
请让我知道本文是否有用、有趣或不一定!
14. 致谢
非常感谢 Alexandru Scvorţov、Max Staudt、Alex Appetiti、Alex Sayers、Stephen Lavelle、Peter Cawley和Niklas Hambüchen审阅了本文的草稿。Max Staudt 还帮助我理解了 get_user_page 的一些微妙之处。
\1. 这将在风格上类似于我的atan2f性能调研(https://mazzo.li/posts/vectorized-atan2.html),尽管所讨论的程序仅用于学习。此外,我们将在不同级别上优化代码。调优 atan2f 是在汇编语言输出指导下进行的微优化,调优管道程序则涉及查看 perf 事件,并减少各种内核开销。
\2. 本测试在英特尔 Skylake i7-8550U CPU 和 Linux 5.17 上运行。你的环境可能会有所不同,因为在过去几年中,影响本文所述程序的 Linux 内部结构一直在不断变化,并且在未来版本中可能还会调整。
\3. “FizzBuzz”据称是一个常见的编码面试问题,虽然我个人从来没有被问到过该问题,但我有确实发生过的可靠证据。
\4. 尽管我们固定了缓冲区大小,但即便我们使用不同的缓冲区大小,考虑到其他瓶颈的影响,(吞吐量)数字实际也并不会有很大差异。
\5. 关于有趣的细节,可随时参考资料库。一般来说,我不会在这里逐字复制代码,因为细节并不重要。相反,我将贴出更新的代码片段。
\6. 注意,这里我们分析了一个包括管道读取和写入的shell调用——默认情况下,perf record跟踪所有子进程。
\7. 分析该程序时,我注意到 perf 的输出被来自“Pressure Stall Information”基础架构(PSI)的信息所污染。因此这些数字取自一个禁用PSI后编译的内核。这可以通过在内核构建配置中设置 CONFIG_PSI=n 来实现。在NixOS 中:
boot.kernelPatches = [{
name = "disable-psi";
patch = null;
extraConfig = ''
PSI n
'';
}];
此外,为了让 perf 能正确显示在系统调用中花费的时间,必须有内核调试符号。如何安装符号因发行版而异。在最新的 NixOS 版本中,默认情况下会安装它们。
\8. 假如你运行了 perf record -g,可以在 perf report 中用 + 展开调用图。
\9. 被称为 tmp_page 的单一“备用页”实际上由 pipe_read 保留,并由pipe_write 重用。然而由于这里始终只是一个页面,我无法利用它来实现更高的性能,因为在调用 pipe_write 和 pipe_ read 时,页面重用会被固定开销所抵消。
\10. 从技术上讲,vmsplice 还支持在另一个方向上传输数据,尽管用处不大。如手册页所述:
“
vmsplice实际上只支持从用户内存到管道的真正拼接。反方向上,它实际上只是将数据复制到用户空间。
”
\11. Travis Downs 指出,该方案可能仍然不安全,因为页面可能会被进一步拼接,从而延长其生命期。这个问题也出现在最初的 FizzBuzz 帖子中。事实上,我并不完全清楚不带 SPLICE_F_GIFT 的 vmsplice 是否真的不安全——vmsplic 的手册页说明它是安全的。然而,在这种情况下,绝对需要特别小心,以实现零拷贝管道,同时保持安全。在测试程序中,读取端将管道拼接到/dev/null 中,因此可能内核知道可以在不复制的情况下拼接页面,但我尚未验证这是否是实际发生的情况。
\12. 这里我们呈现了一个简化模型,其中物理内存是一个简单的平面线性序列。现实情况复杂一些,但简单模型已能说明问题。
\13. 可以通过读取 /proc/self/pagemap 来检查分配给当前进程的虚拟页面所对应的物理地址,并将“页面帧号”乘以页面大小。
\14. 从 Ice Lake 开始,英特尔将页表扩展为5级,从而将最大可寻址内存从256TiB 增加到 128PiB。但此功能必须显式开启,因为有些程序依赖于指针的高 16 位不被使用。
\15. 页表中的地址必须是物理地址,否则我们会陷入死循环。
\16. 注意,高 16 位未使用:这意味着我们每个进程最多可以处理 248 − 1 字节,或 256TiB 的物理内存。
\17. struct page 可能指向尚未分配的物理页,这些物理页还没有物理地址和其他与页相关的抽象。它们被视为对物理页面的完全抽象的引用,但不一定是对已分配的物理页面的引用。这一微妙观点将在后面的旁注中予以说明。
\18. 实际上,管道代码总是在 nr_pages = 16 的情况下调用 get_user_pages_fast,必要时进行循环,这可能是为了使用一个小的静态缓冲区。但这是一个实现细节,拼接页面的总数仍将是32。
\19. 以下部分是本文不需要理解的微妙之处!
如果页表不包含我们要查找的条目,get_user_pages_fast 仍然需要返回一个 struct page。最明显的方法是创建正确的页表条目,然后返回相应的 struct page。
然而,get_user_pages_fast 仅在被要求获取 struct page 以写入其中时才会这样做。否则它不会更新页表,而是返回一个 struct page,给我们一个尚未分配的物理页的引用。这正是 vmsplice 的情况,因为我们只需要生成一个 struct page 来填充管道,而不需要实际写入任何内存。
换句话说,页面分配会被延迟,直到我们实际需要时。这节省了分配物理页的时间,但如果页面从未通过其他方式填充错误,则会导致重复调用 get_user_pages_fast 的慢路径。
因此,如果我们之前不进行 memset,就不会“手动”将错误页放入页表中,结果是不仅在第一次调用 get_user_pages_fast 时会陷入慢路径,而且所有后续调用都会出现慢路径,从而导致明显地减速(25GiB/s而不是30GiB/s):
% ./write --write_with_vmsplice --dont_touch_pages | ./read --read_with_splice 25.0GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
此外,在使用大页时,这种行为不会表现出来:在这种情况下,get_user_pages_fast 在传入一系列虚拟内存时,大页支持将正确地填充错误页。
如果这一切都很混乱,不要担心,get_user_page 和 friends 似乎是内核中非常棘手的一角,即使对于内核开发人员也是如此。
\20. 仅当 CPU 具有 PDPE1GB 标志时。
\21. 例如,CPU包含专用硬件来缓存部分页表,即“转换后备缓冲区”(translation lookaside buffer,TLB)。TLB 在每次上下文切换(每次更改 CR3 的内容)时被刷新。大页可以显著减少 TLB 未命中,因为 2MiB 页的单个条目覆盖的内存是 4KiB 页面的 512 倍。
\22. 如果你在想“太烂了!”正在进行各种努力来简化和/或优化这种情况。最近的内核(从5.17开始)包含了一种新的类型,struct folio,用于显式标识头页。这减少了运行时检查 struct page 是头页还是尾页的需要,从而提高了性能。其他努力的目标是彻底移除额外的 struct pages,尽管我不知道怎么做的。
以上がLinux パイプは実際どのくらい高速になるのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7696
7696
 15
1640
14
1393
52
1287
25
1229
29
15
1640
14
1393
52
1287
25
1229
29

 VSCODEに必要なコンピューター構成
Apr 15, 2025 pm 09:48 PM
VSCODEに必要なコンピューター構成
Apr 15, 2025 pm 09:48 PM
VSコードシステムの要件:オペレーティングシステム:オペレーティングシステム:Windows 10以降、MACOS 10.12以上、Linux Distributionプロセッサ:最小1.6 GHz、推奨2.0 GHz以上のメモリ:最小512 MB、推奨4 GB以上のストレージスペース:最低250 MB以上:その他の要件を推奨:安定ネットワーク接続、XORG/WAYLAND(Linux)
 VSCODEは拡張子をインストールできません
Apr 15, 2025 pm 07:18 PM
VSCODEは拡張子をインストールできません
Apr 15, 2025 pm 07:18 PM
VSコード拡張機能のインストールの理由は、ネットワークの不安定性、許可不足、システム互換性の問題、VSコードバージョンが古すぎる、ウイルス対策ソフトウェアまたはファイアウォール干渉です。ネットワーク接続、許可、ログファイル、およびコードの更新、セキュリティソフトウェアの無効化、およびコードまたはコンピューターの再起動を確認することにより、問題を徐々にトラブルシューティングと解決できます。
 Apr 16, 2025 pm 07:39 PM
Apr 16, 2025 pm 07:39 PM
NotePadはJavaコードを直接実行することはできませんが、他のツールを使用することで実現できます。コマンドラインコンパイラ(Javac)を使用してByteCodeファイル(filename.class)を生成します。 Javaインタープリター(Java)を使用して、バイトコードを解釈し、コードを実行し、結果を出力します。
 vscodeとは何ですか?vscodeとは何ですか?
Apr 15, 2025 pm 06:45 PM
vscodeとは何ですか?vscodeとは何ですか?
Apr 15, 2025 pm 06:45 PM
VSコードは、Microsoftが開発した無料のオープンソースクロスプラットフォームコードエディターと開発環境であるフルネームVisual Studioコードです。幅広いプログラミング言語をサポートし、構文の強調表示、コード自動完了、コードスニペット、および開発効率を向上させるスマートプロンプトを提供します。リッチな拡張エコシステムを通じて、ユーザーは、デバッガー、コードフォーマットツール、GIT統合など、特定のニーズや言語に拡張機能を追加できます。 VSコードには、コードのバグをすばやく見つけて解決するのに役立つ直感的なデバッガーも含まれています。
 vscodeはMacに使用できますか
Apr 15, 2025 pm 07:36 PM
vscodeはMacに使用できますか
Apr 15, 2025 pm 07:36 PM
VSコードはMacで利用できます。強力な拡張機能、GIT統合、ターミナル、デバッガーがあり、豊富なセットアップオプションも提供しています。ただし、特に大規模なプロジェクトまたは非常に専門的な開発の場合、コードと機能的な制限がある場合があります。
 vscodeの使用方法
Apr 15, 2025 pm 11:21 PM
vscodeの使用方法
Apr 15, 2025 pm 11:21 PM
Visual Studio Code(VSCODE)は、Microsoftが開発したクロスプラットフォーム、オープンソース、および無料のコードエディターです。軽量、スケーラビリティ、および幅広いプログラミング言語のサポートで知られています。 VSCODEをインストールするには、公式Webサイトにアクセスして、インストーラーをダウンロードして実行してください。 VSCODEを使用する場合、新しいプロジェクトを作成し、コードを編集し、コードをデバッグし、プロジェクトをナビゲートし、VSCODEを展開し、設定を管理できます。 VSCODEは、Windows、MacOS、Linuxで利用でき、複数のプログラミング言語をサポートし、マーケットプレイスを通じてさまざまな拡張機能を提供します。その利点には、軽量、スケーラビリティ、広範な言語サポート、豊富な機能とバージョンが含まれます
 Linuxの主な目的は何ですか?
Apr 16, 2025 am 12:19 AM
Linuxの主な目的は何ですか?
Apr 16, 2025 am 12:19 AM
Linuxの主な用途には、1。Serverオペレーティングシステム、2。EmbeddedSystem、3。Desktopオペレーティングシステム、4。開発およびテスト環境。 Linuxはこれらの分野で優れており、安定性、セキュリティ、効率的な開発ツールを提供します。
 GITの倉庫アドレスを確認する方法
Apr 17, 2025 pm 01:54 PM
GITの倉庫アドレスを確認する方法
Apr 17, 2025 pm 01:54 PM
gitリポジトリアドレスを表示するには、次の手順を実行します。1。コマンドラインを開き、リポジトリディレクトリに移動します。 2。「git remote -v」コマンドを実行します。 3.出力と対応するアドレスでリポジトリ名を表示します。
