

Linux プロセス グループ スケジューリング メカニズム: プロセスをグループ化してスケジュールする方法

プロセス グループは、Linux システムでプロセスを分類および管理する方法であり、同じ特性または関係を持つプロセスをまとめて論理ユニットを形成できます。プロセス グループの機能は、プロセスの制御、通信、リソース割り当てを容易にして、システムの効率とセキュリティを向上させることです。プロセス グループ スケジューリングは、Linux システムでプロセス グループをスケジュールするためのメカニズムであり、プロセス グループの属性とニーズに基づいて適切な CPU 時間とリソースを割り当てることができるため、システムの同時実行性と応答性が向上します。しかし、Linux プロセス グループのスケジューリング メカニズムを本当に理解していますか? Linux でプロセス グループを作成および管理する方法をご存知ですか? Linux でプロセス グループ スケジューリング メカニズムを使用および構成する方法をご存知ですか?この記事では、Linux プロセス グループのスケジューリング メカニズムに関する関連知識を詳しく紹介し、Linux でこの強力なカーネル機能をよりよく使用し、理解できるようにします。

別の魔法のプロセス スケジューリングの問題が発生しました。システムの再起動プロセス中に、システムがハングし、30 秒後にリセットされたことが判明しました。システム リセットの本当の原因は、元のシステムではなく、ハードウェア ウォッチドッグによってシステムが再起動されたことでした。システムの通常の再起動プロセス。ドッグに餌を与えていない場合、ハードウェアドッグレコードのリセット時間が 30 秒繰り上げられますが、シリアルポートレコードのログを分析すると、その時点のログに「sched: RT throttling activate」という文が出力されていました。
linux-3.0.101-0.7.17 バージョンのカーネル コードから、sched_rt_runtime_exceeded がこの文を出力していることがわかります。カーネルのプロセス グループ スケジューリング プロセスでは、rt_rq->rt_throttled によってリアルタイム プロセス スケジューリングが制限されます。Linux のプロセス グループ スケジューリング メカニズムについては、以下で詳しく説明します。
プロセス グループのスケジューリング メカニズム
グループ スケジューリングは cgroup の概念であり、N プロセスを全体として扱い、システム内のスケジューリング プロセスに参加することを指します。これは例に反映されています: タスク A には 8 つのプロセスまたはスレッドがあり、タスク B には 2 つのプロセスまたはスレッドがありますスレッドは、他のプロセスまたはスレッドが存在する場合、タスク A の CPU 使用率が 40% を超えないよう、タスク B の CPU 使用率が 40% を超えないよう制御する必要があります。他のタスクの占有率が 20% 以上である場合、cgroup のしきい値設定があり、cgroup A は 200、cgroup B は 200、その他のタスクはデフォルトの 100 に設定され、CPU 制御機能が実現されます。
カーネルでは、プロセス グループは task_group によって管理され、関連する内容の多くは cgroup 制御メカニズムです。また、開発単位が作成されています。ここでは、グループ スケジューリングに焦点を当てた部分を参照します。詳細については、次のコメントを参照してください。 。
スケジューリングユニットには、通常スケジューリングユニットとリアルタイムプロセススケジューリングユニットの2種類があります。
リーリーリアルタイム スケジューリングと通常のスケジューリング キューで説明する必要があるオプションは似ているため、スケジューリング キューを見てみましょう。リアルタイム キューを例に挙げます:
リーリー上記の 3 つの構造を分析すると、次の図が得られます (クリックすると図が拡大します)。
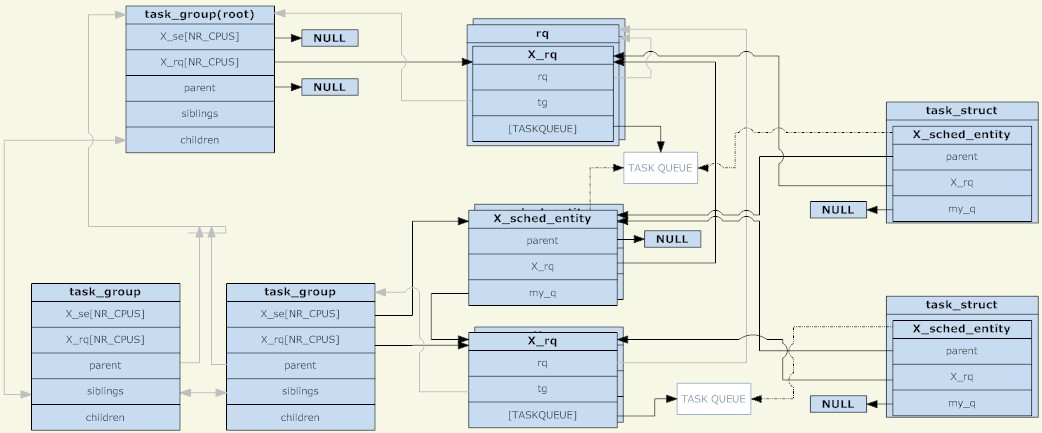 タスクグループ
タスクグループ図からわかるように、スケジューリング ユニットとスケジューリング キューは別のツリー構造であるツリー ノードに結合されていますが、スケジューリング ユニットは TASK_RUNNING がある場合にのみ動作することに注意してください。スケジューリングユニット内のプロセスがディスパッチキューに置かれます。
もう 1 つのポイントは、グループ スケジューリングが存在する前は、各 CPU にスケジューリング キューが 1 つしかなかったということです。当時は、すべてのプロセスが 1 つのスケジューリング グループに属していると理解できましたが、現在では、各スケジューリング グループが各 CPU にスケジューリング キューを持っています。スケジューリング プロセス中に、システムは最初に実行するプロセスを選択しました。現在は、実行するスケジューリング単位を選択します。スケジューリングが発生すると、スケジュール プロセスは root_task_group から開始され、スケジューリング ポリシーによって決定されたスケジューリング単位を探します。ユニットが task_group の場合、task_group に入り、実行キューは適切なスケジューリング ユニットを選択し、最終的に適切なタスク スケジューリング ユニットを見つけます。プロセス全体はツリー トラバーサルであり、TASK_RUNNING プロセスを持つ task_group がツリーのノード、タスク スケジューリング ユニットがツリーのリーフになります。
グループ プロセス スケジューリング ポリシー
グループ プロセス スケジューリングの目的は、リアルタイム プロセス スケジューリングと通常のプロセス スケジューリング、つまり rt および cfs スケジューリングを完了するという本来の目的と変わりません。
CFS组调度策略:
文章前面示例中提到的任务分配CPU,说的就是cfs调度,对于CFS调度而言,调度单元和普通调度进程没有多大区别,调度单元由自己的调度优先级,而且不受调度进程的影响,每个task_group都有一个shares,share并非我们说的进程优先级,而是调度权重,这个是cfs调度管理的概念,但在cfs中最终体现到调度优先排序上。shares值默认都是相同的,所有没有设置权重的值,CPU都是按旧有的cfs管理分配的。总结的说,就是cfs组调度策略没变化。具体到cgroup的CPU控制机制上再说。
RT组调度策略:
实时进程的优先级是设置固定,调度器总是选择优先级最高的进程运行。而在组调度中,调度单元的优先级则是组内优先级最高的调度单元的优先级值,也就是说调度单元的优先级受子调度单元影响,如果一个进程进入了调度单元,那么它所有的父调度单元的调度队列都要重排。实际上我们看到的结果是,调度器总是选择优先级最高的实时进程调度,那么组调度对实时进程控制机制是怎么样的?
在前面的rt_rq实时进程运行队列里面提到rt_time和rt_runtime,一个是运行累计时间,一个是最大运行时间,当运行累计时间超过最大运行时间的时候,rt_throttled则被设置为1,见sched_rt_runtime_exceeded函数。
if (rt_rq->rt_time > runtime) {
rt_rq->rt_throttled = 1;
if (rt_rq_throttled(rt_rq)) {
sched_rt_rq_dequeue(rt_rq);
return 1;
}
}
设置为1意味着实时队列中被限制了,如__enqueue_rt_entity函数,不能入队。
static inline int rt_rq_throttled(struct rt_rq *rt_rq)
{
return rt_rq->rt_throttled && !rt_rq->rt_nr_boosted;
}
static void __enqueue_rt_entity(struct sched_rt_entity *rt_se, bool head)
{
/*
* Don't enqueue the group if its throttled, or when empty.
* The latter is a consequence of the former when a child group
* get throttled and the current group doesn't have any other
* active members.
*/
if (group_rq && (rt_rq_throttled(group_rq) || !group_rq->rt_nr_running))
return;
.....
}
其实还有一个隐藏的时间概念,即sched_rt_period_us,意味着sched_rt_period_us时间内,实时进程可以占用CPU rt_runtime时间,如果实时进程每个时间周期内都没有调度,则在do_sched_rt_period_timer定时器函数中将rt_time减去一个周期,然后比较rt_runtime,恢复rt_throttled。
//overrun来自对周期时间定时器误差的校正 rt_rq->rt_time -= min(rt_rq->rt_time, overrun*runtime); if (rt_rq->rt_throttled && rt_rq->rt_time rt_throttled = 0; enqueue = 1;
则对于cgroup控制实时进程的占用比则是通过rt_runtime实现的,对于root_task_group,也即是所有进程在一个cgroup下,则是通过/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us接口设置的,默认值是1s和0.95s。这么看以为实时进程只能占用95%CPU,那么实时进程占用CPU100%导致进程挂死的问题怎么出现了?
原来实时进程所在的CPU占用超时了,实时进程的rt_runtime可以向别的cpu借用,将其他CPU剩余的rt_runtime-rt_time的值借过来,如此rt_time可以最大等于rt_runtime,造成事实上的单核CPU达到100%。这样做的目的自然规避了实时进程缺少CPU时间而向其他核迁移的成本,未绑核的普通进程自然也可以迁移其他CPU上,不会得不到调度,当然绑核进程仍然是个杯具。
static int do_balance_runtime(struct rt_rq *rt_rq)
{
struct rt_bandwidth *rt_b = sched_rt_bandwidth(rt_rq);
struct root_domain *rd = cpu_rq(smp_processor_id())->rd;
int i, weight, more = 0;
u64 rt_period;
weight = cpumask_weight(rd->span);
raw_spin_lock(&rt_b->rt_runtime_lock);
rt_period = ktime_to_ns(rt_b->rt_period);
for_each_cpu(i, rd->span) {
struct rt_rq *iter = sched_rt_period_rt_rq(rt_b, i);
s64 diff;
if (iter == rt_rq)
continue;
raw_spin_lock(&iter->rt_runtime_lock);
/*
* Either all rqs have inf runtime and there's nothing to steal
* or __disable_runtime() below sets a specific rq to inf to
* indicate its been disabled and disalow stealing.
*/
if (iter->rt_runtime == RUNTIME_INF)
goto next;
/*
* From runqueues with spare time, take 1/n part of their
* spare time, but no more than our period.
*/
diff = iter->rt_runtime - iter->rt_time;
if (diff > 0) {
diff = div_u64((u64)diff, weight);
if (rt_rq->rt_runtime + diff > rt_period)
diff = rt_period - rt_rq->rt_runtime;
iter->rt_runtime -= diff;
rt_rq->rt_runtime += diff;
more = 1;
if (rt_rq->rt_runtime == rt_period) {
raw_spin_unlock(&iter->rt_runtime_lock);
break;
}
}
next:
raw_spin_unlock(&iter->rt_runtime_lock);
}
raw_spin_unlock(&rt_b->rt_runtime_lock);
return more;
}
通过本文,你应该对 Linux 进程组调度机制有了一个深入的了解,知道了它的定义、原理、流程和优化方法。你也应该明白了进程组调度机制的作用和影响,以及如何在 Linux 下正确地使用和配置进程组调度机制。我们建议你在使用 Linux 系统时,使用进程组调度机制来提高系统的效率和安全性。同时,我们也提醒你在使用进程组调度机制时要注意一些潜在的问题和挑战,如进程组类型、优先级、限制等。希望本文能够帮助你更好地使用 Linux 系统,让你在 Linux 下享受进程组调度机制的优势和便利。
以上がLinux プロセス グループ スケジューリング メカニズム: プロセスをグループ化してスケジュールする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7549
7549
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 CentosとUbuntuの違い
Apr 14, 2025 pm 09:09 PM
CentosとUbuntuの違い
Apr 14, 2025 pm 09:09 PM
Centosとubuntuの重要な違いは次のとおりです。起源(CentosはRed Hat、for Enterprises、UbuntuはDebianに由来します。個人用のDebianに由来します)、パッケージ管理(CentosはYumを使用し、安定性に焦点を当てます。チュートリアルとドキュメント)、使用(Centosはサーバーに偏っています。Ubuntuはサーバーやデスクトップに適しています)、その他の違いにはインストールのシンプルさが含まれます(Centos is Thin)
 Centosをインストールする方法
Apr 14, 2025 pm 09:03 PM
Centosをインストールする方法
Apr 14, 2025 pm 09:03 PM
Centosのインストール手順:ISO画像をダウンロードし、起動可能なメディアを燃やします。起動してインストールソースを選択します。言語とキーボードのレイアウトを選択します。ネットワークを構成します。ハードディスクをパーティション化します。システムクロックを設定します。ルートユーザーを作成します。ソフトウェアパッケージを選択します。インストールを開始します。インストールが完了した後、ハードディスクから再起動して起動します。
 メンテナンスを停止した後のCentosの選択
Apr 14, 2025 pm 08:51 PM
メンテナンスを停止した後のCentosの選択
Apr 14, 2025 pm 08:51 PM
Centosは廃止されました、代替品には次のものが含まれます。1。RockyLinux(最高の互換性)。 2。アルマリン(Centosと互換性); 3。Ubuntuサーバー(設定が必要); 4。RedHat Enterprise Linux(コマーシャルバージョン、有料ライセンス); 5。OracleLinux(CentosとRhelと互換性があります)。移行する場合、考慮事項は次のとおりです。互換性、可用性、サポート、コスト、およびコミュニティサポート。
 Dockerデスクトップの使用方法
Apr 15, 2025 am 11:45 AM
Dockerデスクトップの使用方法
Apr 15, 2025 am 11:45 AM
Dockerデスクトップの使用方法は? Dockerデスクトップは、ローカルマシンでDockerコンテナを実行するためのツールです。使用する手順には次のものがあります。1。Dockerデスクトップをインストールします。 2。Dockerデスクトップを開始します。 3。Docker Imageを作成します(DockerFileを使用); 4. Docker画像をビルド(Docker Buildを使用); 5。Dockerコンテナを実行します(Docker Runを使用)。
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosがメンテナンスを停止した後の対処方法
Apr 14, 2025 pm 08:48 PM
Centosがメンテナンスを停止した後の対処方法
Apr 14, 2025 pm 08:48 PM
CentOSが停止した後、ユーザーは次の手段を採用して対処できます。Almalinux、Rocky Linux、Centosストリームなどの互換性のある分布を選択します。商業分布に移行する:Red Hat Enterprise Linux、Oracle Linuxなど。 Centos 9ストリームへのアップグレード:ローリングディストリビューション、最新のテクノロジーを提供します。 Ubuntu、Debianなど、他のLinuxディストリビューションを選択します。コンテナ、仮想マシン、クラウドプラットフォームなどの他のオプションを評価します。
 VSCODEに必要なコンピューター構成
Apr 15, 2025 pm 09:48 PM
VSCODEに必要なコンピューター構成
Apr 15, 2025 pm 09:48 PM
VSコードシステムの要件:オペレーティングシステム:オペレーティングシステム:Windows 10以降、MACOS 10.12以上、Linux Distributionプロセッサ:最小1.6 GHz、推奨2.0 GHz以上のメモリ:最小512 MB、推奨4 GB以上のストレージスペース:最低250 MB以上:その他の要件を推奨:安定ネットワーク接続、XORG/WAYLAND(Linux)
 Dockerはどのような根本的なテクノロジーを使用していますか?
Apr 15, 2025 am 07:09 AM
Dockerはどのような根本的なテクノロジーを使用していますか?
Apr 15, 2025 am 07:09 AM
Dockerは、コンテナエンジン、ミラー形式、ストレージドライバー、ネットワークモデル、コンテナオーケストールツール、オペレーティングシステム仮想化、コンテナレジストリを使用して、コンテナ化機能をサポートし、軽量でポータブルで自動化されたアプリケーションの展開と管理を提供します。
