

Linux CFS: プロセスのスケジューリングで完全な公平性を実現する方法

プロセス スケジューリングは、オペレーティング システムの中核機能の 1 つで、どのプロセスが CPU 実行時間を取得できるか、およびどのくらいの時間を取得できるかを決定します。 Linux システムには、多くのプロセス スケジューリング アルゴリズムがあります。最も重要で一般的に使用されているアルゴリズムは、Linux バージョン 2.6.23 から導入された完全公平スケジューリング アルゴリズム (CFS) です。 CFS の目標は、各プロセスが自身の重みとニーズに応じて合理的かつ公平に CPU 時間を割り当てられるようにし、それによってシステム全体のパフォーマンスと応答速度を向上させることです。この記事では、CFS の基本原理、データ構造、実装の詳細、利点と欠点を紹介し、Linux プロセス スケジューリングの完全な公平性を深く理解するのに役立ちます。
Linux スケジューラの簡単な歴史
初期の Linux スケジューラは、ハイパースレッディングはおろか、多くのプロセッサを備えた大規模なアーキテクチャに焦点を当てていないミニマルな設計を使用していました。 1.2 Linux スケジューラは、実行可能なタスク管理にリング キューを使用し、ラウンドロビン スケジューリング戦略を使用します。このスケジューラは、プロセスを非常に効率的に追加および削除します (構造を保護するロックを使用)。つまり、スケジューラは複雑ではなく、シンプルかつ高速です。
Linux バージョン 2.2 では、クラスのスケジューリングの概念が導入され、リアルタイム タスク、非プリエンプティブ タスク、および非リアルタイム タスクのスケジューリング戦略が可能になりました。 2.2 スケジューラには、対称型マルチプロセッシング (SMP) サポートも含まれています。
2.4 カーネルには、O(N) 間隔で実行される比較的単純なスケジューラが含まれています (スケジューラは、スケジューリング イベント中に各タスクを反復します)。 2.4 スケジューラは時間をエポックに分割し、各エポックではタイム スライスが使い果たされるまで各タスクの実行が許可されます。タスクがタイム スライスをすべて使用していない場合、残りのタイム スライスの半分が新しいタイム スライスに追加され、次のエポックでより長く実行できるようになります。スケジューラは単純にタスクを反復し、良性関数 (メトリック) を適用して、次にどのタスクを実行するかを決定します。この方法は比較的単純ですが、非効率的でスケーラビリティに欠けており、リアルタイム システムでの使用には適していません。また、マルチコア プロセッサなどの新しいハードウェア アーキテクチャを活用する機能も欠けています。
O(1) スケジューラと呼ばれる初期の 2.6 スケジューラは、2.4 スケジューラの問題を解決するように設計されました。スケジューラは、次にスケジュールするタスクを決定するためにタスクのリスト全体を反復処理する必要がありませんでした (そのため、O( という名前が付けられています)。 1) 、これはより効率的でスケーラブルであることを意味します)。 O(1) スケジューラは、実行キュー内の実行可能なタスクを追跡します (実際には、優先度レベルごとに 2 つの実行キューがあります。1 つはアクティブなタスク用、もう 1 つは期限切れのタスク用です)。これは、次にどのタスクを実行するかを決定することを意味します。単に優先度に基づいて特定のアクティビティの実行キューから次のタスクを削除します)。 O(1) スケジューラは拡張性が高く、対話性が備わっているため、タスクが I/O バウンドであるかプロセッサ バウンドであるかを判断するための豊富な洞察が得られます。しかし、カーネル内の O(1) スケジューラは扱いにくいです。啓示を計算するには多くのコードが必要で、管理が難しく、純粋主義者にとってはアルゴリズムの本質を捉えることができません。
O(1) スケジューラが直面する問題を解決し、その他の外部からの圧力に対処するには、何かを変更する必要があります。この変更は、Con Kolivas のカーネル パッチから来ており、これには彼の初期の階段スケジューラの成果を組み込んだ Rotating Staircase Deadline Scheduler (RSDL) が含まれています。この作業の結果、公平性と制限されたレイテンシを組み込んだシンプルに設計されたスケジューラが完成しました。 Kolivas のスケジューラは多くの注目を集めており (そして多くの人がそれを現在の 2.6.21 メインストリーム カーネルに含めることを求めています)、スケジューラの変更が予定されていることは明らかです。 O(1) スケジューラの作成者である Ingo Molnar は、Kolivas のアイデアの一部を基にして CFS ベースのスケジューラを開発しました。 CFS を詳しく分析し、それが高レベルでどのように動作するかを見てみましょう。
————————————————————————————————————————
CFS の概要
CFS の背後にある主な考え方は、プロセッサ時間をタスクに提供するという点でバランス (公平性) を維持することです。これは、プロセスにかなりの数のプロセッサを割り当てる必要があることを意味します。タスクに割り当てられた時間のバランスが崩れている場合 (1 つ以上のタスクに他のタスクに比べて十分な時間が与えられていないことを意味します)、バランスが崩れているタスクには実行時間を与える必要があります。
バランスを実現するために、CFS はいわゆる仮想ランタイムでタスクに提供される時間を維持します。タスクの仮想実行時間が短いほど、タスクがサーバーにアクセスできる時間が短くなり、プロセッサに対する要求が高くなります。 CFS にはスリープ フェアネスの概念も含まれており、現在実行されていないタスク (I/O 待機中など) が、最終的に必要になったときにプロセッサの公平なシェアを確実に取得できるようになります。
しかし、タスクを実行キューに保持しなかった以前の Linux スケジューラとは異なり、CFS は時間順の赤黒ツリーを保持しました (図 1 を参照)。赤黒木は、多くの興味深い有用な特性を持つ木です。まず、これは自己バランス型です。つまり、ツリー内のどのパスも他のパスの 2 倍を超える長さはありません。 2 番目に、ツリー上での実行は O(log n) 時間で実行されます (n はツリー内のノードの数です)。これは、タスクを迅速かつ効率的に挿入または削除できることを意味します。
図 1. 赤黒ツリーの例
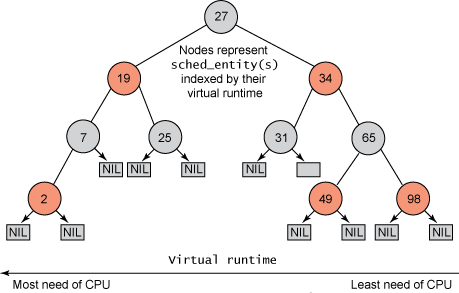
タスクは時間順の赤黒ツリー (sched_entity オブジェクトで表される) に格納され、最もプロセッサを要求するタスク (仮想ランタイムが最も低い) がその左側に格納されます。ツリーでは、プロセッサ要件が最も少ない (仮想ランタイムが最も高い) タスクがツリーの右側に格納されます。次に、公平性を保つために、スケジューラは次にスケジュールされる赤黒ツリーの左端のノードを選択します。タスクは、その実行時間を仮想ランタイムに加算することによって CPU 時間を計算し、実行可能であればツリーに挿入し直します。このようにして、ツリーの左側のタスクには実行時間が与えられ、公平性を維持するためにツリーの内容が右から左に移行されます。したがって、各実行可能タスクは他のタスクに追いつき、実行可能タスクのセット全体にわたって実行バランスを維持します。
————————————————————————————————————————
CFS 内部原則
Linux 内のすべてのタスクは、task_struct というタスク構造によって表されます。この構造 (およびその他の関連コンテンツ) はタスクを完全に記述しており、タスクの現在の状態、そのスタック、プロセス ID、優先度 (静的および動的) などが含まれます。これらの構造と関連する構造は、./linux/include/linux/sched.h にあります。ただし、すべてのタスクが実行可能であるわけではないため、task_struct には CFS 関連のフィールドは見つかりません。代わりに、スケジューリング情報を追跡するために、sched_entity という名前の新しい構造が作成されます (図 2 を参照)。
図 2. タスクと赤黒ツリーの構造階層
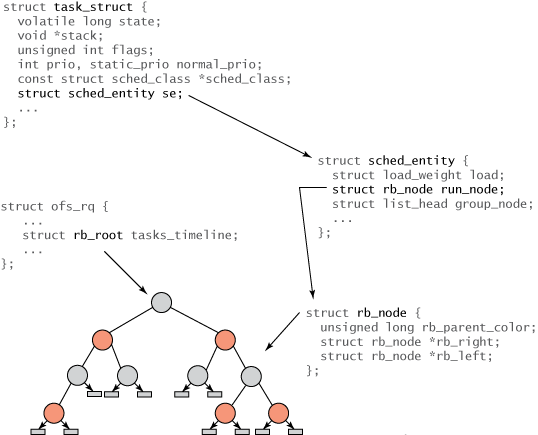
さまざまな構造間の関係を図 2 に示します。ツリーのルートは、rb_root 要素を介して cfs_rq 構造体 (./kernel/sched.c 内) を通じて参照されます。赤黒ツリーの葉には情報が含まれていませんが、内部ノードは 1 つ以上の実行可能なタスクを表します。赤黒ツリーの各ノードは rb_node で表され、子参照と親オブジェクトの色のみが含まれます。 rb_node は sched_entity 構造内に含まれており、この構造には rb_node 参照、負荷重み、およびさまざまな統計が含まれています。最も重要なのは、sched_entity には vruntime (64 ビット フィールド) が含まれていることです。これはタスクの実行時間を表し、赤黒ツリーへのインデックスとして機能します。最後に、task_struct が一番上にあり、タスクを完全に説明しており、sched_entity 構造体が含まれています。
CFS 部分に関する限り、スケジューリング機能は非常に単純です。 ./kernel/sched.c には、現在実行中のタスクをプリエンプトする汎用 schedule() 関数があります (yield() コードによって自身をプリエンプトしない限り)。プリエンプション時間は可変であるため、CFS にはプリエンプションのタイム スライシングという実際の概念がないことに注意してください。現在実行中のタスク (現在プリエンプトされているタスク) は、put_prev_task (スケジューリング クラス経由) の呼び出しによって赤黒ツリーに返されます。 schedule 関数は、スケジュールする次のタスクの決定を開始すると、pick_next_task 関数を呼び出します。この関数も (./kernel/sched.c にある) 汎用関数ですが、スケジューラ クラスを通じて CFS スケジューラを呼び出します。 CFS の pick_next_task 関数は、./kernel/sched_fair.c にあります (pick_next_task_fair() と呼ばれます)。この関数は、単純に赤黒ツリーから一番左のタスクを取得し、関連する sched_entity を返します。この参照から、単純な task_of() 呼び出しによって、返される task_struct 参照が決定されます。ユニバーサル スケジューラは、最終的にこのタスク用のプロセッサを提供します。
————————————————————————————————————————
優先順位と CFS
CFS は優先順位を直接使用しませんが、タスクの実行が許可される時間の減衰係数として使用します。優先度の低いタスクの減衰係数は高くなりますが、優先度の高いタスクの減衰係数は低くなります。これは、タスクの実行に許可される時間が、優先度の高いタスクよりも優先度の低いタスクの方が速く消費されることを意味します。これは、優先順位でスケジュールされた実行キューの維持を回避するための優れたソリューションです。
CFS グループのスケジューリング
CFS のもう 1 つの興味深い側面は、グループ スケジューリングの概念 (2.6.24 カーネルで導入) です。グループ スケジューリングは、特に他の多くのタスクを生成するタスクを処理する場合に、スケジューリングに公平性をもたらすもう 1 つの方法です。多くのタスクを生成するサーバーが受信接続を並列化したいとします (HTTP サーバーの一般的なアーキテクチャ)。すべてのタスクが均一かつ公平に扱われるわけではないため、CFS ではこの動作を処理するグループを導入しています。タスクを生成するサーバー プロセスは、グループ全体 (階層内) で仮想ランタイムを共有しますが、個々のタスクは独自の独立した仮想ランタイムを維持します。このようにして、個々のタスクはグループとほぼ同じスケジュール時間を受け取ります。 /proc インターフェイスはプロセス階層の管理に使用されており、グループの形成方法を完全に制御できることがわかります。この構成を使用すると、ユーザー、プロセス、またはそれらのバリエーション全体に公平性を分散できます。
クラスとドメインのスケジューリング
CFS とともに導入されたのは、スケジューリング クラスの概念です (図 2 で確認できます)。各タスクは、タスクのスケジュール方法を決定するスケジューリング クラスに属します。スケジューリング クラスは、スケジューラの動作を定義する共通の関数セットを (sched_class 経由で) 定義します。たとえば、各スケジューラは、スケジュールするタスクを追加したり、次に実行するタスクを呼び出したり、それをスケジューラに提供したりする方法を提供します。各スケジューラ クラスは 1 対 1 の接続リストで相互に接続されており、クラスを反復できるようになります (たとえば、特定のプロセッサを無効にすることができます)。一般的な構造を図 3 に示します。タスク関数のエンキューまたはデキューは、特定のスケジュール構造に対してタスクを追加または削除するだけであることに注意してください。関数 pick_next_task 実行する次のタスクを選択します (スケジューリング クラスの特定の戦略に応じて)。
図 3. スケジュール グラフィック ビュー

ただし、スケジューリング クラスはタスク構造自体の一部であることを忘れないでください (図 2 を参照)。これにより、スケジューリング クラスに関係なく、タスクの操作が簡素化されます。たとえば、次の関数は、./kernel/sched.c 内の新しいタスクを使用して、現在実行中のタスクをプリエンプトします (curr は現在実行中のタスクを定義し、rq は CFS red を表します) -black ツリーと p はスケジュールされる次のタスクです):
このタスクが公平なスケジューリング クラスを使用している場合、check_preempt_curr() は check_preempt_wakeup() に解決されます。これらの関係は、./kernel/sched_rt.c、./kernel/sched_fair.c、および ./kernel/sched_idle.c で確認できます。
スケジューリング クラスは、スケジューリングが変更されるもう 1 つの興味深い場所ですが、スケジューリング ドメインが増加するにつれて、機能も増加します。これらのドメインを使用すると、負荷分散と分離の目的で 1 つ以上のプロセッサを階層的にグループ化できます。 1 つ以上のプロセッサは、スケジューリング ポリシーを共有したり (プロセッサ間の負荷分散を維持したり)、独立したスケジューリング ポリシーを実装して意図的にタスクを分離したりできます。
その他のスケジューラー
スケジューリングの研究を続けると、パフォーマンスとスケーラビリティの限界を押し上げる開発中のスケジューラが見つかります。 Con Kolivas は、Linux の経験にひるむことなく、BFS と略される別の Linux スケジューラを開発しました。このスケジューラは、NUMA システムやモバイル デバイスでのパフォーマンスが向上すると言われており、Android オペレーティング システムの派生バージョンとして導入されました。
この記事を通じて、CFS の基本を理解する必要があります。CFS は、Linux システムで最も高度で効率的なプロセス スケジューリング アルゴリズムの 1 つです。赤黒ツリーを使用して実行可能なプロセス キューを保存し、仮想プロセス キューを計算します。実行時間は次のとおりです。プロセスの公平性を測定するために使用され、ウェイクアップ プリエンプション機能を実装することで対話型プロセスの応答速度が向上し、プロセス スケジューリングの完全な公平性が実現されます。もちろん、CFS は完璧ではなく、アクティブ スリープ プロセスの過剰補償、リアルタイム プロセスの不十分なサポート、マルチコア プロセッサの十分な活用など、いくつかの潜在的な問題や制限があり、これらは解決する必要があります。将来のバージョンでは、改善と最適化を行います。つまり、CFS は Linux システムに不可欠なコンポーネントであり、徹底的に学習して習得する価値があります。
以上がLinux CFS: プロセスのスケジューリングで完全な公平性を実現する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7549
7549
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 CentosとUbuntuの違い
Apr 14, 2025 pm 09:09 PM
CentosとUbuntuの違い
Apr 14, 2025 pm 09:09 PM
Centosとubuntuの重要な違いは次のとおりです。起源(CentosはRed Hat、for Enterprises、UbuntuはDebianに由来します。個人用のDebianに由来します)、パッケージ管理(CentosはYumを使用し、安定性に焦点を当てます。チュートリアルとドキュメント)、使用(Centosはサーバーに偏っています。Ubuntuはサーバーやデスクトップに適しています)、その他の違いにはインストールのシンプルさが含まれます(Centos is Thin)
 Centosをインストールする方法
Apr 14, 2025 pm 09:03 PM
Centosをインストールする方法
Apr 14, 2025 pm 09:03 PM
Centosのインストール手順:ISO画像をダウンロードし、起動可能なメディアを燃やします。起動してインストールソースを選択します。言語とキーボードのレイアウトを選択します。ネットワークを構成します。ハードディスクをパーティション化します。システムクロックを設定します。ルートユーザーを作成します。ソフトウェアパッケージを選択します。インストールを開始します。インストールが完了した後、ハードディスクから再起動して起動します。
 メンテナンスを停止した後のCentosの選択
Apr 14, 2025 pm 08:51 PM
メンテナンスを停止した後のCentosの選択
Apr 14, 2025 pm 08:51 PM
Centosは廃止されました、代替品には次のものが含まれます。1。RockyLinux(最高の互換性)。 2。アルマリン(Centosと互換性); 3。Ubuntuサーバー(設定が必要); 4。RedHat Enterprise Linux(コマーシャルバージョン、有料ライセンス); 5。OracleLinux(CentosとRhelと互換性があります)。移行する場合、考慮事項は次のとおりです。互換性、可用性、サポート、コスト、およびコミュニティサポート。
 Dockerデスクトップの使用方法
Apr 15, 2025 am 11:45 AM
Dockerデスクトップの使用方法
Apr 15, 2025 am 11:45 AM
Dockerデスクトップの使用方法は? Dockerデスクトップは、ローカルマシンでDockerコンテナを実行するためのツールです。使用する手順には次のものがあります。1。Dockerデスクトップをインストールします。 2。Dockerデスクトップを開始します。 3。Docker Imageを作成します(DockerFileを使用); 4. Docker画像をビルド(Docker Buildを使用); 5。Dockerコンテナを実行します(Docker Runを使用)。
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosがメンテナンスを停止した後の対処方法
Apr 14, 2025 pm 08:48 PM
Centosがメンテナンスを停止した後の対処方法
Apr 14, 2025 pm 08:48 PM
CentOSが停止した後、ユーザーは次の手段を採用して対処できます。Almalinux、Rocky Linux、Centosストリームなどの互換性のある分布を選択します。商業分布に移行する:Red Hat Enterprise Linux、Oracle Linuxなど。 Centos 9ストリームへのアップグレード:ローリングディストリビューション、最新のテクノロジーを提供します。 Ubuntu、Debianなど、他のLinuxディストリビューションを選択します。コンテナ、仮想マシン、クラウドプラットフォームなどの他のオプションを評価します。
 VSCODEに必要なコンピューター構成
Apr 15, 2025 pm 09:48 PM
VSCODEに必要なコンピューター構成
Apr 15, 2025 pm 09:48 PM
VSコードシステムの要件:オペレーティングシステム:オペレーティングシステム:Windows 10以降、MACOS 10.12以上、Linux Distributionプロセッサ:最小1.6 GHz、推奨2.0 GHz以上のメモリ:最小512 MB、推奨4 GB以上のストレージスペース:最低250 MB以上:その他の要件を推奨:安定ネットワーク接続、XORG/WAYLAND(Linux)
 Dockerはどのような根本的なテクノロジーを使用していますか?
Apr 15, 2025 am 07:09 AM
Dockerはどのような根本的なテクノロジーを使用していますか?
Apr 15, 2025 am 07:09 AM
Dockerは、コンテナエンジン、ミラー形式、ストレージドライバー、ネットワークモデル、コンテナオーケストールツール、オペレーティングシステム仮想化、コンテナレジストリを使用して、コンテナ化機能をサポートし、軽量でポータブルで自動化されたアプリケーションの展開と管理を提供します。
