

Linux メモリ モデル: メモリ管理のより深い理解

Linux システムでさまざまなメモリの問題に遭遇したことがありますか?メモリリーク、メモリの断片化など。これらの問題は、Linux メモリ モデルを深く理解することで解決できます。
######I.はじめに######Linux カーネルは、フラット メモリ モデル、不連続メモリ モデル、スパース メモリ モデルという 3 つのメモリ モデルをサポートします。いわゆるメモリ モデルは、実際には、CPU の観点から見た物理メモリの分布と、Linux カーネルでこれらの物理メモリを管理するために使用される方法を指します。さらに、この記事は主に共有メモリ システムに焦点を当てていることに注意してください。これは、すべての CPU が物理アドレス空間を共有することを意味します。 この記事の内容は次のように構成されています: メモリ モデルを明確に分析するために、第 2 章でいくつかの基本用語について説明します。 3 番目の章では、3 つのメモリ モデルの動作原理について説明します。最後の章はコード分析です。コードは 4.4.6 カーネルからのものです。アーキテクチャ関連のコードについては、分析に ARM64 を使用します。
2. メモリモデルに関する用語1. ページフレームとは何ですか? オペレーティング システムの最も重要な機能の 1 つは、コンピュータ システム内のさまざまなリソースを管理することであり、最も重要なリソースであるメモリを管理する必要があります。 Linux オペレーティング システムでは、物理メモリはページ サイズに従って管理されます。特定のページ サイズは、ハードウェアおよび Linux システム構成に関連します。4K が最も古典的な設定です。そこで、物理メモリをページサイズごとにページに分割し、各物理メモリ内のページサイズのメモリ領域をページフレームと呼びます。各物理ページ フレームの構造体ページ データ構造を確立して、各物理ページの使用状況を追跡します。カーネルのテキスト セグメントに使用されているか?それともプロセスのページテーブルでしょうか?さまざまなファイル キャッシュに使用されていますか、それとも無料の状態ですか...
各ページ フレームには、1 対 1 に対応するページ データ構造があります。システムは、ページ フレーム番号とページ データ構造の間で変換するために、page_to_pfn および pfn_to_page マクロを定義します。具体的な変換方法は、メモリ モジュールに関連します。説明します。 Linux カーネルの 3 つのメモリ モデルについては、第 3 章で詳しく説明します。
2.PFNとは何ですか?
コンピュータ システムの場合、その物理アドレス空間全体は、0 から始まり、実際のシステムがサポートできる最大物理空間で終わるアドレス空間である必要があります。 ARM システムでは、物理アドレスが 32 ビットであると仮定すると、物理アドレス空間は 4G となり、ARM64 システムでは、サポートされる物理アドレス ビット数が 48 である場合、物理アドレス空間は 256T になります。もちろん、実際には、このような大きな物理アドレス空間のすべてがメモリに使用されるわけではなく、一部は I/O 空間にも属します (もちろん、一部の CPU アーチには独自の独立した IO アドレス空間があります)。したがって、メモリが占有する物理アドレス空間は限られた範囲になるはずであり、物理アドレス空間全体をカバーすることは不可能である。しかし、メモリがますます大容量化している現在、32 ビット システムの場合、4G 物理アドレス空間ではメモリ要件を満たすことができなくなっているため、後で詳しく説明するハイ メモリという概念があります。
PFN はページ フレーム番号の略で、ページ フレームと呼ばれる物理メモリを指します。物理メモリはページ サイズの領域に分割され、各ページに番号が付けられます。この番号が PFN です。物理メモリがアドレス 0 から始まると仮定すると、PFN が 0 に等しいページ フレームは、アドレス 0 (物理アドレス) から始まるページになります。物理メモリがアドレス x から始まると仮定すると、最初のページ フレーム番号は (x>>PAGE_SHIFT) になります。
3. NUMA とは何ですか?
マルチプロセッサ システムのメモリ アーキテクチャを設計する場合、2 つのオプションがあります: 1 つは UMA (Uniform Memory Access) です。システム内のすべてのプロセッサは、どのプロセッサが開始したかに関係なく、統一された一貫した物理メモリ空間を共有します。アクセス時間はメモリアドレスまでは同じです。 NUMA (Non-Uniform Memory Access) は UMA とは異なり、特定のメモリ アドレスへのアクセスはメモリとプロセッサ間の相対位置に関係します。たとえば、ノード上のプロセッサの場合、ローカル メモリへのアクセスは、リモート メモリへのアクセスよりも時間がかかります。
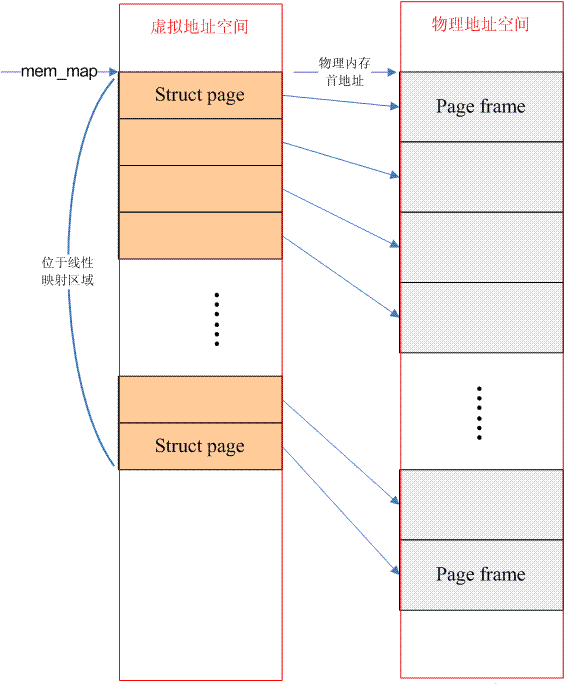
3. Linux カーネルの 3 つのメモリ モデル1. FLAT メモリ モデルとは何ですか? システム内のプロセッサの観点から、プロセッサが物理メモリにアクセスするとき、物理アドレス空間がホールのない連続したアドレス空間である場合、このコンピュータ システムのメモリ モデルはフラット メモリです。このメモリ モデルでは、物理メモリの管理は比較的単純です。各物理ページ フレームには、それを抽象化するためのページ データ構造があります。したがって、システムには構造体ページ (mem_map) の配列があり、各配列エントリは実際の物理ページ フレーム (ページ フレーム)。フラット メモリの場合、PFN (ページ フレーム番号) と mem_map 配列インデックスの関係は線形です (固定オフセットがあり、メモリに対応する物理アドレスが 0 に等しい場合、PFN は配列インデックスになります)。したがって、PFN から対応するページ データ構造への移動、またはその逆が非常に簡単です (詳細については、page_to_pfn および pfn_to_page の定義を参照してください)。さらに、フラット メモリ モデルの場合、(不連続メモリ モデルと同じメカニズムを使用するため) ノード (struct pglist_data) が 1 つだけあります。次の図は、フラット メモリの状況を示しています:

構造体ページによって占有されるメモリは直接マップされた間隔内にあるため、オペレーティング システムがそのためのページ テーブルを作成する必要がないことを強調しておく必要があります。
2. 不連続メモリモデルとは何ですか?
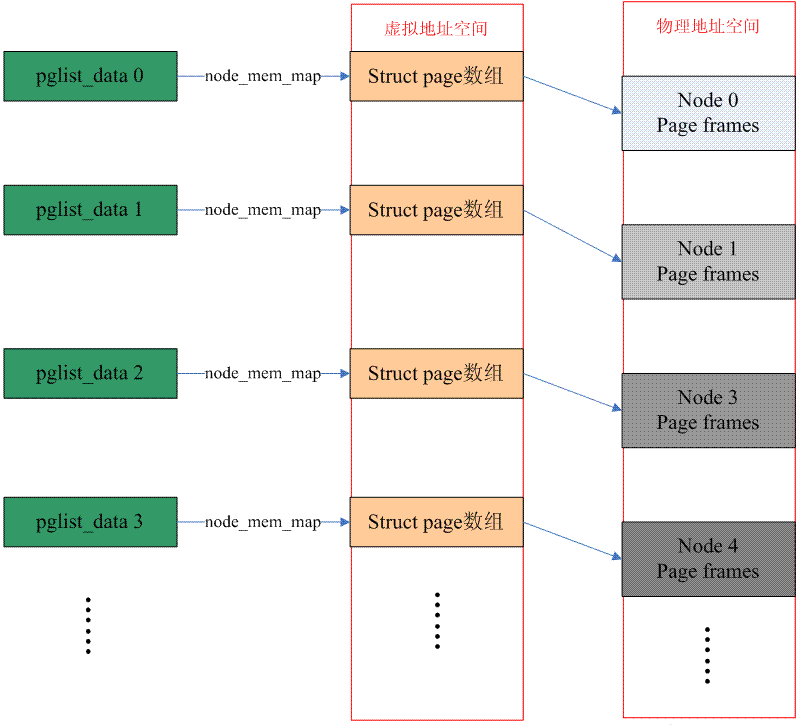
CPU のアドレス空間にいくつかの穴があり、物理メモリにアクセスするときに不連続である場合、このコンピュータ システムのメモリ モデルは不連続メモリです。一般に、NUMA ベースのコンピュータ システムのメモリ モデルは不連続メモリですが、実際には 2 つの概念は異なります。 NUMAはメモリとプロセッサの位置関係を重視しており、メモリモデルとは関係ありませんが、同一ノード上のメモリとプロセッサはより密接な結合関係(高速アクセス)となるため、それを管理するには複数のノードが必要になります。不連続メモリは本質的にフラット メモリ メモリ モデルの拡張です。物理メモリ全体のアドレス空間のほとんどは、中央にいくつかの穴がある大きなメモリ部分です。メモリ アドレス空間の各部分はノードに属します (ノードの場合)。内部的には、ノードのメモリ モデルはフラット メモリです)。次の図は、不連続メモリの状況を示しています:
したがって、このメモリ モデルでは複数のノード データ (struct pglist_data) が存在し、マクロ定義 NODE_DATA は指定されたノードの struct pglist_data を取得できます。ただし、各ノードによって管理される物理メモリは、struct pglist_data データ構造の node_mem_map メンバーに格納されます (概念はフラット メモリの mem_map に似ています)。現時点では、PFN から特定の構造体ページへの変換は少し複雑になります。最初に PFN からノード ID を取得し、次にこの ID に基づいて対応する pglist_data データ構造を見つけ、次に対応するページ配列を見つける必要があります。以降の方法は同様のフラットメモリです。
3. スパース メモリ モデルとは何ですか?
メモリ モデルも進化の過程です。当初はフラット メモリが連続的なメモリ アドレス空間 (mem_maps[]) を抽象化するために使用されていました。NUMA の登場後、不連続なメモリ空間全体がいくつかのノードに分割され、それぞれがノードになります。ノード上の連続したメモリ アドレス空間、つまり、元の単一の mem_maps[] が複数の mem_maps[] になりました。すべてが完璧に見えますが、メモリ ホットプラグの出現により、ノード内の mem_maps[] でさえ不連続になる可能性があるため、元の完璧な設計は不完全になります。実際、スパース メモリの出現後、不連続メモリのメモリ モデルはそれほど重要ではなくなりました。スパース メモリが最終的に不連続メモリに取って代わることは当然です。この置換プロセスは現在進行中です。4.4 カーネルにはまだ 3 つのメモリ モデルがあります。から選ぶ。
疎メモリが最終的に不連続メモリに取って代わる可能性があると言われているのはなぜですか?実際、スパースメモリのメモリモデルでは、連続したアドレス空間をセクション(1Gなど)ごとに分割し、各セクションごとにホットプラグするため、スパースメモリではメモリアドレス空間をさらに細かく分割することができます。セクション。 、より多くの離散的不連続メモリをサポートします。さらに、スパース メモリが登場する前は、NUMA と不連続メモリは常に混乱する関係にありました。NUMA はメモリの連続性を規定しておらず、不連続メモリ システムは必ずしも NUMA システムではありませんでしたが、これら 2 つの構成はすべてマルチです。ノード。スパース メモリを使用すると、メモリの連続性の概念を NUMA から最終的に切り離すことができます。つまり、NUMA システムはフラット メモリまたはスパース メモリにすることができ、スパース メモリ システムは NUMA または UMA にすることができます。
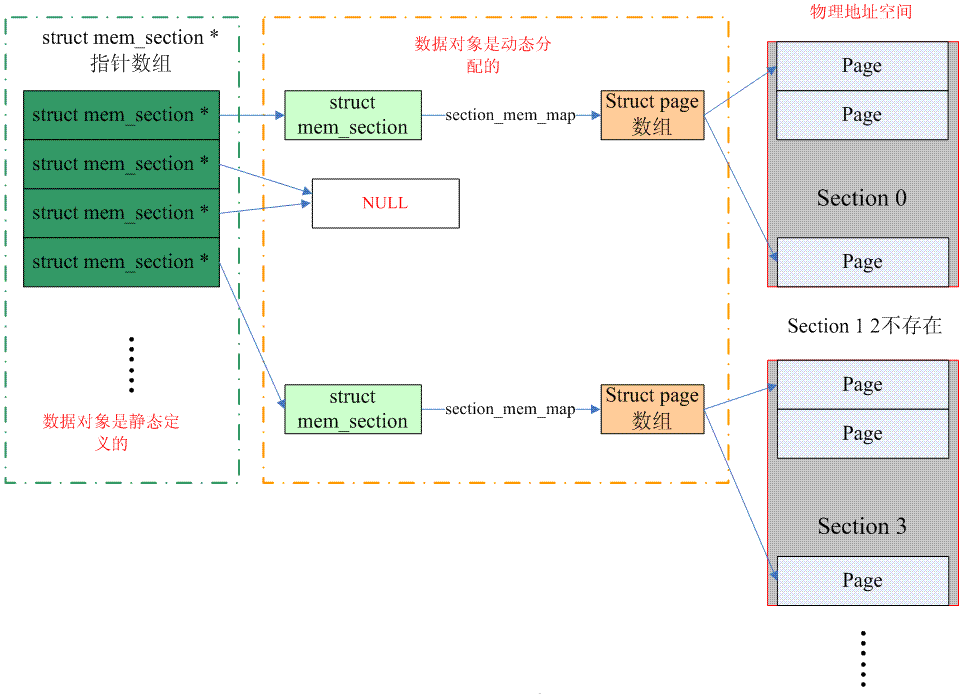
次の図は、スパース メモリがページ フレームを管理する方法を示しています (SPARSEMEM_EXTREME が構成されています)。
(注: 上の図の mem_section ポインターはページを指す必要があり、ページにはいくつかの struct mem_section データ ユニットがあります)
連続した物理アドレス空間全体がセクションごとに切り取られ、各セクション内ではメモリが連続している(フラットメモリの性質に準拠している)ため、セクションにmem_mapのページ配列が付加されます。ノード構造体 (struct pglist_data) の代わりに構造体 (struct mem_section) を使用します。もちろん、どのメモリモデルを使用する場合でも、PFNとページの対応付けは処理する必要がありますが、スパースメモリではセクションという概念が追加され、PFNSectionpageに変換されます。
まず、PFN からページ構造に変換する方法を見てみましょう: mem_section ポインター配列はカーネルで静的に定義されています。セクションには複数のページが含まれることがよくあるため、右シフトによって PFN をセクション番号に変換する必要があります。セクション番号は、PFN に対応するセクション データ構造を見つけるために、mem_section ポインター配列内のインデックスとして使用されます。セクションを見つけたら、section_mem_map に沿って対応するページ データ構造を見つけることができます。ちなみに、当初スパースメモリはポインタ配列ではなく一次元のmemory_section配列を使用していましたが、特にスパース(CONFIG_SPARSEMEM_EXTREME)なシステムではこの実装はメモリを非常に無駄に消費します。また、ホットプラグ対応のためにポインタを保存しておくと便利ですポインタが NULL の場合、セクションが存在しないことを意味します。上の図は、1 次元の mem_section ポインター配列 (SPARSEMEM_EXTREME が構成されている) の状況を示しています。SPARSEMEM_EXTREME 以外の構成でも、概念は同様です。特定の操作のコードを読み取ることができます。
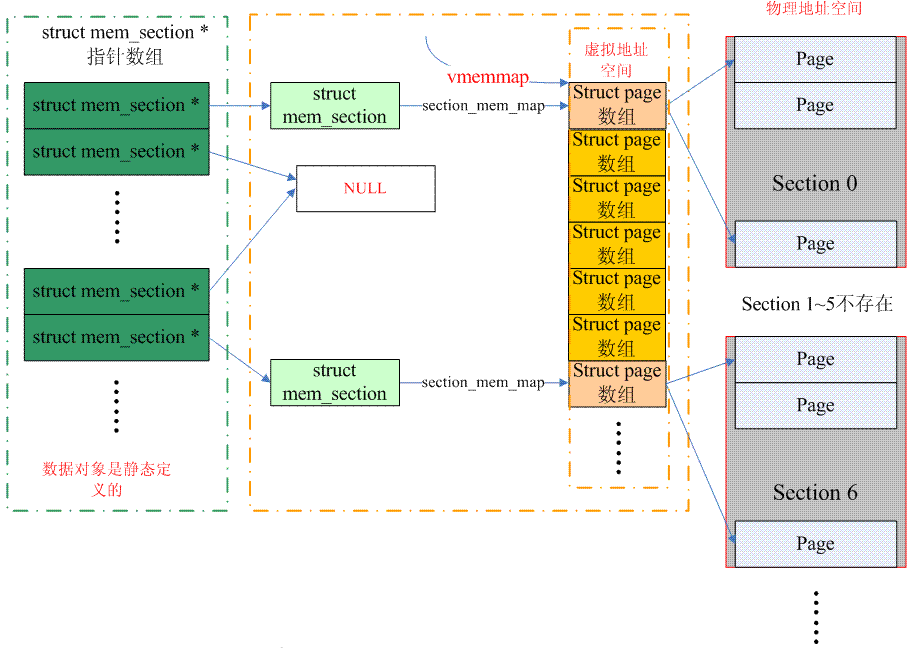
ページから PFN に移動するのは少し面倒ですが、実は PFN は 2 つの部分に分かれており、1 つはセクションのインデックス、もう 1 つはセクション内のページのオフセットです。まずページからセクション インデックスを取得し、次に対応するメモリ セクションを取得する必要があります。メモリ セクションがわかっているということは、ページがセクションメム マップ内にあることを意味し、セクション内のページのオフセットもわかっています。最後に、PFN を合成できます。 。ページをセクション インデックスに変換するには、スパース メモリには 2 つの解決策があります。最初に、page->flags に保存される (SECTION_IN_PAGE_FLAGS が設定されている) 従来の解決策を見てみましょう。この方法の最大の問題は、このフラグには情報が多すぎるため、ページ->フラグのビット数が必ずしも十分ではないことです。さまざまなページ フラグ、ノード ID、ゾーン ID にセクション ID が追加されるようになりました。達成できないアルゴリズム異なるアーキテクチャでの一貫性 普遍的なアルゴリズムはありますか?これは CONFIG_SPARSEMEM_VMEMMAP です。特定のアルゴリズムについては、次の図を参照してください:
(上の図には問題があります。PHYS_OFFSET が 0 に等しい場合、vmemmap は最初の構造体ページ配列のみを指します。一般的に言えば、オフセットがあるはずですが、私はそれを変更するのが面倒です。笑)
古典的なスパース メモリ モデルの場合、セクションの構造体ページ配列によって占有されるメモリは、直接マップされた領域から取得されます。ページ テーブルは初期化中に確立され、ページ フレームが割り当てられます。つまり、仮想アドレスが割り当てられます。ただし、SPARSEMEM_VMEMMAPの場合は最初から仮想アドレスが割り当てられており、vmemmapから始まる連続した仮想アドレス空間であり、各ページには対応する構造体ページがあり、当然仮想アドレスのみで物理アドレスは存在しません。したがって、セクションが発見されると、対応する構造体ページの仮想アドレスがすぐにわかります。もちろん、物理ページフレームを割り当ててからページテーブルを構築する必要もあります。したがって、この種のスパースメモリの場合、オーバーヘッドはわずかに大きくなります (マッピングを確立するもう 1 つのプロセス)。
4. コード分析
コード分析は主に include/asm-generic/memory_model.h を通じて実行されます。
1. フラットメモリ。コードは以下のように表示されます:
#「」
リーリー
」
# コードからわかるように、PFN と構造体ページ配列 (mem_map) インデックスは線形関係にあり、ARCH_PFN_OFFSET と呼ばれる固定オフセットがあり、このオフセットは推定されたアーキテクチャに関連しています。 ARM64 の場合は、arch/arm/include/asm/memory.h ファイルで定義されますが、当然、この定義はメモリが占有する物理アドレス空間に関係します (つまり、PHYS_OFFSET の定義に関係します)。
2. 不連続メモリモデル。コードは以下のように表示されます:
“
\#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
unsigned long __nid = arch_pfn_to_nid(__pfn); \
NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\
})
\#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \
(unsigned long)(__pg - __pgdat->node_mem_map) + \
__pgdat->node_start_pfn; \
})
ログイン後にコピー
”
Discontiguous Memory Model需要获取node id,只要找到node id,一切都好办了,比对flat memory model进行就OK了。因此对于__pfn_to_page的定义,可以首先通过arch_pfn_to_nid将PFN转换成node id,通过NODE_DATA宏定义可以找到该node对应的pglist_data数据结构,该数据结构的node_start_pfn记录了该node的第一个page frame number,因此,也就可以得到其对应struct page在node_mem_map的偏移。__page_to_pfn类似,大家可以自己分析。
3、Sparse Memory Model。经典算法的代码我们就不看了,一起看看配置了SPARSEMEM_VMEMMAP的代码,如下:
“
\#define __pfn_to_page(pfn) (vmemmap + (pfn))
\#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)
ログイン後にコピー
”
简单而清晰,PFN就是vmemmap这个struct page数组的index啊。对于ARM64而言,vmemmap定义如下:
“
\#define vmemmap ((struct page *)VMEMMAP_START - \
SECTION_ALIGN_DOWN(memstart_addr >> PAGE_SHIFT))
ログイン後にコピー
”
毫无疑问,我们需要在虚拟地址空间中分配一段地址来安放struct page数组(该数组包含了所有物理内存跨度空间page),也就是VMEMMAP_START的定义。
总之,Linux内存模型是一个非常重要的概念,可以帮助你更好地理解Linux系统中的内存管理。如果你想了解更多关于这个概念的信息,可以查看本文提供的参考资料。
 (注: 上の図の mem_section ポインターはページを指す必要があり、ページにはいくつかの struct mem_section データ ユニットがあります)
(注: 上の図の mem_section ポインターはページを指す必要があり、ページにはいくつかの struct mem_section データ ユニットがあります)
#「」 リーリー
」
# コードからわかるように、PFN と構造体ページ配列 (mem_map) インデックスは線形関係にあり、ARCH_PFN_OFFSET と呼ばれる固定オフセットがあり、このオフセットは推定されたアーキテクチャに関連しています。 ARM64 の場合は、arch/arm/include/asm/memory.h ファイルで定義されますが、当然、この定義はメモリが占有する物理アドレス空間に関係します (つまり、PHYS_OFFSET の定義に関係します)。“
\#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
unsigned long __nid = arch_pfn_to_nid(__pfn); \
NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\
})
\#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \
(unsigned long)(__pg - __pgdat->node_mem_map) + \
__pgdat->node_start_pfn; \
})
”
“
\#define __pfn_to_page(pfn) (vmemmap + (pfn)) \#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)
”
“
\#define vmemmap ((struct page *)VMEMMAP_START - \ SECTION_ALIGN_DOWN(memstart_addr >> PAGE_SHIFT))
”
以上がLinux メモリ モデル: メモリ管理のより深い理解の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7699
7699
 15
1640
14
1393
52
1287
25
1230
29
15
1640
14
1393
52
1287
25
1230
29

 VSCODEに必要なコンピューター構成
Apr 15, 2025 pm 09:48 PM
VSCODEに必要なコンピューター構成
Apr 15, 2025 pm 09:48 PM
VSコードシステムの要件:オペレーティングシステム:オペレーティングシステム:Windows 10以降、MACOS 10.12以上、Linux Distributionプロセッサ:最小1.6 GHz、推奨2.0 GHz以上のメモリ:最小512 MB、推奨4 GB以上のストレージスペース:最低250 MB以上:その他の要件を推奨:安定ネットワーク接続、XORG/WAYLAND(Linux)
 VSCODEは拡張子をインストールできません
Apr 15, 2025 pm 07:18 PM
VSCODEは拡張子をインストールできません
Apr 15, 2025 pm 07:18 PM
VSコード拡張機能のインストールの理由は、ネットワークの不安定性、許可不足、システム互換性の問題、VSコードバージョンが古すぎる、ウイルス対策ソフトウェアまたはファイアウォール干渉です。ネットワーク接続、許可、ログファイル、およびコードの更新、セキュリティソフトウェアの無効化、およびコードまたはコンピューターの再起動を確認することにより、問題を徐々にトラブルシューティングと解決できます。
 Apr 16, 2025 pm 07:39 PM
Apr 16, 2025 pm 07:39 PM
NotePadはJavaコードを直接実行することはできませんが、他のツールを使用することで実現できます。コマンドラインコンパイラ(Javac)を使用してByteCodeファイル(filename.class)を生成します。 Javaインタープリター(Java)を使用して、バイトコードを解釈し、コードを実行し、結果を出力します。
 vscodeとは何ですか?vscodeとは何ですか?
Apr 15, 2025 pm 06:45 PM
vscodeとは何ですか?vscodeとは何ですか?
Apr 15, 2025 pm 06:45 PM
VSコードは、Microsoftが開発した無料のオープンソースクロスプラットフォームコードエディターと開発環境であるフルネームVisual Studioコードです。幅広いプログラミング言語をサポートし、構文の強調表示、コード自動完了、コードスニペット、および開発効率を向上させるスマートプロンプトを提供します。リッチな拡張エコシステムを通じて、ユーザーは、デバッガー、コードフォーマットツール、GIT統合など、特定のニーズや言語に拡張機能を追加できます。 VSコードには、コードのバグをすばやく見つけて解決するのに役立つ直感的なデバッガーも含まれています。
 vscodeはMacに使用できますか
Apr 15, 2025 pm 07:36 PM
vscodeはMacに使用できますか
Apr 15, 2025 pm 07:36 PM
VSコードはMacで利用できます。強力な拡張機能、GIT統合、ターミナル、デバッガーがあり、豊富なセットアップオプションも提供しています。ただし、特に大規模なプロジェクトまたは非常に専門的な開発の場合、コードと機能的な制限がある場合があります。
 vscodeの使用方法
Apr 15, 2025 pm 11:21 PM
vscodeの使用方法
Apr 15, 2025 pm 11:21 PM
Visual Studio Code(VSCODE)は、Microsoftが開発したクロスプラットフォーム、オープンソース、および無料のコードエディターです。軽量、スケーラビリティ、および幅広いプログラミング言語のサポートで知られています。 VSCODEをインストールするには、公式Webサイトにアクセスして、インストーラーをダウンロードして実行してください。 VSCODEを使用する場合、新しいプロジェクトを作成し、コードを編集し、コードをデバッグし、プロジェクトをナビゲートし、VSCODEを展開し、設定を管理できます。 VSCODEは、Windows、MacOS、Linuxで利用でき、複数のプログラミング言語をサポートし、マーケットプレイスを通じてさまざまな拡張機能を提供します。その利点には、軽量、スケーラビリティ、広範な言語サポート、豊富な機能とバージョンが含まれます
 Linuxの主な目的は何ですか?
Apr 16, 2025 am 12:19 AM
Linuxの主な目的は何ですか?
Apr 16, 2025 am 12:19 AM
Linuxの主な用途には、1。Serverオペレーティングシステム、2。EmbeddedSystem、3。Desktopオペレーティングシステム、4。開発およびテスト環境。 Linuxはこれらの分野で優れており、安定性、セキュリティ、効率的な開発ツールを提供します。
 GITの倉庫アドレスを確認する方法
Apr 17, 2025 pm 01:54 PM
GITの倉庫アドレスを確認する方法
Apr 17, 2025 pm 01:54 PM
gitリポジトリアドレスを表示するには、次の手順を実行します。1。コマンドラインを開き、リポジトリディレクトリに移動します。 2。「git remote -v」コマンドを実行します。 3.出力と対応するアドレスでリポジトリ名を表示します。
