

オペレーティング システムはすべてのプログラムの基盤として、アプリケーションのパフォーマンスに重要な影響を与えます。ただし、コンピュータのさまざまなコンポーネント間の速度の差は非常に大きくなります。たとえば、CPU とハードドライブの速度差は、ウサギとカメの速度差よりも大きくなります。
以下では、CPU、メモリ、I/O の基本を簡単に説明し、それらのパフォーマンスを評価するためのいくつかのコマンドを紹介します。
まず、コンピュータの最も重要なコンピューティング コンポーネントである中央処理装置について説明します。通常、top コマンドを通じてパフォーマンスを観察できます。
top コマンドを使用すると、CPU のいくつかの動作インジケーターを観察できます。図に示すように、top コマンドを入力した後、1 キーを押すと、各コア CPU の詳細なステータスが表示されます。
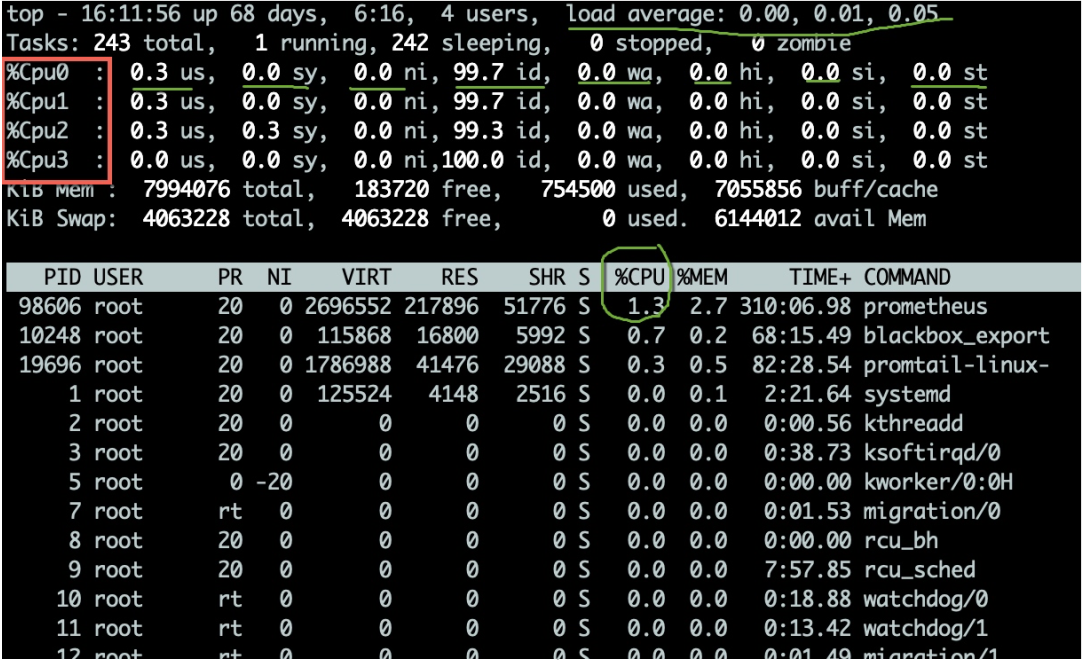
CPU 使用率には複数の指標があり、以下で説明します。
一般に、アイドル状態の CPU の割合により注目します。これは、全体的な CPU 使用率を反映している可能性があります。
CPU タスク実行のキューイング状況も評価する必要があります。これらの値は load(load) です。 topコマンドで表示されるCPU負荷はそれぞれ過去1分、5分、15分の値です。
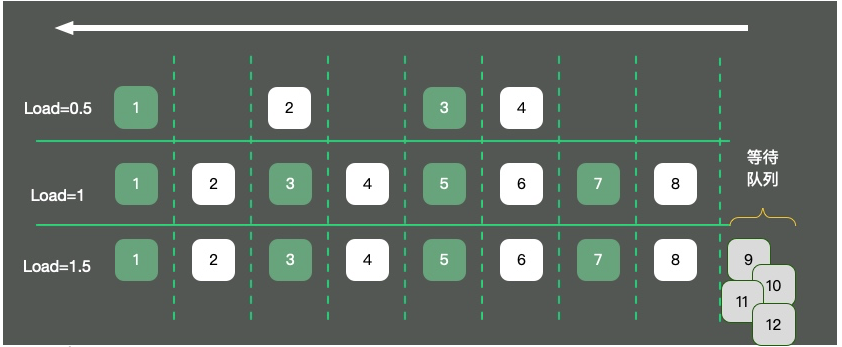
図に示すように、シングルコア オペレーティング システムを例にとると、CPU リソースは一方通行に抽象化されます。 3 つの状況が発生します:
4 台の車しかなく、交通はスムーズに流れており、負荷は約 0.5 です。 ロード 1 とはどういう意味ですか?この問題に関してはまだ多くの誤解があります。
多くの学生は、負荷が 1 に達するとシステムがボトルネックに達すると信じていますが、これは完全に正しいわけではありません。負荷の値は CPU コアの数と密接に関係しています。例は次のとおりです。
つまり、10 まで負荷がかかっているが 16 コアを備えているマシンの場合、システムは負荷制限に達するには程遠いということになります。 uptime コマンドを使用すると、負荷ステータスも確認できます。
CPU のビジー状態を確認するには、vmstat コマンドを使用することもできます。以下は、vmstat コマンドからの出力情報の一部です。
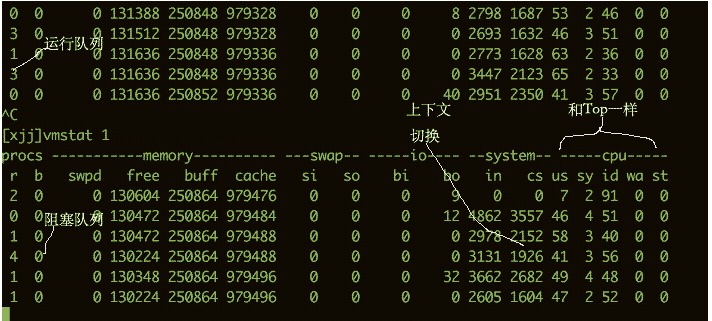
私たちは次の列にもっと関心があります:
b I/O 待ちなどの待機キューに存在するカーネル スレッドの数。数値が大きすぎると、CPU がビジー状態になります。 cs はコンテキストスイッチの数を表します。コンテキストスイッチが頻繁に行われる場合は、スレッド数が多すぎないかを考慮する必要があります。 si/so は、スワップ パーティションの使用法を示しています。スワップ パーティションはパフォーマンスに大きな影響を与えるため、特別な注意が必要です。 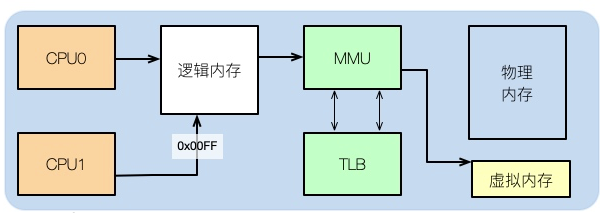
メモリがパフォーマンスに与える影響を理解したい場合は、オペレーティング システム レベルからメモリの分布を調べる必要があります。
通常、コードを書いた後、たとえば C プログラムを書いた場合、そのアセンブリを見ると、その中のメモリ アドレスが実際の物理メモリ アドレスではないことがわかります。
では、アプリケーションが使用するのは論理メモリです。これは、コンピュータの構造を勉強したことのある学生なら誰でも知っています。
論理アドレスは物理メモリと仮想メモリにマッピングできます。たとえば、物理メモリが 8 GB で、16 GB の SWAP パーティションが割り当てられている場合、アプリケーションで使用できる合計メモリは 24 GB になります。
先頭のコマンドから複数の列のデータが表示されます。四角で囲まれた 3 つの領域に注目してください。説明は次のとおりです。
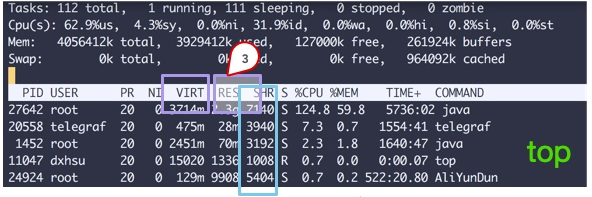
 Java の知識ポイントのほとんどはマルチスレッドに関するものですが、スレッドのタイム スライスが複数の CPU にまたがる場合、同期の問題が発生するためです。
Java の知識ポイントのほとんどはマルチスレッドに関するものですが、スレッドのタイム スライスが複数の CPU にまたがる場合、同期の問題が発生するためです。
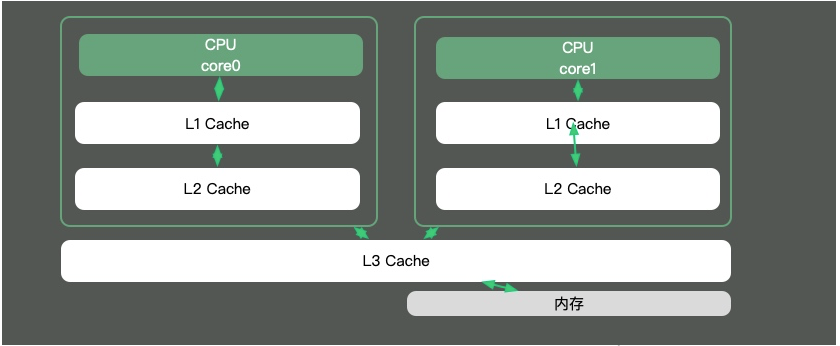
在Java中,最典型的和CPU缓存相关的知识点,就是并发编程中,针对Cache line的伪共享(false sharing)问题。
伪共享是指:在这些高速缓存中,是以缓存行为单位进行存储的。哪怕你修改了缓存行中一个很小很小的数据,它都会整个的刷新。所以,当多线程修改一些变量的值时,如果这些变量在同一个缓存行里,就会造成频繁刷新,无意中影响彼此的性能。
通过以下命令即可看到当前操作系统的缓存行大小。
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
通过以下命令可以看到不同层次的缓存大小。
[root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index1/size 32K [root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index2/size 256K [root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index3/size 20480K
在JDK8以上的版本,通过开启参数-XX:-RestrictContended,就可以使用注解@sun.misc.Contended进行补齐,来避免伪共享的问题。在并发优化中,我们再详细讲解。
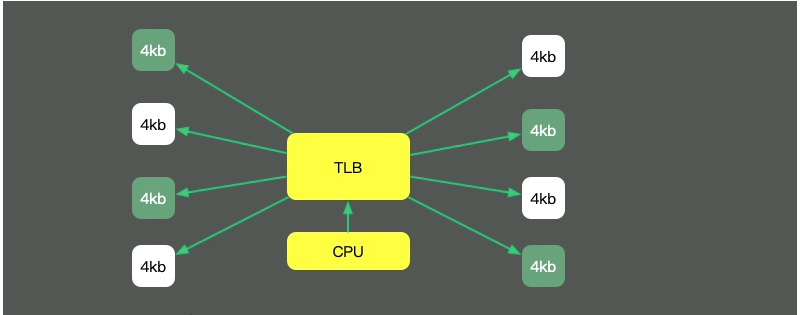
回头看我们最长的那副图,上面有一个叫做TLB的组件,它的速度虽然高,但容量也是有限的。这就意味着,如果物理内存很大,那么映射表的条目将会非常多,会影响CPU的检索效率。
默认内存是以4K的page来管理的。如图,为了减少映射表的条目,可采取的办法只有增加页的尺寸。像这种将Page Size加大的技术,就是Huge Page。
HugePage有一些副作用,比如竞争加剧,Redis还有专门的研究(https://redis.io/topics/latency) ,但在一些大内存的机器上,开启后会一定程度上增加性能。
另外,一些程序的默认行为,也会对性能有所影响。比如JVM的-XX:+AlwaysPreTouch参数。默认情况下,JVM虽然配置了Xmx、Xms等参数,但它的内存在真正用到时,才会分配。
但如果加上这个参数,JVM就会在启动的时候,把所有的内存预先分配。这样,启动时虽然慢了些,但运行时的性能会增加。
I/O设备可能是计算机里速度最差的组件了。它指的不仅仅是硬盘,还包括外围的所有设备。
硬盘有多慢呢?我们不去探究不同设备的实现细节,直接看它的写入速度(数据未经过严格测试,仅作参考)。
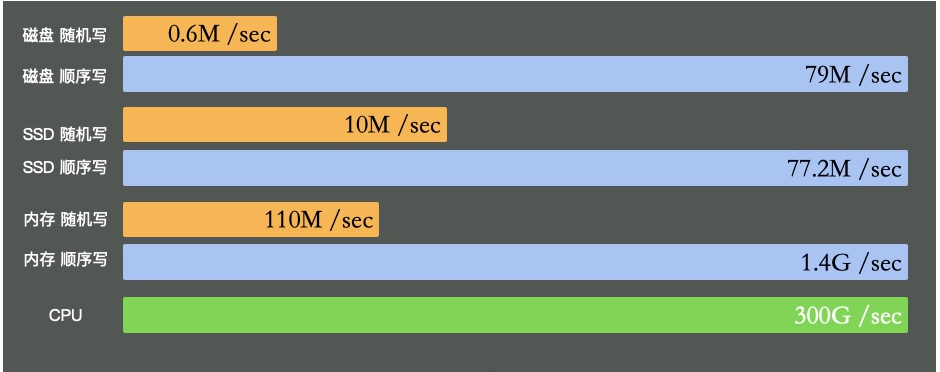
可以看到普通磁盘的随机写和顺序写相差是非常大的。而随机写完全和cpu内存不在一个数量级。
缓冲区依然是解决速度差异的唯一工具,在极端情况比如断电等,就产生了太多的不确定性。这些缓冲区,都容易丢。
I/O の混雑度を反映する最良の方法は、先頭のコマンドの wa% と vmstat コマンドです。アプリケーションが大量のログを書き込む場合、I/O 待機時間が非常に長くなる可能性があります。
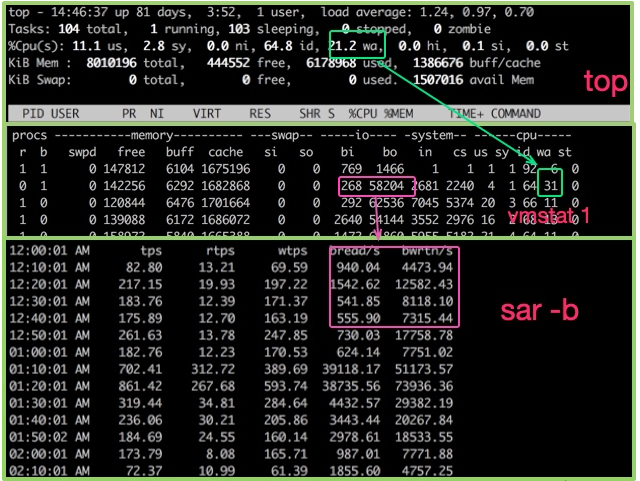
ハード ディスクの場合、iostat コマンドを使用して特定のハードウェアの使用状況を表示できます。 %util が 80% を超える限り、システムは基本的に実行できません。
詳細は次のとおりです:
svctm の値が await に非常に近い場合、待機中の I/O がほとんどなく、ディスクのパフォーマンスが非常に良好であることを意味します。 await の値が svctm よりも大幅に大きい場合は、I/O キューの待機時間が長すぎ、システム上で実行されているアプリケーションの速度が低下することを意味します。 両者の違いを見てみましょう:
ファイルの内容をソケット経由で送信するには、従来の方法では次の手順が必要です。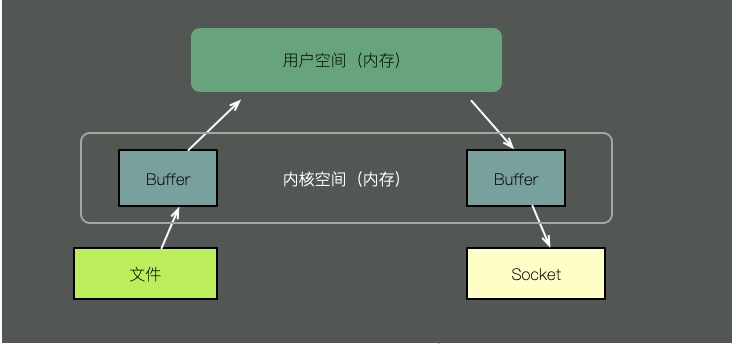
ファイルの内容をカーネル空間にコピーします。
除了iotop、iostat这些命令外,sar命令可以方便的看到网络运行状况,下面是一个简单的示例,用于描述入网流量和出网流量。
$ sar -n DEV 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00 12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00 12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00 12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00 12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 ^C
当然,我们可以选择性的只看TCP的一些状态。
$ sar -n TCP,ETCP 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 12:17:19 AM active/s passive/s iseg/s oseg/s 12:17:20 AM 1.00 0.00 10233.00 18846.00 12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:17:20 AM 0.00 0.00 0.00 0.00 0.00 12:17:20 AM active/s passive/s iseg/s oseg/s 12:17:21 AM 1.00 0.00 8359.00 6039.00 12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:17:21 AM 0.00 0.00 0.00 0.00 0.00 ^C
不要寄希望于这些指标,能够立刻帮助我们定位性能问题。这些工具,只能够帮我们大体猜测发生问题的地方,它对性能问题的定位,只是起到辅助作用。想要分析这些bottleneck,需要收集更多的信息。
想要获取更多的性能数据,就不得不借助更加专业的工具,比如基于eBPF的BCC工具,这些牛x的工具我们将在其他文章里展开。读完本文,希望你能够快速的了解Linux的运行状态,对你的系统多一些掌控。
以上がLinuxの健康状態が61秒でわかる!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



