

Linux カーネルの 4 つの主要な IO スケジューリング アルゴリズムを 1 つの記事で理解する

Linux カーネルには、Noop IO スケジューラ、Anticipatory IO スケジューラ、Deadline IO スケジューラ、CFQ IO スケジューラという 4 種類の IO スケジューラが含まれています。
通常、ディスクの読み取りおよび書き込みの遅延は、ディスク ヘッドのシリンダへの移動によって発生します。この遅延を解決するために、カーネルは主に、キャッシュ アルゴリズムと IO スケジューリング アルゴリズムという 2 つの戦略を採用します。
スケジューリング アルゴリズムの概念
- データのブロックがデバイスに書き込まれるか、デバイスから読み取られると、リクエストは完了を待つキューに入れられます。
- 各ブロックデバイスには独自のキューがあります。
- I/O スケジューラは、メディアをより効率的に利用するためにこれらのキューの順序を維持する責任があります。 I/O スケジューラは、順序付けされていない I/O 操作を順序付けされた I/O 操作に変換します。
- スケジュールを設定する前に、カーネルはまずキュー内にリクエストがいくつあるかを判断する必要があります。
IO スケジューラ
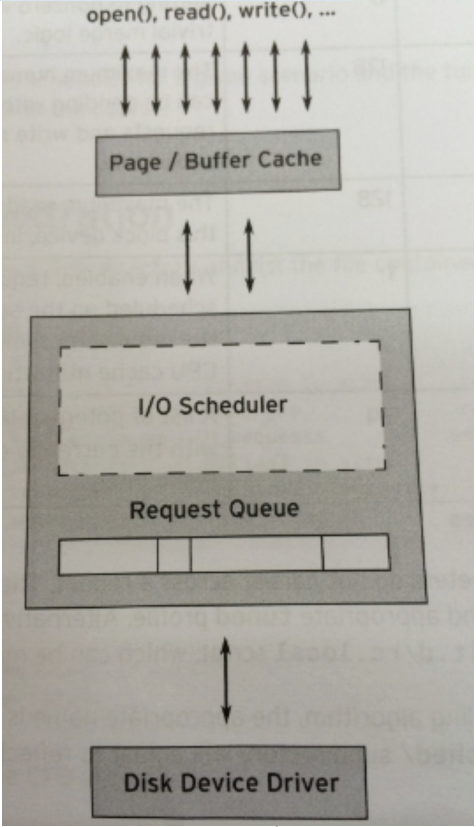
IO スケジューラ (IO スケジューラ) は、ブロック デバイス上で IO 操作が送信される順序を決定するためにオペレーティング システムによって使用される方法です。存在目的は 2 つあり、1 つは IO スループットの向上、もう 1 つは IO 応答時間の短縮です。
ただし、IO スループットと IO 応答時間は矛盾することがよくあります。この 2 つのバランスを可能な限り高めるために、IO スケジューラは、さまざまな IO 要求シナリオに適応するさまざまなスケジューリング アルゴリズムを提供します。その中で、データベースなどのランダムな読み取りおよび書き込みシナリオに最も有益なアルゴリズムは DEANLINE です。
カーネル スタック内の IO スケジューラの場所は次のとおりです:
ブロック デバイスに関して最も悲劇的なのは、非常に時間のかかるプロセスであるディスクのローテーションです。各ブロック デバイスまたはブロック デバイスのパーティションは、独自のリクエスト キュー (request_queue) に対応し、各リクエスト キューは、送信されたリクエストを調整する I/O スケジューラを選択できます。
I/O スケジューラの基本的な目的は、ブロック デバイス上の対応するセクタ番号に従ってリクエストを配置し、ヘッドの移動を減らし、効率を向上させることです。各デバイスのリクエスト キュー内のリクエストは順番に応答されます。
実際には、このキューに加えて、各スケジューラ自体も、送信されたリクエストを処理するために異なる数のキューを維持しており、キューの先頭にあるリクエストは、やがてリクエスト キューに移動されます。

IO スケジューラの機能は主に、ディスク回転の必要性を減らすことです。主に 2 つの方法で実現します:
- マージ###### 選別######
- 各デバイスには対応する独自のリクエスト キューがあり、すべてのリクエストは処理される前にリクエスト キューに置かれます。新しいリクエストが来たとき、このリクエストの位置が前のリクエストに隣接していることが判明した場合、そのリクエストを 1 つのリクエストにマージできます。 マージが見つからない場合は、ディスクの回転方向に従ってソートされます。通常、IO スケジューラの役割は、単一リクエストの処理時間にあまり影響を与えずにマージとソートを実行することです。
FIFO
-
noop とは何ですか? noop は入出力のスケジューリング アルゴリズムです。NOOP、No Operation. 何もせず、リクエストを 1 つずつ処理します。この方法は実際にはより簡単で効果的です。問題は、ディスクのシークが多すぎることであり、これは従来のディスクでは許容できないことです。ただし、SSD ディスクは回転する必要がないため、SSD ディスクの場合は問題ありません。
-
noop の別名は、エレベーター スケジュール アルゴリズムとも呼ばれます。
-
noop の原理とは何ですか?
入力リクエストと出力リクエストを FIFO キューに入れ、キュー内の入力リクエストと出力リクエストを順番に実行します。新しいリクエストが来たとき:
-
マージできる場合はマージしてください
-
マージできない場合は、並べ替えを試みます。キュー上のリクエストがすでに非常に古い場合、この新しいリクエストはキューに入ることができず、最後に配置することしかできません。それ以外の場合は、適切な位置に挿入します
-
マージできず、挿入に適した位置がない場合は、リクエスト キューの最後に配置されます。
-
該当シーン
4.1 入力リクエストと出力リクエストの順序を変更したくないシナリオの場合;
4.2 NAS ストレージ デバイスなど、入出力においてよりインテリジェントなスケジューリング アルゴリズムを備えたデバイス;
4.3 上位層アプリケーションの入力および出力リクエストは慎重に最適化されています;
4.4 SSDディスクなどの非回転ヘッドディスクデバイス
2. CFQ (完全に公平なキューイング、完全に公平なキューイング)
CFQ (Completely Fair Queuing) アルゴリズムは、その名前が示すように、完全に公平なアルゴリズムです。ブロック デバイスを使用する権利を競合するすべてのプロセスにリクエスト キューとタイム スライスを割り当てようとします。スケジューラによってプロセスに割り当てられたタイム スライス内で、プロセスはその読み取りおよび書き込みリクエストを基礎となるブロック デバイスに送信できます。 . プロセスのタイムスライスが消費されたとき 完了後、プロセスのリクエストキューは一時停止され、スケジューリングを待ちます。
各プロセスのタイム スライスと各プロセスのキューの長さは、プロセスの IO 優先度によって異なります。各プロセスには IO 優先度があり、CFQ スケジューラはそれを、いつ実行するかを決定するために考慮する要素の 1 つとして使用します。プロセスのリクエストキューはブロックデバイスの使用権を取得できます。
IO の優先順位は、高から低まで 3 つのカテゴリに分類できます。
RT(リアルタイム)
BE(ベストトライ)
IDLE(アイドル)
RT と BE はさらに 8 つのサブ優先度に分類できます。 ionice を通じて表示および変更できます。優先順位が高くなるほど、処理が早くなり、このプロセスに使用されるタイム スライスが増え、一度に処理できるリクエストの数が増えます。
実際、CFQ スケジューラの公平性はプロセスに対するものであり、プロセスには同期リクエスト (読み取りまたは同期書き込み) のみが存在し、それらはプロセス独自のリクエスト キューに入れられることはすでにわかっています。同じ優先度のリクエストは、どのプロセスからのものであっても、共通のキューに入れられ、合計 8 (RT) 8 (BE) 1 (IDLE) = 17 の非同期リクエスト キューがあります。
Linux 2.6.18 以降、CFQ がデフォルトの IO スケジューリング アルゴリズムとして使用されます。汎用サーバーの場合は、CFQ の方が適しています。使用する具体的なスケジューリング アルゴリズムは、特定のビジネス シナリオに基づく十分なベンチマークに基づいて選択される必要があり、他人の言葉だけで決定することはできません。
3、締切
DEADLINE は CFQ に基づいており、IO リクエストの枯渇という極端な状況を解決します。
CFQ 自体が持つ IO ソート キューに加えて、DEADLINE は読み取り IO と書き込み IO 用の FIFO キューをさらに提供します。
FIFO キューの読み取りの最大待ち時間は 500 ミリ秒、FIFO キューの書き込みの最大待ち時間は 5 秒です (もちろん、これらのパラメーターは手動で設定できます)。
FIFO キュー内の IO リクエストの優先度は CFQ キュー内の IO リクエストよりも高く、読み取り FIFO キューの優先度は書き込み FIFO キューの優先度よりも高くなります。優先度は次のように表現できます:
#デッドライン アルゴリズムは、特定の IO リクエストの最小遅延時間を保証します。この点を理解すると、DSS アプリケーションに非常に適していることがわかります。#「」
FIFO(読み取り) > FIFO(書き込み) > CFQ」
deadline は実際にはエレベーターの改善です:
\1. 長時間処理できないリクエストは避けてください。
\2. 読み取り操作と書き込み操作を別の方法で扱います。
deadline IO は 3 つのキューを維持します。最初のキューはエレベーターと同じで、物理的な位置に従って並べ替えようとします。 2 番目のキューと 3 番目のキューはどちらも時間によってソートされていますが、違いは、一方が読み取り操作であり、もう一方が書き込み操作であることです。
Deadline IO では、読み取りと書き込みが区別されます。これは、アプリケーションが読み取りリクエストを送信すると、通常はそこでブロックされ、結果が返されるまで待機すると設計者が考えているためです。通常、書き込みリクエストはメモリに書き込むアプリケーションのリクエストではなく、バックグラウンド プロセスによってディスクに書き戻されます。通常、アプリケーションは書き込みが完了するまで待機せずに続行します。したがって、読み取りリクエストは書き込みリクエストよりも優先される必要があります。
この設計では、各新しいリクエストは最初に最初のキューに配置されます。アルゴリズムはエレベーターのアルゴリズムと同じで、読み取りまたは書き込みキューの最後にも追加されます。このようにして、最初のキューのいくつかのリクエストを処理すると同時に、2 番目/3 番目のキューの最初のいくつかのリクエストが長時間待機していないかどうかを検出し、しきい値を超えている場合は処理されます。このしきい値は、読み取りリクエストの場合は 5 ミリ秒、書き込みリクエストの場合は 5 秒です。
個人的には、Oracle のオンライン ログ、mysql の binlog などのデータベース変更ログの記録には、この種のパーティションを使用しない方がよいと思います。このタイプの書き込みリクエストは通常 fsync を呼び出すためです。書き込みが完了できない場合、アプリケーションのパフォーマンスにも大きな影響を与えます。
4、予想的
CFQ と DEADLINE の焦点は、分散した IO リクエストを満たすことです。連続読み取りなどの連続 IO リクエストの場合、最適化は行われません。ランダム IO とシーケンシャル IO が混在するシナリオに対応するために、Linux は ANTICIPATORY スケジューリング アルゴリズムもサポートしています。 DEADLINE に基づいて、ANTICIPATORY は各読み取り IO に 6 ミリ秒の待機時間ウィンドウを設定します。 OS がこの 6ms 以内に隣接する場所から読み取り IO 要求を受信した場合、即座に応答できます。
######まとめ######
IO スケジューラ アルゴリズムの選択は、ハードウェアの特性とアプリケーション シナリオの両方に依存します。従来の SAS ディスクでは、CFQ、DEADLINE、および ANTICIPATORY はすべて適切な選択肢ですが、専用データベース サーバーの場合、DEADLINE のスループットと応答時間は良好に機能します。
ただし、SSD や Fusion IO などの新興ソリッド ステート ドライブでは、最も単純な NOOP が最適なアルゴリズムである可能性があります。他の 3 つのアルゴリズムの最適化はシーク時間の短縮に基づいており、ソリッド ステート ドライブにはいわゆるシーク時間、チャネル時間と IO 応答時間は非常に短いです。
以上がLinux カーネルの 4 つの主要な IO スケジューリング アルゴリズムを 1 つの記事で理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7526
7526
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 CentosとUbuntuの違い
Apr 14, 2025 pm 09:09 PM
CentosとUbuntuの違い
Apr 14, 2025 pm 09:09 PM
Centosとubuntuの重要な違いは次のとおりです。起源(CentosはRed Hat、for Enterprises、UbuntuはDebianに由来します。個人用のDebianに由来します)、パッケージ管理(CentosはYumを使用し、安定性に焦点を当てます。チュートリアルとドキュメント)、使用(Centosはサーバーに偏っています。Ubuntuはサーバーやデスクトップに適しています)、その他の違いにはインストールのシンプルさが含まれます(Centos is Thin)
 Centosはメンテナンスを停止します2024
Apr 14, 2025 pm 08:39 PM
Centosはメンテナンスを停止します2024
Apr 14, 2025 pm 08:39 PM
Centosは、上流の分布であるRhel 8が閉鎖されたため、2024年に閉鎖されます。このシャットダウンはCentos 8システムに影響を与え、更新を継続し続けることができません。ユーザーは移行を計画する必要があり、提案されたオプションには、Centos Stream、Almalinux、およびRocky Linuxが含まれ、システムを安全で安定させます。
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosをインストールする方法
Apr 14, 2025 pm 09:03 PM
Centosをインストールする方法
Apr 14, 2025 pm 09:03 PM
Centosのインストール手順:ISO画像をダウンロードし、起動可能なメディアを燃やします。起動してインストールソースを選択します。言語とキーボードのレイアウトを選択します。ネットワークを構成します。ハードディスクをパーティション化します。システムクロックを設定します。ルートユーザーを作成します。ソフトウェアパッケージを選択します。インストールを開始します。インストールが完了した後、ハードディスクから再起動して起動します。
 Dockerデスクトップの使用方法
Apr 15, 2025 am 11:45 AM
Dockerデスクトップの使用方法
Apr 15, 2025 am 11:45 AM
Dockerデスクトップの使用方法は? Dockerデスクトップは、ローカルマシンでDockerコンテナを実行するためのツールです。使用する手順には次のものがあります。1。Dockerデスクトップをインストールします。 2。Dockerデスクトップを開始します。 3。Docker Imageを作成します(DockerFileを使用); 4. Docker画像をビルド(Docker Buildを使用); 5。Dockerコンテナを実行します(Docker Runを使用)。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 セントスにハードディスクをマウントする方法
Apr 14, 2025 pm 08:15 PM
セントスにハードディスクをマウントする方法
Apr 14, 2025 pm 08:15 PM
CentOSハードディスクマウントは、次の手順に分割されます。ハードディスクデバイス名(/dev/sdx)を決定します。マウントポイントを作成します( /mnt /newdiskを使用することをお勧めします);マウントコマンド(Mount /dev /sdx1 /mnt /newdisk)を実行します。 /etc /fstabファイルを編集して、永続的なマウント構成を追加します。 Umountコマンドを使用して、デバイスをアンインストールして、プロセスがデバイスを使用しないことを確認します。
 Centosがメンテナンスを停止した後の対処方法
Apr 14, 2025 pm 08:48 PM
Centosがメンテナンスを停止した後の対処方法
Apr 14, 2025 pm 08:48 PM
CentOSが停止した後、ユーザーは次の手段を採用して対処できます。Almalinux、Rocky Linux、Centosストリームなどの互換性のある分布を選択します。商業分布に移行する:Red Hat Enterprise Linux、Oracle Linuxなど。 Centos 9ストリームへのアップグレード:ローリングディストリビューション、最新のテクノロジーを提供します。 Ubuntu、Debianなど、他のLinuxディストリビューションを選択します。コンテナ、仮想マシン、クラウドプラットフォームなどの他のオプションを評価します。
