

Linux では CPU 使用率はどのように計算されますか?

オンライン サーバー上でオンライン サービスの実行ステータスを観察する場合、ほとんどの人は最初に top コマンドを使用して、現在のシステムの全体的な CPU 使用率を確認することを好みます。たとえば、ランダムなマシンの場合、top コマンドによって表示される使用率情報は次のとおりです。

この出力結果は、控えめに言っても単純ですが、複雑になると理解するのが難しくなります。例えば:###
質問 1: トップによって出力される使用率情報はどのように計算されますか? それは正確ですか?
質問 2: ni 列は便利ですが、処理時の CPU オーバーヘッドを出力します。
質問 3: wa は io wait を表します。この期間中、CPU はビジーですか、それともアイドルですか?
今日は私たち自身の考えから始めます!
1. まず考えてみましょう
Linux の実装はさておき、次の要件がある場合、4 つのプロセスが実行されているクアッドコア サーバーが存在します。
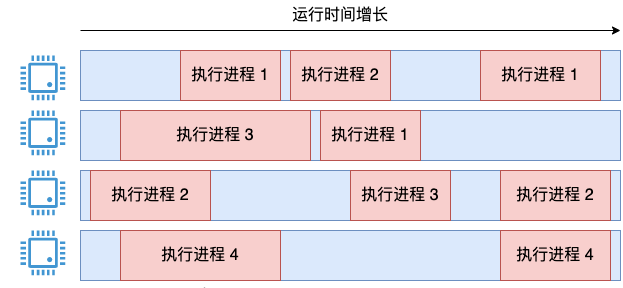 システム全体の CPU 使用率を設計および計算できます。top コマンドのような出力をサポートし、次の要件を満たします。
CPU 使用率はできるだけ正確である必要があります;
システム全体の CPU 使用率を設計および計算できます。top コマンドのような出力をサポートし、次の要件を満たします。
CPU 使用率はできるだけ正確である必要があります;- 瞬間的なCPUの状態を可能な限り第2レベルに反映する必要があります。
- 立ち止まって、数分間考えてみてはいかがでしょうか。

すべてのプロセスの実行時間を合計し、システムの合計実行時間 * 4 で割るのが 1 つのアイデアです。
この考え方には問題はなく、この方法を使用して長期間にわたる CPU 使用率をカウントすることが可能であり、統計は十分に正確です。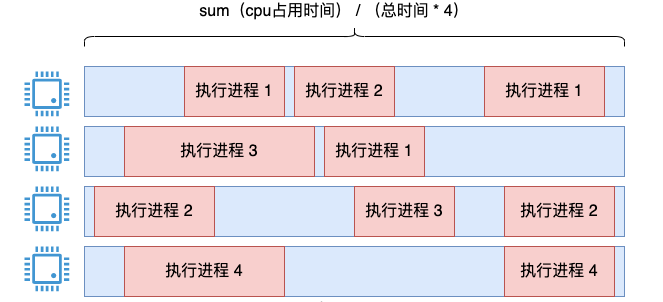
しかし、top を使用したことがある限り、top によって出力される CPU 使用率は長期間一定ではないことがわかりますが、デフォルトでは 3 秒単位で動的に更新されます (この時間間隔は次のコマンドを使用して設定できます) -d)。私たちのソリューションは全体的な使用率を反映できますが、この瞬間的な状態を反映することは困難です。 3秒に1回と数えられると思うかもしれませんね?しかし、この 3 秒間はどの時点から始まるのでしょうか。粒度の制御は困難です。
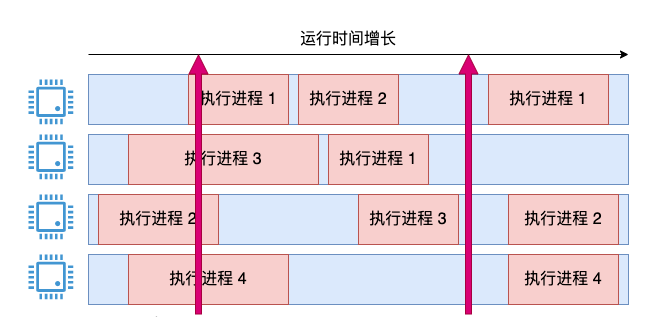
前の思考の問題の核心は、瞬間的な問題を解決する方法です。過渡状態に関しては、別の考えがあるかもしれません。次に、インスタント サンプリングを使用して、現在ビジー状態になっているコアの数を確認します。 4 つのコアのうち 2 つがビジー状態の場合、使用率は 50% になります。
この考え方も正しいですが、2 つの問題があります:
計算する数値はすべて 25% の倍数です;- この瞬間値により、CPU 使用率の表示が大きく変動する可能性があります。
- たとえば、次の図:
これを改善して上記 2 つのアイデアを組み合わせてみましょう。問題を解決できるかもしれません。サンプリングに関しては周期を細かく設定していますが、計算に関しては周期を粗く設定しています。
1 ミリ秒ごとのサンプリングなど、採用期間、タイミングの概念を導入します。サンプリング時に CPU が実行されている場合、この 1 ミリ秒は使用済みとして記録されます。このとき、瞬間的な CPU 使用率が取得され、保存されます。
上図の t1 と t2 の時間範囲など、3 秒以内の CPU 使用率をカウントする場合。次に、この期間中のすべての瞬間値を加算し、平均を取ります。これにより、上記の問題が解決され、統計は比較的正確になり、瞬間値が激しく振動したり粒度が粗すぎる(25% 単位でしか変更できない)という問題が回避されます。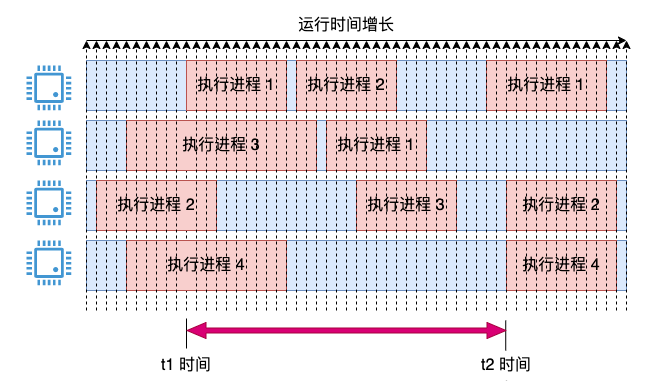
下の図に示すように、2 つのサンプリングの間に CPU が変化したらどうなるのかと尋ねる生徒もいるかもしれません。
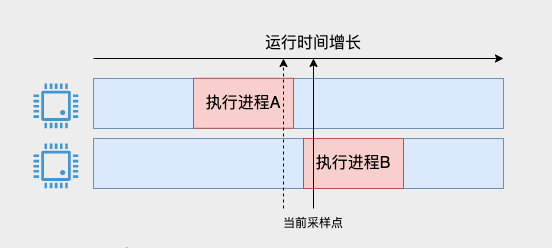
現在のサンプリング ポイントが到着すると、プロセス A は実行を終了したばかりで、しばらく前のサンプリング ポイントでカウントされておらず、今回もカウントできません。プロセス B については、実際に開始されたのは短時間であり、1 ミリ秒すべてを記録するには少し多すぎるように思えます。
この問題は確かに存在しますが、サンプリングは 1 ミリ秒に 1 回であるため、実際に確認して使用すると、少なくとも第 2 レベルにあり、これには数千のサンプリング ポイントからの情報が含まれるため、このエラーは発生します。全体的な状況の把握には影響しません。
実際、これは Linux がシステムの CPU 使用率をカウントする方法です。誤差はあるかもしれませんが、統計データとしては十分です。実装の観点から見ると、Linux は実際に瞬間データのコピーを多数保存するのではなく、すべての瞬間値を特定のデータに蓄積します。
次に、Linux に入って、システム CPU 使用率統計の具体的な実装を見てみましょう。
2. 先頭のコマンドで使用されるデータはどこですか
前節で述べた Linux の実装は、特定のデータに対する瞬間値を蓄積することであり、この値はカーネルによって /proc/stat 疑似ファイルを通じてユーザー モードに公開されます。 Linux は、システムの CPU 使用率を計算するときにこれを使用します。
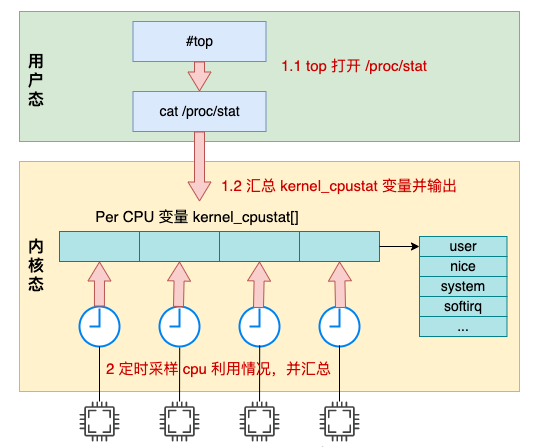
全体的に、トップ コマンドの動作の内部詳細を次の図に示します。
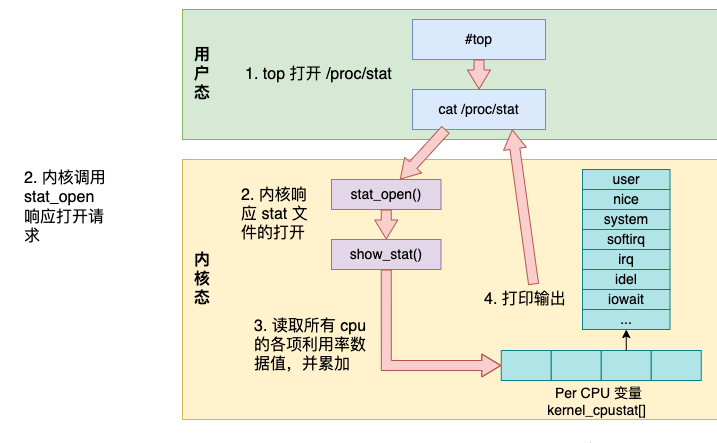
先頭のコマンドは /proc/stat にアクセスして、さまざまな CPU 使用率の値を取得します;
-
カーネルは stat_open 関数を呼び出して /proc/stat へのアクセスを処理します;
-
カーネルによってアクセスされるデータは、kernel_cpustat 配列から取得され、要約されます;
-
出力をユーザーモードに出力します。
次に、各ステップを詳しく見てみましょう。
strace を使用して top コマンドのさまざまなシステム コールをトレースすると、ファイルへの呼び出しを確認できます。
リーリーリーリー#「」
/proc/stat に加えて、各プロセスごとに分類された /proc/{pid}/stat もあり、これは各プロセスの CPU 使用率を計算するために使用されます。
」
#カーネルは擬似ファイルごとに処理関数を定義しており、/proc/stat ファイルの処理方法は proc_stat_operations です。
proc_stat_operations には、このファイルに対応する操作メソッドが含まれます。 /proc/stat ファイルが開かれると、stat_open が呼び出されます。 stat_open は、single_open_size と show_stat を順番に呼び出して、データの内容を出力します。コードを見てみましょう:
リーリー上記のコードでは、for_each_possible_cpu は CPU 使用率データを格納する kcpustat_cpu 変数を走査しています。この変数は percpu 変数であり、論理コアごとに配列要素を準備します。 user、nice、system、idel、iowait、irq、softirq など、現在のコアに対応するさまざまなイベントが保存されます。
このループでは、各コアの使用量を合計します。最後に、データは seq_put_decmal_ull を通じて出力されます。
カーネルでは、各時間は実際にはナノ秒単位で記録されますが、出力時にすべてビート単位に変換されることに注意してください。拍単位の長さについては次の章で紹介します。つまり、/proc/stat の出力は percpu 変数 kernel_cpustat から読み取られます。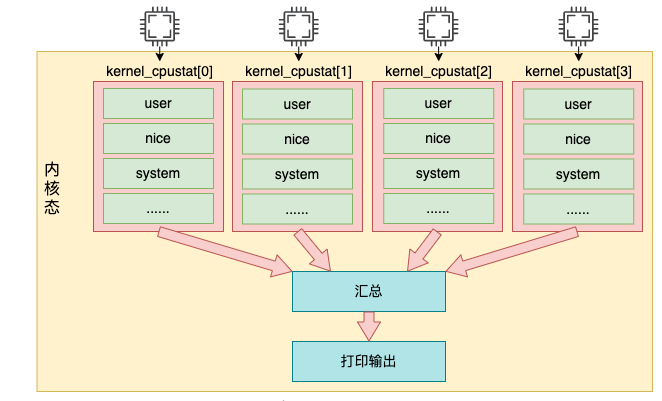
この変数のデータがいつ追加されたかを見てみましょう。
三、统计数据怎么来的
前面我们提到内核是以采样的方式来统计 cpu 使用率的。这个采样周期依赖的是 Linux 时间子系统中的定时器。
Linux 内核每隔固定周期会发出 timer interrupt (IRQ 0),这有点像乐谱中的节拍的概念。每隔一段时间,就打出一个拍子,Linux 就响应之并处理一些事情。
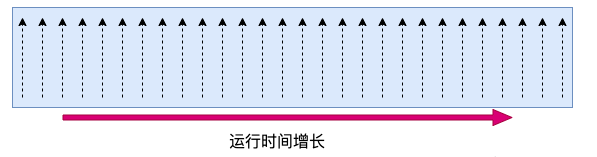
一个节拍的长度是多长时间,是通过 CONFIG_HZ 来定义的。它定义的方式是每一秒有几次 timer interrupts。不同的系统中这个节拍的大小可能不同,通常在 1 ms 到 10 ms 之间。可以在自己的 Linux config 文件中找到它的配置。
# grep ^CONFIG_HZ /boot/config-5.4.56.bsk.10-amd64 CONFIG_HZ=1000
从上述结果中可以看出,我的机器每秒要打出 1000 次节拍。也就是每 1 ms 一次。
每次当时间中断到来的时候,都会调用 update_process_times 来更新系统时间。更新后的时间都存储在我们前面提到的 percpu 变量 kcpustat_cpu 中。
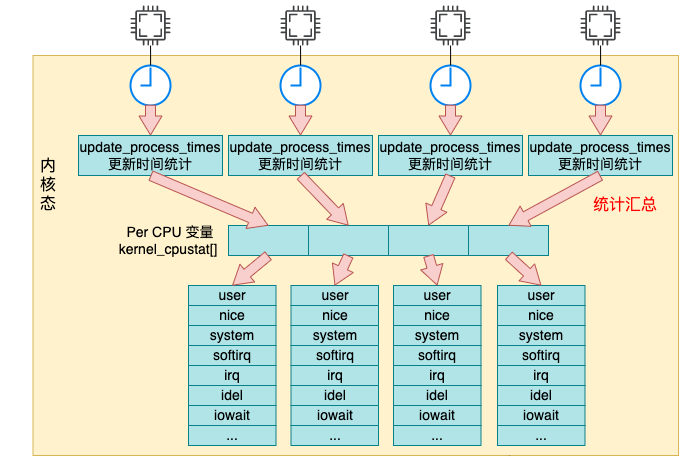
我们来详细看下汇总过程 update_process_times 的源码,它位于 kernel/time/timer.c 文件中。
//file:kernel/time/timer.c
void update_process_times(int user_tick)
{
struct task_struct *p = current;
//进行时间累积处理
account_process_tick(p, user_tick);
...
}
这个函数的参数 user_tick 指的是采样的瞬间是处于内核态还是用户态。接下来调用 account_process_tick。
//file:kernel/sched/cputime.c
void account_process_tick(struct task_struct *p, int user_tick)
{
cputime = TICK_NSEC;
...
if (user_tick)
//3.1 统计用户态时间
account_user_time(p, cputime);
else if ((p != rq->idle) || (irq_count() != HARDIRQ_OFFSET))
//3.2 统计内核态时间
account_system_time(p, HARDIRQ_OFFSET, cputime);
else
//3.3 统计空闲时间
account_idle_time(cputime);
}
在这个函数中,首先设置 cputime = TICK_NSEC, 一个 TICK_NSEC 的定义是一个节拍所占的纳秒数。接下来根据判断结果分别执行 account_user_time、account_system_time 和 account_idle_time 来统计用户态、内核态和空闲时间。
3.1 用户态时间统计
//file:kernel/sched/cputime.c
void account_user_time(struct task_struct *p, u64 cputime)
{
//分两种种情况统计用户态 CPU 的使用情况
int index;
index = (task_nice(p) > 0) ? CPUTIME_NICE : CPUTIME_USER;
//将时间累积到 /proc/stat 中
task_group_account_field(p, index, cputime);
......
}
account_user_time 函数主要分两种情况统计:
- 如果进程的 nice 值大于 0,那么将会增加到 CPU 统计结构的 nice 字段中。
- 如果进程的 nice 值小于等于 0,那么增加到 CPU 统计结构的 user 字段中。
看到这里,开篇的问题 2 就有答案了,其实用户态的时间不只是 user 字段,nice 也是。之所以要把 nice 分出来,是为了让 Linux 用户更一目了然地看到调过 nice 的进程所占的 cpu 周期有多少。
我们平时如果想要观察系统的用户态消耗的时间的话,应该是将 top 中输出的 user 和 nice 加起来一并考虑,而不是只看 user!
接着调用 task_group_account_field 来把时间加到前面我们用到的 kernel_cpustat 内核变量中。
//file:kernel/sched/cputime.c
static inline void task_group_account_field(struct task_struct *p, int index,
u64 tmp)
{
__this_cpu_add(kernel_cpustat.cpustat[index], tmp);
...
}
3.2 内核态时间统计
我们再来看内核态时间是如何统计的,找到 account_system_time 的代码。
//file:kernel/sched/cputime.c
void account_system_time(struct task_struct *p, int hardirq_offset, u64 cputime)
{
if (hardirq_count() - hardirq_offset)
index = CPUTIME_IRQ;
else if (in_serving_softirq())
index = CPUTIME_SOFTIRQ;
else
index = CPUTIME_SYSTEM;
account_system_index_time(p, cputime, index);
}
内核态的时间主要分 3 种情况进行统计。
- 如果当前处于硬中断执行上下文, 那么统计到 irq 字段中;
- 如果当前处于软中断执行上下文, 那么统计到 softirq 字段中;
- 否则统计到 system 字段中。
判断好要加到哪个统计项中后,依次调用 account_system_index_time、task_group_account_field 来将这段时间加到内核变量 kernel_cpustat 中。
//file:kernel/sched/cputime.c
static inline void task_group_account_field(struct task_struct *p, int index,
u64 tmp)
{
__this_cpu_add(kernel_cpustat.cpustat[index], tmp);
}
3.3 空闲时间的累积
没错,在内核变量 kernel_cpustat 中不仅仅是统计了各种用户态、内核态的使用时间,空闲也一并统计起来了。
如果在采样的瞬间,cpu 既不在内核态也不在用户态的话,就将当前节拍的时间都累加到 idle 中。
//file:kernel/sched/cputime.c
void account_idle_time(u64 cputime)
{
u64 *cpustat = kcpustat_this_cpu->cpustat;
struct rq *rq = this_rq();
if (atomic_read(&rq->nr_iowait) > 0)
cpustat[CPUTIME_IOWAIT] += cputime;
else
cpustat[CPUTIME_IDLE] += cputime;
}
在 cpu 空闲的情况下,进一步判断当前是不是在等待 IO(例如磁盘 IO),如果是的话这段空闲时间会加到 iowait 中,否则就加到 idle 中。从这里,我们可以看到 iowait 其实是 cpu 的空闲时间,只不过是在等待 IO 完成而已。
看到这里,开篇问题 3 也有非常明确的答案了,io wait 其实是 cpu 在空闲状态的一项统计,只不过这种状态和 idle 的区别是 cpu 是因为等待 io 而空闲。
四、总结
本文深入分析了 Linux 统计系统 CPU 利用率的内部原理。全文的内容可以用如下一张图来汇总:
Linux 中的定时器会以某个固定节拍,比如 1 ms 一次采样各个 cpu 核的使用情况,然后将当前节拍的所有时间都累加到 user/nice/system/irq/softirq/io_wait/idle 中的某一项上。
top 命令是读取的 /proc/stat 中输出的 cpu 各项利用率数据,而这个数据在内核中是根据 kernel_cpustat 来汇总并输出的。
回到开篇问题 1,top 输出的利用率信息是如何计算出来的,它精确吗?
/proc/stat 文件输出的是某个时间点的各个指标所占用的节拍数。如果想像 top 那样输出一个百分比,计算过程是分两个时间点 t1, t2 分别获取一下 stat 文件中的相关输出,然后经过个简单的算术运算便可以算出当前的 cpu 利用率。
再说是否精确。这个统计方法是采样的,只要是采样,肯定就不是百分之百精确。但由于我们查看 cpu 使用率的时候往往都是计算 1 秒甚至更长一段时间的使用情况,这其中会包含很多采样点,所以查看整体情况是问题不大的。
另外从本文,我们也学到了 top 中输出的 cpu 时间项目其实大致可以分为三类:
第****一类:用户态消耗时间,包括 user 和 nice。如果想看用户态的消耗,要将 user 和 nice 加起来看才对。
第二类:内核态消耗时间,包括 irq、softirq 和 system。
第三类:空闲时间,包括 io_wait 和 idle。其中 io_wait 也是 cpu 的空闲状态,只不过是在等 io 完成而已。如果只是想看 cpu 到底有多闲,应该把 io_wait 和 idle 加起来才对。
以上がLinux では CPU 使用率はどのように計算されますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1662
1662
 14
1419
52
1312
25
1262
29
1235
24
14
1419
52
1312
25
1262
29
1235
24

 Linuxアーキテクチャ:5つの基本コンポーネントを発表します
Apr 20, 2025 am 12:04 AM
Linuxアーキテクチャ:5つの基本コンポーネントを発表します
Apr 20, 2025 am 12:04 AM
Linuxシステムの5つの基本コンポーネントは次のとおりです。1。Kernel、2。Systemライブラリ、3。Systemユーティリティ、4。グラフィカルユーザーインターフェイス、5。アプリケーション。カーネルはハードウェアリソースを管理し、システムライブラリは事前コンパイルされた機能を提供し、システムユーティリティはシステム管理に使用され、GUIは視覚的な相互作用を提供し、アプリケーションはこれらのコンポーネントを使用して機能を実装します。
 GITの倉庫アドレスを確認する方法
Apr 17, 2025 pm 01:54 PM
GITの倉庫アドレスを確認する方法
Apr 17, 2025 pm 01:54 PM
gitリポジトリアドレスを表示するには、次の手順を実行します。1。コマンドラインを開き、リポジトリディレクトリに移動します。 2。「git remote -v」コマンドを実行します。 3.出力と対応するアドレスでリポジトリ名を表示します。
 VSCODE前の次のショートカットキー
Apr 15, 2025 pm 10:51 PM
VSCODE前の次のショートカットキー
Apr 15, 2025 pm 10:51 PM
VSコードワンステップ/次のステップショートカットキー使用法:ワンステップ(後方):Windows/Linux:Ctrl←; macOS:CMD←次のステップ(フォワード):Windows/Linux:Ctrl→; macOS:CMD→
 Linuxの主な目的は何ですか?
Apr 16, 2025 am 12:19 AM
Linuxの主な目的は何ですか?
Apr 16, 2025 am 12:19 AM
Linuxの主な用途には、1。Serverオペレーティングシステム、2。EmbeddedSystem、3。Desktopオペレーティングシステム、4。開発およびテスト環境。 Linuxはこれらの分野で優れており、安定性、セキュリティ、効率的な開発ツールを提供します。
 Apr 16, 2025 pm 07:39 PM
Apr 16, 2025 pm 07:39 PM
NotePadはJavaコードを直接実行することはできませんが、他のツールを使用することで実現できます。コマンドラインコンパイラ(Javac)を使用してByteCodeファイル(filename.class)を生成します。 Javaインタープリター(Java)を使用して、バイトコードを解釈し、コードを実行し、結果を出力します。
 コードを書いた後に崇高に実行する方法
Apr 16, 2025 am 08:51 AM
コードを書いた後に崇高に実行する方法
Apr 16, 2025 am 08:51 AM
Sublimeでコードを実行するには6つの方法があります。ホットキー、メニュー、ビルドシステム、コマンドライン、デフォルトビルドシステムの設定、カスタムビルドコマンド、プロジェクト/ファイルを右クリックして個々のファイル/プロジェクトを実行します。ビルドシステムの可用性は、崇高なテキストのインストールに依存します。
 Laravelインストールコード
Apr 18, 2025 pm 12:30 PM
Laravelインストールコード
Apr 18, 2025 pm 12:30 PM
Laravelをインストールするには、これらの手順を順番に進みます。コンポーザー(MacOS/LinuxとWindows用)インストールLaravelインストーラーをインストールします。
 vscodeの使用方法
Apr 15, 2025 pm 11:21 PM
vscodeの使用方法
Apr 15, 2025 pm 11:21 PM
Visual Studio Code(VSCODE)は、Microsoftが開発したクロスプラットフォーム、オープンソース、および無料のコードエディターです。軽量、スケーラビリティ、および幅広いプログラミング言語のサポートで知られています。 VSCODEをインストールするには、公式Webサイトにアクセスして、インストーラーをダウンロードして実行してください。 VSCODEを使用する場合、新しいプロジェクトを作成し、コードを編集し、コードをデバッグし、プロジェクトをナビゲートし、VSCODEを展開し、設定を管理できます。 VSCODEは、Windows、MacOS、Linuxで利用でき、複数のプログラミング言語をサポートし、マーケットプレイスを通じてさまざまな拡張機能を提供します。その利点には、軽量、スケーラビリティ、広範な言語サポート、豊富な機能とバージョンが含まれます
