

視覚言語モデルに空間推論を行わせると、Google は再び新しくなります

視覚言語モデル (VLM) は、画像の説明、視覚的な質問応答、具体化された計画、行動認識などの多くのタスクで大幅な進歩を遂げていますが、空間推論には課題が残っています。多くのモデルでは、3 次元空間におけるターゲットの位置や空間関係を理解することが依然として困難です。これは、視覚言語モデルをさらに開発する過程で、複雑な視覚タスクの処理におけるモデルの精度と効率を向上させるために、空間推論の問題の解決に焦点を当てる必要があることを示しています。
研究者は、人間の身体的経験や進化の発達を通じてこの疑問を探求することがよくあります。人間には、複雑な思考プロセスや暗算を必要とせずに、オブジェクトの相対位置などの空間的関係を簡単に判断したり、距離やサイズを推定したりできる空間推論スキルが固有に備わっています。
直接空間推論タスクにおけるこの熟練度は、現在の視覚言語モデルの機能の限界とは対照的であり、視覚言語を強化することが可能かどうかという、説得力のある研究上の疑問を提起します。モデルは似ていますか?人間の空間推論能力?
最近、Google は空間推論機能を備えた視覚言語モデル、SpatialVLM を提案しました。

- 論文タイトル: SpatialVLM: 視覚を与える - 言語空間推論機能を備えたモデル
- 論文アドレス: https://arxiv.org/pdf/2401.12168.pdf
- ##プロジェクトのホームページ: https://spatial-vlm.github.io/
#対照的に、この研究は、現実の 3D 世界の多様性と複雑さを示すために、実世界のデータを使用して空間情報を直接抽出することに焦点を当てています。この方法は、最新のビジュアル モデリング テクノロジに触発されており、2D 画像から 3D 空間アノテーションを自動的に生成できます。
SpatialVLM システムの重要な機能は、オブジェクト検出、深度推定、セマンティック セグメンテーション、オブジェクト中心記述モデルなどの技術を使用して、大規模で高密度に注釈が付けられた実世界データを処理して、機能を強化することです。視覚言語モデルの空間推論機能。 SpatialVLM システムは、ビジュアル モデルによって生成されたデータを、記述、VQA、空間推論に使用できるハイブリッド データ形式に変換することにより、ビジュアル言語モデルのデータ生成とトレーニングの目標を達成します。研究者らの努力により、このシステムは視覚情報をよりよく理解して処理できるようになり、それによって複雑な空間推論タスクにおけるパフォーマンスが向上しました。このアプローチは、画像とテキストの関係をよりよく理解して処理できるように視覚言語モデルをトレーニングするのに役立ち、それによってさまざまな視覚タスクにおける精度と効率が向上します。
研究によると、この記事で提案した視覚言語モデルは複数の分野で満足のいく機能を発揮します。まず、定性的な空間問題の処理において大幅な改善が見られます。第 2 に、モデルはトレーニング データにノイズが存在する場合でも、定量的な推定値を確実に生成できます。この機能により、ターゲットのサイズに関する常識的な知識が得られるだけでなく、再配置タスクやオープン語彙の報酬アノテーションの処理にも役立ちます。最後に、空間視覚言語モデルは、強力な大規模言語モデルと組み合わせることで、空間推論チェーンを実行し、自然言語インターフェイスに基づいて複雑な空間推論タスクを解決できます。
手法の概要
視覚言語モデルに定性的および定量的な空間推論機能を持たせるために、研究者らは大規模な空間 VQA データセットを生成することを提案しました。視覚トレーニングのための言語モデル。具体的には、まず、オープンボキャブラリ検出、メトリクス深さ推定、セマンティックセグメンテーション、ターゲット中心記述モデルなどの既製のコンピュータビジョンモデルを利用して、ターゲット中心の背景情報を抽出する包括的なデータ生成フレームワークを設計することです。次に、テンプレートベースのアプローチを採用して、妥当な品質の大規模空間 VQA データを生成します。この論文では、研究者らは、生成されたデータセットを使用して SpatialVLM をトレーニングし、直接空間推論機能を学習させ、それを LLM に埋め込まれた高レベルの常識推論と組み合わせて、連鎖思考の空間推論を解き放ちました。

# 2D 画像の空間データ
#研究者らは、空間推論の質問を含む VQA データを生成するプロセスを設計しました。その具体的なプロセスを図 2 に示します。

1. セマンティック フィルタリング: この記事のデータ合成プロセスでは、最初のステップはオープン ボキャブラリーを使用することです。 CLIP に基づく分類モデルはすべての画像を分類し、不適切な画像を除外します。
2. 2D 画像抽出ターゲット中心の背景: このステップでは、ピクセル クラスターとオープンボキャブラリーの説明からなるターゲット中心のエンティティを取得します。
3. 2D 背景情報から 3D 背景情報へ: 深度推定後、片目の 2D ピクセルがメートルスケールの 3D 点群にアップグレードされます。この論文は、インターネット スケールの画像をオブジェクト中心の 3D 点群にアップスケーリングし、それらを使用して 3D 空間推論監視を備えた VQA データを合成した最初の論文です。
4. 曖昧さ回避: 場合によっては、画像内に同様のカテゴリの複数のオブジェクトが存在し、その結果、説明ラベルが曖昧になることがあります。したがって、これらの目標について質問する前に、参照式に曖昧さが含まれていないことを確認する必要があります。
大規模空間推論 VQA データ セット
研究者らは、事前トレーニングに合成データを使用して、「直感的に」 」空間推論機能が VLM に統合されています。したがって、合成には、画像内の 2 つ以下のオブジェクト (A と B で示される) の空間推論の質問と回答のペアが含まれます。ここでは主に次の 2 種類の質問を検討します:
1. 定性的質問: 特定の空間関係の判断について尋ねます。たとえば、「2 つのオブジェクト A と B がある場合、どちらがより左にありますか?」
2. 定量的な質問: 数値や単位など、より詳細な回答を求めます。たとえば、「物体 A は物体 B に対してどれだけ左にありますか?」、「物体 A は B からどのくらい離れていますか?」
ここで、研究者は 38 種類の異なるタイプを指定しました。定性的および定量的な空間推論の質問。それぞれに約 20 の質問テンプレートと 10 の回答テンプレートが含まれます。
図 3 は、この記事で取得した合成質問と回答のペアの例を示しています。研究者らは、1,000 万枚の画像と 20 億の直接空間推論の質問と回答のペア (定性的 50%、定量的 50%) からなる大規模なデータセットを作成しました。

#空間推論を学ぶ
直接空間推論: 視覚言語モデルは、画像 I と空間タスクに関するクエリ Q を入力として受け取り、外部ツールを使用したり他の大規模なモデルと対話したりすることなく、テキスト形式で提示された回答 A を出力します。この記事では、PaLM のバックボーンが PaLM 2-S に置き換えられることを除いて、PaLM-E と同じアーキテクチャとトレーニング プロセスを採用しています。次に、元の PaLM-E データセットと著者のデータセットを混合して使用し、トークンの 5% を空間推論タスクに使用してモデル トレーニングを実行しました。連鎖思考の空間推論: SpatialVLM は、基礎となる概念に関する質問をクエリするために使用できる自然言語インターフェイスを提供し、強力な LLM と組み合わせることで、複雑な空間推論を実行できます。
ソクラティック モデルと LLM コーディネーターのメソッドと同様に、この記事では LLM (text-davinci-003) を使用して SpatialVLM との通信を調整し、連鎖思考プロンプトで複雑な問題を解決します。問題を図 4 に示します。
研究者は実験を通じて次の疑問を証明し、答えました。 質問 1: この記事で設計された空間 VQA データの生成およびトレーニング プロセスは、VLM の一般的な空間推論能力を向上させますか?そしてそれはどのように機能するのでしょうか? 質問 2: ノイズの多いデータとさまざまなトレーニング戦略が詰まった合成空間 VQA データは、学習パフォーマンスにどのような影響を与えますか? 質問 3: 「直接」空間推論機能を備えた VLM は、連鎖思考推論や具体化された計画などの新しい機能を解放できますか? 研究者らは、PaLM-E トレーニング セットとこの記事で設計した空間 VQA データ セットを組み合わせて使用してモデルをトレーニングしました。空間推論における VLM の制限がデータの問題であるかどうかを検証するために、彼らは現在の最先端の視覚言語モデルをベースラインとして選択しました。意味論的記述タスクは、この記事の空間 VQA データ セットをトレーニングに使用するのではなく、これらのモデルのトレーニング プロセスでかなりの部分を占めます。 空間 VQA のパフォーマンス 定性的な空間 VQA。この質問の場合、人間による注釈付きの回答と VLM 出力は両方とも自由形式の自然言語です。したがって、VLM のパフォーマンスを評価するために、人間の評価者を使用して回答が正しいかどうかを判断しました。各 VLM の成功率を表 1 に示します。 定量的な空間 VQA。表 2 に示すように、私たちのモデルは両方の指標においてベースラインよりも優れたパフォーマンスを示しており、はるかに優れています。 空間 VQA データが一般的な VQA に及ぼす影響
##Frozen ViT (対照的なターゲットでトレーニングされた) は、空間推論に十分な情報をエンコードしますか?これを調査するために、研究者らの実験はトレーニング ステップ 110,000 から開始され、1 つは Frozen ViT、もう 1 つは Unfrozen ViT の 2 つのトレーニング実行に分割されました。両方のモデルを 70,000 ステップでトレーニングした場合の評価結果を表 4 に示します。
研究者らは、ロボット操作データセットを使用して視覚言語モデルをトレーニングしたところ、モデルが操作フィールドで精密な距離推定を実行できることがわかり(図5)、データの精度がさらに証明されました。
ビジュアル言語モデルは、ロボット工学の分野で重要な用途を持っています。最近の研究では、視覚言語モデルと大規模言語モデルが、一般的なオープンボキャブラリの報酬アノテーターやロボットタスクの成功検出器として機能し、効果的な制御戦略を開発するために使用できることが示されています。ただし、VLM の報酬ラベル付け機能は、空間認識が不十分なために制限されることがよくあります。 SpatialVLM は、画像から距離や寸法を定量的に推定できるため、高密度報酬アノテーターとして独特に適しています。著者らは、現実世界のロボット工学実験を実施し、自然言語でタスクを指定し、SpatialVLM に軌道内の各フレームの報酬に注釈を付けるように依頼します。 図 6 の各ドットはターゲットの位置を表し、その色は注釈付きの報酬を表します。ロボットが特定の目標に向かって進歩するにつれて、報酬が単調に増加することがわかり、高密度報酬アノテーターとしての SpatialVLM の機能が実証されています。 #2. 連鎖思考空間推論 研究者らはまた、SpatialVLM の基本的な空間的質問に答える能力が強化されているため、SpatialVLM を使用して複数ステップの推論が必要なタスクを実行できるかどうかも調査しました。著者らは、図 1 と図 4 にいくつかの例を示しています。大規模言語モデル (GPT-4) に空間推論サブモジュールとして SpatialVLM が装備されている場合、環境内の 3 つのオブジェクトが「二等辺三角形」を形成できるかどうかを答えるなど、複雑な空間推論タスクを実行できます。 技術的な詳細と実験結果については、元の論文を参照してください。 
#実験と結果
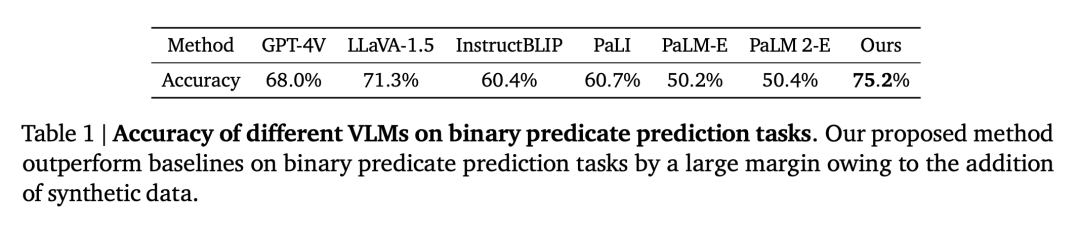
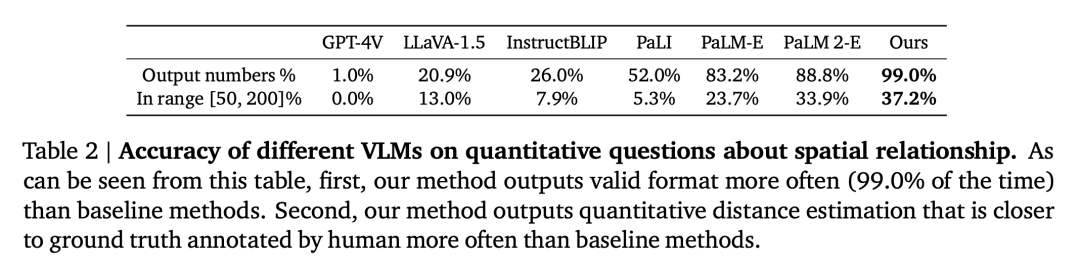
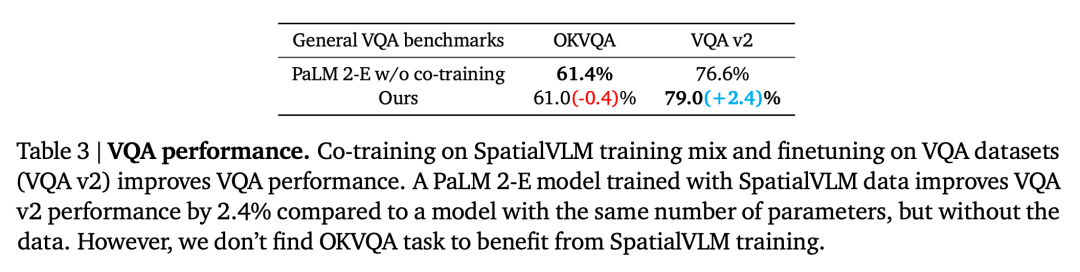

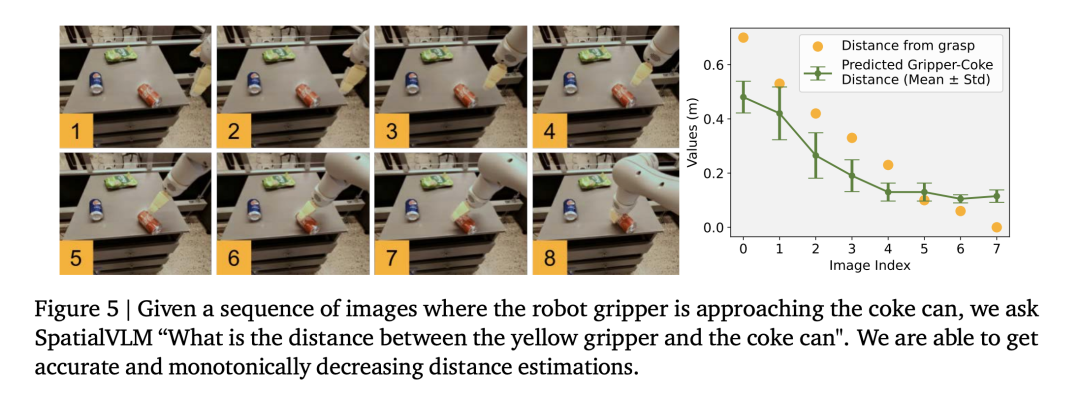 表 5 は、定量的空間 VQA における全体的な VLM パフォーマンスに対するさまざまなガウス ノイズ標準偏差の影響を比較しています。
表 5 は、定量的空間 VQA における全体的な VLM パフォーマンスに対するさまざまなガウス ノイズ標準偏差の影響を比較しています。  # 空間推論が新しいアプリケーションを触発する
# 空間推論が新しいアプリケーションを触発する1. ビジョン高密度報酬アノテーターとしての言語モデル

以上が視覚言語モデルに空間推論を行わせると、Google は再び新しくなりますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7561
7561
 15
1384
52
84
11
28
98
15
1384
52
84
11
28
98

 世界のトップ10の仮想通貨取引プラットフォームのトップ10のランキングは何ですか?
Feb 20, 2025 pm 02:15 PM
世界のトップ10の仮想通貨取引プラットフォームのトップ10のランキングは何ですか?
Feb 20, 2025 pm 02:15 PM
暗号通貨の人気により、仮想通貨取引プラットフォームが登場しています。世界の上位10の仮想通貨取引プラットフォームは、トランザクションの量と市場シェアに従って次のようにランク付けされています:Binance、Coinbase、FTX、Kucoin、Crypto.com、Kraken、Huobi、Gate.io、Bitfinex、Gemini。これらのプラットフォームは、幅広い暗号通貨の選択から、さまざまなレベルのトレーダーに適したデリバティブ取引に至るまで、幅広いサービスを提供しています。
 ゴマのオープンエクスチェンジを中国語に調整する方法
Mar 04, 2025 pm 11:51 PM
ゴマのオープンエクスチェンジを中国語に調整する方法
Mar 04, 2025 pm 11:51 PM
ゴマのオープンエクスチェンジを中国語に調整する方法は?このチュートリアルでは、コンピューターとAndroidの携帯電話の詳細な手順、予備的な準備から運用プロセスまで、そして一般的な問題を解決するために、セサミのオープン交換インターフェイスを中国に簡単に切り替え、取引プラットフォームをすばやく開始するのに役立ちます。
 ブートストラップ画像の中央でFlexBoxを使用する必要がありますか?
Apr 07, 2025 am 09:06 AM
ブートストラップ画像の中央でFlexBoxを使用する必要がありますか?
Apr 07, 2025 am 09:06 AM
ブートストラップの写真を集中させる方法はたくさんあり、FlexBoxを使用する必要はありません。水平にのみ中心にする必要がある場合、テキスト中心のクラスで十分です。垂直または複数の要素を中央に配置する必要がある場合、FlexBoxまたはグリッドがより適しています。 FlexBoxは互換性が低く、複雑さを高める可能性がありますが、グリッドはより強力で、学習コストが高くなります。メソッドを選択するときは、長所と短所を比較検討し、ニーズと好みに応じて最も適切な方法を選択する必要があります。
 トップ10の暗号通貨取引プラットフォーム、トップ10の推奨される通貨取引プラットフォームアプリ
Mar 17, 2025 pm 06:03 PM
トップ10の暗号通貨取引プラットフォーム、トップ10の推奨される通貨取引プラットフォームアプリ
Mar 17, 2025 pm 06:03 PM
上位10の暗号通貨取引プラットフォームには、1。Okx、2。Binance、3。Gate.io、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 c-subscript 3 subscript 5 c-subscript 3 subscript 5アルゴリズムチュートリアルを計算する方法
Apr 03, 2025 pm 10:33 PM
c-subscript 3 subscript 5 c-subscript 3 subscript 5アルゴリズムチュートリアルを計算する方法
Apr 03, 2025 pm 10:33 PM
C35の計算は、本質的に組み合わせ数学であり、5つの要素のうち3つから選択された組み合わせの数を表します。計算式はC53 = 5です! /(3! * 2!)。これは、ループで直接計算して効率を向上させ、オーバーフローを避けることができます。さらに、組み合わせの性質を理解し、効率的な計算方法をマスターすることは、確率統計、暗号化、アルゴリズム設計などの分野で多くの問題を解決するために重要です。
 トップ10仮想通貨取引プラットフォーム2025暗号通貨取引アプリランキングトップ10
Mar 17, 2025 pm 05:54 PM
トップ10仮想通貨取引プラットフォーム2025暗号通貨取引アプリランキングトップ10
Mar 17, 2025 pm 05:54 PM
トップ10仮想通貨取引プラットフォーム2025:1。OKX、2。BINANCE、3。GATE.IO、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 安全で信頼できるデジタル通貨プラットフォームは何ですか?
Mar 17, 2025 pm 05:42 PM
安全で信頼できるデジタル通貨プラットフォームは何ですか?
Mar 17, 2025 pm 05:42 PM
安全で信頼できるデジタル通貨プラットフォーム:1。OKX、2。Binance、3。Gate.io、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 推奨される安全な仮想通貨ソフトウェアアプリトップ10デジタル通貨取引アプリ2025ランキング
Mar 17, 2025 pm 05:48 PM
推奨される安全な仮想通貨ソフトウェアアプリトップ10デジタル通貨取引アプリ2025ランキング
Mar 17, 2025 pm 05:48 PM
推奨される安全な仮想通貨ソフトウェアアプリ:1。Okx、2。Binance、3。Gate.io、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
