

ピンゴラってすごいですね! Nginxを超える超人気Webサーバー

Rust 上に構築された新しい HTTP プロキシである Pingora を紹介できることを嬉しく思います。 1 日あたり 1 兆を超えるリクエストを処理し、パフォーマンスを向上させ、Cloudflare の顧客に新機能を提供しながら、必要な CPU リソースとメモリ リソースは元のプロキシ インフラストラクチャの 3 分の 1 のみです。
Cloudflare が拡張し続けるにつれて、NGINX の処理能力ではもはやニーズを満たせないことがわかりました。長年にわたってうまく機能していましたが、時間が経つにつれて、私たちの規模での課題に対処するには限界があることに気づきました。したがって、パフォーマンスと機能のニーズを満たすために、いくつかの新しいソリューションを構築する必要があると感じました。
Cloudflareの顧客とユーザーは、HTTPクライアントとサーバー間のプロキシとしてCloudflareグローバルネットワークを使用します。私たちは多くの議論を行い、多くのテクノロジーを開発し、QUIC や HTTP/2 の最適化などの新しいプロトコルを実装して、ネットワークに接続するブラウザーやその他のユーザー エージェントの効率を向上させてきました。
今日は、この方程式に関連するもう 1 つの側面、つまりネットワークとインターネット サーバー間のトラフィックの管理を担当するプロキシ サービスに焦点を当てます。このプロキシ サービスは、CDN、ワーカーフェッチ、トンネル、ストリーム、R2、その他多くの機能と製品のサポートとパワーを提供します。
従来のサービスをアップグレードすることにした理由を詳しく調べ、Pingora システムの開発プロセスを探ってみましょう。このシステムは、Cloudflare の顧客のユースケースと規模に合わせて特別に設計されています。
別のプロキシを構築する理由
近年、NGINX を使用する際にいくつかの制限に遭遇しました。一部の制限については、それらを回避する方法を最適化または採用しました。ただし、より困難な制限がいくつかあります。
アーキテクチャ上の制限によりパフォーマンスが低下する
NGINX ワーカー (プロセス) アーキテクチャ [4] には、私たちのユースケースにとって運用上の欠陥があり、パフォーマンスと効率に悪影響を及ぼします。
まず第一に、NGINX では、各リクエストは 1 つのワーカーによってのみ処理されます。これにより、すべての CPU コア [5] 間で負荷の不均衡が生じ、速度低下が発生します [6]。
このリクエスト プロセスのロック効果により、CPU を集中的に使用するリクエストやブロック IO タスクを実行するリクエストは、他のリクエストの速度を低下させる可能性があります。これらのブログ投稿で指摘されているように、私たちはこれらの問題の解決に多くの時間を費やしてきました。
このユースケースで最も重要な問題は、マシンが HTTP リクエストをプロキシするオリジン サーバーとの TCP 接続を確立するときの接続の再利用です。接続プールからの接続を再利用すると、新しい接続に必要な TCP および TLS ハンドシェイクをスキップできるため、リクエストの TTFB (最初のバイトまでの時間) が高速化されます。
ただし、NGINX 接続プール [9] は 1 つのワーカーに対応します。リクエストがワーカーに到達すると、そのワーカー内でのみ接続を再利用できます。拡張するために NGINX ワーカーを追加すると、接続がすべてのプロセスにわたってより分離されたプールに分散されるため、接続の再利用は悪化します。その結果、TTFB が遅くなり、維持しなければならない接続が増加し、当社とお客様のリソース (およびお金) が消費されます。 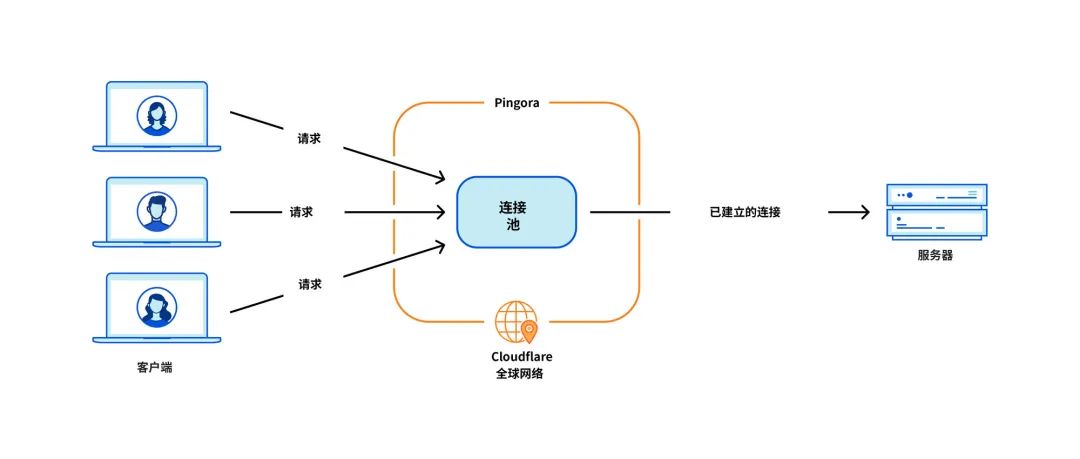
過去のブログ投稿で述べたように、これらの問題のいくつかについては回避策を提供しました。しかし、ワーカー/プロセス モデルという根本的な問題を解決できれば、これらの問題はすべて自然に解決されるでしょう。
一部の機能は追加が困難です
NGINX は、優れた Web サーバー、ロード バランサー、またはシンプルなゲートウェイです。しかし、Cloudflare はそれ以上のことを行います。以前は必要なすべての機能を NGINX を中心に構築していましたが、NGINX アップストリーム コードベースからの分岐を避けようとするのは簡単ではありませんでした。
たとえば、リクエスト/リクエストの失敗[10]を再試行するときに、異なるリクエスト ヘッダーのセットを使用して、別のオリジン サーバーにリクエストを送信したい場合があります。しかし、NGINX はこれを許可しません。この場合、NGINX の制限を回避するために時間と労力を費やす必要があります。
同時に、私たちが使用を余儀なくされているプログラミング言語は、これらの問題を軽減するのに役立ちません。 NGINX は純粋に C で書かれており、設計上メモリ安全ではありません。このようにサードパーティのコードベースを使用すると、非常にエラーが発生しやすくなります。経験豊富なエンジニアであっても、メモリの安全性の問題 [11] に陥りやすいため、これらの問題はできる限り回避したいと考えています。
C を補完するために使用するもう 1 つの言語は Lua です。リスクは低くなりますが、パフォーマンスも低くなります。さらに、複雑な Lua コードやビジネス ロジックを扱う場合、静的型付けが欠けていることに気づくことがよくあります [12]。
さらに、NGINX コミュニティはあまり活発ではなく、開発は「密室」で行われることがよくあります [13]。
独自の構築を選択する
過去数年間、顧客ベースと機能セットが拡大し続ける中、私たちは 3 つのオプションを評価し続けてきました。
過去数年間、私たちはこれらのオプションを四半期ごとに評価してきました。どのオプションが最適であるかを決定するための明確な公式はありません。数年間にわたり、私たちは最も抵抗の少ない道を歩み続け、NGINX を強化し続けました。ただし、場合によっては、独自の代理店を構築することの ROI の方が価値があると思われる場合もあります。私たちはエージェントをゼロから構築することを求め、夢のエージェント アプリケーションの設計を開始しました。
Pingora プロジェクト
設計の決定
毎秒数百万のリクエストに対応する高速、効率的、安全なプロキシを構築するには、まずいくつかの重要な設計上の決定を下す必要がありました。
Rust[16] をプロジェクトの言語として選択したのは、パフォーマンスに影響を与えることなく、C で実行できることをメモリ安全な方法で実行できるためです。
hyper[17] など、優れた既製のサードパーティ HTTP ライブラリがいくつかありますが、HTTP トラフィックの処理における柔軟性を最大限に高め、独自の Innovate に確実に従うことができるようにしたかったため、独自のライブラリを構築することにしました。ペースで。
Cloudflare では、インターネット全体のトラフィックを処理します。私たちは、HTTP トラフィックの多くの奇妙なケースや RFC に準拠していないケースをサポートする必要があります。これは HTTP コミュニティと Web に共通するジレンマであり、HTTP 仕様に厳密に従うか、潜在的なレガシー クライアントやサーバーのより広範なエコシステムの微妙な違いに適応するか、難しい選択をする必要があります。
HTTP ステータス コードは、RFC 9110 で 3 桁の整数 [18] として定義されており、通常は 100 ~ 599 の範囲であると予想されます。 Hyper はそのような実装の 1 つです。ただし、多くのサーバーは 599 ~ 999 のステータス コードの使用をサポートしています。この特集では、議論のさまざまな側面を探る質問 [19] を作成しました。ハイパー チームは最終的にこの変更を受け入れましたが、そのような要求を拒否するには十分な理由があり、これは私たちがサポートする必要があった多くの不遵守事例の 1 つにすぎませんでした。
HTTP エコシステムにおける Cloudflare の地位を満たすためには、インターネットのさまざまなリスク環境に耐え、さまざまな非準拠のユースケースをサポートできる、堅牢で耐性があり、カスタマイズ可能な HTTP ライブラリが必要です。これを保証する最善の方法は、独自のアーキテクチャを実装することです。
次の設計上の決定は、ワークロード スケジューリング システムに関するものです。リソース、特に接続プーリングを簡単に共有するために、マルチプロセッシング [20] ではなくマルチスレッドを選択します。私たちは、上記の特定のカテゴリのパフォーマンス問題を回避するために、ワーク スティーリング [21] も実装する必要があると考えています。 Tokio 非同期ランタイムは、私たちのニーズに完全に適合します [22]。
最後に、私たちはプロジェクトを直感的で開発者にとって使いやすいものにしたいと考えています。私たちが構築しているものは最終製品ではありませんが、その上にさらに多くの機能が構築されるため、プラットフォームとして拡張可能である必要があります。私たちは、NGINX/OpenResty[23]と同様の「リクエストライフサイクル」イベントに基づいてプログラマブルインターフェイスを実装することにしました。たとえば、Request Filter ステージを使用すると、開発者はリクエスト ヘッダーの受信時にリクエストを変更または拒否するコードを実行できます。この設計により、ビジネス ロジックと一般的なプロキシ ロジックを明確に分離できます。以前 NGINX に取り組んでいた開発者は、Pingora に簡単に切り替えることができ、すぐに生産性が向上します。
Pingora は本番環境では高速です
話を早送りしてみましょう。 Pingora は、オリジン サーバーとの対話を必要とするほぼすべての HTTP リクエスト (キャッシュ ミスなど) を処理し、その過程で大量のパフォーマンス データを収集します。
まず、Pingora がどのように顧客のトラフィックを高速化するかを見てみましょう。 Pingora の全体的なトラフィックは、TTFB の中央値が 5 ミリ秒の減少、95 パーセンタイルの減少が 80 ミリ秒であることを示しています。それはコードの実行が速くなったからではありません。私たちの古いサービスでも、ミリ秒未満の範囲でリクエストを処理できます。
すべてのスレッドで接続を共有する新しいアーキテクチャにより、時間の節約が可能になります。これは、接続の再利用が向上し、TCP および TLS ハンドシェイクにかかる時間が短縮されることを意味します。
全顧客全体で見ると、Pingora の 1 秒あたりの新規接続数は、古いサービスと比較して 3 分の 1 にすぎません。ある大手顧客では、接続の再利用が 87.1% から 99.92% に増加し、新しい接続が 160 分の 1 に減少しました。ざっくり言うと、Pingora に切り替えることで、顧客とユーザーの 434 年間にわたる毎日の握手を節約できました。
#その他の機能
以前の制限を取り除きながら、エンジニアにとって使い慣れた開発者フレンドリーなインターフェイスを備えることで、より多くの機能をより迅速に開発できるようになります。新しいプロトコルなどのコア機能は、お客様により多くのものを提供するための構成要素として機能します。たとえば、大きな障害を伴うことなく、HTTP/2 アップストリーム サポートを Pingora に追加することができました。これにより、お客様がすぐに gRPC を利用できるようになります[24]。同じ機能を NGINX に追加するには、より多くのエンジニアリング作業が必要となり、不可能になる可能性があります [25]。
最近、Pingora が R2 ストレージをキャッシュ レイヤーとして使用する Cache Reserve[26] の開始を発表しました。 Pingora にさらに多くの機能を追加することで、以前は実現できなかった新しい製品を提供できるようになります。
#########もっと効率的な#########
実稼働環境では、Pingora は、以前のサービスと比較して、同じトラフィック負荷の下で CPU 消費量が約 70%、メモリ消費量が約 67% 少なくなります。節約にはいくつかの要因があります。私たちの Rust コードは、古い Lua コード [27] よりも効率的に実行されます [28]。それに加えて、アーキテクチャにも効率の違いがあります。たとえば、NGINX/OpenResty では、Lua コードが HTTP ヘッダーにアクセスする場合、NGINX C 構造体からヘッダーを読み取り、Lua 文字列を割り当て、それを Lua 文字列にコピーする必要があります。その後、Lua は新しい文字列のガベージ コレクションも行います。 Pingora では、単純な文字列アクセスです。 マルチスレッド モデルにより、リクエスト間でのデータ共有もより効率的になります。 NGINX にも共有メモリがありますが、実装の制限により、各共有メモリ アクセスではミューテックスを使用する必要があり、共有メモリに入れることができるのは文字列と数値のみです。 Pingora では、ほとんどの共有アイテムは、アトミック参照カウンターの背後にある共有参照を通じて直接アクセスできます [29]。
上で述べたように、CPU 節約のもう 1 つの重要な部分は、新しい接続の削減です。 TLS ハンドシェイクは、確立された接続を介してデータを送受信するよりも明らかにコストが高くなります。より安全な
私たちの規模では、機能を迅速かつ安全にリリースすることは困難です。 1 秒あたり数百万のリクエストを処理する分散環境で発生する可能性のあるすべてのエッジケースを予測することは困難です。ファズテストと静的解析では軽減できる範囲は限られています。 Rust のメモリセーフ セマンティクスは、未定義の動作から私たちを守り、サービスが正しく実行されるという確信を与えてくれます。
これらの保証により、サービスの変更が他のサービスや顧客ソースとどのように相互作用するかにさらに重点を置くことができます。メモリの安全性や診断が難しいクラッシュに悩まされることなく、より高い頻度で機能を開発することができました。 クラッシュが発生した場合、エンジニアは時間をかけてクラッシュがどのように発生し、何が原因で発生したのかを診断する必要があります。 Pingora が設立されて以来、私たちは何千億ものリクエストに対応してきましたが、サービス コードが原因でクラッシュしたことはまだありません。
実際、Pingora のクラッシュは非常にまれであるため、クラッシュに遭遇すると、通常は無関係な問題が見つかります。最近、サービスがクラッシュし始めた直後にカーネルのバグ [30] を発見しました。また、一部のマシンではハードウェアの問題も発見されており、これまでは、大規模なデバッグがほぼ不可能だったにもかかわらず、ソフトウェアによって引き起こされるまれなメモリ エラーが除外されていました。要約
要約すると、当社は現在および将来の製品のプラットフォームとして機能する、より高速で効率的、そして多用途な社内エージェントを構築しました。
私たちが直面した問題とアプリケーションの最適化についての技術的な詳細と、Pingora の構築とインターネットの重要な部分をサポートするための展開から学んだ教訓については、後ほど詳しく説明します。オープンソースへの取り組みについても紹介します。 この記事は、Yuchen Wu および Andrew Hauck によって書かれた CloudFlare ブログから転載されたものです
リンク: https://blog.cloudflare.com/zh-cn/how-we-built-pingora-the-proxy-that-connects-cloudflare-to-the-internet-zh-cn/以上がピンゴラってすごいですね! Nginxを超える超人気Webサーバーの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7549
7549
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 Nginxが開始されるかどうかを確認する方法
Apr 14, 2025 pm 01:03 PM
Nginxが開始されるかどうかを確認する方法
Apr 14, 2025 pm 01:03 PM
nginxが開始されるかどうかを確認する方法:1。コマンドラインを使用します:SystemCTLステータスnginx(Linux/unix)、netstat -ano | FindStr 80(Windows); 2。ポート80が開いているかどうかを確認します。 3.システムログのnginx起動メッセージを確認します。 4. Nagios、Zabbix、Icingaなどのサードパーティツールを使用します。
 Windowsでnginxを構成する方法
Apr 14, 2025 pm 12:57 PM
Windowsでnginxを構成する方法
Apr 14, 2025 pm 12:57 PM
Windowsでnginxを構成する方法は? nginxをインストールし、仮想ホスト構成を作成します。メイン構成ファイルを変更し、仮想ホスト構成を含めます。 nginxを起動またはリロードします。構成をテストし、Webサイトを表示します。 SSLを選択的に有効にし、SSL証明書を構成します。ファイアウォールを選択的に設定して、ポート80および443のトラフィックを許可します。
 Nginxが起動されているかどうかを確認する方法は?
Apr 14, 2025 pm 12:48 PM
Nginxが起動されているかどうかを確認する方法は?
Apr 14, 2025 pm 12:48 PM
Linuxでは、次のコマンドを使用して、nginxが起動されるかどうかを確認します。SystemCTLステータスNGINXコマンド出力に基づいて、「アクティブ:アクティブ(実行)」が表示された場合、NGINXが開始されます。 「アクティブ:非アクティブ(dead)」が表示されると、nginxが停止します。
 Linuxでnginxを開始する方法
Apr 14, 2025 pm 12:51 PM
Linuxでnginxを開始する方法
Apr 14, 2025 pm 12:51 PM
Linuxでnginxを開始する手順:nginxがインストールされているかどうかを確認します。 systemctlを使用して、nginxを開始してnginxサービスを開始します。 SystemCTLを使用して、NGINXがシステムスタートアップでNGINXの自動起動を有効にすることができます。 SystemCTLステータスNGINXを使用して、スタートアップが成功していることを確認します。 Webブラウザのhttp:// localhostにアクセスして、デフォルトのウェルカムページを表示します。
 Nginxクロスドメインの問題を解決する方法
Apr 14, 2025 am 10:15 AM
Nginxクロスドメインの問題を解決する方法
Apr 14, 2025 am 10:15 AM
Nginxクロスドメインの問題を解決するには2つの方法があります。クロスドメイン応答ヘッダーの変更:ディレクティブを追加して、クロスドメイン要求を許可し、許可されたメソッドとヘッダーを指定し、キャッシュ時間を設定します。 CORSモジュールを使用します。モジュールを有効にし、CORSルールを構成して、ドメインクロスリクエスト、メソッド、ヘッダー、キャッシュ時間を許可します。
 nginxの実行ステータスを確認する方法
Apr 14, 2025 am 11:48 AM
nginxの実行ステータスを確認する方法
Apr 14, 2025 am 11:48 AM
nginxの実行ステータスを表示する方法は次のとおりです。PSコマンドを使用してプロセスステータスを表示します。 nginx configuration file /etc/nginx/nginx.confを表示します。 NGINXステータスモジュールを使用して、ステータスエンドポイントを有効にします。 Prometheus、Zabbix、Nagiosなどの監視ツールを使用します。
 nginxサーバーを開始する方法
Apr 14, 2025 pm 12:27 PM
nginxサーバーを開始する方法
Apr 14, 2025 pm 12:27 PM
NGINXサーバーを起動するには、異なるオペレーティングシステムに従って異なる手順が必要です。Linux/UNIXシステム:NGINXパッケージをインストールします(たとえば、APT-GetまたはYumを使用)。 SystemCtlを使用して、NGINXサービスを開始します(たとえば、Sudo SystemCtl Start NGinx)。 Windowsシステム:Windowsバイナリファイルをダウンロードしてインストールします。 nginx.exe実行可能ファイルを使用してnginxを開始します(たとえば、nginx.exe -c conf \ nginx.conf)。どのオペレーティングシステムを使用しても、サーバーIPにアクセスできます
 nginx304エラーを解く方法
Apr 14, 2025 pm 12:45 PM
nginx304エラーを解く方法
Apr 14, 2025 pm 12:45 PM
質問への回答:304変更されていないエラーは、ブラウザがクライアントリクエストの最新リソースバージョンをキャッシュしたことを示しています。解決策:1。ブラウザのキャッシュをクリアします。 2.ブラウザキャッシュを無効にします。 3.クライアントキャッシュを許可するようにnginxを構成します。 4.ファイル許可を確認します。 5.ファイルハッシュを確認します。 6. CDNまたは逆プロキシキャッシュを無効にします。 7。nginxを再起動します。
