

Windows や Office を直接使い始めることができ、大規模なモデル エージェントを使用したコンピューターの操作は非常に簡単です。

AI アシスタントの未来というと、「アイアンマン」シリーズの AI アシスタント、ジャービスをすぐに思い浮かべることができます。ジャーヴィスは映画の中で目覚ましい活躍を見せており、トニー・スタークの右腕であるだけでなく、先端技術とのコミュニケーションの架け橋でもあります。大型模型の登場により、人間の道具の使い方は革命的に変化しており、SFのシナリオにまた一歩近づいているのかもしれません。人間と同じように、キーボードとマウスを使って周囲のコンピュータを直接制御できるマルチモーダル エージェントを想像してみてください。この画期的な進歩は、どれほどエキサイティングなことでしょう。
AI Assistant Jarvis
吉林大学人工知能学部の最新研究「ScreenAgent」 : ビジョン言語モデル駆動のコンピュータ制御エージェント」は、視覚的な大規模言語モデルを使用してコンピュータ GUI を直接制御するという想像が現実になったことを示しています。この研究では、ScreenAgent モデルを提案しました。これは、追加のラベル支援を必要とせずに、VLM エージェントを介してコンピュータのマウスとキーボードを直接制御することを初めて検討し、大規模モデルの直接コンピュータ操作という目標を達成しました。さらに、ScreenAgent は、自動化された「計画、実行、反映」プロセスを使用して、初めて GUI インターフェイスの継続的な制御を実現します。この研究では、人間とコンピューターの対話方法を探索および革新し、データセット、コントローラー、正確な位置情報を含むトレーニング コードなどのリソースもオープンソース化します。

- 文書アドレス: https://arxiv.org/abs/2402.07945
- プロジェクト アドレス: https://github.com/niuzaisheng/ScreenAgent
ScreenAgent はユーザーです便利なオンラインエンターテイメント、ショッピング、旅行、読書体験を提供します。パソコンの管理や素早い作業を実現するパーソナルバトラーとしてもご利用いただけます。手間をかけずに強力なオフィスアシスタントになります。実際の効果を通じて、ユーザーはその機能を理解できます。
#インターネットをサーフィンして、エンターテイメントの自由を実現しましょう##ScreenAgent は、ユーザーに基づいて指定されたビデオをオンラインで検索して再生しますテキストの説明:
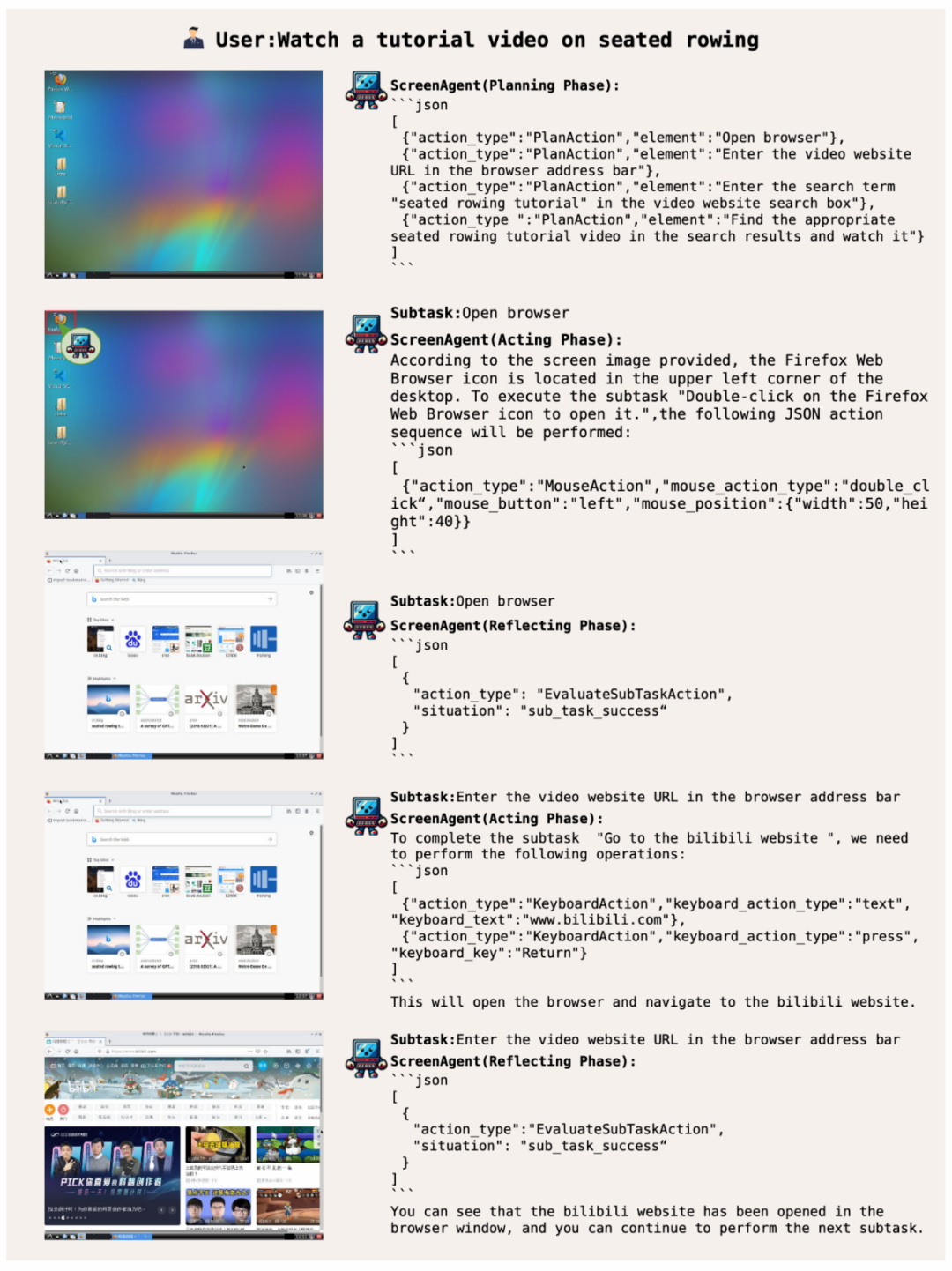
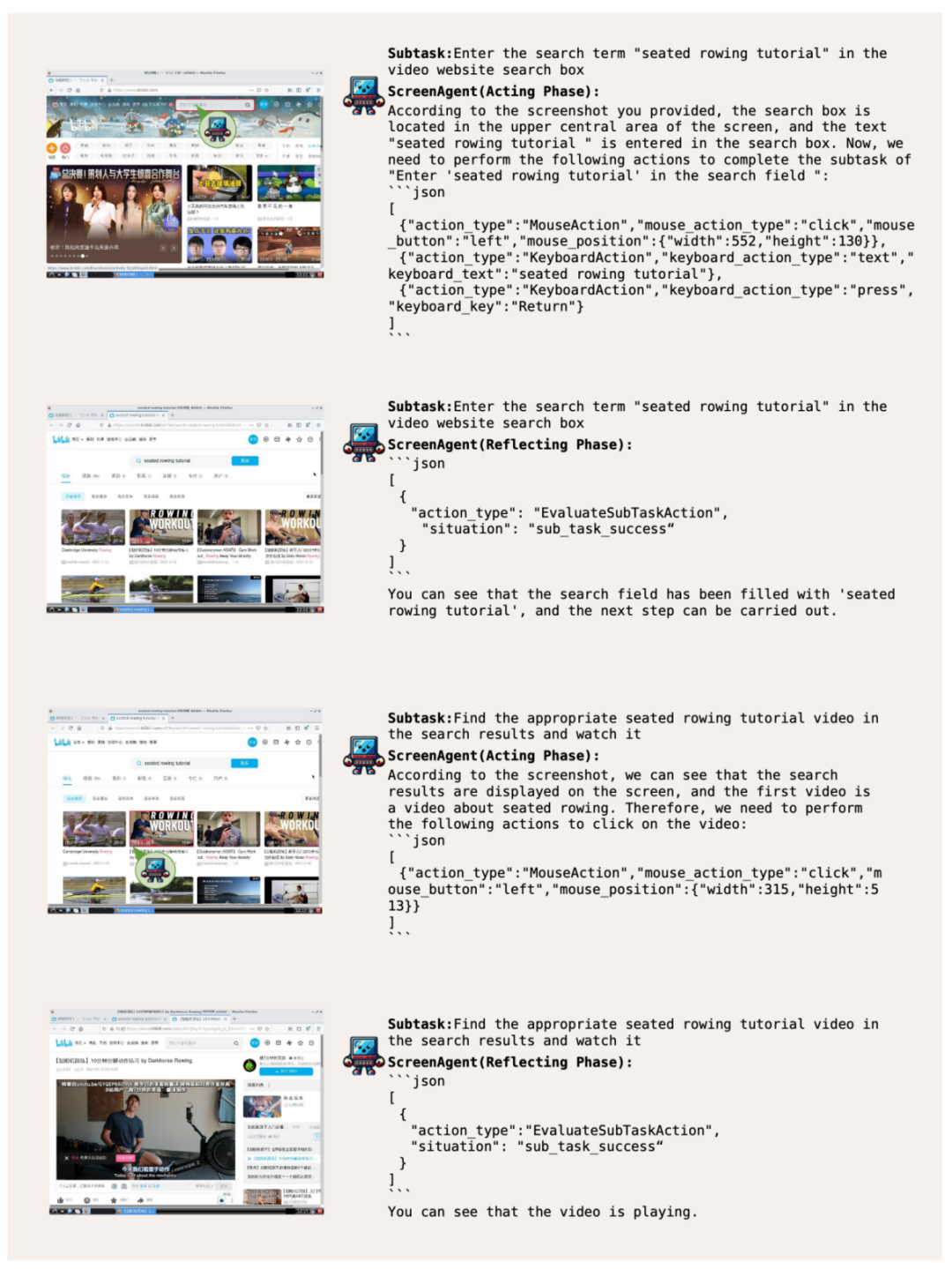 ユーザーに高度なスキルを提供するシステム運用マネージャー
ユーザーに高度なスキルを提供するシステム運用マネージャー
ScreenAgent で Windows イベント ビューアを開いてみましょう:
##オフィス スキルをマスターして、オフィスを簡単に操作しましょう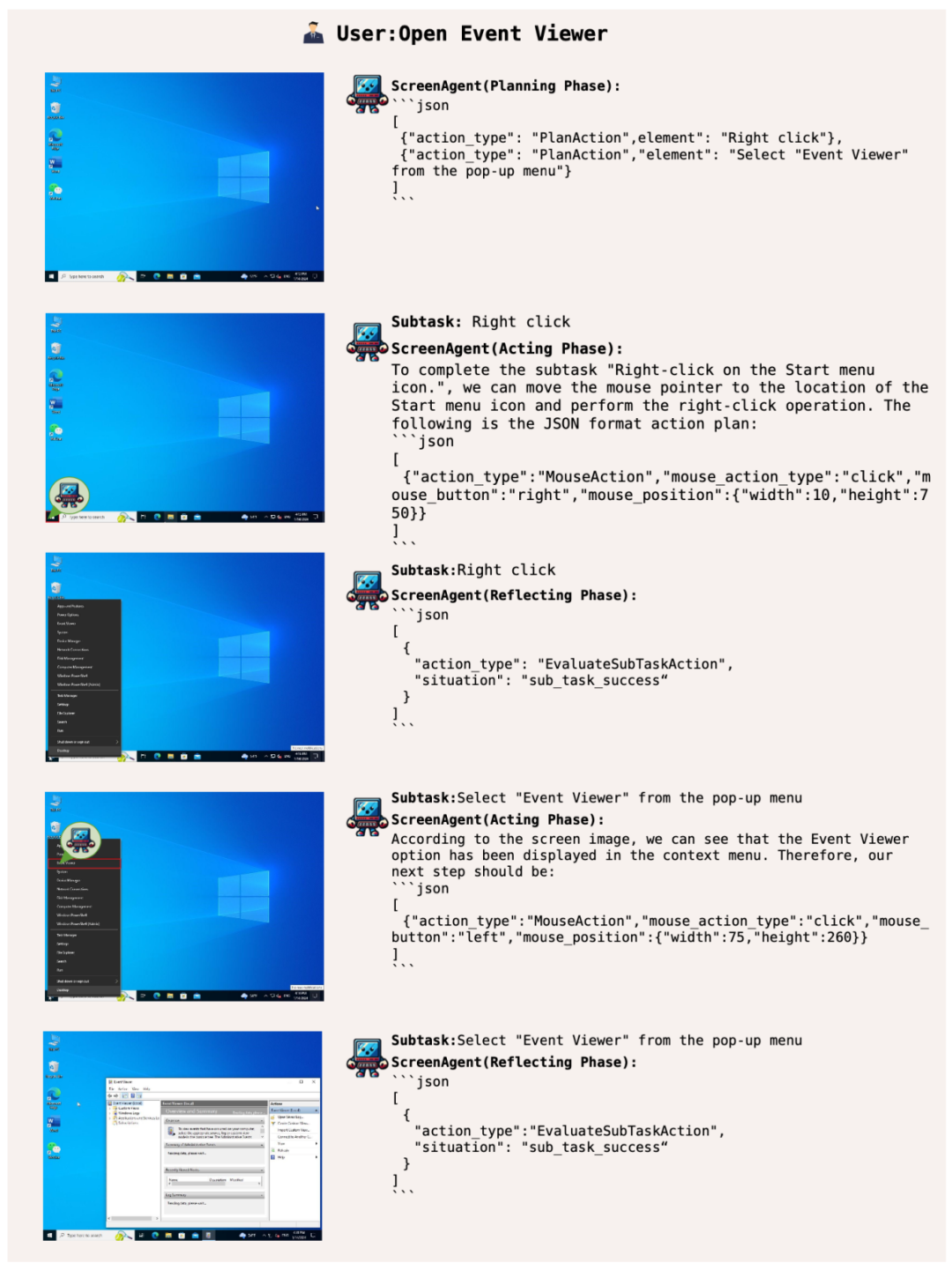
##また、ScreenAgent はオフィス ソフトウェアを使用できます。たとえば、ユーザーのテキスト説明に従って、開いた 2 ページ目の PPT を削除します。
行動を起こす前に計画を立ててください。どこで停止して利益を得るべきかを知る
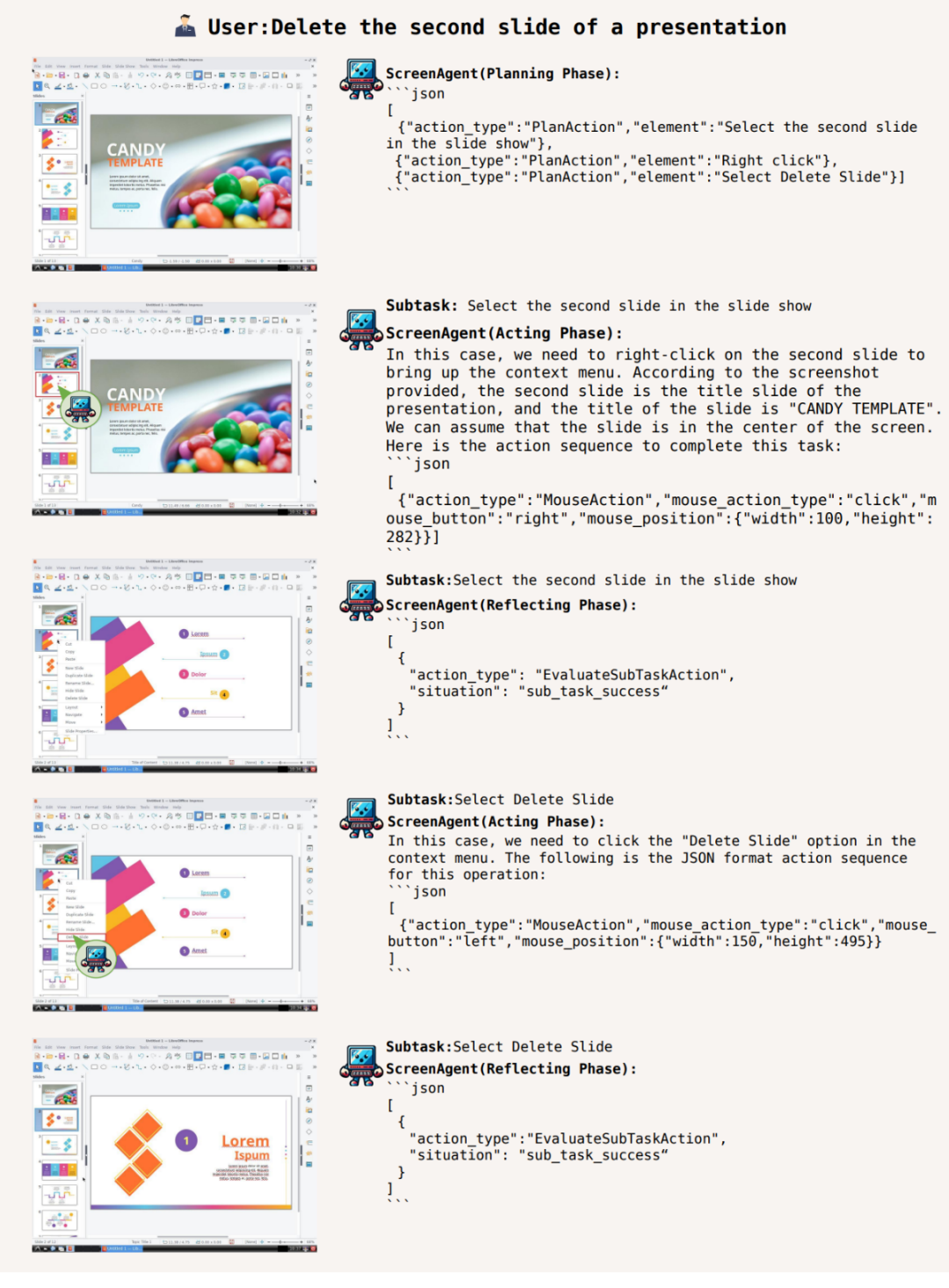
特定のタスクを完了するには、タスクを実行する前にアクティビティを計画する必要があります。 ScreenAgent は、タスクを開始する前に、観察された画像とユーザーのニーズに基づいて計画を立てることができます。例:
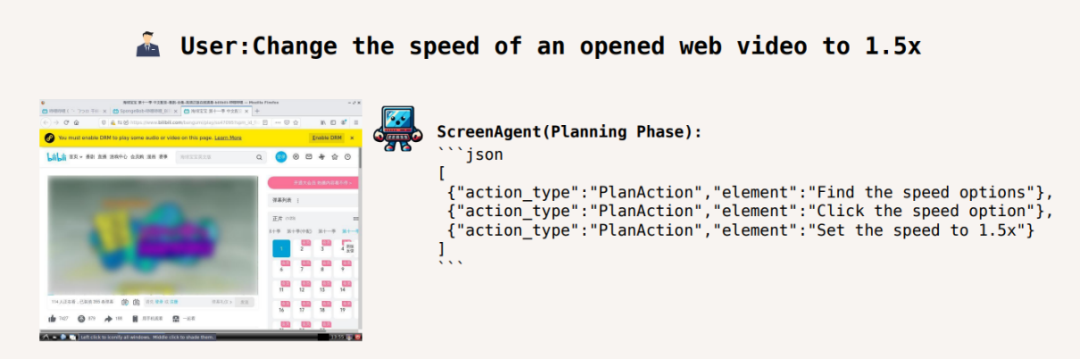
ビデオの再生速度を 1.5 倍に調整します:
# 58 市のウェブサイトでマゴタンの中古車の価格を検索してください:
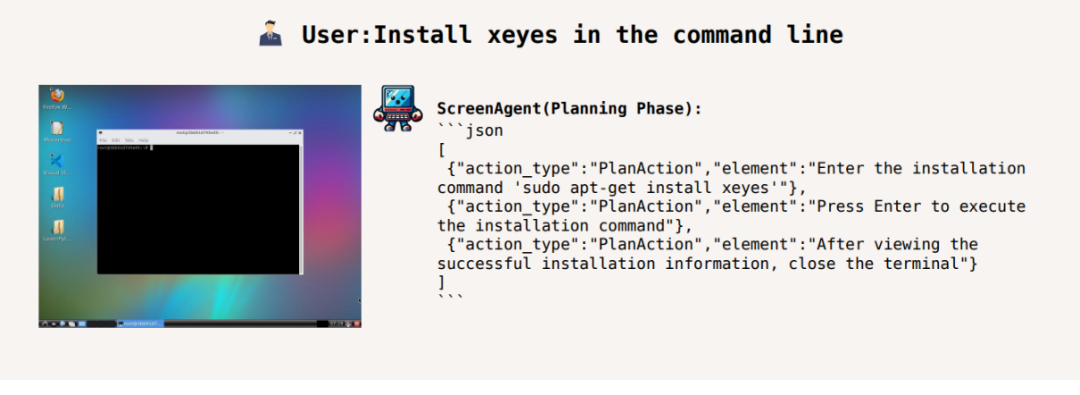
コマンドライン xeyes のインストール:

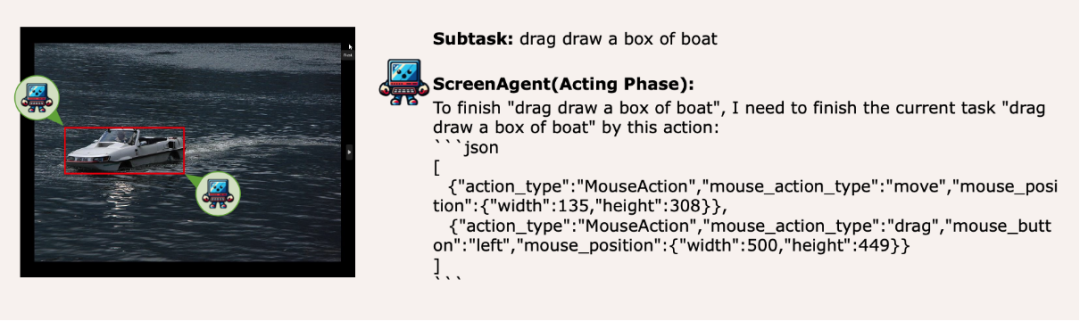
視覚的な位置決め機能の移行、マウス選択はストレスフリーです
ScreenAgent 也保留了對於自然事物的視覺定位能力,可以透過滑鼠拖曳的方式繪製出物體的選框:

##方法
事實上,要教會Agent 與使用者圖形介面直接互動並不是一件簡單的事情,需要Agent 同時具備任務規劃、影像理解、視覺定位、工具使用等多種綜合能力。現有的模型或交互方案都存在一定妥協,例如LLaVA-1.5 等模型缺乏在大尺寸圖像上的精確視覺定位能力;GPT-4V 有非常強的任務規劃、圖像理解和OCR 的能力,但是拒絕給出精確的座標。現有的方案需要在圖像上人工標註額外的數位標籤,並讓模型選擇需要點選的UI 元素,例如Mobile-Agent、UFO 等項目;此外,CogAgent、Fuyu-8B 等模型可以支援高解析度圖像輸入並有精確視覺定位能力,但是CogAgent 缺乏完整函數呼叫能力,Fuyu-8B 則語言能力不足。
為了解決上述問題,文章提出為視覺語言模型智能體(VLM Agent)建構一個與真實電腦螢幕互動的全新環境。在這個環境中,智能體可以觀察螢幕截圖,並透過輸出滑鼠和鍵盤操作來操縱圖形使用者介面。為了引導 VLM Agent 與電腦螢幕進行持續的交互,文章建構了一個包含「計畫-執行-反思」的運行流程。在計劃階段,Agent 被要求將使用者任務拆解為子任務。在執行階段,Agent 將觀察螢幕截圖,給出執行子任務的具體滑鼠和鍵盤動作。控制器將執行這些動作,並將執行結果回饋給 Agent。在反思階段,Agent 觀察執行結果,並判定目前的狀態,選擇繼續執行、重試或調整計畫。這項流程持續進行,直到任務完成。值得一提的是,ScreenAgent 不需要使用任何文字辨識或圖示辨識模組,使用端到端的方式訓練模型所有的能力。
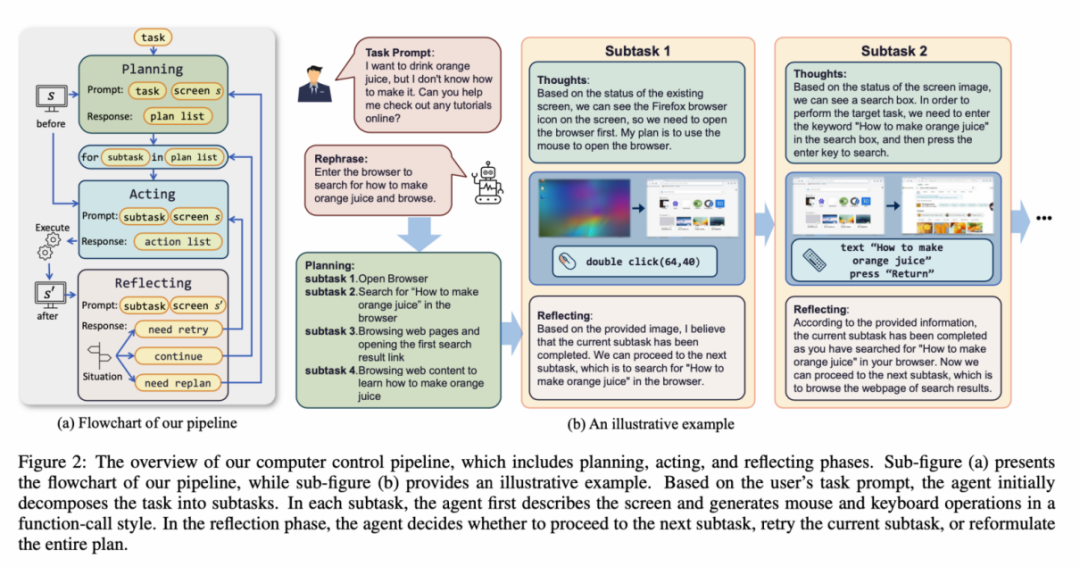
ScreenAgent 環境參考了VNC 遠端桌面連線協定來設計Agent 的動作空間,包含最基本的滑鼠和鍵盤操作,滑鼠的點擊操作都需要Agent 給出精確的螢幕座標位置。相較於呼叫特定的 API 來完成任務,這種方式更加通用,可以適用於各種 Windows、Linux Desktop 等桌面作業系統和應用程式。
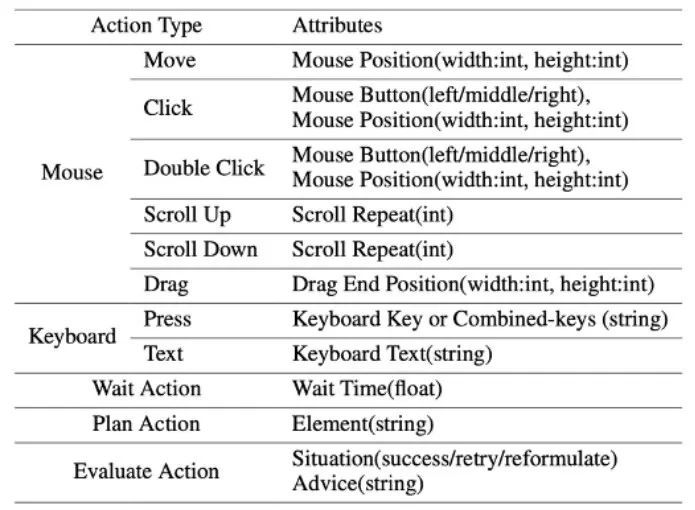
ScreenAgent 資料集
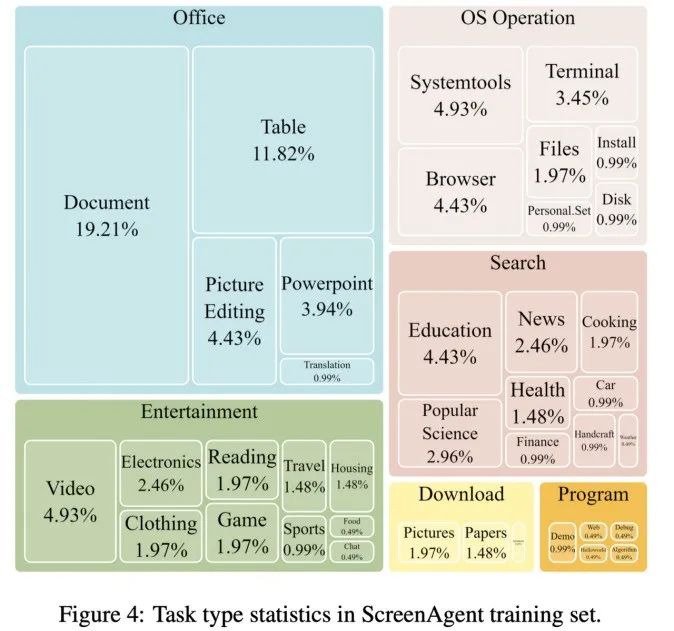
為了訓練ScreenAgent 模型,文章手動標註了具備精準視覺定位訊息的ScreenAgent 資料集。這個資料集涵蓋了豐富的日常電腦任務,包括了 Windows 和 Linux Desktop 環境下的檔案操作、網頁瀏覽、遊戲娛樂等場景。
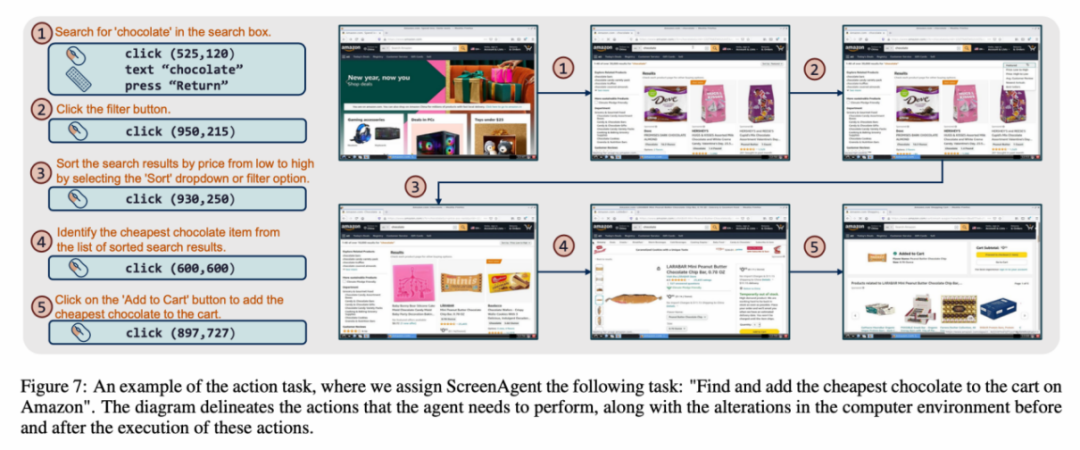
資料集中每一個樣本都是完成一個任務的完整流程,包含了動作描述、螢幕截圖和具體執行的動作。例如,在亞馬遜網站上「將最便宜的巧克力加入購物車」的案例,需要先在搜尋框中搜尋關鍵字,再使用過濾器對價格進行排序,最後將最便宜的商品加入購物車。整個資料集包含 273 筆完整的任務記錄。
實驗結果
#在實驗分析部分作者將ScreenAgent 與多個現有的VLM 模型從各個角度進行比較,主要包括兩個層面,指令跟隨能力和細粒度動作預測的正確率。指令跟隨能力主要考驗模型能否正確輸出 JSON 格式的動作序列和動作類型的正確率。而動作屬性預測的正確率則比較每種動作的屬性值是否預測正確,例如滑鼠點擊的位置、鍵盤按鍵等。
指令跟隨
##########################在指令跟隨方面,Agent 的首要任務就是能夠根據提示詞輸出正確的工具函數調用,即輸出正確的JSON 格式,在這方面ScreenAgent 與GPT-4V 都能夠很好的遵循指令,而原版的CogAgent 由於視覺微調訓練時缺乏API 呼叫形式的資料的支撐,反而喪失了輸出JSON 的能力。
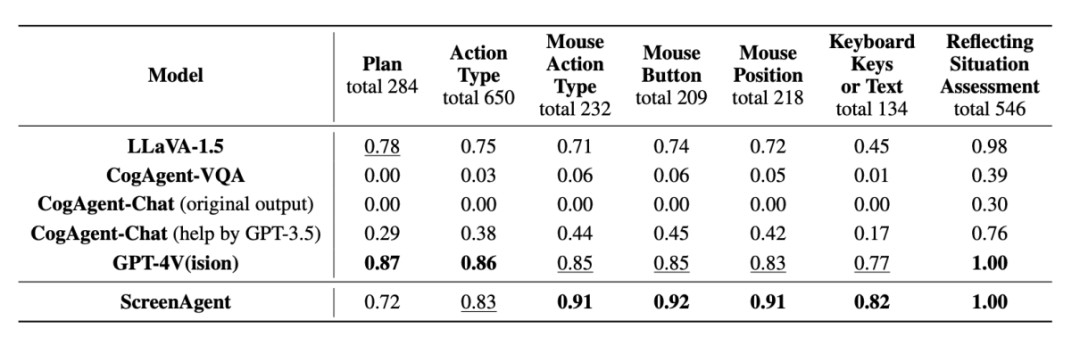
動作屬性預測的正確率
##從動作屬性的正確率來看,ScreenAgent 也達到了與GPT-4V 相當的水平。值得注意的是,ScreenAgent 在滑鼠點擊的精確度上遠遠超過了現有模型。這顯示視覺微調有效增強了模型的精確定位能力。此外,我們也觀察到 ScreenAgent 在任務規劃方面與 GPT-4V 相比有明顯差距,這凸顯了 GPT-4V 的常識知識和任務規劃能力。
#吉林大學人工智慧學院團隊提出的ScreenAgent 能夠採用與人類一樣的控制方式控制電腦,不依賴其他的API 或OCR 模型,可以廣泛應用於各種軟體和作業系統。 ScreenAgent 在「規劃-執行-反思」的流程控制下,可以自主地完成使用者給定的任務。採用這樣的方式,使用者可以看到任務完成的每一步,更能理解 Agent 的行為想法。
文章開源了控制軟體、模型訓練程式碼、以及資料集。在此基礎上可以探索更多邁向通用人工智慧的前沿工作,例如在環境回饋下的強化學習、Agent 對開放世界的主動探索、建立世界模型、Agent 技能庫等等。
此外,AI Agent 驅動的個人助理具有巨大的社會價值,例如幫助肢體受限的人群使用電腦,減少人類重複的數位勞動以及普及電腦教育等。在未來,或許不是每個人都能成為像鋼鐵人那樣的超級英雄,但我們都可能擁有一位專屬的賈維斯,一位可以陪伴、輔助和指導我們的智能夥伴,為我們的生活和工作帶來更多便利與可能。
以上がWindows や Office を直接使い始めることができ、大規模なモデル エージェントを使用したコンピューターの操作は非常に簡単です。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7486
7486
 15
1377
52
77
11
19
38
15
1377
52
77
11
19
38

 vscode で Word ドキュメントを表示する方法 vscode で Word ドキュメントを表示する方法
May 09, 2024 am 09:37 AM
vscode で Word ドキュメントを表示する方法 vscode で Word ドキュメントを表示する方法
May 09, 2024 am 09:37 AM
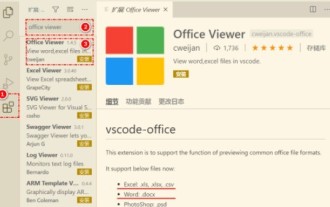
まず、コンピュータ上で vscode ソフトウェアを開き、図の①に示すように、左側の [拡張機能] アイコンをクリックし、図の②に示すように、拡張機能インターフェイスの検索ボックスに「officeviewer」と入力します。次に、図の③のように検索結果からインストールする「officeviewer」を選択し、最後に以下のようにdocxやpdfなどのファイルを開きます。
 WPS および Office には中国語フォントが含まれておらず、中国語フォント名は英語で表示されます。
Jun 19, 2024 am 06:56 AM
WPS および Office には中国語フォントが含まれておらず、中国語フォント名は英語で表示されます。
Jun 19, 2024 am 06:56 AM
友人のコンピュータでは、WPS や OFFICE で模倣 Song、Kai style、Xing Kai、Microsoft Yahei などの中国語フォントがすべて見つかりません。この問題の解決方法を説明します。システム内のフォントは正常ですが、WPS フォント オプションのすべてのフォントは利用できず、クラウド フォントのみが利用可能です。 OFFICE には英語フォントのみがあり、中国語フォントはありません。さまざまなバージョンの WPS をインストールすると、英語のフォントが利用可能になりますが、中国語のフォントも利用できません。解決策: [コントロール パネル] → [カテゴリ] → [時計、言語、および地域] → [表示言語の変更] → (地域と言語) [管理] → (非 Unicode プログラムの言語) [システム地域設定の変更] → [中国語 (簡体字、中国)] → [再起動]。コントロールパネル、右上隅の表示モードを「カテゴリ」に変更し、時計、言語、地域を変更します。
 Xiaomi Mi Pad 6シリーズがPCレベルのWPS Officeを完全版で発売
Apr 25, 2024 pm 09:10 PM
Xiaomi Mi Pad 6シリーズがPCレベルのWPS Officeを完全版で発売
Apr 25, 2024 pm 09:10 PM
4月25日のこのサイトのニュースによると、Xiaomiは本日、Xiaomi Mi Pad 6、Mi Pad 6 Pro、Mi Pad 6 Max 14、およびMi Pad 6 S ProがPCレベルのWPSOfficeを完全にサポートしたことを正式に発表しました。このうち、Xiaomi Mi Pad 6 Pro と Xiaomi Mi Pad 6 は、Xiaomi App Store から WPSOfficePC をダウンロードする前に、システム バージョンを V816.0.4.0 以降にアップグレードする必要があります。 WPSOfficePC はコンピュータと同じ操作とレイアウトを採用しており、タブレットのキーボード アクセサリと組み合わせることで、オフィスの効率を向上させることができます。このサイトの以前の評価経験によると、ドキュメント、フォーム、プレゼンテーション、その他のファイルを編集する場合、WPSOfficePC は大幅に効率的です。また、テキストレイアウトや画像挿入、
 3D レンダリング、コンピューター構成? 3D レンダリングを設計するにはどのようなコンピューターが必要ですか?
May 06, 2024 pm 06:25 PM
3D レンダリング、コンピューター構成? 3D レンダリングを設計するにはどのようなコンピューターが必要ですか?
May 06, 2024 pm 06:25 PM
3D レンダリング、コンピューター構成? 1 3D レンダリングにはコンピュータの構成が非常に重要であり、レンダリングの効果と速度を確保するには十分なハードウェア パフォーマンスが必要です。 23D レンダリングには多くの計算と画像処理が必要なため、高性能の CPU、グラフィックス カード、メモリが必要です。 3 より高度な 3D レンダリングのニーズを満たすために、少なくとも 6 コアおよび 12 スレッドの CPU、16 GB 以上のメモリ、および高性能グラフィックス カードを備えたコンピュータを少なくとも 1 台構成することをお勧めします。同時に、コンピューターの安定した動作を確保するために、コンピューターの放熱と電源構成にも注意を払う必要があります。 3D レンダリングを設計するにはどのようなコンピューターが必要ですか?私はデザイナーでもあるので、一連の構成を提供します (もう一度使用します) CPU: 6 コアの amd960t (または直接オーバークロックされた 1090t) メモリ: 1333
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
何?ズートピアは国産AIによって実現するのか?ビデオとともに公開されたのは、「Keling」と呼ばれる新しい大規模な国産ビデオ生成モデルです。 Sora も同様の技術的ルートを使用し、自社開発の技術革新を多数組み合わせて、大きく合理的な動きをするだけでなく、物理世界の特性をシミュレートし、強力な概念的結合能力と想像力を備えたビデオを制作します。データによると、Keling は、最大 1080p の解像度で 30fps で最大 2 分の超長時間ビデオの生成をサポートし、複数のアスペクト比をサポートします。もう 1 つの重要な点は、Keling は研究所が公開したデモやビデオ結果のデモンストレーションではなく、ショートビデオ分野のリーダーである Kuaishou が立ち上げた製品レベルのアプリケーションであるということです。さらに、主な焦点は実用的であり、白紙小切手を書かず、リリースされたらすぐにオンラインに移行することです。Ke Ling の大型モデルは Kuaiying でリリースされました。
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
