

ステーション B については皆さんよくご存知だと思います。実際、ステーション B のクローラー Web サイトには多くの検索結果があります。ただ、紙で読んだことは所詮浅くて、詳しくやらなければいけないことは確かに分かっているのでここにいます。最終的に、クロールされたデータの総量は 760 万 アイテムでした。
######準備######まずステーション B を開き、ホームページでビデオを見つけてクリックします。通常の操作を行うには、開発者ツールを開きます。今回の目的は、Web ページを解析せずにステーション B が提供する API をクローリングしてビデオ情報を取得することですが、Web ページの解析速度が遅すぎて、IP アドレスがブロックされやすくなります。 JS オプションをチェックし、F5 キーを押して更新します
API アドレスが見つかりました
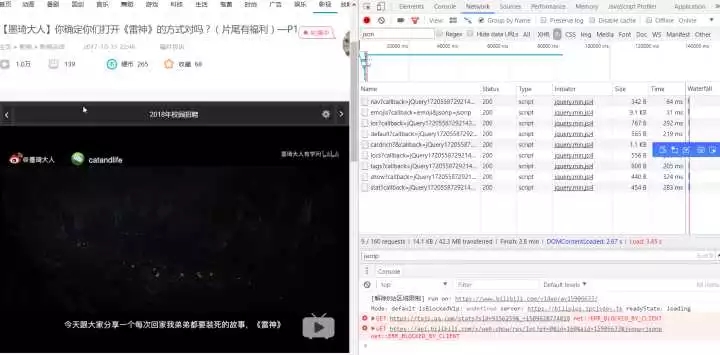
それをコピーし、不要なコンテンツを削除して、https://api.bilibili.com/x/web-interface/archive/stat?aid=15906633
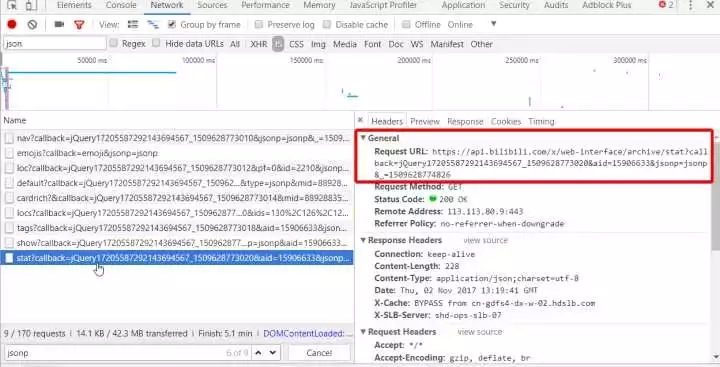 を取得し、ブラウザで開くと、次のjsonデータを取得します
を取得し、ブラウザで開くと、次のjsonデータを取得します
実践的なコーディング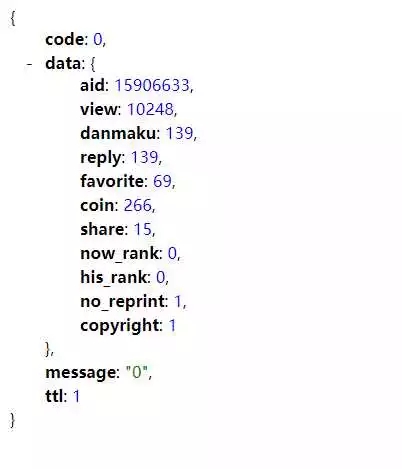
わかりました。コードはここにコーディングできます。データはリクエストの継続的な反復を通じて取得されます。クローラをより効率的にするために、マルチスレッドを使用できます。
コアコード
反復クロール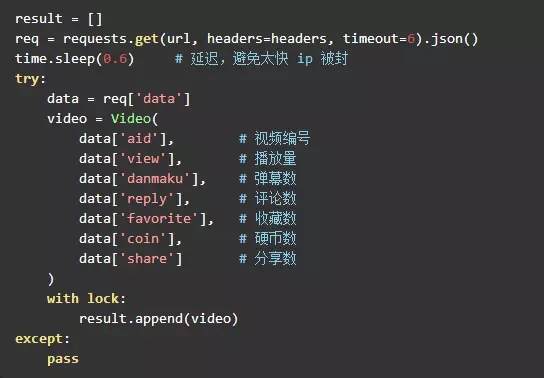
プロジェクト全体の中で最も重要な部分は約 20 行のコードであり、非常に簡潔です。
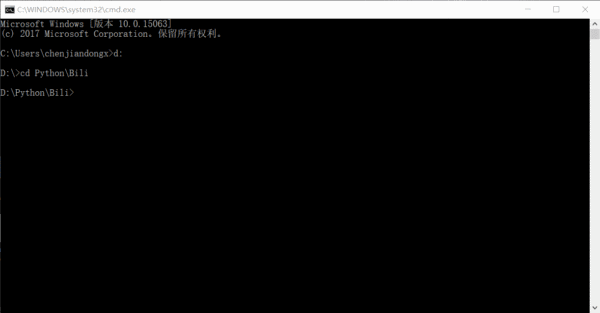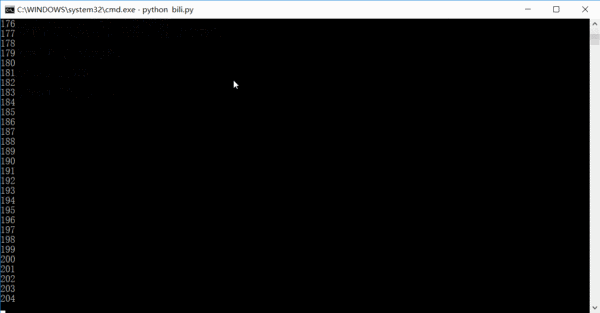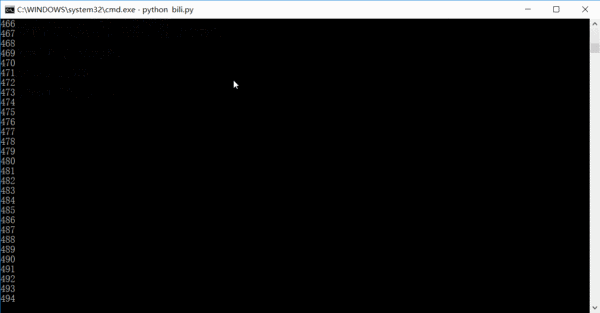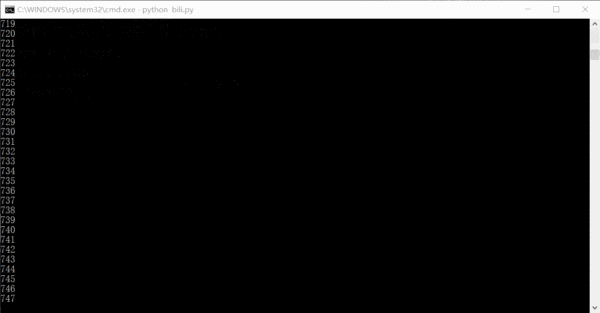
 実行効果はおおよそ次のようになります。数字はクロールされたリンクの数です。実際には、サイト全体の情報は 1 ~ 2 日でクロールできます。
実行効果はおおよそ次のようになります。数字はクロールされたリンクの数です。実際には、サイト全体の情報は 1 ~ 2 日でクロールできます。
クロール後の処理は好みによりますが、まずはcsvファイルで保存し、それをまとめてデータベースに挿入します。
このコンテンツを数か月前にクロールして以来、データは実際に遅れています。
トップ 10 のビデオをクエリする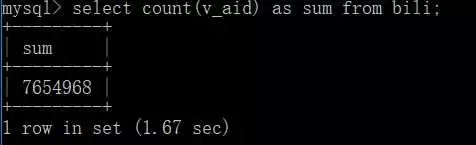
返信が多かったトップ 10 の動画をチェックしてください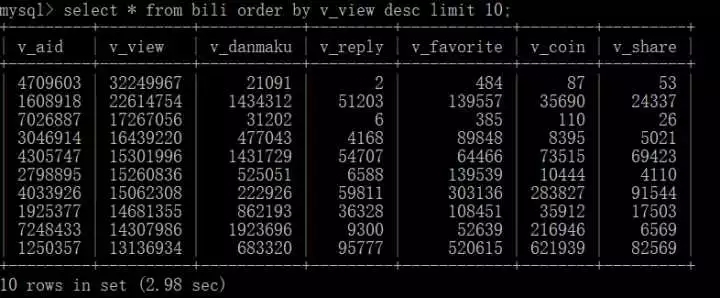
以上がPython を使用してステーション B のビデオ情報全体をクロールします。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



