

NLP の大規模モデルを時系列に適用するにはどうすればよいですか? 5つのカテゴリーに分けた方法をまとめました!

最近、カリフォルニア大学は、自然言語処理の分野で事前トレーニングされた大規模言語モデルを時系列予測に適用する方法を探るレビュー記事を発表しました。この記事では、時系列分野における 5 つの異なる NLP 大規模モデルの適用について要約します。次に、このレビューで取り上げた 5 つの方法を簡単に紹介します。
 図
図
論文タイトル: 時系列のための大規模言語モデル: 調査
ダウンロード アドレス: https://arxiv.org /pdf/2402.01801.pdf
 図
図
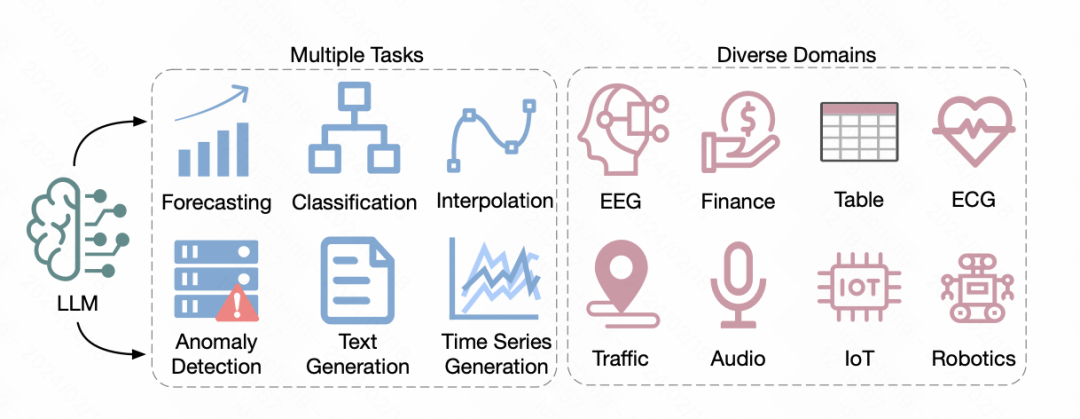
1. プロンプトベースのメソッド
プロンプトメソッドを直接使用することで、モデルはターゲットを絞ることができます。予測出力の時系列データ。以前のプロンプト メソッドの基本的な考え方は、プロンプト テキストを事前トレーニングし、それを時系列データで満たし、モデルに予測結果を生成させることでした。たとえば、時系列タスクを説明するテキストを作成する場合、時系列データを入力し、モデルに予測結果を直接出力させます。
 写真
写真
時系列を処理する場合、数値はテキストの一部としてみなされることが多く、数値のトークン化の問題も大きな注目を集めています。いくつかの方法では、数値をより明確に区別し、辞書内の数値間の不合理な区別を避けるために、数値の間にスペースを特別に追加します。
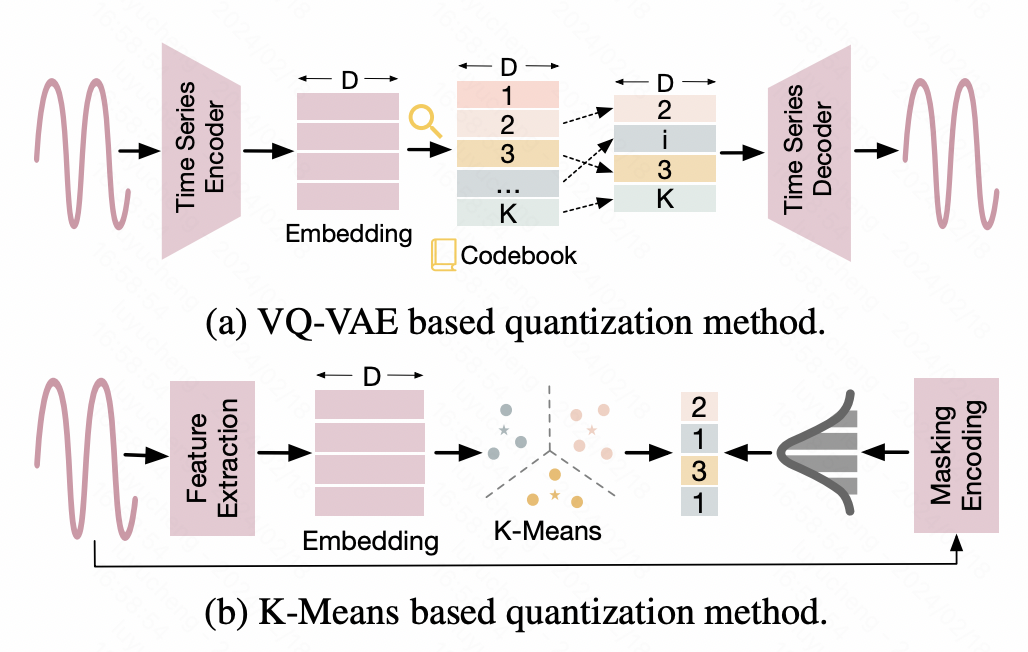
2. 離散化
このタイプのメソッドは、時系列を離散化し、連続値を離散 ID 結果に変換して、大規模な NLP モデルの入力形式に適応させます。たとえば、1 つのアプローチは、ベクトル量子化変分オートエンコーダー (VQ-VAE) テクノロジーを利用して、時系列を離散表現にマッピングすることです。 VQ-VAE は VAE に基づいたオートエンコーダ構造であり、VAE はエンコーダを通じて元の入力を表現ベクトルにマッピングし、デコーダを通じて元のデータを復元します。 VQ-VAE は、中間生成された表現ベクトルが確実に離散化されるようにします。この離散化表現ベクトルに基づいて辞書が構築され、時系列データの離散化マッピングが実現されます。もう 1 つの方法は、K 平均法による離散化に基づいており、K 平均法によって生成された重心を使用して元の時系列を離散化します。さらに、一部の作業では、時系列もテキストに直接変換されます。たとえば、一部の金融シナリオでは、毎日の価格上昇、価格下落、その他の情報が、大規模な NLP モデルへの入力として、対応する文字記号に直接変換されます。
 図
図
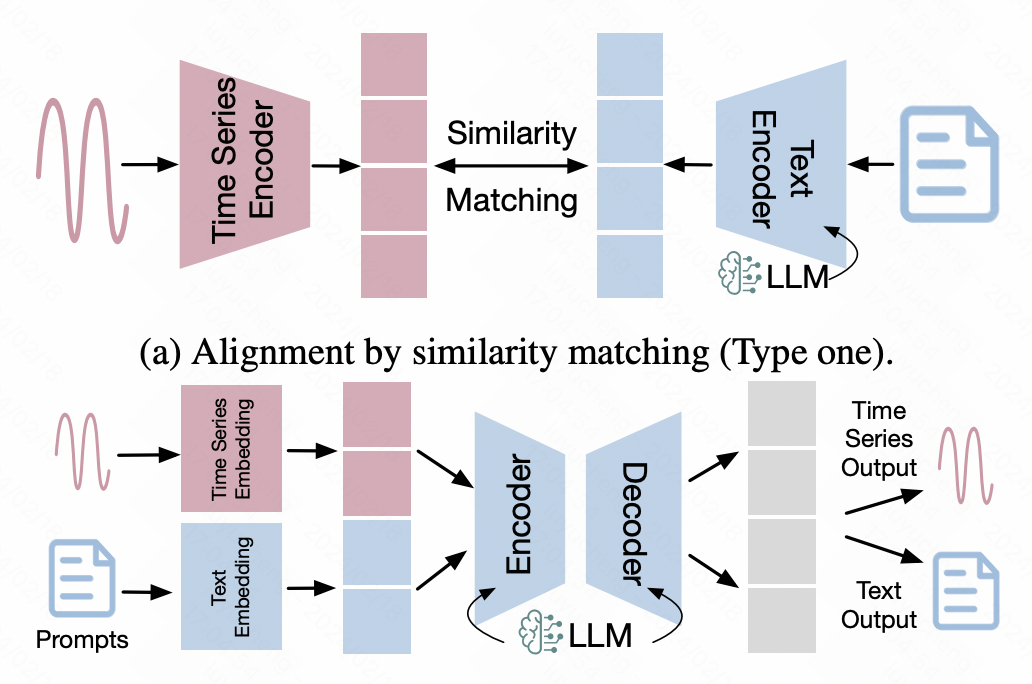
3. 時系列テキストの配置
このタイプの方法は、マルチモーダル フィールドの配置テクノロジに依存しています。時間を結合する シーケンスの表現がテキスト空間に合わせて配置されるため、時系列データを大規模な NLP モデルに直接入力するという目標が達成されます。
このタイプの方法では、いくつかのマルチモーダル位置合わせ方法が広く使用されています。最も代表的なのは対比学習によるマルチモーダルアライメントであり、CLIPと同様に、時系列エンコーダと大規模モデルをそれぞれ時系列とテキストの表現ベクトルとして入力し、対比学習により距離を縮める手法である。ポジティブサンプルペア間の潜在空間における時系列とテキストデータの表現の位置合わせ。
もう 1 つの方法は、NLP 大規模モデルをバックボーンとして使用し、これに基づいて追加のネットワーク適応時系列データを導入する、時系列データに基づいた微調整です。その中でも、LoRA などの効率的なクロスモーダル微調整手法は比較的一般的であり、バックボーンのほとんどのパラメータを凍結して少数のパラメータのみを微調整するか、微調整用の少数のアダプタ パラメータを導入してマルチモーダル アライメントを実現します。
 写真
写真
4. 視覚情報の導入
この方法は比較的まれで、通常は時系列と視覚情報の間の接続を確立します。次に、画像とテキストを使用して詳細に研究されたマルチモーダル機能が導入され、下流のタスクに効果的な特徴が抽出されます。たとえば、ImageBind は時系列型データを含む 6 つのモダリティのデータを均一に整列させ、大規模なマルチモーダル モデルの統合を実現します。金融分野の一部のモデルは、株価をチャート データに変換し、CLIP を使用して画像とテキストを配置し、下流の時系列タスク用のチャート関連機能を生成します。
5. 大規模モデル ツール
このタイプの方法は、NLP 大規模モデルを改善したり、大規模モデルに適応させるために時系列データ形式を変換したりするのではなく、NLP 大規模モデルを解決のためのツールとして直接扱います。時系列の問題。たとえば、大規模モデルで時系列予測を解決するコードを生成し、それを時系列予測に適用したり、大規模モデルでオープン ソース API を呼び出して時系列問題を解決したりできます。もちろん、この方法は実用的なアプリケーションに偏っています。
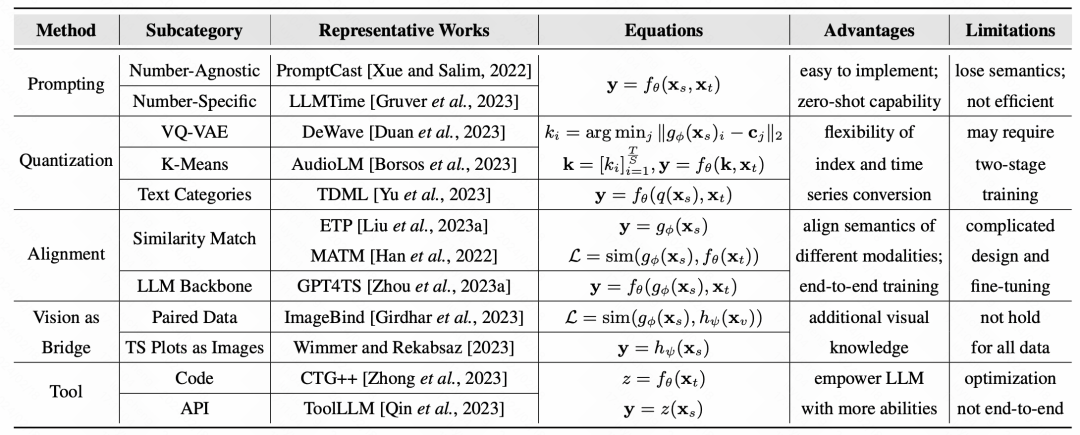
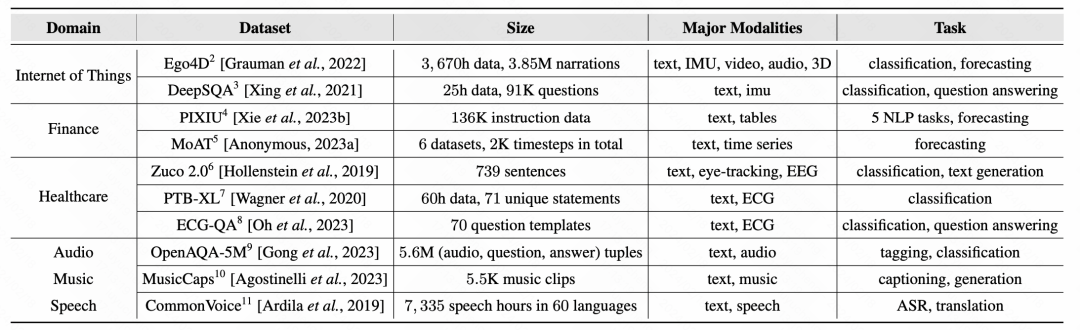
最後に、この記事では、さまざまな手法の代表的な研究と代表的なデータセットを要約します:
 写真
写真
 写真##################
写真##################
以上がNLP の大規模モデルを時系列に適用するにはどうすればよいですか? 5つのカテゴリーに分けた方法をまとめました!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
5月30日、TencentはHunyuanモデルの包括的なアップグレードを発表し、Hunyuanモデルに基づくアプリ「Tencent Yuanbao」が正式にリリースされ、AppleおよびAndroidアプリストアからダウンロードできるようになりました。前のテスト段階のフンユアン アプレット バージョンと比較して、Tencent Yuanbao は、日常生活シナリオ向けの AI 検索、AI サマリー、AI ライティングなどのコア機能を提供し、Yuanbao のゲームプレイもより豊富で、複数の機能を提供します。 、パーソナルエージェントの作成などの新しいゲームプレイ方法が追加されます。 Tencent Cloud 副社長で Tencent Hunyuan 大型モデルの責任者である Liu Yuhong 氏は、「テンセントは、最初に大型モデルを開発しようとはしません。」と述べました。 Tencent Hunyuan の大型モデルは、ビジネス シナリオにおける豊富で大規模なポーランド テクノロジーを活用しながら、ユーザーの真のニーズを洞察します。
 Bytedance Beanbao 大型モデルがリリース、Volcano Engine フルスタック AI サービスが企業のインテリジェントな変革を支援
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao 大型モデルがリリース、Volcano Engine フルスタック AI サービスが企業のインテリジェントな変革を支援
Jun 05, 2024 pm 07:59 PM
Volcano Engine の社長である Tan Dai 氏は、大規模モデルを実装したい企業は、モデルの有効性、推論コスト、実装の難易度という 3 つの重要な課題に直面していると述べました。複雑な問題を解決するためのサポートとして、適切な基本的な大規模モデルが必要です。また、サービスは低コストの推論を備えているため、大規模なモデルを広く使用できるようになり、企業がシナリオを実装できるようにするためには、より多くのツール、プラットフォーム、アプリケーションが必要になります。 ——Huoshan Engine 01 社長、Tan Dai 氏。大きなビーンバッグ モデルがデビューし、頻繁に使用されています。モデル効果を磨き上げることは、AI の実装における最も重要な課題です。 Tan Dai 氏は、良いモデルは大量に使用することでのみ磨かれると指摘しました。現在、Doubao モデルは毎日 1,200 億トークンのテキストを処理し、3,000 万枚の画像を生成しています。企業による大規模モデルシナリオの実装を支援するために、バイトダンスが独自に開発した豆包大規模モデルが火山を通じて打ち上げられます。
 時系列予測 NLP 大規模モデルの新機能: 時系列予測の暗黙的なプロンプトを自動的に生成
Mar 18, 2024 am 09:20 AM
時系列予測 NLP 大規模モデルの新機能: 時系列予測の暗黙的なプロンプトを自動的に生成
Mar 18, 2024 am 09:20 AM
今日は、時系列予測のパフォーマンスを向上させるために、時系列データを潜在空間上の大規模な自然言語処理 (NLP) モデルと整合させる方法を提案するコネチカット大学の最近の研究成果を紹介したいと思います。この方法の鍵は、潜在的な空間ヒント (プロンプト) を使用して時系列予測の精度を高めることです。論文タイトル: S2IP-LLM: SemanticSpaceInformedPromptLearningwithLLMforTimeSeriesForecasting ダウンロードアドレス: https://arxiv.org/pdf/2403.05798v1.pdf 1. 大きな問題の背景モデル
 Shengteng AI テクノロジーを使用した秦嶺・秦川交通モデルは、西安のスマート交通イノベーション センターの構築を支援します
Oct 15, 2023 am 08:17 AM
Shengteng AI テクノロジーを使用した秦嶺・秦川交通モデルは、西安のスマート交通イノベーション センターの構築を支援します
Oct 15, 2023 am 08:17 AM
「高度な複雑性、高度な断片化、およびクロスドメイン」は、輸送業界のデジタル化およびインテリジェントなアップグレードに向かう上で常に主要な問題点でした。最近、チャイナビジョン、西安雁塔区政府、西安未来人工知能コンピューティングセンターが共同で構築したパラメータースケール1000億の「秦嶺・秦川交通モデル」は、スマート交通・交通分野を指向している。西安とその周辺地域にサービスを提供しており、この地域はスマート交通イノベーションの拠点となるでしょう。 「秦嶺・秦川交通モデル」は、オープンシナリオにおける西安の膨大な地元交通生態データ、中国科学ビジョンが自社開発したオリジナルの高度なアルゴリズム、そして西安未来人工知能コンピューティングセンターのShengteng AIの強力なコンピューティング能力を組み合わせたものです。道路網の監視を提供するため、緊急指令、メンテナンス管理、公共交通機関などのスマートな交通シナリオは、デジタルでインテリジェントな変化をもたらします。交通管理には都市ごとに異なる特徴があり、道路の交通状況も異なります。
 NVIDIA の大規模モデル推論フレームワークを明らかにする: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
NVIDIA の大規模モデル推論フレームワークを明らかにする: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. TensorRT-LLM の製品位置付け TensorRT-LLM は、NVIDIA が開発した大規模言語モデル (LLM) 向けのスケーラブルな推論ソリューションです。 TensorRT 深層学習コンパイル フレームワークに基づいて計算グラフを構築、コンパイル、実行し、FastTransformer の効率的なカーネル実装を利用します。さらに、デバイス間の通信には NCCL を利用します。開発者は、カットラスに基づいてカスタマイズされた GEMM を開発するなど、技術開発や需要の違いに基づいて特定のニーズを満たすためにオペレーターをカスタマイズできます。 TensorRT-LLM は、NVIDIA の公式推論ソリューションであり、高いパフォーマンスを提供し、実用性を継続的に向上させることに尽力しています。 TensorRT-LL
 GPT-4をベンチマーク!中国移動の九天大型モデルが二重登録を通過
Apr 04, 2024 am 09:31 AM
GPT-4をベンチマーク!中国移動の九天大型モデルが二重登録を通過
Apr 04, 2024 am 09:31 AM
4月4日のニュースによると、中国サイバースペース局は最近、登録された大型モデルのリストを発表し、その中にチャイナモバイルの「九天自然言語インタラクション大型モデル」が含まれており、チャイナモバイルの九天AI大型モデルが生成人工言語を正式に提供できることを示した。外部世界への諜報機関。チャイナモバイルは、これは中央企業が開発した初めての大規模モデルであり、国家の「生成人工知能サービス登録」と「国内深層合成サービスアルゴリズム登録」の二重登録を通過したと述べた。報告によると、Juiutian の自然言語インタラクション大規模モデルは、強化された業界能力、セキュリティ、信頼性の特徴を持ち、フルスタック ローカリゼーションをサポートしており、90 億、139 億、570 億、1000 億などのさまざまなパラメータ バージョンを形成しており、クラウド、エッジ、エンドでは状況が異なりますが、柔軟に導入できます。
 産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
1. 背景の紹介 まず、Yunwen Technology の開発の歴史を紹介します。 Yunwen Technology Company ...2023 年は大規模モデルが普及する時期であり、多くの企業は大規模モデルの後、グラフの重要性が大幅に低下し、以前に検討されたプリセット情報システムはもはや重要ではないと考えています。しかし、RAG の推進とデータ ガバナンスの普及により、より効率的なデータ ガバナンスと高品質のデータが民営化された大規模モデルの有効性を向上させるための重要な前提条件であることがわかり、ますます多くの企業が注目し始めています。知識構築関連コンテンツへ。これにより、知識の構築と処理がより高いレベルに促進され、探索できる技術や方法が数多く存在します。新しいテクノロジーの出現によってすべての古いテクノロジーが打ち破られるわけではなく、新旧のテクノロジーが統合される可能性があることがわかります。
 新しいテストベンチマークがリリース、最も強力なオープンソースのLlama 3が困惑
Apr 23, 2024 pm 12:13 PM
新しいテストベンチマークがリリース、最も強力なオープンソースのLlama 3が困惑
Apr 23, 2024 pm 12:13 PM
テストの問題が簡単すぎると、上位の生徒も下位の生徒も 90 点を獲得でき、その差は広がりません。Claude3、Llama3、さらには GPT-5 などのより強力なモデルが後にリリースされるため、業界はより困難で差別化されたモデルのベンチマークが緊急に必要です。大型モデルアリーナの背後にある組織 LMSYS は、次世代ベンチマーク Arena-Hard を発表し、広く注目を集めました。 Llama3 命令の 2 つの微調整されたバージョンの強度に関する最新のリファレンスもあります。全員が同様のスコアを持っていた以前の MTBench と比較すると、アリーナとハードの識別は 22.6% から 87.4% に増加し、一目で強くも弱くもなりました。 Arena-Hard は、アリーナからのリアルタイムの人間データを使用して構築されており、人間の好みとの一致率は 89.1% です。
