

Sora がビデオ生成を爆発させると、Meta は中国人作家の主導で、Agent を使用してビデオを自動的にカットし始めました。

最近、AIビデオ技術の分野が注目を集めており、特にOpenAIが発表したSoraビデオ生成大型モデルは大きな話題を呼んでいます。一方、ビデオ編集の分野でも、Agentなどの大規模AIモデルが強い力を発揮しています。
ビデオ編集作業には自然言語が使用されますが、ユーザーは手動操作なしで直接意図を表現できます。しかし、現在のビデオ編集ツールのほとんどは依然として多くの手動操作を必要とし、パーソナライズされた状況に応じたサポートが不足しています。その結果、ユーザーは複雑なビデオ編集の問題を自分で解決する必要があります。
重要なのは、共同編集者として機能し、編集プロセス中にユーザーを継続的に支援できるビデオ編集ツールをどのように設計するかです。この記事では、トロント大学メタ (Reality Labs Research) とカリフォルニア大学サンディエゴ校の研究者が、大規模言語モデル (LLM) の多機能言語機能をビデオ編集に使用し、将来を探ることを提案しています。ビデオ編集パラダイムを活用し、手動のビデオ編集プロセスでのフラストレーションを軽減します。

- #論文タイトル: LAVE: LLM を活用したビデオ編集のためのエージェント支援と言語拡張
- 論文アドレス: https://arxiv.org/pdf/2402.10294.pdf
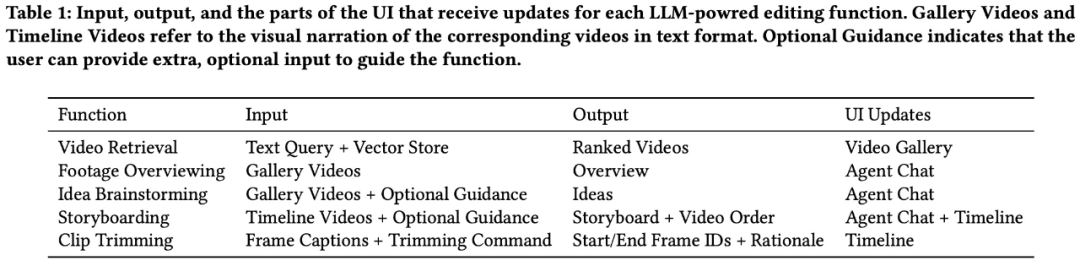
研究者は、LAVE と呼ばれるビデオ編集ツールを開発しました。 LLM。 LAVE は、LLM に基づくインテリジェントな計画および実行システムを導入しています。これは、ユーザーの自由形式の言語命令を解釈し、ユーザーのビデオ編集目標を達成するために関連する操作を計画および実行できます。このインテリジェント システムは、創造的なブレーンストーミングやビデオ映像の概要などの概念的な支援と、セマンティックベースのビデオ検索、ストーリーボード作成、クリップのトリミングなどの操作上の支援を提供します。
これらのエージェントをスムーズに操作するために、LAVE は視覚言語モデル (VLM) を使用してビデオ視覚効果の言語記述を自動的に生成します。これらの視覚的なナラティブにより、LLM はビデオ コンテンツを理解し、言語機能を使用してユーザーの編集を支援できます。さらに、LAVE は、エージェント支援と直接操作という 2 つのインタラクティブなビデオ編集モードを提供します。このデュアル モードにより、ユーザーは必要に応じてエージェントの操作をより柔軟に改善できます。
LAVE の編集効果については?研究者らは、初心者と経験豊富な編集者を含む 8 人の参加者を対象にユーザー調査を実施しました。その結果、参加者は LAVE を使用して満足のいく AI コラボレーション ビデオを作成できることがわかりました。
この研究の著者 6 人のうち 5 人が中国人であることは注目に値します。筆頭著者の Bryan Wang 氏は、トロント大学メタリサーチのコンピューターサイエンスの博士課程の学生です。科学者のYuliang Li、Zhaoyang Lv、Yan Xu、およびカリフォルニア大学サンディエゴ校の助教授Haijun Xia。
LAVE ユーザー インターフェイス (UI)
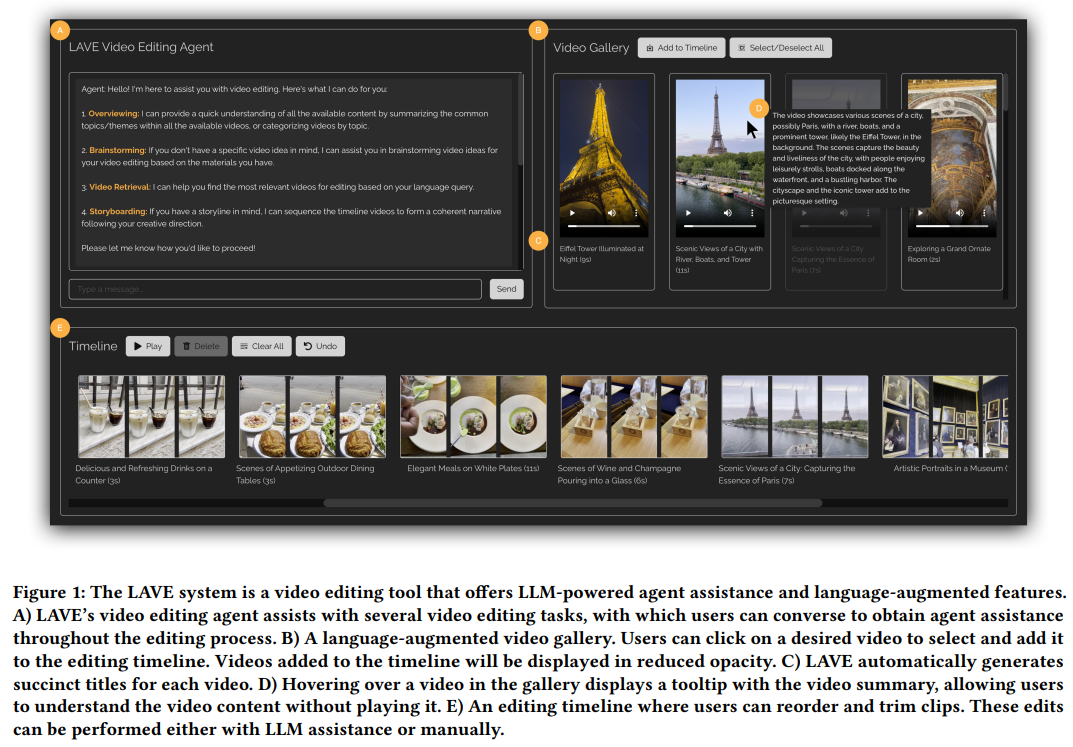
まず、以下の図 1 に示すように、LAVE のシステム設計を見てみましょう。
LAVE のユーザー インターフェイスは、次の 3 つの主要コンポーネントで構成されています。
- 自動生成されたビデオ クリップとともに表示される、言語が強化されたビデオ ライブラリ言語で説明;
- ビデオ クリッピング タイムライン (編集用のメイン タイムラインを含む);
- ビデオ クリッピング エージェント。ユーザーは、会話エージェントを利用してサポートを受けてください。
#設計ロジックは次のとおりです。ユーザーがエージェントと対話すると、メッセージ交換がチャット UI に表示されます。その際、エージェントはビデオ ライブラリとクリップ タイムラインに変更を加えます。さらに、ユーザーは従来の編集インターフェイスと同様に、カーソルを使用してビデオ ライブラリとタイムラインを直接操作できます。
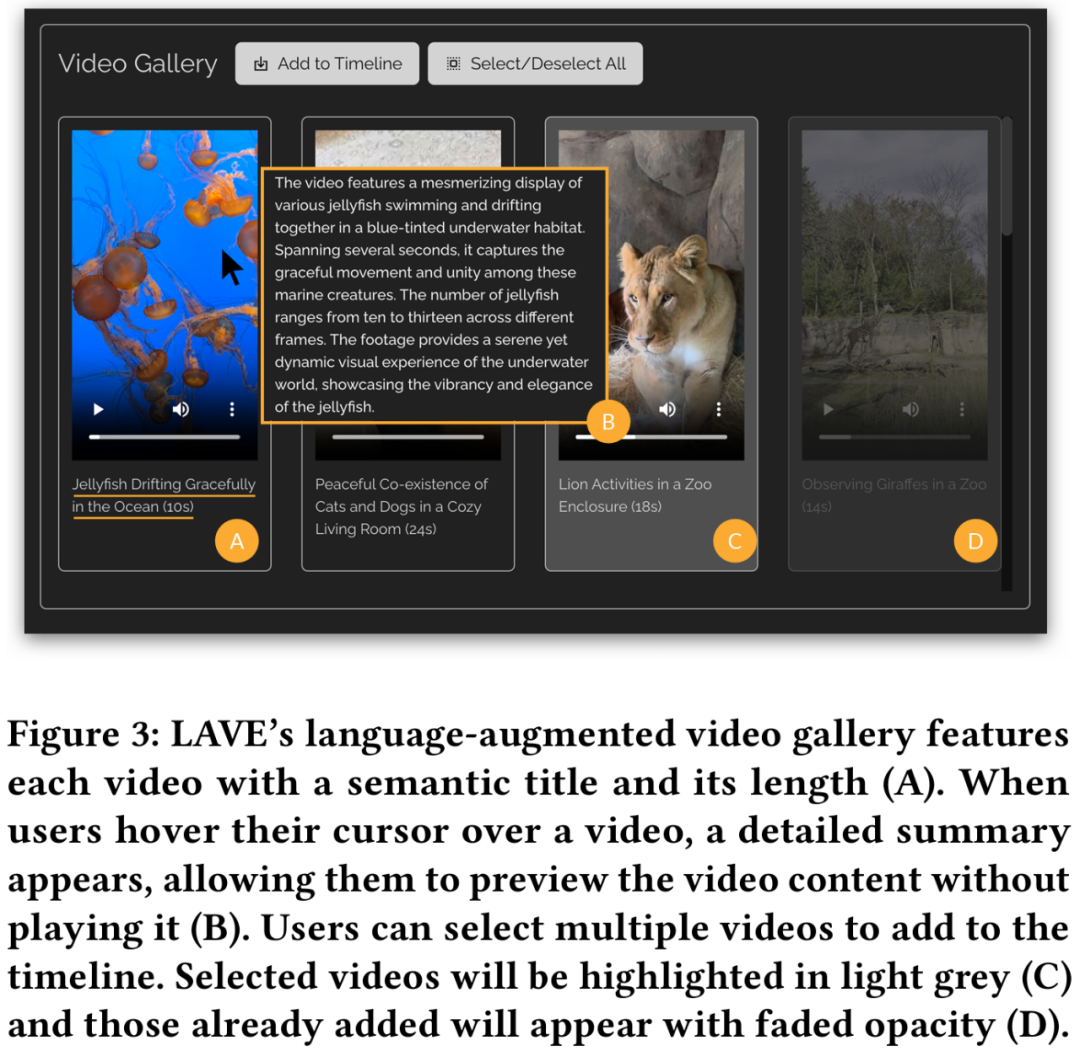
# 言語強化ビデオ ライブラリ
言語強化ビデオの機能図 3 に示すように、ライブラリは次のとおりです。従来のツールと同様、この機能ではクリップの再生が可能ですが、視覚的なナラティブ、つまり意味論的なタイトルや概要を含む各ビデオの自動生成されたテキスト説明が提供されます。タイトルはクリップの理解とインデックス付けに役立ち、概要は各クリップのビジュアル コンテンツの概要を提供し、ユーザーが編集プロジェクトのストーリーラインを形成するのに役立ちます。タイトルと再生時間が各ビデオの下に表示されます。
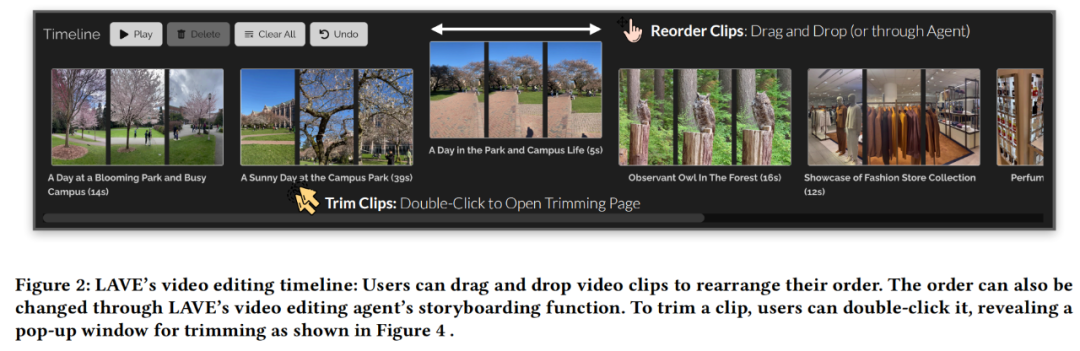
さらに、LAVE を使用すると、ユーザーはセマンティック言語クエリを使用してビデオを検索でき、取得されたビデオはビデオ ライブラリに表示され、関連性によって並べ替えられます。この機能はクリップ エージェントによって実行される必要があります。 ビデオ クリップ タイムライン ビデオ ライブラリからビデオを選択し、クリップ タイムラインに追加すると、以下の図 2 に示すように、インターフェイスの下部にあるビデオ クリップ タイムラインに表示されます。タイムライン上の各クリップはボックスで表され、開始フレーム、中間フレーム、終了フレームの 3 つのサムネイル フレームが表示されます。 LAVE システムでは、各サムネイル フレームはクリップ内の 1 秒間の素材を表します。ビデオ ギャラリーと同様に、各クリップにはタイトルと説明が表示されます。 LAVE のクリップ タイムラインには、クリップの並べ替えとトリミングという 2 つの重要な機能があります。 タイムライン上でクリップをシーケンスすることは、ビデオ編集における一般的なタスクであり、一貫した物語を作成するために重要です。 LAVE では、ビデオクリップエージェントのストーリーボード機能を使用した LLM ベースのソートと、ユーザーの直接操作によりソートする手動ソートの 2 つのソート方法をサポートしており、各ビデオ ボックスをドラッグ アンド ドロップして順序を設定できます。クリップが表示されます。 トリミングは、ビデオ編集において重要なセグメントを強調表示し、余分なコンテンツを削除するためにも重要です。トリミング中に、ユーザーがタイムライン内のクリップをダブルクリックすると、以下の図 4 に示すように、1 秒のフレームを表示するポップアップ ウィンドウが開きます。 #ビデオ クリップ エージェント LAVE Video Clip Agent は、ユーザーと LLM ベースのエージェント間の対話を容易にするチャットベースのコンポーネントです。コマンド ライン ツールとは異なり、ユーザーは自由形式の言語を使用してエージェントと対話できます。エージェントは LLM の言語インテリジェンスを活用してビデオ編集支援を提供し、編集プロセス全体を通じてユーザーをガイドおよび支援するための具体的な応答を提供します。 LAVE のエージェント支援機能は、エージェント操作を通じて提供され、各操作にはシステムでサポートされる編集機能の実行が含まれます。 全体として、LAVE はアイデア出しや事前計画から実際の編集操作に至るまでワークフロー全体をカバーする機能を提供しますが、システムは厳密なワークフローを要求するものではありません。ユーザーは、編集目標に合った機能のサブセットを柔軟に利用できます。たとえば、明確な編集ビジョンと明確なストーリーラインを持つユーザーは、アイデア作成フェーズを回避して、すぐに編集に取り掛かることができます。 この調査では、OpenAI の GPT-4 を使用して、LAVE バックエンド システムの設計を説明します。エージェント設計、LLM による編集機能の 2 つの側面を実装します。 エージェント設計 この研究では、LLM (つまり GPT-4) の多言語機能を活用します (推論、計画、ストーリーテリング) によって LAVE エージェントが構築されます。 LAVE エージェントには、計画と実行という 2 つの状態があります。この設定には 2 つの主な利点があります: #以下の図 6 に示すように、パイプラインはまずユーザー入力に基づいてアクション プランを作成します。次に、プランはテキストの説明から関数呼び出しに変換され、対応する関数が実行されます。 LLM 主導の編集機能を実装します ユーザーが完了するのを支援するためにビデオ 編集タスクの場合、LAVE は主に LLM によって駆動される次の 5 つの機能をサポートします。

バックエンド システム
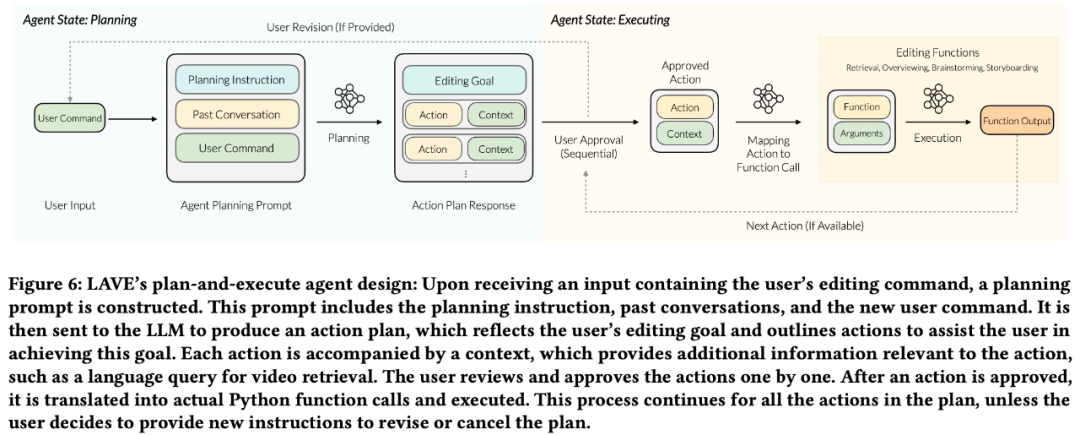
最初の 4 つはエージェントを通じてアクセスできます (図 5)。トリム機能は、タイムライン内のクリップをダブルクリックすると利用でき、ポップアップ ウィンドウが開き、1 秒のフレームが表示されます (図 4)。 

以上がSora がビデオ生成を爆発させると、Meta は中国人作家の主導で、Agent を使用してビデオを自動的にカットし始めました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7548
7548
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 ソニーは、PS5 Proで特別なGPUを使用してAMDを使用してAIを開発する可能性を確認しています
Apr 13, 2025 pm 11:45 PM
ソニーは、PS5 Proで特別なGPUを使用してAMDを使用してAIを開発する可能性を確認しています
Apr 13, 2025 pm 11:45 PM
Sony InteractiveEntertainmentのチーフアーキテクト(SIE、Sony Interactive Entertainment)のMark Cernyは、パフォーマンスアップグレードAMDRDNA2.xアーキテクチャGPU、およびAMDとの機械学習/人工知能プログラムコードノームの「Amethylst」を含む、次世代ホストPlayStation5Pro(PS5PRO)のハードウェアの詳細をリリースしました。 PS5PROパフォーマンスの改善の焦点は、より強力なGPU、高度なレイトレース、AI搭載のPSSRスーパー解像度関数を含む3つの柱に依然としてあります。 GPUは、SonyがRDNA2.xと名付けたカスタマイズされたAMDRDNA2アーキテクチャを採用しており、RDNA3アーキテクチャがあります。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CENTOSでのZookeeperパフォーマンスチューニングは、ハードウェア構成、オペレーティングシステムの最適化、構成パラメーターの調整、監視、メンテナンスなど、複数の側面から開始できます。特定のチューニング方法を次に示します。SSDはハードウェア構成に推奨されます。ZookeeperのデータはDISKに書き込まれます。十分なメモリ:頻繁なディスクの読み取りと書き込みを避けるために、Zookeeperに十分なメモリリソースを割り当てます。マルチコアCPU:マルチコアCPUを使用して、Zookeeperが並行して処理できるようにします。
 CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentOSシステムでのPytorchモデルの効率的なトレーニングには手順が必要であり、この記事では詳細なガイドが提供されます。 1。環境の準備:Pythonおよび依存関係のインストール:Centosシステムは通常Pythonをプリインストールしますが、バージョンは古い場合があります。 YumまたはDNFを使用してPython 3をインストールし、PIP:sudoyumupdatepython3(またはsudodnfupdatepython3)、pip3install-upgradepipをアップグレードすることをお勧めします。 cuda and cudnn(GPU加速):nvidiagpuを使用する場合は、cudatoolをインストールする必要があります
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
