

消費されるコンピューティング リソースは、従来の Stable Video Diffusion (SVD) モデルの 2/25 のみです。
AnimateLCM-SVD-xt がリリースされ、繰り返しノイズ除去を行うためにビデオ拡散モデルが変更されますが、これには時間がかかり、多くの計算が必要です。
まず、生成されたアニメーション効果を見てみましょう。
サイバーパンク スタイルは制御が簡単で、少年はヘッドフォンを着用してネオン街の通りに立っています:
 写真
写真
リアル風は大丈夫、新婚夫婦が寄り添い、絶妙な花束を持ち、古代の石の壁の下で愛を目撃します:
 写真
写真
SF スタイル、あります。地球に侵略してくるエイリアンの視覚的な感覚もあります:
 写真
写真
AnimateLCM-SVD-xt は、MMLab、Avolution AI、上海、中文大学によって作成されています。香港の人工知能研究所とセンスタイム研究所の研究者が共同で提案した。
 画像
画像
25 フレーム解像度 576x1024 の高品質アニメーションを 2 ~ 8 ステップで生成できます。分類器のガイダンスが必要です 、4 つのステップで生成されたビデオは、従来の SVD よりも高速かつ効率的に高忠実度を実現できます:
 画像
画像
 画像
画像
#Picture 次に、プロンプトとネガティブ プロンプトを入力して、生成されるアニメーションの内容と品質をガイドできます。
次に、プロンプトとネガティブ プロンプトを入力して、生成されるアニメーションの内容と品質をガイドできます。
Picture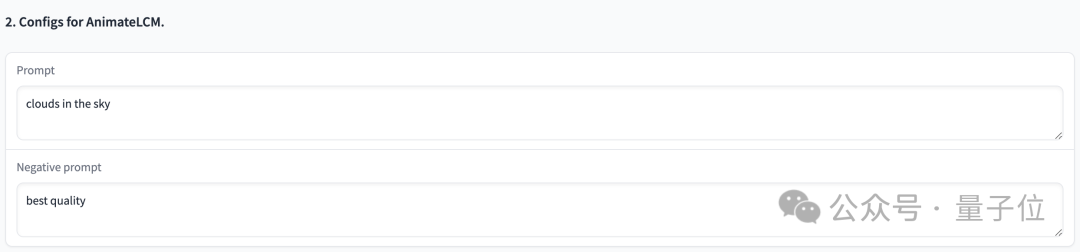 調整できるパラメータもいくつかあります:
調整できるパラメータもいくつかあります:
Picture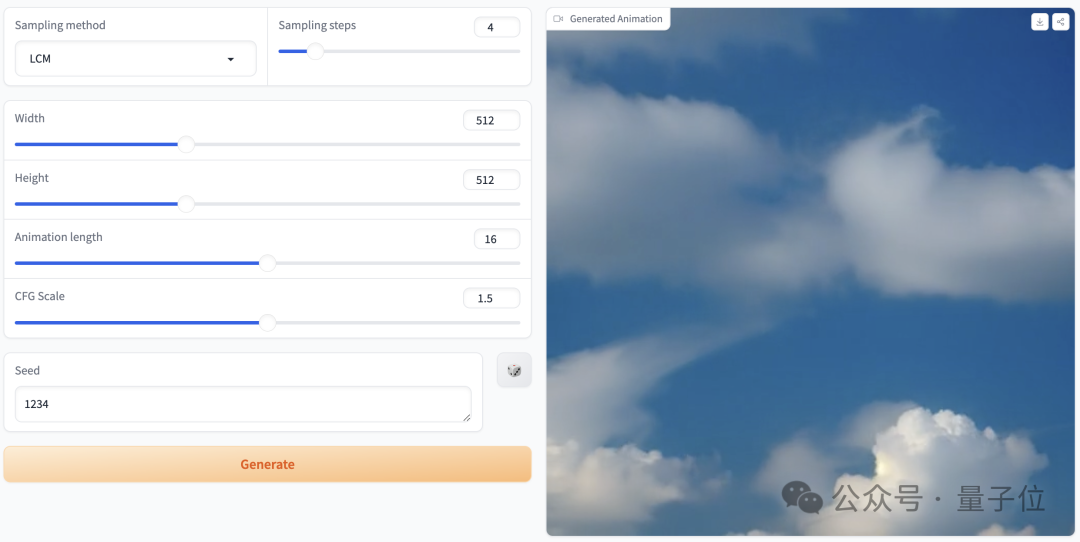 実際に試してみましたプロンプトは「clouds in the sky」、パラメータ設定は上に示したとおりで、サンプリングステップが 4 ステップのみの場合、生成されるエフェクトは次のようになります。
実際に試してみましたプロンプトは「clouds in the sky」、パラメータ設定は上に示したとおりで、サンプリングステップが 4 ステップのみの場合、生成されるエフェクトは次のようになります。
Picture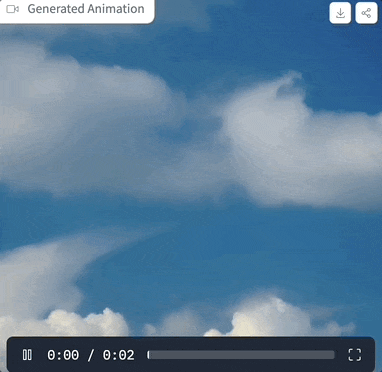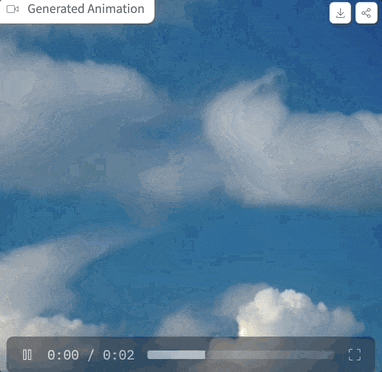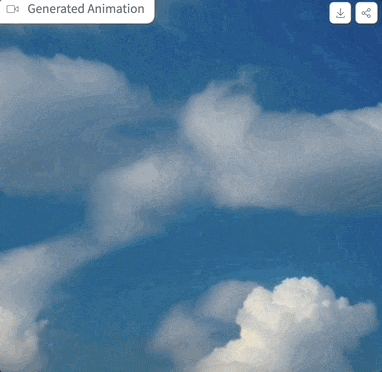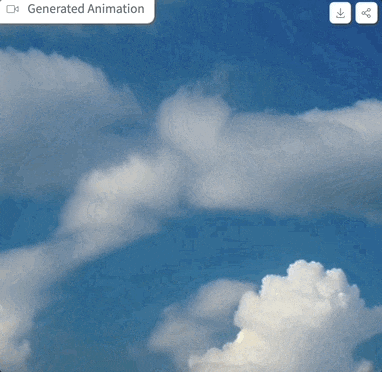 サンプリング ステップが 25 ステップ、プロンプト ワード「ウサギを抱いている少年」の場合、効果は次のとおりです:
サンプリング ステップが 25 ステップ、プロンプト ワード「ウサギを抱いている少年」の場合、効果は次のとおりです:
 正式リリースの表示効果をもう一度見てください。 2 ステップ、4 ステップ、および 8 ステップの効果の比較は次のとおりです。
正式リリースの表示効果をもう一度見てください。 2 ステップ、4 ステップ、および 8 ステップの効果の比較は次のとおりです。
 ステップが多いほど、アニメーションの品質は向上します。 AnimateLCM の 4 つのステップだけで高忠実度を実現できます:
ステップが多いほど、アニメーションの品質は向上します。 AnimateLCM の 4 つのステップだけで高忠実度を実現できます:
 さまざまなスタイルを実現できます:
さまざまなスタイルを実現できます:
 写真
写真
ビデオ拡散モデルは、一貫性のある高忠実度のビデオを生成できるため注目が高まっていますが、反復的なノイズ除去プロセスは時間がかかるだけでなく、計算量も多いことが難点の 1 つであることに注意してください。これにより、適用範囲が制限されます。
そして、この作品 AnimateLCM では、研究者は、サンプリングに必要なステップを削減するために事前トレーニングされた画像拡散モデルを簡素化する一貫性モデル (CM) からインスピレーションを得て、拡張に成功しました。条件付き画像生成に関する潜在整合性モデル (LCM) 。
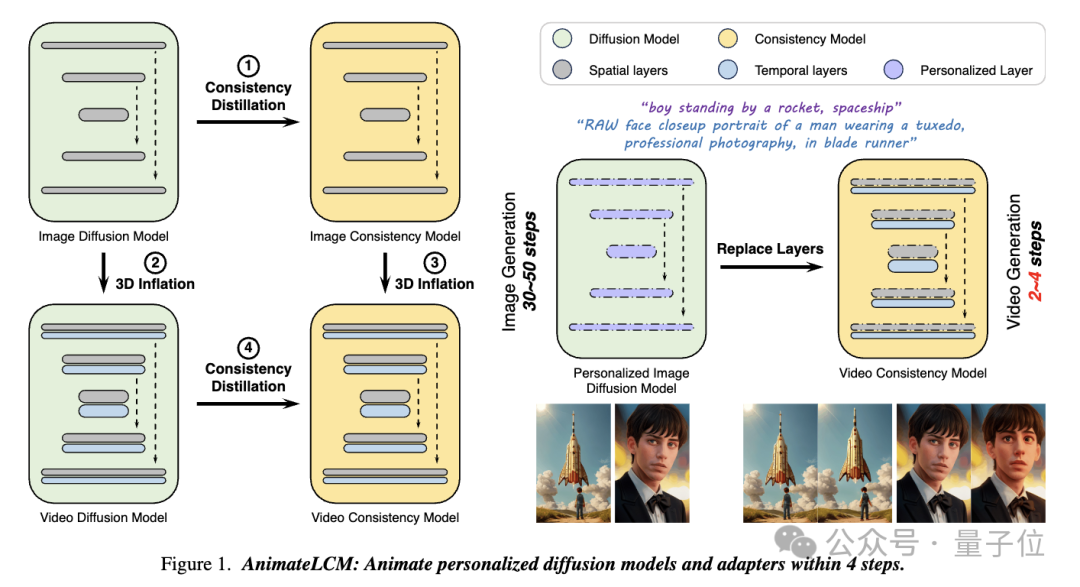 写真
写真
具体的には、研究者らは、分離一貫性学習(分離一貫性学習)戦略を提案しました。
まず安定拡散モデルを高品質の画像テキスト データ セットの画像一貫性モデルに抽出し、次にビデオ データに対して一貫性抽出を実行してビデオ一貫性モデルを取得します。この戦略は、空間レベルと時間レベルで個別にトレーニングすることでトレーニング効率を向上させます。
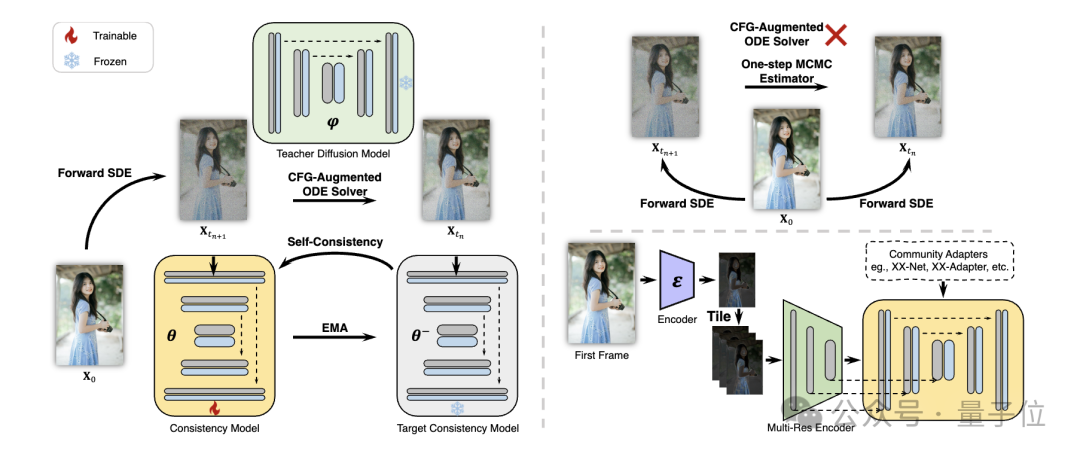 写真
写真
さらに、Stable Diffusion コミュニティでプラグ アンド プレイ アダプターのさまざまな機能を実装できるようにするため、 (たとえば、ControlNet 制御生成) を使用して、研究者らは、既存の制御アダプターと既存の制御アダプターの一貫性を高めるための Teacher-Free Adaptation (Teacher-Free Adaptation) 戦略も提案しました。一貫性モデルにより、より制御可能なビデオ生成を実現します。
 写真
写真
定量的実験と定性的実験の両方で、この方法の有効性が証明されています。
UCF-101 データセットに対するゼロサンプルのテキストからビデオへの生成タスクでは、AnimateLCM が FVD メトリクスと CLIPSIM メトリクスの両方で最高のパフォーマンスを達成しました。
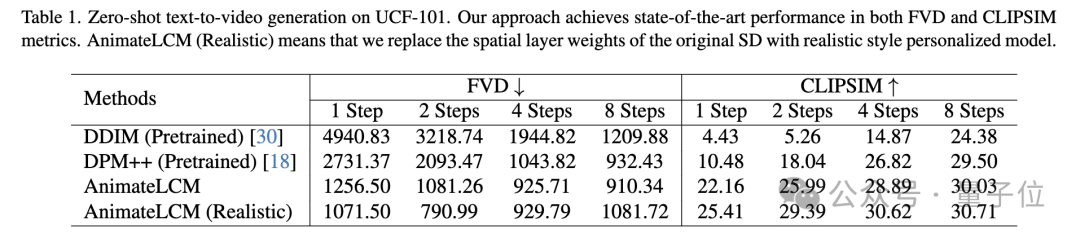 図
図
 図
図
アブレーション研究は、分離された整合性学習と特定の初期化の有効性を検証します。戦略:
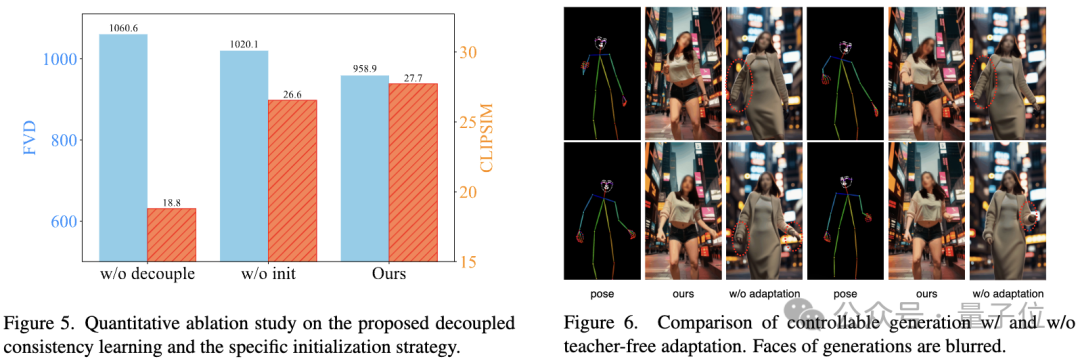 写真
写真
プロジェクトリンク:
[1]https://animatelcm.github.io/
[2]https://huggingface.co/wangfuyun/AnimateLCM-SVD-xt
以上が2 つのステップで 25 フレームの高品質アニメーションを生成 (SVD の 8% として計算) | オンラインで再生可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



