

Sora 爆発のテクノロジー、普及モデルの最新開発方向をまとめた記事

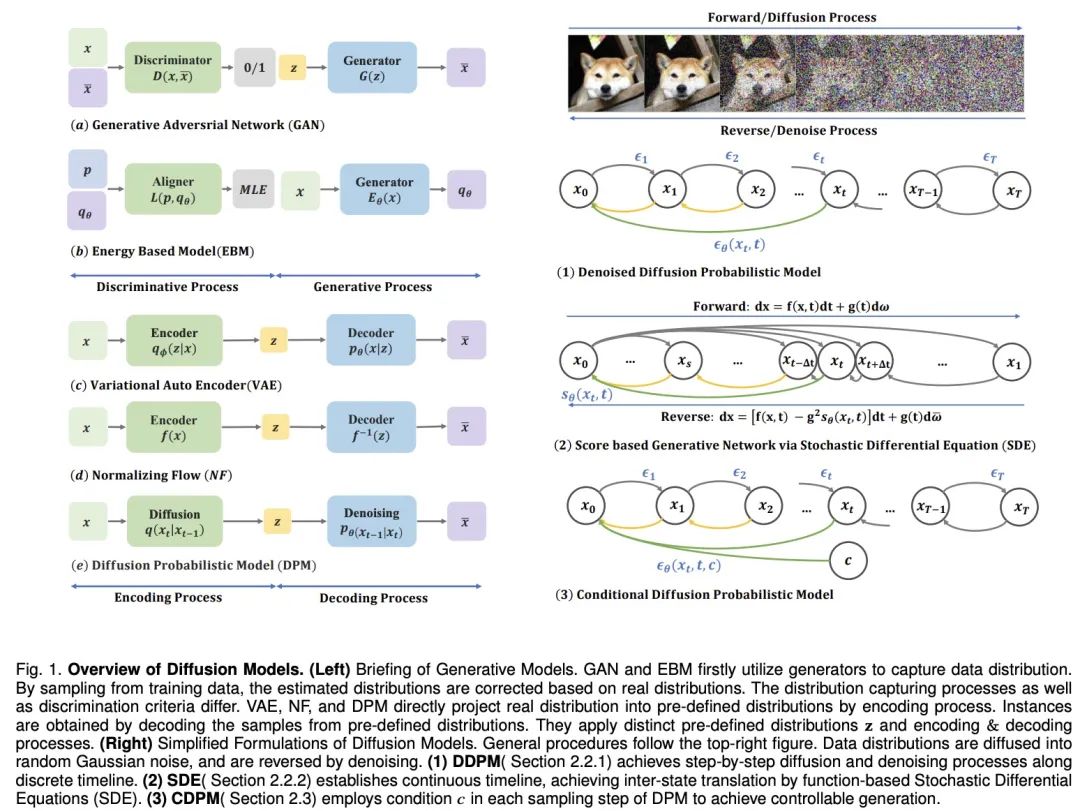

論文アドレス: https://arxiv.org/pdf/2209.02646.pdf プロジェクト アドレス: https://github.com/chq1155/ A-Survey-on-Generative-Diffusion-Model?tab=readme-ov-file
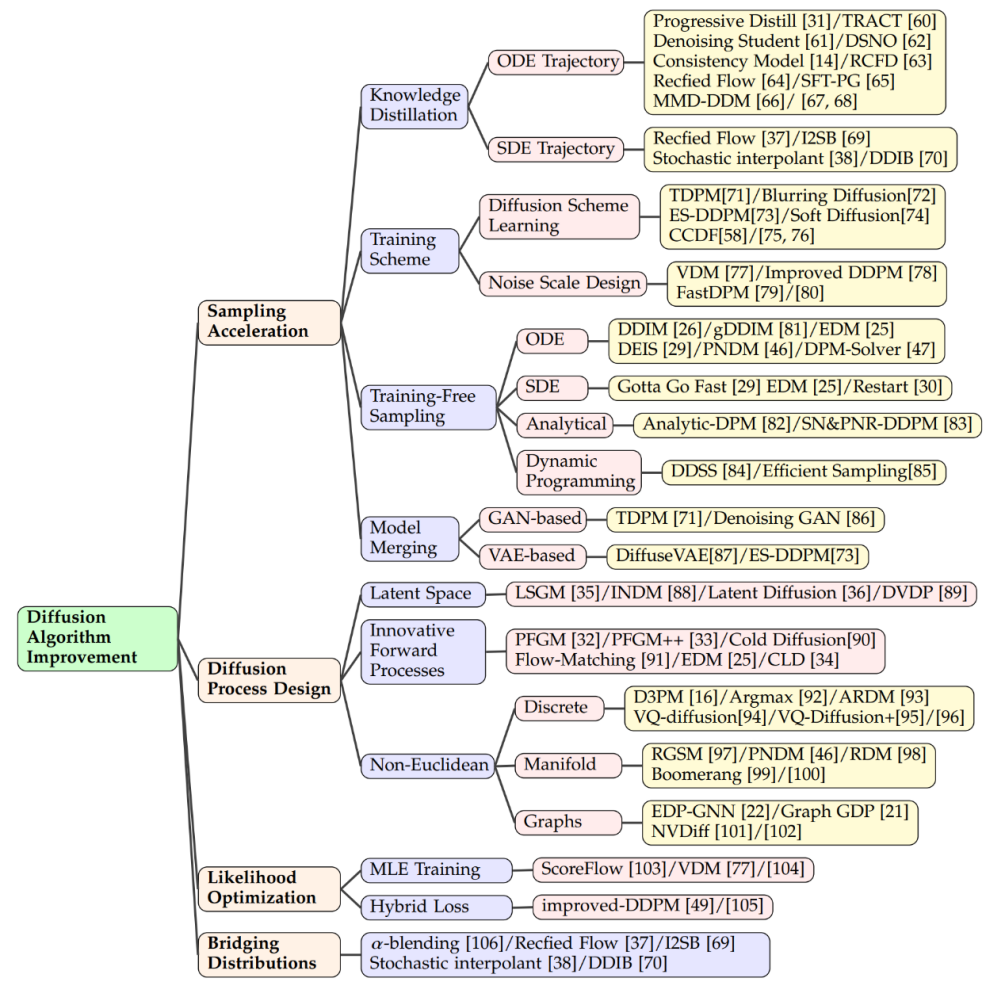
サンプリングの高速化
##知識の蒸留
- トレーニング方法を改善することも重要ですブースティングサンプリング 効率化の方法。一部の研究では、新しい拡散スキームの学習に焦点を当てています。このスキームでは、データに単純にガウス ノイズを加えるのではなく、より複雑な方法を通じて潜在空間にマッピングします。これらの方法の中には、エンコードの深さの調整など、逆デコード プロセスの最適化に焦点を当てているものもあれば、ノイズの追加が静的なものではなく、トレーニング プロセス中に変更できる変数になるように、新しいノイズ スケールの設計を検討しているものもあります。 .パラメータを学習しました。
- トレーニングに加えて新しいモデル 効率を向上させるために、事前にトレーニングされた拡散モデルのサンプリング プロセスを高速化するための専用のテクニックもいくつかあります。 ODE アクセラレーションは、ODE を使用して拡散プロセスを記述し、サンプリングをより速く進めることができる技術の 1 つです。たとえば、DDIM はサンプリングに ODE を利用する手法であり、その後の研究により、サンプリング速度をさらに向上させるために、PNDM や EDM などのより効率的な ODE ソルバーが導入されました。
- さらに、研究者らはサンプリングを高速化する分析手法を提案しており、これらの手法は、ノイズの多いデータから繰り返しを行わずにクリーンなデータを直接復元できる分析ソリューションを見つけようとしています。これらのメソッドには、Analytic-DPM とその改良版 Analytic-DPM が含まれており、高速で正確なサンプリング戦略を提供します。
- LSGM や INDM などの潜在空間拡散モデルは、VAE または正規化されたフロー モデルを組み合わせて、共有の重み付きノイズ除去フラクショナル マッチング損失および拡散モデルを通じてコーデックを最適化します。 ELBO または対数尤度の最適化は、学習とサンプル生成が容易な潜在空間を構築することを目的としています。たとえば、安定拡散では、まず VAE を使用して潜在空間を学習し、次にテキスト入力を受け入れるように拡散モデルをトレーニングします。 DVDP は、画像の摂動中にピクセル空間の直交成分を動的に調整します。
生成モデルの効率と強度を向上させるために、研究者は新しい前進プロセス設計を模索しています。ポアソン場生成モデルはデータを電荷として扱い、単純な分布を電力線に沿ったデータ分布に導き、従来の拡散モデルよりも強力なバックサンプリングを提供します。 PFGM は、この概念をさらに高次元の変数に取り入れます。 Dockhorn らの臨界減衰ランジュバン拡散モデルは、ハミルトン力学における速度変数を使用した条件付き速度分布の分数関数の学習を簡素化します。
離散内空間データ (テキスト、カテゴリデータなど) の拡散モデル、D3PM は離散空間の前方プロセスを定義します。この方法に基づいて、研究は言語テキストの生成、グラフのセグメント化、可逆圧縮にまで拡張されました。マルチモーダルな課題では、ベクトル量子化データがコードに変換され、優れた結果が得られます。ロボット工学やタンパク質モデリングなどのリーマン多様体の多様体データでは、拡散サンプリングをリーマン多様体に組み込む必要があります。 EDP-GNN や GraphGDP などのグラフ ニューラル ネットワークと拡散理論の組み合わせは、グラフ データを処理して順列不変性を捕捉します。
##拡散モデルは、高品質のデータを取得するという問題の解決に役立ちます。医療分析、特に医療画像処理における一連の課題。これらのモデルは、強力な画像キャプチャ機能により、画像解像度、分類、ノイズ処理の向上に成功しています。たとえば、Score-MRI と Diff-MIC は高度な技術を使用して、MRI 画像の再構成を高速化し、より正確な分類を可能にします。 MCG は CT 画像の超解像度に多様体補正を採用し、再構成の速度と精度を向上させます。レア画像の生成に関しては、モデルは特定の技術を通じて異なるタイプの画像間で変換できます。たとえば、FNDM と DiffuseMorph は、それぞれ脳の異常検出と MR 画像の登録に使用されます。一部の新しい手法では、少数の高品質サンプルからトレーニング データセットを合成します。たとえば、31,740 個のサンプルを使用して 100,000 インスタンスのデータセットを合成し、非常に低い FID スコアを達成したモデルがあります。
#テキスト生成
理解とシミュレーションの向上を目的とした拡散モデルを使用してグラフを生成します。現実世界のネットワーク構造と伝播プロセス。このアプローチは、研究者が複雑なシステムのパターンと相互作用を掘り起こし、起こり得る結果を予測するのに役立ちます。アプリケーションには、ソーシャル ネットワーク、生物学的ネットワーク分析、グラフ データセットの作成などが含まれます。従来の方法は隣接行列またはノード特徴の生成に依存していますが、これらの方法はスケーラビリティが低く、実用性が限られています。したがって、最新のグラフ生成技術では、特定の条件に基づいてグラフを生成することが好まれています。たとえば、PCFI モデルはグラフの機能の一部と最短経路予測を使用して生成プロセスをガイドし、EDGE と DiffFormer はノード次数とエネルギー制約を使用してそれぞれ生成を最適化し、D4Explainer は分布と反事実損失を組み合わせることによってグラフのさまざまな可能性を探ります。これらの方法により、グラフ生成の精度と実用性が向上します。
拡散モデルと従来のマシンの統合理論を組み合わせることで、さまざまなタスクのパフォーマンスを向上させる新たな機会が得られます。半教師あり学習は、一般化問題などの拡散モデルに固有の課題に対処し、データが限られている場合に効率的な条件付き生成を可能にする場合に特に価値があります。ラベルのないデータを活用することで、拡散モデルの汎化機能が強化され、特定の条件下でサンプルを生成する際に理想的なパフォーマンスが実現されます。
さらに、強化学習は、微調整アルゴリズムを使用してモデルのサンプリング プロセス中に的を絞ったガイダンスを提供することにより、重要な役割を果たします。このガイダンスにより、集中的な探査が保証され、制御された生成が促進されます。さらに、追加のフィードバックを統合することで強化学習が強化され、制御可能な状態を生成するモデルの能力が向上します。
以上がSora 爆発のテクノロジー、普及モデルの最新開発方向をまとめた記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7465
7465
 15
1376
52
77
11
18
19
15
1376
52
77
11
18
19

 世界のトップ10の仮想通貨取引プラットフォームのトップ10のランキングは何ですか?
Feb 20, 2025 pm 02:15 PM
世界のトップ10の仮想通貨取引プラットフォームのトップ10のランキングは何ですか?
Feb 20, 2025 pm 02:15 PM
暗号通貨の人気により、仮想通貨取引プラットフォームが登場しています。世界の上位10の仮想通貨取引プラットフォームは、トランザクションの量と市場シェアに従って次のようにランク付けされています:Binance、Coinbase、FTX、Kucoin、Crypto.com、Kraken、Huobi、Gate.io、Bitfinex、Gemini。これらのプラットフォームは、幅広い暗号通貨の選択から、さまざまなレベルのトレーダーに適したデリバティブ取引に至るまで、幅広いサービスを提供しています。
 PEPU 通貨タイプの概要
Dec 12, 2024 am 11:43 AM
PEPU 通貨タイプの概要
Dec 12, 2024 am 11:43 AM
PEPU Coin は、イーサリアム ブロックチェーンに基づく ERC-20 トークンであり、PEPU.io によって運営され、PEPU アプリケーションでネイティブ トークンとして使用されます。
 ゴマのオープンエクスチェンジを中国語に調整する方法
Mar 04, 2025 pm 11:51 PM
ゴマのオープンエクスチェンジを中国語に調整する方法
Mar 04, 2025 pm 11:51 PM
ゴマのオープンエクスチェンジを中国語に調整する方法は?このチュートリアルでは、コンピューターとAndroidの携帯電話の詳細な手順、予備的な準備から運用プロセスまで、そして一般的な問題を解決するために、セサミのオープン交換インターフェイスを中国に簡単に切り替え、取引プラットフォームをすばやく開始するのに役立ちます。
 トップ10の暗号通貨取引プラットフォーム、トップ10の推奨される通貨取引プラットフォームアプリ
Mar 17, 2025 pm 06:03 PM
トップ10の暗号通貨取引プラットフォーム、トップ10の推奨される通貨取引プラットフォームアプリ
Mar 17, 2025 pm 06:03 PM
上位10の暗号通貨取引プラットフォームには、1。Okx、2。Binance、3。Gate.io、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 安全で信頼できるデジタル通貨プラットフォームは何ですか?
Mar 17, 2025 pm 05:42 PM
安全で信頼できるデジタル通貨プラットフォームは何ですか?
Mar 17, 2025 pm 05:42 PM
安全で信頼できるデジタル通貨プラットフォーム:1。OKX、2。Binance、3。Gate.io、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 トップ10仮想通貨取引プラットフォーム2025暗号通貨取引アプリランキングトップ10
Mar 17, 2025 pm 05:54 PM
トップ10仮想通貨取引プラットフォーム2025暗号通貨取引アプリランキングトップ10
Mar 17, 2025 pm 05:54 PM
トップ10仮想通貨取引プラットフォーム2025:1。OKX、2。BINANCE、3。GATE.IO、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 トップ10の仮想通貨トレーディングアプリのうち、トップ10の仮想通貨取引アプリのどれが最も信頼できますか?
Mar 19, 2025 pm 05:00 PM
トップ10の仮想通貨トレーディングアプリのうち、トップ10の仮想通貨取引アプリのどれが最も信頼できますか?
Mar 19, 2025 pm 05:00 PM
トップ10仮想通貨取引アプリのランキング:1。OKX、2。Binance、3。Gate.io、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 推奨される安全な仮想通貨ソフトウェアアプリトップ10デジタル通貨取引アプリ2025ランキング
Mar 17, 2025 pm 05:48 PM
推奨される安全な仮想通貨ソフトウェアアプリトップ10デジタル通貨取引アプリ2025ランキング
Mar 17, 2025 pm 05:48 PM
推奨される安全な仮想通貨ソフトウェアアプリ:1。Okx、2。Binance、3。Gate.io、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
