

Underscore.js 1.3.3 中国語アノテーション翻訳手順_基礎知識

// アンダースコア.js 1.3.3
// (c) 2009-2012 Jeremy Ashkenas、DocumentCloud Inc.
// アンダースコアは MIT ライセンスに基づいて自由に配布できます。
// アンダースコアの一部は Prototype からインスピレーションを得たもの、または借用したものです。
// Oliver Steele の Functional、および John Resig の Micro-Templating。
// すべての詳細とドキュメントについては:
// http://documentcloud.github.com/underscore
(関数() {
// グローバル オブジェクトを作成します。ブラウザではウィンドウ オブジェクトとして表され、Node.js ではグローバル オブジェクトとして表されます。
var root = これ;
//「_」(アンダースコア変数)が上書きされる前に値を保存する
// 名前の競合がある場合、または仕様を考慮している場合は、_.noConflict() メソッドを使用して、Underscore によって占有される前の "_" の値を復元し、名前変更のために Underscore オブジェクトを返すことができます。
varPreviousUnderscore = root._;
//内部共有および使用のために空のオブジェクト定数を作成します
var ブレーカー = {};
// 組み込みオブジェクトのプロトタイプ チェーンをローカル変数にキャッシュして、迅速な呼び出しを容易にします。
var ArrayProto = Array.prototype, //
ObjProto = Object.prototype, //
FuncProto = Function.prototype;
// 組み込みオブジェクト プロトタイプの共通メソッドをローカル変数にキャッシュして、すばやく呼び出すことができるようにします
var スライス = ArrayProto.slice, //
unshift = ArrayProto.unshift, //
toString = ObjProto.toString, //
hasOwnProperty = ObjProto.hasOwnProperty;
// これは JavaScript 1.6 によって提供されるいくつかの新しいメソッドを定義します
// ホスト環境がこれらのメソッドをサポートしている場合は、これらのメソッドが最初に呼び出されます。ホスト環境がこれらのメソッドを提供していない場合は、Underscore によって実装されます。
varnativeForEach = ArrayProto.forEach, //
ネイティブマップ = ArrayProto.map, //
NativeReduce = ArrayProto.reduce, //
NativeReduceRight = ArrayProto.reduceRight, //
NativeFilter = ArrayProto.filter, //
NativeEvery = ArrayProto.every, //
NativeSome = ArrayProto.some, //
NativeIndexOf = ArrayProto.indexOf, //
ネイティブLastIndexOf = ArrayProto.lastIndexOf, //
NativeIsArray = Array.isArray, //
NativeKeys = Object.keys, //
ネイティブバインド = FuncProto.bind;
// Underscore ラッパーを返すオブジェクト スタイルの呼び出しメソッドを作成します。ラッパー オブジェクトのプロトタイプには、Underscore のすべてのメソッドが含まれています (DOM オブジェクトを jQuery オブジェクトにラップするのと似ています)。
var _ = 関数(obj) {
// すべての Underscore オブジェクトはラッパー オブジェクトを通じて内部的に構築されます
新しいラッパー(obj)を返します;
};
// 異なるホスト環境では、Undersocre の名前付き変数を異なるオブジェクトに保存します。
if( typeof exports !== 'unknown') {// Node.js 環境
if( モジュールのタイプ !== '未定義' && module.exports) {
エクスポート = モジュール.エクスポート = _;
}
エクスポート。_ = _;
} else {//ブラウザ環境の Underscore の名前付き変数が window オブジェクトにハングされます
ルート['_'] = _;
}
// バージョンステートメント
_.VERSION = '1.3.3';
// コレクション関連のメソッド(データやオブジェクトの一般的な処理メソッド)
//---------------------
// プロセッサを反復し、コレクション内の各要素に対してプロセッサ メソッドを実行します
var each = _.each = _.forEach = function(obj, iterator, context) {
//null値は扱わない
if(obj == null)
戻る;
if(nativeForEach && obj.forEach ===nativeForEach) {
// ホスト環境がサポートしている場合は、JavaScript 1.6 で提供される forEach メソッドが最初に呼び出されます。
obj.forEach(イテレータ、コンテキスト);
else if(obj.length === obj.length) {
//<array> 内の各要素に対してプロセッサ メソッドを実行します。
for(var i = 0, l = obj.length; i 2;
if(obj == null)
obj = [];
// ホスト環境が提供するreduceメソッドの呼び出しを優先します
if(nativeReduce && obj.reduce ===nativeReduce && false) {
if(コンテキスト)
イテレータ = _.bind(イテレータ, コンテキスト);
初期値を返しますか? obj.reduce(イテレータ, メモ) : obj.reduce(イテレータ);
}
// コレクション内の要素を反復処理します。
each(obj, function(value, インデックス, リスト) {
if(!初期) {
// 初期値がない場合、オブジェクト コレクションが処理される場合は、最初の要素が初期値として使用され、デフォルト値は最初の属性の値になります。
メモ = 値;
初期値 = true;
} それ以外 {
// 処理結果を記録し、結果を次の反復に渡します
memo = iterator.call(コンテキスト、メモ、値、インデックス、リスト);
}
});
if(!初期)
throw new TypeError('初期値のない空の配列を削減');
メモを返す。
};
//reduce と同様に、コレクション内の要素を逆方向 (つまり、最後の要素から最初の要素まで) に反復します。
_.reduceRight = _.foldr = function(obj, イテレータ, メモ, コンテキスト) {
var 初期値 = 引数.長さ > 2;
if(obj == null)
obj = [];
// ホスト環境が提供するreduceRightメソッドの呼び出しを優先します
if(nativeReduceRight && obj.reduceRight ===nativeReduceRight) {
if(コンテキスト)
イテレータ = _.bind(イテレータ, コンテキスト);
初期値を返しますか? obj.reduceRight(イテレータ, メモ) : obj.reduceRight(イテレータ);
}
// コレクション内の要素の順序を逆にします
var reversed = _.toArray(obj).reverse();
if(コンテキスト && !初期値)
イテレータ = _.bind(イテレータ, コンテキスト);
//reduceメソッドでデータを処理する
初期値を返す ? _.reduce(反転、イテレータ、メモ、コンテキスト) : _.reduce(反転、イテレータ);
};
// コレクション内の要素を走査し、プロセッサ検証に合格できる最初の要素を返します。
_.find = _.detect = function(obj, iterator, context) {
// 結果には検証に合格した最初の要素が格納されます
var 結果;
// any メソッドを通じてデータを走査し、検証に合格した要素を記録します
// (反復中にプロセッサの戻りステータスをチェックしている場合は、ここで each メソッドを使用する方が適切です)
any(obj, function(値, インデックス, リスト) {
// プロセッサによって返された結果がブール型に変換され、値が true の場合、現在の要素が記録されて返されます
if(iterator.call(コンテキスト, 値, インデックス, リスト)) {
結果 = 値;
true を返します。
}
});
結果を返します。
};
// find メソッドと似ていますが、filter メソッドはコレクション内の検証済みの要素をすべて記録します。
_.filter = _.select = function(obj, イテレータ, コンテキスト) {
// 検証に合格した要素の配列を保存するために使用されます
var 結果 = [];
if(obj == null)
結果を返します。
// ホスト環境が提供するフィルターメソッドの呼び出しを優先する
if(nativeFilter && obj.filter ===nativeFilter)
obj.filter(イテレータ、コンテキスト)を返します。
// コレクション内の要素を反復処理し、プロセッサによって検証された要素を配列に入れて返します。
each(obj, function(value, インデックス, リスト) {
if(iterator.call(コンテキスト, 値, インデックス, リスト))
結果[結果.長さ] = 値;
});
結果を返します。
};
// filter メソッドの逆の効果、つまりプロセッサ検証に合格しなかった要素のリストを返す
_.reject = function(obj, イテレータ, コンテキスト) {
var 結果 = [];
if(obj == null)
結果を返します。
each(obj, function(value, インデックス, リスト) {
if(!iterator.call(コンテキスト、値、インデックス、リスト))
結果[結果.長さ] = 値;
});
結果を返します。
};
// コレクション内のすべての要素がプロセッサー検証に合格できる場合、true を返します
_.every = _.all = function(obj, イテレータ, コンテキスト) {
var 結果 = true;
if(obj == null)
結果を返します。
// ホスト環境が提供するすべてのメソッドの呼び出しを優先します。
if(nativeEvery && obj.every ===nativeEvery)
obj.every(イテレータ, コンテキスト)を返します;
// コレクション内の要素を反復処理します。
each(obj, function(value, インデックス, リスト) {
// これは result = (result && iterator.call(context, value,index, list)) として理解されます
// プロセッサの結果が真値かどうかをBoolean型に変換して検証する
if(!( result = result && iterator.call(コンテキスト, 値, インデックス, リスト)))
リターンブレーカー。
});
!!結果を返します。
};
// コレクション内の要素がブール型に変換されるときに true 値を持つかどうかを確認します。それとも、プロセッサーによって処理された後に true 値を持つかどうかを確認します。
var any = _.some = _.any = function(obj, イテレータ, コンテキスト) {
// プロセッサ パラメータが指定されていない場合、デフォルトのプロセッサ関数は要素自体を返し、反復中に要素をブール型に変換することでそれが true 値であるかどうかを判断します。
イテレータ || ( イテレータ = _.identity);
var 結果 = false;
if(obj == null)
結果を返します。
// ホスト環境が提供する一部のメソッドの呼び出しを優先する
if(nativeSome && obj.some === ネイティブSome)
obj.some(イテレータ, コンテキスト) を返します。
// コレクション内の要素を反復処理します。
each(obj, function(value, インデックス, リスト) {
if(結果 || ( 結果 = iterator.call(コンテキスト, 値, インデックス, リスト)))
リターンブレーカー。
});
!!結果を返します。
};
// ターゲットパラメータと完全に一致する値がコレクション内に存在するかどうかを確認します (データ型も一致します)
_.include = _.contains = function(obj, target) {
見つかった変数 = false;
if(obj == null)
見つかったものを返します。
// ホスト環境が提供する Array.prototype.indexOf メソッドの呼び出しを優先します
if(nativeIndexOf && obj.indexOf ===nativeIndexOf)
obj.indexOf(ターゲット) を返します != -1;
// any メソッドを使用してコレクション内の要素を反復処理し、要素の値と型がターゲットと完全に一致するかどうかを確認します。
見つかった = any(obj, function(value) {
戻り値 === ターゲット;
});
見つかったものを返します。
};
// コレクション内のすべての要素の同じ名前のメソッドを、要素の呼び出しメソッドに渡される 3 番目のパラメータから順番に呼び出します。
// すべてのメソッドの処理結果を格納する配列を返す
_.invoke = function(obj, メソッド) {
// 同名のメソッド呼び出し時に渡されるパラメータ(第3パラメータ以降)
var args = slide.call(arguments, 2);
// 各要素のメソッドを順番に呼び出し、結果を配列に入れて返します
return _.map(obj, function(value) {
return (_.isFunction(メソッド) ? メソッド || 値 : 値[メソッド]).apply(値, 引数);
});
};
// オブジェクトのリストで構成される配列を走査し、各オブジェクトの指定された属性の値のリストを返します
_.pluck = function(obj, key) {
// プロパティがオブジェクト内に存在しない場合は、unknown を返します
return _.map(obj, function(value) {
戻り値[キー];
});
};
// コレクション内の最大値を返します。比較可能な値がない場合は、unknown を返します。
_.max = function(obj, イテレータ, コンテキスト) {
// コレクションが配列であり、プロセッサが使用されていない場合は、Math.max を使用して最大値を取得します
// 通常、一連の Number 型データは配列に格納されます。
if(!iterator && _.isArray(obj) && obj[0] === obj[0])
return Math.max.apply(Math, obj);
// null 値の場合は、負の無限大を直接返します
if(!イテレータ && _.isEmpty(obj))
戻り値 -Infinity;
// 計算された一時オブジェクトは、比較プロセス中に最大値を保存するために使用されます (一時的)
var 結果 = {
計算値: -Infinity
};
// コレクション内の要素を反復処理します。
each(obj, function(value, インデックス, リスト) {
// プロセッサー パラメーターが指定されている場合、比較されるデータはプロセッサーによって返される値になります。それ以外の場合は、各走査中のデフォルト値が直接使用されます。
var computed = iterator ? iterator.call(コンテキスト, 値, インデックス, リスト) : 値;
// 比較値が前の値より大きい場合は、現在の値を result.value に代入します。
計算済み >= 結果.計算済み && ( 結果 = {
値: 値、
計算された : 計算された
});
});
// 最大値を返す
結果の値を返します。
};
// セット内の最小値を返します。処理プロセスは max メソッドと一致します
_.min = function(obj, イテレータ, コンテキスト) {
if(!iterator && _.isArray(obj) && obj[0] === obj[0])
return Math.min.apply(Math, obj);
if(!イテレータ && _.isEmpty(obj))
無限大を返します。
var 結果 = {
計算: 無限
};
each(obj, function(value, インデックス, リスト) {
var computed = iterator ? iterator.call(コンテキスト, 値, インデックス, リスト) : 値;
計算された < 結果.計算された && ( 結果 = {
値: 値、
計算された : 計算された
});
});
結果の値を返します。
};
// 配列を整理する必要がないように乱数を使用します
_.shuffle = function(obj) {
// シャッフルされた変数には処理プロセスと最終結果データが格納されます
var shuffled = [], rand;
// コレクション内の要素を反復処理します。
each(obj, function(value, インデックス, リスト) {
// 乱数を生成します。乱数は <0 ~ 現在処理されている数値> の範囲内になります。
rand = Math.floor(Math.random() * (インデックス 1));
// ランダムに取得した要素をシャッフルされた配列の最後に置きます
シャッフル[インデックス] = シャッフル[ランド];
//前回取得した乱数の位置に最新の値を挿入
シャッフル[ランド] = 値;
});
// ランダムにシャッフルされたコレクション要素を格納する配列を返します。
シャッフルして返します。
};
// 特定のフィールドまたは値に従ってコレクション内の要素を配置します。
// Array.prototype.sort メソッドと比較して、sortBy メソッドはオブジェクトの並べ替えをサポートします。
_.sortBy = function(obj, val, context) {
// val はオブジェクトのプロパティであるか、プロセッサの場合は比較する必要があるデータを返す必要があります。
var iterator = _.isFunction(val) val : function(obj) {
obj[val]を返します;
};
// 呼び出しシーケンス: _.pluck(_.map().sort());
// _.map() メソッドを呼び出してコレクションを走査し、コレクション内の要素を値ノードに配置し、要素内で比較する必要があるデータを criteria 属性に配置します。
//sort() メソッドを呼び出して、 criteria 属性のデータに従ってコレクション内の要素を並べ替えます。
// pluck を呼び出してソートされたオブジェクト コレクションを取得し、それを返します
return _.pluck(_.map(obj, function(値, インデックス, リスト) {
戻る {
値: 値、
条件: iterator.call(コンテキスト、値、インデックス、リスト)
};
}).sort(関数(左, 右) {
var a = left.criteria、b = right.criteria;
if(a ===
ボイド0)
1を返します。
if(b ===
ボイド0)
-1 を返します。
a < b ? : a > b ? を返します。
})、 '価値');
};
// プロセッサから返されたキーに従って、コレクション内の要素を複数の配列に分割します
_.groupBy = function(obj, val) {
var 結果 = {};
// val はグループ化用のプロセッサ関数に変換されます。val が Function 型データでない場合、要素をフィルタリングする際のキー値として使用されます。
var iterator = _.isFunction(val) val : function(obj) {
obj[val]を返します;
};
// コレクション内の要素を反復処理します。
each(obj, 関数(値, インデックス) {
// プロセッサの戻り値をキーとして使用し、同じキー要素を新しい配列に入れます
var key = イテレータ(値, インデックス);
(結果[キー] || (結果[キー] = [])).push(値);
});
// グループ化されたデータを返す
結果を返します。
};
_.sortedIndex = function(array, obj, iterator) {
イテレータ || ( イテレータ = _.identity);
var low = 0、high = array.length;
while(低 < 高) {
varmid = (低高) >> 1;
iterator(array[mid]) < iterator(obj) ? 低 = 中 1 : 高 = 中;
}
ローに戻ります。
};
// コレクションを配列に変換して返す
// 通常、引数を配列に変換するか、オブジェクトの順序付けされていないコレクションをデータ形式の順序付けされたコレクションに変換するために使用されます。
_.toArray = function(obj) {
if(!obj)
戻る [];
if(_.isArray(obj))
戻りスライス.call(obj);
//引数を配列に変換する
if(_.isArguments(obj))
戻りスライス.call(obj);
if(obj.toArray && _.isFunction(obj.toArray))
obj.toArray() を返します。
// オブジェクトを配列に変換します。この配列には、オブジェクト内のすべてのプロパティ (オブジェクトのプロトタイプ チェーン内のプロパティを除く) の値リストが含まれます。
_.values(obj)を返します;
};
// コレクション内の要素の数をカウントします
_.size = 関数(obj) {
// コレクションが配列の場合、配列の要素の数をカウントします
// コレクションがオブジェクトの場合、オブジェクト内のプロパティの数を数えます (オブジェクトのプロトタイプ チェーン内のプロパティを除く)
_.isArray(obj) を返しますか? obj.length : _.keys(obj).length;
};
// 配列関連のメソッド
// ---------------
// 指定された配列の最初または n 個の要素を順番に返します
_.first = _.head = _.take = function(配列, n, ガード) {
// パラメータ n が指定されていない場合は、最初の要素を返します
// n が指定された場合は、指定された数の n 要素を順番に含む新しい配列を返します。
//ガード パラメーターは、ガードが true の場合、指定された数値 n が無効であることを決定するために使用されます。
return (n != null) && !guard ? slide.call(array, 0, n) : array[0];
};
//最初の要素を除く他の要素を含む、または最後の要素から前方に指定された n 要素を除いた新しい配列を返します。
// 最初のメソッドとの違いは、最初に配列の前の必須要素の位置を決定し、配列の最後にある除外要素の位置を最初に決定することです。
_.initial = function(配列, n, ガード) {
// パラメータ n が渡されない場合、デフォルトで最後の要素を除く他の要素が返されます。
// パラメータ n が渡された場合は、最後の要素から n つ前の要素を除いた他の要素が返されます。
// ガードは 1 つの要素のみが返されるようにするために使用されます。ガードが true の場合、指定された数値 n は無効になります。
return slide.call(array, 0, array.length - ((n == null) || ガード ? 1 : n));
};
//配列の最後の n 要素、または指定された n 要素を逆順で返します
_.last = function(配列, n, ガード) {
if((n != null) && !guard) {
// 取得した要素位置nを配列の最後まで計算して指定し、新たな配列として返す
戻りスライス.call(array, Math.max(array.length - n, 0));
} それ以外 {
// 数値が指定されていない場合、またはガードが true の場合、最後の要素のみが返されます
配列[配列の長さ - 1]を返します。
}
};
// 最初の要素または指定された最初の n 要素を除く他の要素を取得します
_.rest = _.tail = function(配列、インデックス、ガード) {
// スライスの 2 番目の位置パラメータを配列の終わりまで計算します
// インデックスが指定されていない場合、またはガード値が true の場合は、最初の要素を除く他の要素を返します。
// (index == null) 値が true の場合、スライス関数に渡されるパラメータは自動的に 1 に変換されます
returnlice.call(array, (index == null) || ガード ? 1 : インデックス);
};
// 値が true に変換できる配列内のすべての要素を返し、新しい配列を返します
// 変換できない値には false、0、''、null、unknown、NaN が含まれます。これらの値は false に変換されます
_.compact = 関数(配列) {
return _.filter(配列, 関数(値) {
!!値を返します。
});
};
// 多次元の数値を 1 次元の配列に結合し、深いマージをサポートします
// 浅いパラメータはマージの深さを制御するために使用されます。shallow が true の場合、最初のレイヤーのみがマージされ、デフォルトでは深いマージが実行されます。
_. flatten = function(配列, 浅い) {
// 配列内の各要素を反復処理し、戻り値をデモとして次の反復に渡します。
return _.reduce(配列, 関数(メモ, 値) {
// 要素が配列のままの場合は、次のように判断します。
// - 深いマージが実行されない場合は、Array.prototype.concat を使用して現在の配列と以前のデータを接続します。
// - ディープマージがサポートされている場合、基礎となる要素が配列型でなくなるまで、 flatten メソッドが繰り返し呼び出されます。
if(_.isArray(値))
return memo.concat(shallow ? value : _. flatten(value));
// データ (値) はすでに最下位にあり、配列型ではなくなった場合、データをメモにマージして戻ります
メモ[メモ.長さ] = 値;
メモを返す。
}、[]);
};
// 指定されたデータと等しくない現在の配列の差分データをフィルタリングして返します (difference メソッドのコメントを参照してください)
_.without = 関数(配列) {
return _.difference(配列, スライス.コール(引数, 1));
};
// 配列内のデータの重複を除去します (比較には === を使用します)
// isSorted パラメータが false でない場合、配列内の要素に対して include メソッドが順番に呼び出され、戻り値 (配列) に同じ要素が追加されているかどうかがチェックされます。
// 呼び出す前に配列内のデータが順番に配置されていることを確認する場合、isSorted を true に設定すると、最後の要素と比較して同じ値が除外されます。isSorted を使用する方が、デフォルトの include メソッドより効率的です。 。
// uniq メソッドはデフォルトで配列内のデータを比較します。イテレータ プロセッサが宣言されている場合、比較時には配列内のデータが優先されますが、返されるのはデータだけです。最後はまだ元の配列です
_.uniq = _.unique = function(array, isSorted, iterator) {
// イテレータ プロセッサが使用されている場合、現在の配列内のデータは最初にイテレータによって処理され、新しい処理された配列が返されます。
// 新しい配列が比較の基準として使用されます
var 初期 = イテレータ ? _.map(配列, イテレータ) : 配列;
// 処理結果を記録するために使用される一時配列
var 結果 = [];
// 配列内の値が 2 つだけの場合、比較に include メソッドを使用する必要はありません。isSorted を true に設定すると、操作効率が向上します。
if(配列の長さ < 3)
isSorted = true;
//reduceメソッドを使って処理結果を繰り返し蓄積する
// 初期変数は、比較する必要があるベースライン データです。元の配列またはプロセッサの結果セット (反復子が設定されている場合) です。
_.reduce(初期値, 関数(メモ, 値, インデックス) {
// isSorted パラメータが true の場合、=== を直接使用してレコード内の最後のデータを比較します
// isSorted パラメータが false の場合、 include メソッドを使用してコレクション内の各データと比較します
if( isSorted ? _.last(memo) !== value || !memo.length : !_.include(memo, value)) {
//memo は比較された重複しないデータを記録します
// イテレータのパラメータの状態に応じて、メモに記録されるデータはオリジナルのデータである場合もあれば、プロセッサによって処理されたデータである場合もあります
メモ.push(値);
// 処理結果の配列に格納されるデータは常に元の配列のデータです
results.push(配列[インデックス]);
}
メモを返す。
}、[]);
// 配列内の重複しないデータのみを含む処理結果を返します。
結果を返します。
};
// Union メソッドは uniq メソッドと同じ効果があります。違いは、Union では複数の配列をパラメータとして渡すことができることです。
_.union = function() {
// Union はパラメータ内の複数の配列を浅く結合して配列オブジェクトにし、処理のために uniq メソッドに渡します。
return _.uniq(_. flatten(arguments, true));
};
// 現在の配列と 1 つ以上の他の配列の交差要素を取得します
// 2 番目のパラメータから始まるのは、比較する必要がある 1 つ以上の配列です
_.intersection = _.intersect = 関数(配列) {
// 残りの変数には、比較する必要がある他の配列オブジェクトが記録されます。
varrest = スライス.コール(引数, 1);
// 計算の繰り返しを避けるために、uniq メソッドを使用して現在の配列内の重複データを削除します。
// 現在の配列のデータをプロセッサーでフィルターし、条件を満たすデータを返します (同じ要素を比較)
return _.filter(_.uniq(array), function(item) {
// each メソッドを使用して、各配列に比較する必要のあるデータが含まれていることを確認します。
// すべての配列に比較データが含まれている場合はすべて true を返し、配列に要素が含まれていない場合は false を返します
return _.every(rest, function(other) {
// 他のパラメータには、比較する必要がある各配列が格納されます
// item には、現在の配列で比較する必要があるデータが格納されます
// 要素が配列内に存在するかどうかを検索するには、indexOf メソッドを使用します (indexOf メソッドのコメントを参照してください)
return _.indexOf(other, item) >= 0;
});
});
};
// 現在の配列内の、指定されたデータと等しくない差分データをフィルタリングして返します。
// この関数は通常、配列内の指定されたデータを削除し、削除後に新しい配列を取得するために使用されます。
// このメソッドの機能は without と同等です。without メソッドのパラメータではデータを配列に含めることができませんが、difference メソッドのパラメータは配列であることが推奨されます (without と同じパラメータを使用することもできます)。
_.difference = 関数(配列) {
// 2 番目のパラメータから始まるすべてのパラメータを配列としてマージします (深いマージではなく、最初のレベルのみをマージします)
// 残りの変数には、このメソッドで元のデータと比較するために使用される検証データが格納されます。
varrest = _. flatten(slice.call(arguments, 1), true);
// マージされた配列データをフィルターします。フィルター条件は、現在の配列にパラメーターで指定された検証データが含まれていないことです。
// フィルター条件を満たすデータを新しい配列に結合して返します
return _.filter(配列, 関数(値) {
return !_.include(rest, value);
});
};
//各配列の同じ位置のデータを新しい 2 次元配列として返します。返される配列の長さは、渡されたパラメーターの最大配列長に基づいて決まります。他の配列の空白の位置は未定義で埋められます。
// zip メソッドには複数のパラメータを含める必要があり、各パラメータは配列である必要があります
_.zip = 関数() {
//パラメータを配列に変換します。このとき args は 2 次元配列です
var args = スライス.コール(引数);
// 各配列の長さを計算し、最大長の値を返します。
var length = _.max(_.pluck(args, 'length'));
//最大長の値に従って新しい空の配列を作成し、処理結果を格納するために使用します
var results = 新しい配列(長さ);
//ループの最大長。各ループで pluck メソッドが呼び出され、各配列内の同じ位置 (シーケンスの 0 から最後の位置まで) にあるデータを取得します。
// 取得したデータを新しい配列に格納し、結果に入れて返します
for(var i = 0; i < length; i )
results[i] = _.pluck(args, "" i);
// 返される結果は 2 次元配列です
結果を返します。
};
// 配列内で最初に出現する要素を検索し、その要素が存在しない場合は -1 を返します。
// 検索時に要素を一致させるには === を使用します
_.indexOf = function(配列, 項目, isSorted) {
if(配列 == null)
-1 を返します。
変数 i、l;
if(isSorted) {
i = _.sortedIndex(配列, 項目);
戻り値 配列[i] === 項目 ? i : -1;
}
// ホスト環境が提供するindexOfメソッドの呼び出しを優先する
if(nativeIndexOf && array.indexOf ===nativeIndexOf)
戻り配列.indexOf(項目);
// ループして最初に出現した要素を返します
for( i = 0, l = array.length; i < l; i )
if( 配列内の i && 配列[i] === 項目)
私を返します。
// 要素が見つからないため、-1 を返します
-1 を返します。
};
// 配列内で最後に出現した要素の位置を返します。要素が存在しない場合は -1 を返します。
// 検索時に要素を一致させるには === を使用します
_.lastIndexOf = 関数(配列, 項目) {
if(配列 == null)
-1 を返します。
// ホスト環境が提供する lastIndexOf メソッドの呼び出しを優先します
if(nativeLastIndexOf && array.lastIndexOf ===nativeLastIndexOf)
戻り配列.lastIndexOf(item);
var i = 配列の長さ;
// ループして、最後に出現した要素を返します。
その間(私は--)
if( 配列内の i && 配列[i] === 項目)
私を返します。
// 要素が見つからないため、-1 を返します
-1 を返します。
};
// 間隔とステップ サイズに基づいて一連の整数を生成し、配列として返します。
// 開始パラメータは最小数を表します
// stop パラメータは最大数を示します
//ステップパラメータは、複数の値を生成する間のステップ値を表します。
_.range = 関数(開始、停止、ステップ) {
// パラメータ制御
if(arguments.length <= 1) {
// パラメータがない場合、start = 0、stop = 0、ループ内でデータは生成されず、空の配列が返されます。
// パラメータが 1 つの場合、そのパラメータは stop、start = 0 に割り当てられます。
停止 = 開始 || 0;
開始 = 0;
}// 整数のステップ値を生成します。デフォルトは 1 です
ステップ = 引数[2] || 1;
// 間隔とステップ サイズに基づいて生成される最大値を計算します
var len = Math.max(Math.ceil((停止 - 開始) / ステップ), 0);
varidx = 0;
var range = 新しい配列(len);
// 整数のリストを生成し、範囲配列に格納します
while(idx < len) {
範囲[idx] = 開始;
開始 = ステップ;
}
//リストの結果を返す
戻り範囲。
};
//関数関連のメソッド
// ------------------
//プロトタイプ設定用のパブリック関数オブジェクトを作成
var ctor = function() {
};
//関数の実行コンテキストをバインドします。関数が呼び出されるたびに、関数内の this はコンテキスト オブジェクトを指します。
// 関数をバインドするときに、同時に呼び出しパラメータを関数に渡すことができます
_.bind = 関数バインド(関数, コンテキスト) {
var バインド、引数;
// ホスト環境が提供するバインドメソッドの呼び出しを優先する
if(func.bind === ネイティブバインド && ネイティブバインド)
returnnativeBind.apply(func,slice.call(arguments,1));
// func パラメータは関数型でなければなりません
if(!_.isFunction(関数))
新しい TypeError をスローします。
// args 変数には、bind メソッドから始まる 3 番目のパラメータ リストが格納され、関数が呼び出されるたびに func 関数に渡されます。
args = スライス.コール(引数, 2);
戻り値 = function() {
if(!(このインスタンスのバインド))
return func.apply(context, sargs.concat(slice.call(arguments)));
ctor.prototype = func.prototype;
var self = 新しい ctor;
var result = func.apply(self, args.concat(slice.call(arguments)));
if(オブジェクト(結果) === 結果)
結果を返します。
自分自身を返します。
};
};
// 指定された関数、またはオブジェクト自体のすべての関数をオブジェクト自体にバインドします。バインドされた関数が呼び出されるとき、コンテキスト オブジェクトは常にオブジェクト自体を指します。
// このメソッドは通常、オブジェクト イベントを処理するときに使用されます。例:
// _(obj).bindAll(); // または _(obj).bindAll('handlerClick');
// document.addEventListener('click', obj.handlerClick);
// handlerClick メソッドでは、コンテキストは依然として obj オブジェクトです
_.bindAll = function(obj) {
// 2 番目のパラメータは、バインドする必要がある関数の名前を示し始めます。
var funcs = スライス.コール(引数, 1);
// 特定の関数名が指定されていない場合、デフォルトで Function 型のすべてのプロパティがオブジェクト自体にバインドされます。
if(関数の長さ == 0)
funcs = _.functions(obj);
// ループして、すべての関数コンテキストを obj オブジェクト自体に設定します
// each メソッド自体は、オブジェクトのプロトタイプ チェーン内のメソッドをトラバースしませんが、ここでの funcs リストは、プロトタイプ チェーン内のメソッドが既に含まれている _.functions メソッドを通じて取得されます。
each(関数、関数(f) {
obj[f] = _.bind(obj[f], obj);
});
オブジェクトを返します。
};
// memoize メソッドは関数を返します。この関数はキャッシュ関数を統合し、計算された値をローカル変数にキャッシュし、次回呼び出されたときに直接返します。
// 計算結果が巨大なオブジェクトやデータの場合、メモリ使用量を考慮して使用する必要があります。
_.memoize = function(func, hasher) {
// キャッシュされた結果を保存するために使用されるメモ オブジェクト
var メモ = {};
// ハッシュ パラメータは、キャッシュを読み取るための識別子として使用されるキーを返すために使用される関数である必要があります。
// キーが指定されていない場合、関数の最初のパラメーターがデフォルトでキーとして使用されます。関数の最初のパラメーターが複合データ型の場合は、[Object object] のようなキーが返されることがあります。後続のデータが正しくなくなる可能性があります。
ハッシュ || ( ハッシュ = _.identity);
// 最初にキャッシュをチェックし、次にキャッシュされていないデータを呼び出す関数を返します。
戻り関数() {
var key = hasher.apply(this, argument);
return _.has(memo, key) ? memo[key] : (memo[key] = func.apply(this, argument));
};
};
// 関数の実行を遅らせる
// 待機の単位はmsで、3番目のパラメータは実行関数に順番に渡されます。
_.lay = function(func, wait) {
var args = slide.call(arguments, 2);
return setTimeout(function() {
return func.apply(null, args);
}、 待って);
};
// 遅延実行関数
// JavaScript の setTimeout は別の関数スタックで実行されます。実行時間は、現在のスタックで呼び出されるすべての関数が実行された後です。
// defer は、関数が 1ms 後に実行されるように設定します。その目的は、func 関数を別のスタックに置き、現在の関数が完了するのを待ってから実行することです。
// defer メソッドは通常、DOM 操作の優先順位を処理して、正しい論理フローとよりスムーズなインタラクティブ エクスペリエンスを実現するために使用されます。
_.defer = function(func) {
return _.lay.apply(_, [func, 1].concat(slice.call(arguments, 1)));
};
// 関数のスロットル メソッド。スロットル メソッドは主に、制御された時間間隔内で、頻繁に呼び出される関数が複数回実行されないように制御するために使用されます。
// 関数が時間間隔内で複数回呼び出された場合、時間間隔が経過すると自動的に 1 回呼び出されます。手動で呼び出す前に、時間が経過するまで待つ必要はありません (自動的に呼び出された場合、戻り値はありません)。 )
// スロットル関数は、通常、複雑で頻繁に呼び出される関数を処理するために使用され、スロットルによって関数の呼び出し頻度を制御し、処理リソースを節約します。
// たとえば、window.onresize にバインドされたイベント関数、または element.onmousemove にバインドされたイベント関数は、throttle とともにパッケージ化できます。
// throttle メソッドは関数を返します。この関数は自動的に func を呼び出してスロットル制御を実行します。
_.throttle = function(func, wait) {
var context、args、timeout、throttling、その他、result;
// whenDone 変数は debounce メソッドを呼び出すため、関数が複数回呼び出される場合、最後の呼び出しによって以前に呼び出されたタイマーが上書きされ、ステータスのクリア関数は 1 回だけ実行されます。
// whenDone 関数は、最後の関数実行の時間間隔が経過すると呼び出され、スロットリングと呼び出しプロセス中に記録された一部の状態がクリアされます。
var whenDone = _.debounce(function() {
詳細 = スロットリング = false;
}、 待って);
// 関数を返し、関数内でスロットル制御を実行します
戻り関数() {
//関数の実行コンテキストとパラメータを保存します
コンテキスト = これ;
args = 引数;
//最後の関数呼び出しの時間間隔が経過すると、後の関数が実行されます
var 後で = function() {
// 次の関数呼び出しを容易にするためにタイムアウト ハンドルをクリアします
タイムアウト = null;
// 最後の呼び出しから時間間隔の有効期限までに関数が繰り返し呼び出されたかどうかをさらに記録します
// 関数が繰り返し呼び出される場合、時間間隔が経過すると関数は自動的に再度呼び出されます。
もし(もっと)
func.apply(コンテキスト, 引数);
// whenDone を呼び出し、一定時間後にスロットル状態をクリアするために使用されます
whenDone();
};
// タイムアウトは、最後の関数実行の時間間隔ハンドルを記録します。
// タイムアウト間隔が経過すると、後の関数を呼び出します。タイムアウトは後でクリアされ、関数を再度呼び出す必要があるかどうかを確認します。
if(!タイムアウト)
タイムアウト = setTimeout(後で待機);
// スロットル変数は、最後の呼び出しの時間間隔が終了したかどうか、つまりスロットル プロセス中かどうかを記録します。
// スロットルは関数が呼び出されるたびに true に設定され、スロットルの必要性を示し、時間間隔が経過すると false に設定されます (whenDone 関数で実装)
if(スロットリング) {
// スロットル プロセス中に複数の呼び出しが行われ、時間間隔が経過したときに関数を自動的に再度呼び出す必要があることを示すステータスが more に記録されます。
もっと = 真;
} それ以外 {
// スロットル プロセス中ではありません。関数を初めて呼び出すか、最後の呼び出しの間隔を超えた可能性があります。関数を直接呼び出すことができます。
結果 = func.apply(context, args);
}
// whenDone を呼び出し、一定時間後にスロットル状態をクリアするために使用されます
whenDone();
// スロットリング変数は、関数が呼び出されたときのスロットル ステータスを記録します。
スロットリング = true;
//呼び出し結果を返す
結果を返します。
};
};
// デバウンス メソッドは、関数のスロットルに使用されるスロットル メソッドに似ています。両者の違いは次のとおりです。
// -- スロットルは関数の実行頻度に焦点を当てます。関数は指定された頻度内で 1 回だけ実行されます。
// -- デバウンス関数は、関数実行間の間隔にさらに注意を払います。つまり、2 つの関数呼び出しの間の時間を指定された時間より短くすることはできません。
// 2 つの関数間の実行間隔が wait より短い場合、タイマーはクリアされて再作成されます。つまり、関数が継続的かつ頻繁に呼び出される場合、関数は特定の呼び出しと呼び出しの間の時間まで実行されません。前の呼び出しはミリ秒以上待機しています。
// debounce 関数は通常、実行に時間がかかる操作を制御するために使用されます。たとえば、ユーザーが入力を完了してから 200 ミリ秒後にユーザーにプロンプトを表示するには、debounce を使用して関数をラップし、それを onkeyup イベントにバインドできます。 。
//------------------------------------------------ ----------------
// @param {Function} func は実行された関数を表します
// @param {Number} wait は、許容される時間間隔を表します。この時間範囲内での繰り返しの呼び出しは、待機ミリ秒ごとに再延期されます。
// @param {ブール値}immediate は、関数が呼び出された後すぐに実行されるかどうかを示します。true はすぐに呼び出されることを意味し、false は、時間が経過したときに呼び出されることを意味します。
// debounce メソッドは関数を返します。この関数は自動的に func を呼び出し、スロットル制御を実行します。
_.debounce = function(関数、待機、即時) {
// タイムアウトは、最後の関数呼び出し (タイマー ハンドル) の実行ステータスを記録するために使用されます。
// タイムアウトが null の場合、最後の呼び出しが終了したことを意味します
var タイムアウト;
// 関数を返し、関数内でスロットル制御を実行します
戻り関数() {
// 関数のコンテキスト オブジェクトとパラメータを保持します
var context = this、args = 引数;
var 後で = function() {
//タイムアウトをnullに設定します
// 許可された時間が経過すると、後の関数が呼び出されます
// この関数を呼び出すと、最後の関数の実行時間が合意された時間間隔を超えたことを示し、この時間以降の後続の呼び出しは許可されます。
タイムアウト = null;
if(!即時)
func.apply(コンテキスト, 引数);
};
// 関数がすぐに実行されるように設定されており、最後の呼び出しの時間が経過した場合は、関数をすぐに呼び出します
if(即時 && !タイムアウト)
func.apply(コンテキスト, 引数);
//関数の呼び出しステータスを確認および設定するためのタイマーを作成します
// タイマーを作成する前に、最後にバインドされた関数が実行されたかどうかに関係なく、最後の setTimeout ハンドルをクリアします。
// この関数が呼び出されたときに、前の関数の実行がまだ開始されていない場合 (通常は imimmediate が false に設定されている場合)、関数の実行時間が遅れるため、タイムアウト ハンドルが再作成されます。
クリアタイムアウト(タイムアウト);
// 許可された時間が経過したら、後の関数を呼び出します
タイムアウト = setTimeout(後で待機);
};
};
// 1 回だけ実行される関数を作成します。関数が繰り返し呼び出された場合は、最初の実行結果が返されます。
// この関数は、ユーザーが使用しているブラウザの種類の取得など、固定データのロジックを取得および計算するために使用されます
_.once = 関数(関数) {
// ran は関数が実行されたかどうかを記録します
//memo は関数の最後の実行結果を記録します
var ran = false、メモ;
戻り関数() {
// 関数が以前に実行されたことがある場合は、最初の実行結果を直接返します
もし(走った)
メモを返す。
実行 = true;
return memo = func.apply(this, argument);
};
};
// 現在の関数をパラメータとしてラッパー関数に渡す関数を返します。
// ラップされた関数では、最初のパラメータを通じて現在の関数を呼び出し、結果を返すことができます
// 通常、複数のプロセス処理関数の低結合結合呼び出しに使用されます。
_.wrap = function(func, ラッパー) {
戻り関数() {
// 現在の関数を最初のパラメータとしてラッパー関数に渡します
var args = [func].concat(slice.call(arguments, 0));
// ラッパー関数の処理結果を返す
戻りwrapper.apply(this, args);
};
};
// 複数の関数を結合します。パラメータの受け渡し順序に従って、後の関数の戻り値がパラメータとして前の関数に渡され、処理が続行されます。
// _.compose(A, B, C); は A(B(C())) と同等です。
// このメソッドの欠点は、関連付けられた関数によって処理されるパラメーターの数が 1 つだけであることです。複数のパラメーターを渡す必要がある場合、それらのパラメーターは配列またはオブジェクト複合データ型を使用して組み立てることができます。
_.compose = function() {
// 関数リストを取得します。すべてのパラメータは関数型でなければなりません
var funcs = 引数;
//呼び出し用の関数ハンドルを返す
戻り関数() {
// 関数を後ろから前へ順番に実行し、記録された戻り値をパラメータとして前の関数に渡して処理を続行します。
var args = 引数;
for(var i = funcs.length - 1; i >= 0; i--) {
args = [funcs[i].apply(this, args)];
}
// 最後の関数呼び出しの戻り値を返します
引数[0]を返します;
};
};
// 呼び出しカウンターとして機能する関数を返します。関数が 回呼び出される (または 回を超える) と、func 関数が実行されます。
// after メソッドは通常、非同期カウンターとして使用されます。たとえば、複数の AJAX リクエストが完了した後に関数を実行する必要がある場合、after を使用して各 AJAX リクエストが完了した後にその関数を呼び出すことができます。
_.after = function(times, func) {
// 時間が指定されていないか無効な場合は、func が直接呼び出されます
if(回 <= 0)
関数を返します;
// カウンタ関数を返す
戻り関数() {
// カウンタ関数 time が呼び出されるたびに 1 ずつデクリメントされます。times を呼び出した後、func 関数を実行し、func 関数の戻り値を返します。
if(--times < 1) {
return func.apply(this, argument);
}
};
};
// オブジェクト関連のメソッド
//----------------
// オブジェクトの属性名のリストを取得します (プロトタイプ チェーン内の属性を除く)
_.keys = ネイティブキー ||
関数(obj) {
if(obj !== オブジェクト(obj))
throw new TypeError('無効なオブジェクト');
var キー = [];
// オブジェクトのすべてのプロパティ名を記録して返します
for(obj の var キー)
if(_.has(obj, key))
キー[キーの長さ] = キー;
キーを返す。
};
// オブジェクト内のすべてのプロパティの値リストを返します (プロトタイプ チェーン内のプロパティを除く)
_.values = 関数(obj) {
return _.map(obj, _.identity);
};
// Function タイプであるオブジェクト内のすべてのプロパティ値のキー リストを取得し、キー名で並べ替えます (プロトタイプ チェーン内のプロパティを含む)
_.functions = _.methods = function(obj) {
変数名 = [];
for(obj の var キー) {
if(_.isFunction(obj[キー]))
names.push(キー);
}
names.sort() を返します。
};
// 1 つ以上のオブジェクトのプロパティ (プロトタイプ チェーン内のプロパティを含む) を obj オブジェクトにコピーし、同じ名前のプロパティがある場合は上書きします。
_.extend = 関数(obj) {
// 各ループパラメータ内の 1 つ以上のオブジェクト
each(slice.call(arguments, 1), function(source) {
// オブジェクト内のすべてのプロパティを obj オブジェクトにコピーまたは上書きします
for(ソース内のvar prop) {
obj[プロップ] = ソース[プロップ];
}
});
オブジェクトを返します。
};
// 新しいオブジェクトを返し、指定されたプロパティを obj から新しいオブジェクトにコピーします
// 2 番目のパラメータは、コピーする必要がある指定された属性名で始まります (複数のパラメータと深い配列をサポートします)
_.pick = function(obj) {
//コピーされた指定された属性を保存するオブジェクトを作成します
var 結果 = {};
// 2 番目のパラメータから始めて、それを配列にマージして属性名のリストを保存します。
each(_. flatten(slice.call(arguments, 1)), function(key) {
// 属性名のリストをループし、属性が obj に存在する場合は、それを結果オブジェクトにコピーします。
if(obj のキー)
結果[キー] = obj[キー];
});
// コピーした結果を返す
結果を返します。
};
// obj に存在しない属性、またはパラメータで指定された 1 つ以上のオブジェクトからブール型に変換した後に false の値を持つ属性を obj にコピーします。
// 通常、オブジェクトにデフォルト値を割り当てるために使用されます
_.defaults = function(obj) {
// 2 番目のパラメータから複数のオブジェクトを指定でき、これらのオブジェクトのプロパティが順番に obj オブジェクトにコピーされます (プロパティが obj オブジェクトに存在しない場合)
each(slice.call(arguments, 1), function(source) {
// 各オブジェクトのすべてのプロパティを反復処理します。
for(ソース内のvar prop) {
// objに存在しない場合、またはBoolean型に変換後の属性値がfalseの場合、その属性をobjにコピー
if(obj[prop] == null)
obj[プロップ] = ソース[プロップ];
}
});
オブジェクトを返します。
};
//obj のコピーを作成し、obj のすべてのプロパティと値のステータスを含む新しいオブジェクトを返します
// clone 関数はディープ コピーをサポートしていません。たとえば、obj のプロパティにオブジェクトが格納されている場合、そのオブジェクトはコピーされません。
// obj が配列の場合、同一の配列オブジェクトが作成されます
_.clone = 関数(obj) {
//非配列およびオブジェクト型のデータはサポートされません
if(!_.isObject(obj))
オブジェクトを返します。
// 配列またはオブジェクトをコピーして返す
_.isArray(obj) を返しますか? obj.slice() : _.extend({}, obj);
};
//関数を実行し、関数にパラメータとして obj を渡します。関数の実行後、最終的に obj オブジェクトが返されます。
// 通常、タップ メソッドはメソッド チェーンを作成するときに使用されます。例:
// _(obj).chain().tap(click).tap(mouseover).tap(mouseout);
_.tap = function(obj, インターセプタ) {
インターセプター(obj);
オブジェクトを返します。
};
// eq 関数は isEqual メソッド内でのみ呼び出され、2 つのデータの値が等しいかどうかを比較するために使用されます。
// === との違いは、eq はデータの値により多くの注意を払うことです。
// 2 つの複合データ型間の比較の場合、それらが同じ参照からのものであるかどうかを比較するだけでなく、詳細な比較 (2 つのオブジェクトの構造とデータの比較) も実行されます。
関数 eq(a, b, スタック) {
// 2 つの単純なデータ型の値が等しいかどうかを確認します
// 複合データ型の場合、同じ参照からのものである場合、それらは等しいとみなされます。
// 比較される値に 0 が含まれる場合、0 === -0 が true であるため、他の値が -0 であるかどうかを確認します。
// そして 1 / 0 == 1 / -0 は真ではありません (1 / 0 の値は無限大、1 / -0 の値は -Infinity であり、Infinity は -Infinity と等しくありません)
if(a === b)
!== 0 || を返します。
// データをBoolean型に変換した後、その値がfalseの場合、2つの値のデータ型が等しいかどうかを判定します(nullは未定義、false、0、および空文字列に等しいため、非定義の場合) -厳密な比較)
if(a == null || b == null)
a === b を返します。
// 比較されるデータが Underscore でカプセル化されたオブジェクトの場合 (_chain 属性を持つオブジェクトは Underscore オブジェクトとみなされます)
// 次に、オブジェクトをアンラップして独自のデータを取得し (_wrapped を通じてアクセス)、独自のデータを比較します。
// それらの関係は、jQuery によってカプセル化された DOM オブジェクトと、ブラウザ自体によって作成された DOM オブジェクトに似ています。
if(a._chain)
a = a._wraped;
if(b._chain)
b = b._wraped;
// オブジェクトがカスタム isEqual メソッドを提供する場合 (Undersocre オブジェクトは前のステップでブロック解除されているため、ここでの isEqual メソッドは Undersocre オブジェクトの isEqual メソッドではありません)
// 次に、オブジェクトのカスタム isEqual メソッドを使用して、別のオブジェクトと比較します。
if(a.isEqual && _.isFunction(a.isEqual))
a.isEqual(b) を返します。
if(b.isEqual && _.isFunction(b.isEqual))
b.isEqual(a) を返します。
// 2 つのデータのデータ型を検証します
// オブジェクト a のデータ型を取得します (Object.prototype.toString メソッド経由)
var className = toString.call(a);
// オブジェクト a のデータ型がオブジェクト b と一致しない場合、2 つのデータ値も一致しないとみなされます。
if(クラス名 != toString.call(b))
false を返します。
// ここで実行すると、比較する必要がある 2 つのデータが複合データ型であり、データ型が等しいことを確認できます。
// スイッチを介してデータのデータ型を確認し、異なるデータ型に対して異なる比較を実行します。
// (配列とオブジェクト型は、後で比較するより深いデータが含まれる可能性があるため、ここには含まれません)
スイッチ (クラス名) {
case '[オブジェクト文字列]':
// 比較対象が文字列型の場合 (a は new String() によって作成された文字列です)
// 次に、B を String オブジェクトに変換して照合します (これらは同じオブジェクトからの参照ではないため、ここでの照合では厳密なデータ型チェックは実行されません)
// 比較のために == を呼び出すと、オブジェクトの toString() メソッドが自動的に呼び出され、2 つの単純なデータ型文字列が返されます。
== String(b) を返します。
ケース '[オブジェクト番号]':
// a を a を通じて Number に変換します。変換前と変換後で a が等しくない場合、a は NaN 型であるとみなされます。
// NaN と NaN は等しくないため、a の値が NaN の場合、単純に a == b を使用して一致させることはできませんが、同じ方法を使用して b が NaN であるかどうかを確認します (つまり、 b != b)。
// a の値が NaN 以外のデータの場合、b が -0 のとき 0 === -0 が成立するため、a が 0 であるかどうかを確認します (実際には、論理的には 2 つの異なるデータに属します)。
戻り値 a != a ? b != b : (a == 0 ? 1 / a == 1 / b : a == b);
ケース '[オブジェクトの日付]':
// 日付型には return や Break が使用されないため、実行は次のステップに進みます (データ型が Boolean 型であるかどうかに関係なく、次のステップで Boolean 型がチェックされるため)。
ケース '[オブジェクト ブール値]':
//日付またはブール型を数値に変換します
// 日付タイプは数値タイムスタンプに変換されます (無効な日付形式は NaN に変換されます)
// ブール型の場合、trueは1に変換され、falseは0に変換されます。
// 2 つの日付またはブール型を比較し、数値に変換した後に等しいかどうかを確認します。
a == b を返します。
ケース '[オブジェクト RegExp]':
// 正規表現タイプ。ソースを通じて式の文字列形式にアクセスします。
// 2 つの式の文字列形式が等しいかどうかをチェックします
// 2 つの式のグローバル プロパティが同じかどうかを確認します (g、i、m を含む)
// 完全に等しい場合、2 つのデータは等しいとみなされます
return a.source == b.source && a.global == b.global && a.multiline == b.multiline && a.ignoreCase == b.ignoreCase;
}// ここまで実行すると、2 つのデータ ab は同じオブジェクト型または配列型である必要があります。
if( a のタイプ != 'オブジェクト' || b のタイプ != 'オブジェクト')
false を返します。
// stack (ヒープ) は、isEqual が eq 関数を呼び出すときに内部的に渡される空の配列です。これは、後でオブジェクトとデータを比較する内部反復で eq メソッドが呼び出されるときにも渡されます。
//length はヒープの長さを記録します
var length = stack.length;
while(長さ--) {
// ヒープ内のオブジェクトがデータ a と一致する場合、等しいとみなされます
if(スタック[長さ] == a)
true を返します。
}
//データaをヒープに追加
stack.push(a);
//いくつかのローカル変数を定義します
var サイズ = 0、結果 = true;
// 再帰によるオブジェクトと配列の詳細な比較
if(クラス名 == '[オブジェクト配列]') {
//比較対象のデータは配列型です
// size は配列の長さを記録します
// result は 2 つの配列の長さを比較して、それらが一致しているかどうかを確認します。長さが一致しない場合は、メソッドの最後に結果 (つまり false) が返されます。
サイズ = a.長さ;
結果 = サイズ == b.length;
// 2 つの配列の長さが同じ場合
if(結果) {
// eq メソッドを呼び出して、配列内の要素を繰り返し比較します (配列に 2 次元配列またはオブジェクトが含まれている場合、eq メソッドは詳細な比較を実行します)
while(サイズ--) {
// 両方の配列に現在のインデックスの要素が含まれていることを確認する場合は、詳細な比較のために eq メソッドを呼び出します (ヒープ データを eq メソッドに渡します)。
// 比較結果を result 変数に格納します。結果が false の場合 (つまり、比較中に取得された特定の要素のデータが矛盾している場合)、反復を停止します。
if(!( result = a のサイズ == b のサイズ && eq(a[サイズ], b[サイズ], スタック)))
壊す;
}
}
} それ以外 {
// 比較されるデータはオブジェクト型です
// 2 つのオブジェクトが同じクラスのインスタンスではない場合 (コンストラクター プロパティを通じて比較)、2 つのオブジェクトは等しくないとみなされます。
if(a の 'constructor' != b の 'constructor' || a.constructor != b.constructor)
false を返します。
// 2 つのオブジェクトのデータを詳細に比較します
for(a の var key) {
if(_.has(a, key)) {
// size は、比較された属性の数を記録するために使用されます。これは、ここで走査されるのは a オブジェクトの属性であり、b オブジェクトの属性のデータを比較するためです。
// オブジェクト b の属性の数がオブジェクト a を超える場合、このロジックは成り立ちますが、2 つのオブジェクトは等しくありません。
サイズ ;
// eq メソッドを繰り返し呼び出して、2 つのオブジェクトの属性値を詳細に比較します
// 比較結果を結果変数に記録し、異なるデータが比較された場合は反復を停止します。
if(!( result = _.has(b, key) && eq(a[key], b[key], stack)))
壊す;
}
}
// 詳細な比較が完了すると、オブジェクト a のすべてのデータとオブジェクト b の同じデータも存在することが確認されます。
// サイズ (オブジェクト属性の長さ) に基づいて、オブジェクト b の属性の数がオブジェクト a と等しいかどうかを確認します。
if(結果) {
// オブジェクト b のすべてのプロパティを走査します
for(b のキー) {
// サイズが 0 に達し (つまり、オブジェクト a の属性の数が走査され)、オブジェクト b にまだ属性が存在する場合、オブジェクト b はオブジェクト a よりも多くの属性を持ちます。
if(_.has(b, key) && !(size--))
壊す;
}
// オブジェクト b がオブジェクト a よりも多くの属性を持っている場合、2 つのオブジェクトは等しくないとみなされます。
結果 = !サイズ;
}
}
// 関数の実行が完了したら、ヒープから最初のデータを削除します (オブジェクトまたは配列を比較する場合、eq メソッドが反復され、ヒープ内に複数のデータが存在する可能性があります)
stack.pop();
//返された結果には、最終的な比較結果が記録されます
結果を返します。
}
// 2 つのデータの値を比較 (複合データ型をサポート)、内部関数 eq の外部メソッド
_.isEqual = function(a, b) {
return eq(a, b, []);
};
// データが空かどうかを確認します。これには、''、false、0、null、未定義、NaN、空の配列 (配列の長さは 0)、空のオブジェクト (オブジェクト自体にはプロパティがありません) が含まれます。
_.isEmpty = function(obj) {
// obj はブール型に変換され、値は false になります
if(obj == null)
true を返します。
// オブジェクトまたは文字列の長さが 0 かどうかを確認します
if(_.isArray(obj) || _.isString(obj))
obj.length === 0 を返します。
// オブジェクトをチェックします (for in ループを使用する場合、オブジェクト自体のプロパティが最初にループされ、続いてプロトタイプ チェーン内のプロパティがループされます)。そのため、最初のプロパティがオブジェクト自体に属している場合、そのオブジェクトは空のオブジェクト
for(obj の var キー)
if(_.has(obj, key))
false を返します。
// すべてのデータ型は検証に合格しておらず、空のデータです
true を返します。
};
// オブジェクトが DOM オブジェクトであるかどうかを確認します
_.isElement = function(obj) {
return !!(obj && obj.nodeType == 1);
};
// オブジェクトが配列型であるかどうかを確認し、最初にホスト環境によって提供される isArray メソッドを呼び出します
_.isArray = ネイティブIsArray ||
関数(obj) {
return toString.call(obj) == '[オブジェクト配列]';
};
// オブジェクトが複合データ型オブジェクト (つまり、非基本データ型 String、Boolean、Number、null、unknown) かどうかを検証します。
// 基本データ型が new によって作成された場合、それはオブジェクト型にも属します
_.isObject = 関数(obj) {
obj を返す === オブジェクト(obj);
};
// データが引数パラメータ オブジェクトであるかどうかを確認します
_.isArguments = function(obj) {
return toString.call(obj) == '[オブジェクト引数]';
};
// isArguments 関数を検証します。実行環境で引数の型データが正常に検証できない場合は、isArguments メソッドを再定義します。
if(!_.isArguments(引数)) {
// 環境が toString を通じて引数の型を検証できない場合は、引数の一意の呼び出し先メソッドを呼び出して検証します。
_.isArguments = function(obj) {
// callee は引数の属性であり、引数が属する関数自体への参照を指します。
return !!(obj && _.has(obj, 'callee'));
};
}
// オブジェクトが関数型であるかどうかを確認します
_.isFunction = function(obj) {
return toString.call(obj) == '[オブジェクト関数]';
};
// オブジェクトが文字列型かどうかを確認します
_.isString = 関数(obj) {
return toString.call(obj) == '[オブジェクト文字列]';
};
// オブジェクトが数値型かどうかを検証します
_.isNumber = function(obj) {
return toString.call(obj) == '[オブジェクト番号]';
};
// 数値が有効な数値であり、有効な範囲 (数値型、負の無限大から正の無限大までの値) があるかどうかを確認します。
_.isFinite = function(obj) {
return _.isNumber(obj) && isFinite(obj);
};
// データの型が NaN であるかどうかを確認します (NaN と NaN だけがすべてのデータと等しいわけではありません)
_.isNaN = 関数(obj) {
obj を返します !== obj;
};
// データの型がブール型かどうかを確認します
_.isBoolean = function(obj) {
// リテラルおよびオブジェクト形式のブール データをサポートします
戻り値 obj === true || obj === false || toString.call(obj) == '[オブジェクト ブール値]';
};
// データが日付型であるかどうかを確認します
_.isDate = 関数(obj) {
return toString.call(obj) == '[オブジェクトの日付]';
};
// データが正規表現タイプであるかどうかを確認します
_.isRegExp = 関数(obj) {
return toString.call(obj) == '[オブジェクト RegExp]';
};
// データが Null 値かどうかを確認します
_.isNull = 関数(obj) {
obj === null を返します。
};
// データが未定義値かどうかを確認します
_.isUnknown = function(obj) {
オブジェクトを返す ===
ボイド0;
};
// プロパティがプロトタイプ チェーンではなくオブジェクト自体に属しているかどうかを確認します
_.has = function(obj, key) {
return hasOwnProperty.call(obj, key);
};
// ユーティリティ関数
// ------------------
// _ (アンダースコア) で指定された Underscore オブジェクトを破棄し、Underscore オブジェクトを返します。これは通常、名前の競合を回避したり、命名方法を標準化するために使用されます。
// 例えば:
// var us = _.noConflict(); // _ (アンダースコア) 命名をキャンセルし、Underscore オブジェクトを us 変数に格納します
// console.log(_); // _ (アンダースコア) は、アンダースコア オブジェクトにアクセスできなくなり、アンダースコアが定義される前の値に戻ります。
_.noConflict = function() {
//previousUnderscore 変数には、Underscore が定義される前の _ (アンダースコア) の値が記録されます。
root._ = 前のアンダースコア;
これを返します。
};
// パラメータと同じ値を返します。通常、データ取得メソッドを関数取得メソッドに変換するために使用されます (メソッドの構築時にデフォルトのプロセッサ関数として内部的に使用されます)。
_.identity = 関数(値) {
戻り値;
};
// 指定された関数を n 回繰り返し実行します (パラメータなし)
_.times = function(n, イテレータ, コンテキスト) {
for(var i = 0; i < n; i )
iterator.call(context, i);
};
// HTML 文字列内の特殊文字を HTML エンティティに変換します (& < を含む)。
_.escape = 関数(文字列) {
return ('' 文字列).replace(/&/g, '&').replace(/</g, '<').replace(/>/g, '>').replace(/ "/g, '"').replace(/'/g, ''').replace(///g, '/');
};
// オブジェクトの属性を指定し、その属性に対応する値を返します。属性が関数に対応する場合は、その関数が実行され、結果が返されます。
_.result = 関数(オブジェクト, プロパティ) {
if(オブジェクト == null)
null を返します。
// オブジェクトの値を取得します
var 値 = オブジェクト[プロパティ];
// 値が関数の場合は実行して返します。それ以外の場合は直接返します。
戻り値 _.isFunction(値) 値.call(オブジェクト) : 値;
};
//一連のカスタム メソッドを Underscore オブジェクトに追加して、Underscore プラグインを拡張します
_.mixin = function(obj) {
//obj は一連のカスタム メソッドを集めたオブジェクトです。ここで、オブジェクトを走査する方法はそれぞれを介して行われます。
each(_.functions(obj), function(name) {
//addToWrapper 関数を通じて Underscore によって構築されたオブジェクトにカスタム メソッドを追加し、オブジェクトベースの呼び出しをサポートします
// 関数呼び出しをサポートするために _ 自体にもメソッドを追加します
addToWrapper(名前, _[名前] = obj[名前]);
});
};
// グローバルに一意の識別子を取得します。識別子は 0 から始まり累積していきます。
var idCounter = 0;
// prefix は識別子の接頭辞を表します。接頭辞が指定されていない場合、識別子は通常、オブジェクトまたは DOM の一意の ID を作成するために使用されます。
_.uniqueId = 関数(プレフィックス) {
var id = idカウンター;
プレフィックスを返しますか? プレフィックス ID : ID;
};
// Define the delimiting symbol of the template, used in the template method
_.templateSettings = {
//Delimiter of JavaScript executable code
evaluate : /<%([sS] ?)%>/g,
// Directly output the delimiter of the variable
interpolate : /<%=([sS] ?)%>/g,
//Delimiter required to output HTML as a string (convert special symbols into string form)
escape : /<%-([sS] ?)%>/g
};
var noMatch = /.^/;
// The escapes object records the correspondence between special symbols and string forms that need to be converted to each other, and is used as an index when the two are converted to each other.
// First define special characters according to string form
var escapes = {
'\' : '\',
"'" : "'",
'r' : 'r',
'n' : 'n',
't' : 't',
'u2028' : 'u2028',
'u2029' : 'u2029'
};
// Traverse all special character strings and record the string form using special characters as keys
for(var p in escapes)
escapes[escapes[p]] = p;
// Define the special symbols that need to be replaced in the template, including backslash, single quote, carriage return, line feed, tab, line separator, paragraph separator
// Used when converting special symbols in a string to string form
var escaper = /\|'|r|n|t|u2028|u2029/g;
// Used when reversing (replacing) special symbols in string form
var unescaper = /\(\|'|r|n|t|u2028|u2029)/g;
//Reverse special symbols in string
// The JavaScript source code that needs to be executed in the template needs to be reversed with special symbols, otherwise if it appears in the form of HTML entities or strings, a syntax error will be thrown
var unescape = function(code) {
return code.replace(unescaper, function(match, escape) {
return escapes[escape];
});
};
// Underscore template parsing method, used to fill data into a template string
// Template parsing process:
// 1. Convert special symbols in the template to strings
// 2. Parse the escape form tag and parse the content into HTML entities
// 3. Parse interpolate form tags and output variables
// 4. Parse the evaluate form tag and create executable JavaScript code
// 5. Generate a processing function that can directly fill in the template after getting the data and return the filled string
// 6. Return the filled string or the handle of the processing function according to the parameters
//------------------
//In the template body, two parameters can be obtained through argments, namely the filling data (named obj) and the Underscore object (named _)
_.template = function(text, data, settings) {
// Template configuration, if no configuration item is specified, the configuration item specified in templateSettings is used.
settings = _.defaults(settings || {}, _.templateSettings);
// Start parsing the template into executable source code
var source = "__p ='" text.replace(escaper, function(match) {
//Convert special symbols to string form
return '\' escapes[match];
}).replace(settings.escape || noMatch, function(match, code) {
// Parse the escape form tag <%- %>, convert the HTML contained in the variable into an HTML entity through the _.escape function
return "' n_.escape(" unescape(code) ") n'";
}).replace(settings.interpolate || noMatch, function(match, code) {
// Parse the interpolate form tag <%= %>, connect the template content as a variable with other strings, and it will be output as a variable
return "' n(" unescape(code) ") n'";
}).replace(settings.evaluate || noMatch, function(match, code) {
// Parse the evaluate form tag <% %>. The JavaScript code that needs to be executed is stored in the evaluate tag. The current string splicing ends here and is executed as JavaScript syntax in a new line, and the following content is used as characters again. The beginning of the string, so the JavaScript code in the evaluate tag can be executed normally.
return "';n" unescape(code) "n;__p ='";
}) "';n";
if(!settings.variable)
source = 'with(obj||{}){n' source '}n';
source = "var __p='';" "var print=function(){__p =Array.prototype.join.call(arguments, '')};n" source "return __p;n";
// Create a function, use the source code as the function execution body, and pass obj and Underscore as parameters to the function
var render = new Function(settings.variable || 'obj', '_', source);
// If the fill data of the template is specified, replace the template content and return the replaced result
if(data)
return render(data, _);
// If no fill data is specified, returns a function that replaces the received data into the template
// If the same template will be filled multiple times in the program, it is recommended not to specify the filling data in the first call. After obtaining the reference of the processing function, calling it directly will improve the operating efficiency.
var template = function(data) {
return render.call(this, data, _);
};
//Add the created source code string to the function object, generally used for debugging and testing
template.source = 'function(' (settings.variable || 'obj') '){n' source '}';
//If no filling data is specified, return the processing function handle
return template;
};
// Support method chain operation of Underscore object, please refer to wrapper.prototype.chain
_.chain = function(obj) {
return _(obj).chain();
};
// Underscore object encapsulates related methods
// ---------------
//Create a wrapper to wrap some raw data
// All undersocre objects are constructed and encapsulated internally through the wrapper function
//The internal relationship between Underscore and wrapper:
// - Define the variable _ internally, and add Underscore related methods to _, so that functional calls can be supported, such as _.bind()
// - Define the wrapper class internally and point the prototype object of _ to the prototype of the wrapper class
// -Add Underscore related methods to the wrapper prototype, and the created _ object will have Underscore methods
// - Add Array.prototype related methods to the wrapper prototype, and the created _ object will have the methods in Array.prototype
// -new _() actually creates and returns a wrapper() object, stores the original array into the _wrapped variable, and calls the corresponding method with the original value as the first parameter.
var wrapper = function(obj) {
//The original data is stored in the _wrapped attribute of the wrapped object
this._wrapped = obj;
};
// Point the prototype object of Underscore to the prototype of wrapper, so by adding methods like the wrapper prototype, the Underscore object will also have the same method.
_.prototype = wrapper.prototype;
//Return an object. If the current Underscore calls the chain() method (that is, the _chain attribute is true), then a wrapped Underscore object is returned, otherwise the object itself is returned.
// result function
ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7378
7378
 15
1628
14
1357
52
1267
25
1216
29
15
1628
14
1357
52
1267
25
1216
29

 Edge ブラウザに付属の翻訳 Web ページが見つからない場合はどうすればよいですか?
Mar 14, 2024 pm 08:50 PM
Edge ブラウザに付属の翻訳 Web ページが見つからない場合はどうすればよいですか?
Mar 14, 2024 pm 08:50 PM
エッジブラウザには翻訳機能が搭載されており、いつでもどこでも翻訳できるため、ユーザーは非常に便利ですが、多くのユーザーは、組み込みの翻訳 Web ページが見つからないという意見を述べています。私が持ってきた翻訳ページがありませんか?このサイトでは、Edge ブラウザーに付属の翻訳された Web ページが見つからない場合に復元する方法を紹介します。 Edge ブラウザーに付属の翻訳 Web ページが表示されない場合の復元方法 1. 翻訳機能が有効になっているかどうかを確認します。Edge ブラウザーで、右上隅にある 3 つの点のアイコンをクリックし、[設定] オプションを選択します。設定ページの左側で、言語オプションを選択します。必ず「翻訳(&R)」してください
 字幕なしで映画を見ても心配しないでください。 Xiaomi、日本語と韓国語の翻訳のためのリアルタイム字幕Xiaoai Translationの開始を発表
Jul 22, 2024 pm 02:11 PM
字幕なしで映画を見ても心配しないでください。 Xiaomi、日本語と韓国語の翻訳のためのリアルタイム字幕Xiaoai Translationの開始を発表
Jul 22, 2024 pm 02:11 PM
7月22日のニュースによると、今日、Xiaomi ThePaper OSの公式Weiboは、Xiaoai翻訳が日本語と韓国語の翻訳にアップグレードされ、字幕なしのビデオやライブ会議を文字起こしして翻訳できるようになったと発表しました。リアルタイムで。対面同時通訳では、中国語、英語、日本語、韓国語、ロシア語、ポルトガル語、スペイン語、イタリア語、フランス語、ドイツ語、インドネシア語、ヒンディー語を含む 12 言語への翻訳がサポートされています。上記の機能は現在、次の 3 つの新しい携帯電話のみをサポートしています: Xiaomi MIX Fold 4 Xiaomi MIX Flip Redmi K70 Extreme Edition 2021 年には日本語と韓国語の翻訳に Xiao Ai の AI 字幕が追加される予定であると報告されています。 AI 字幕は、Xiaomi が自社開発した同時通訳技術を使用し、より高速で安定した正確な字幕読み取り体験を提供します。 1. 公式声明によると、Xiaoai Translator はオーディオおよびビデオ会場でのみ使用できるわけではありません
 Sogou ブラウザを翻訳する方法
Feb 01, 2024 am 11:09 AM
Sogou ブラウザを翻訳する方法
Feb 01, 2024 am 11:09 AM
Sogou ブラウザはどのように翻訳しますか?普段、Sogou ブラウザを使って情報を確認していると、すべて英語の Web サイトに遭遇します。英語が理解できないため、Web サイトを閲覧するのは非常に難しく、これも非常に不便です。あなたはこの状況に遭遇します! Sogou Browser には翻訳ボタンが組み込まれています。ワンクリックするだけで、Sogou Browser は Web ページ全体を自動的に翻訳します。操作方法がわからない場合は、Sogou Browser で翻訳する具体的な手順を編集者がまとめていますので、フォローして読み進めてください。 Sogou Browser を翻訳する方法 1. Sogou Browser を開き、右上隅の翻訳アイコンをクリックします 2. 翻訳テキストの種類を選択し、翻訳する必要があるテキストを入力します 3. Sogou Browser がテキストを自動的に翻訳します。この時点で、上記総合ブラウジングの操作は完了です。
 Google Chromeの組み込み翻訳が失敗する問題を解決するにはどうすればよいですか?
Mar 13, 2024 pm 08:46 PM
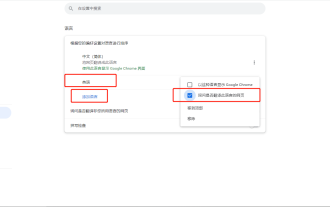
Google Chromeの組み込み翻訳が失敗する問題を解決するにはどうすればよいですか?
Mar 13, 2024 pm 08:46 PM
ブラウザには翻訳機能が搭載されていることが多いので、外国語のサイトを閲覧しても理解できないという心配はありません! Google Chromeも例外ではありませんが、一部のユーザーは、Google Chromeの翻訳機能を開いたときに、応答がなかったり、失敗したりすることがあります。私が見つけた最新の解決策を試してみてください。操作チュートリアル: 右上隅の 3 つの点をクリックし、[設定] をクリックします。 [言語の追加] をクリックし、英語と中国語を追加し、次の設定を行います。英語の設定では、Web ページをこの言語で翻訳するかどうかを尋ねられます。中国語の設定では、この言語で Web ページが表示されます。中国語はその前に先頭に移動する必要があります。をデフォルトの言語として設定できます。 Web ページを開いて翻訳オプションが表示されない場合は、右クリックして [中国語翻訳] を選択し、[OK] をクリックします。
 JavaScript ベースのリアルタイム翻訳ツールの構築
Aug 09, 2023 pm 07:22 PM
JavaScript ベースのリアルタイム翻訳ツールの構築
Aug 09, 2023 pm 07:22 PM
JavaScript ベースのリアルタイム翻訳ツールの構築 はじめに グローバル化の需要が高まり、国境を越えた交流や交換が頻繁に行われるようになったことで、リアルタイム翻訳ツールは非常に重要なアプリケーションとなっています。 JavaScript といくつかの既存の API を活用して、シンプルだが便利なリアルタイム翻訳ツールを構築できます。この記事では、JavaScript をベースにこの機能を実装する方法をコード例とともに紹介します。実装手順 ステップ 1: HTML 構造の作成 まず、単純な HTML を作成する必要があります。
 なぜGoogle Chromeは中国語を翻訳できないのでしょうか?
Mar 11, 2024 pm 04:04 PM
なぜGoogle Chromeは中国語を翻訳できないのでしょうか?
Mar 11, 2024 pm 04:04 PM
なぜGoogle Chromeは中国語を翻訳できないのでしょうか?ご存知のとおり、Google Chrome は翻訳機能が組み込まれたブラウザの 1 つであり、このブラウザで他国で書かれたページを閲覧すると、ブラウザはそのページを自動的に中国語に翻訳します。最近、一部のユーザーが中国語に翻訳したと言っています。現時点では設定で修正する必要があります。次に、編集者がGoogle Chromeが中国語に翻訳できない問題の解決策を紹介しますので、興味のある友達はぜひ見に来てください。 Google Chrome で中国語の解決策を翻訳できない 1. ローカルの hosts ファイルを変更します。hosts は拡張子のないシステム ファイルです。メモ帳などのツールで開くことができます。主な機能は、IP アドレスとホスト名の間のマッピング関係を定義することです。マッピングIPアドレスです
 Sogou Browser が Web ページを翻訳できない問題の解決方法
Jan 29, 2024 pm 09:18 PM
Sogou Browser が Web ページを翻訳できない問題の解決方法
Jan 29, 2024 pm 09:18 PM
Sogou Browser がこの Web ページを翻訳できない場合はどうすればよいですか? Sogou Browser は非常に使いやすい多機能ブラウザで、Web ページの翻訳機能が非常に強力で、勉強や仕事でのほとんどの悩みを解決することができます。しかし、一部の友人から、Sogou Browser にはこの Web ページを翻訳できないという問題があるとの報告がありました。これは不適切な操作が原因である可能性があります。翻訳機能を正しく操作するだけで十分です。以下のエディターで解決できます。このページの解決策を翻訳してください。 Sogou Browser はこの Web ページを翻訳できません。解決方法 1: 1. Sogou Browser をダウンロードしてインストールします。 2. Sogou Browser を開きます。 3. 英語の Web サイトを開きます。 4. Web サイトを開いたら、右上隅の翻訳アイコンをクリックします。 5. [翻訳] を選択します。テキストを入力し、「現在の Web ページを翻訳」をクリックします 6
 iOS 17.2: iPhone のアクションボタンを使用して音声を翻訳する方法
Dec 15, 2023 pm 11:21 PM
iOS 17.2: iPhone のアクションボタンを使用して音声を翻訳する方法
Dec 15, 2023 pm 11:21 PM
iOS 17.2 では、iPhone のアクション ボタンの新しいカスタム翻訳オプションでコミュニケーションの障壁を克服します。使い方については続きを読んでください。 iPhone 15 Pro などのアクション ボタンを備えた iPhone をお持ちの場合、Apple の iOS 17.2 ソフトウェア アップデートによりボタンに新しい翻訳オプションが追加され、ライブ会話を複数の言語に翻訳できるようになります。 Apple によれば、翻訳は正確であるだけでなく、文脈を認識しており、ニュアンスや話し言葉が効果的に捉えられているとのことです。この機能は、旅行者、学生、言語を学習している人にとってはありがたいものです。翻訳機能を使用する前に、翻訳先の言語を必ず選択してください。これは、Apple の組み込み翻訳アプリを通じて行うことができます。
