

国内の大学がSoraのようなモデルVDTを構築、ユニバーサルビデオ拡散トランスがICLR 2024に採択


- #論文タイトル: VDT: マスク モデリングによる汎用ビデオ拡散トランス
- 記事アドレス: Openreview: https://openreview.net/pdf?id=Un0rgm9f04
- arXiv アドレス: https://arxiv.org/abs/2305.13311
- プロジェクトアドレス: VDT: マスクモデリングによる汎用ビデオ拡散トランスフォーマー
- コードアドレス: https://github.com/RERV/VDT# ###################1. VDT の優位性と革新
モデルが世界の知識 (時空関係や物理法則など) を学習 (または記憶) した場合にのみ、現実世界と一致するビデオを生成できます。したがって、モデルの能力がビデオの普及の重要な要素になります。 Transformer は拡張性が高いことが証明されています。たとえば、PaLM モデルには最大 540B のパラメータがありますが、当時の最大の 2D U-Net モデル サイズはわずか 2.6B パラメータ (SDXL) でした。そのため、Transformer は 3D U よりも適しています。 -Net.ビデオ生成の課題。
ビデオ生成の分野には、無条件生成、ビデオ予測、補間、テキストから画像への生成などの複数のタスクが含まれます。これまでの研究は単一のタスクに焦点を当てていることが多く、下流のタスクを微調整するための特殊なモジュールの導入が必要になることがよくありました。さらに、これらのタスクには、フレームやモダリティによって異なる可能性があるさまざまな条件付き情報が含まれるため、さまざまな入力長やモダリティを処理できる強力なアーキテクチャが必要です。 Transformer の導入により、これらのタスクを統合できます。 - #VDT の革新には主に次の側面が含まれます。
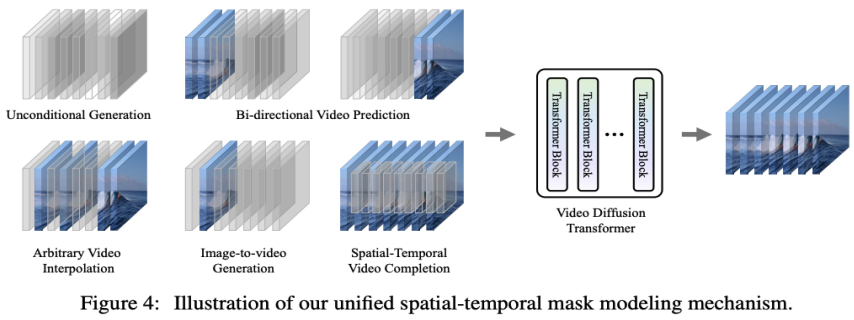
- #VDT によるさまざまなビデオ生成タスクの処理を可能にし、技術の広範な適用を実現する、統合時空間マスク モデリング マシンを提案します# ##。単純なトークン空間スプライシングなどの VDT の柔軟な条件付き情報処理方法は、さまざまな長さや形式の情報を効果的に統合します。同時に、本研究で提案した時空間マスクモデリング機構と組み合わせることで、VDTはモデル構造を変更することなく無条件生成、映像後続フレーム予測、フレーム補間、画像生成に適用できる汎用的な映像普及ツールとなった。 . ビデオやビデオ画面の完成など、さまざまなビデオ生成タスク。
VDT フレームワークは Sora のフレームワークに非常に似ており、次の部分で構成されています: 入出力機能。 VDT の目標は、サイズ H×W のビデオの F フレームで構成される F×H×W×3 ビデオ セグメントを生成することです。ただし、生のピクセルが VDT への入力として使用される場合、特に F が大きい場合、計算が非常に複雑になります。この問題を解決するために、VDT は潜在拡散モデル (LDM) にヒントを得て、事前トレーニングされた VAE トークナイザーを使用してビデオを潜在空間に投影します。入力と出力の潜在特徴/ノイズのベクトル次元を F×H/8×W/8×C に削減することで、VDT のトレーニングと推論の速度が向上します。ここで、F フレームの潜在特徴のサイズは H/8×W です。 /8 .ここで、8 は VAE トークナイザーのダウンサンプリング レートであり、C は潜在的な特徴の次元を表します。 線形埋め込み。 Vision Transformer アプローチに従って、VDT は潜在ビデオ特徴表現をサイズ N×N の重複しないパッチに分割します。 時空変換ブロック。ビデオ モデリングにおける時空間的自己注意の成功に触発され、VDT は時間的次元モデリング機能を取得するために、時間的注意レイヤーをトランスフォーマー ブロックに挿入しました。具体的には、各トランスフォーマー ブロックは、上の図に示すように、マルチヘッドの時間的アテンション、マルチヘッドの空間的アテンション、および完全に接続されたフィードフォワード ネットワークで構成されます。 Sora が公開した最新の技術レポートを比較すると、実装の詳細において VDT と Sora の間にはいくつかの微妙な違いがあるだけであることがわかります。
まず、VDT はアテンション メカニズムを空間次元と時間次元で別々に処理する手法を採用していますが、Sora は時間次元と空間次元を統合し、単一のアテンション メカニズムを使用します。それを処理するために。この注意の分離アプローチはビデオ分野では非常に一般的になっており、ビデオ メモリの制約下での妥協の選択肢として見られることがよくあります。 VDT は、コンピューティング リソースが限られているため、分割注意を使用することを選択します。 Sora の強力なビデオ ダイナミック機能は、空間と時間の全体的な注意メカニズムから来ている可能性があります。
#第二に、VDT とは異なり、Sora はテキスト条件の融合も考慮しています。また、Transformer (DiT など) に基づいたテキスト条件付き融合に関する以前の研究もあります。Sora はそのモジュールにクロスアテンション メカニズムをさらに追加する可能性があると推測されています。もちろん、条件付き入力の形式としてテキストとノイズを直接接続することもできます。という可能性も潜在的にあります。
VDT の研究プロセス中に、に置き換えました。これにより、ビデオ拡散タスクにおける Transformer の有効性が検証され、拡張が容易で継続性が向上するという利点が示されただけでなく、その潜在的な価値についてさらに深く考えるきっかけにもなりました。
GPT モデルの成功と自己回帰 (AR) モデルの普及により、研究者はビデオ生成の分野での Transformer のより深い応用を模索し始めました。視覚的知性を実現する新しい方法を提供できるかどうかを検討してください。ビデオ生成の分野には、ビデオ予測という密接に関連したタスクがあります。視覚的知性への道として次のビデオ フレームを予測するというアイデアは単純に見えるかもしれませんが、実際には多くの研究者の間で共通の懸念事項です。
この考察に基づいて、研究者はビデオ予測タスクにモデルをさらに適応させ、最適化したいと考えています。ビデオ予測タスクは、条件付き生成とみなすこともできます。指定された条件付きフレームはビデオの最初の数フレームです。 VDT では主に次の 3 つの条件生成方法が考慮されます。アダプティブ レイヤーの正規化。ビデオ予測を達成する簡単な方法は、時間情報を拡散プロセスに統合する方法と同様に、条件付きフレームの特徴を VDT ブロックのレイヤー正規化に統合することです。 クロスアテンション。研究者らは、ビデオ予測スキームとしてクロスアテンションを使用することも検討しています。このスキームでは、条件付きフレームがキーと値として使用され、ノイズ フレームがクエリとして使用されます。これにより、条件付き情報とノイズ フレームの融合が可能になります。クロスアテンション層に入る前に、VAE トークナイザーを使用して条件付きフレームの特徴を抽出し、パッチを適用します。一方、VDT が条件付きフレーム内の対応する情報を学習できるように、空間的および時間的位置の埋め込みも追加されています。 トークンのスプライシング。 VDT モデルは純粋な Transformer アーキテクチャを採用しているため、条件付きフレームを入力トークンとして直接使用することは、VDT にとってより直観的な方法です。これは、条件付きフレーム (潜在的な特徴) とノイズ フレームをトークン レベルで連結することで実現され、VDT に供給されます。次に、図 3 (b) に示すように、VDT の出力フレーム シーケンスを分割し、予測フレームを拡散処理に使用しました。研究者らは、このスキームが最初の 2 つの方法と比較して最速の収束速度を示し、最終結果で優れたパフォーマンスを提供することを発見しました。さらに研究者らは、トレーニング中に固定長の条件付きフレームが使用された場合でも、VDT は入力および出力の一貫した予測特徴として任意の長さの条件付きフレームを受け入れることができることを発見しました。 VDT のフレームワークでは、ビデオ予測タスクを達成するためにネットワーク構造に変更を加える必要はなく、モデルの入力のみが必要です。変えられること。この発見は直観的な疑問につながります: このスケーラビリティをさらに活用して、追加のモジュールやパラメータを導入することなく、VDT をより多様なビデオ生成タスク (画像生成ビデオなど) に拡張できないか 。 無条件生成とビデオ予測における VDT の機能を確認すると、唯一の違いは入力特徴のタイプにあります。具体的には、入力は純粋にノイズを含む潜在フィーチャ、または条件付き潜在フィーチャとノイズを含む潜在フィーチャの連結である可能性があります。次に、研究者は、以下の図 4 に示すように、条件付き入力を統合するために統合時空間マスク モデリングを導入しました。 VDT の性能評価 
上記の方法により、VDT モデルは無条件のビデオ生成とビデオ予測タスクをシームレスに処理できるだけでなく、入力機能を調整するだけで、ビデオフレーム補間などの幅広いビデオ生成分野に拡張できます。この柔軟性と拡張性の実施形態は、VDTフレームワークの強力な可能性を実証し、将来のビデオ生成技術に新たな方向性と可能性を提供する。
#研究者らは、生成モデル VDT による単純な物理法則のシミュレーションも調査しました。彼らは Physion データセットで実験を実施しました。この実験では、VDT は最初の 8 フレームを条件付きフレームとして使用し、次の 8 フレームを予測します。最初の例 (上の 2 行) と 3 番目の例 (下の 2 行) では、VDT は、放物線の軌道に沿って移動するボールと、平面上を転がって円柱に衝突するボールを含む物理プロセスをうまくシミュレートしています。 2 番目の例 (中央の 2 行) では、ボールがシリンダーに衝突する前に停止するときに、VDT がボールの速度/運動量をキャプチャします。これは、Transformer アーキテクチャが特定の物理法則を学習できることを証明しています。VDT はネットワーク構造を部分的に除去します。モデルのパフォーマンスは GFlops に強く関係しており、モデル構造自体の一部の詳細は大きな影響を与えていないことがわかり、これは DiT の調査結果とも一致しています。 研究者らは、VDT モデルについていくつかの構造アブレーション研究も実施しました。結果は、パッチサイズを減らし、レイヤーの数を増やし、隠しサイズを増やすと、モデルのパフォーマンスをさらに向上できることがわかります。時間的および空間的アテンションの位置とアテンション ヘッドの数は、モデルの結果にほとんど影響を与えません。いくつかの設計上のトレードオフが必要ですが、全体としては、同じ GFlops を維持しながらモデルのパフォーマンスに大きな違いはありません。ただし、GFlops が増加すると結果が向上し、VDT またはトランスフォーマー アーキテクチャの拡張性が実証されます。 #VDT のテスト結果は、ビデオ データ生成の処理における Transformer アーキテクチャの有効性と柔軟性を実証しています。コンピューティング リソースの制限により、VDT 実験はいくつかの小規模な学術データセットに対してのみ行われました。私たちは、VDT に基づくビデオ生成技術の新たな方向性と応用をさらに探求するための今後の研究を楽しみにしています。また、中国企業ができるだけ早く国産の Sora モデルを発売することを期待しています。

以上が国内の大学がSoraのようなモデルVDTを構築、ユニバーサルビデオ拡散トランスがICLR 2024に採択の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 DeepMind ロボットが卓球をすると、フォアハンドとバックハンドが空中に滑り出し、人間の初心者を完全に打ち負かしました
Aug 09, 2024 pm 04:01 PM
DeepMind ロボットが卓球をすると、フォアハンドとバックハンドが空中に滑り出し、人間の初心者を完全に打ち負かしました
Aug 09, 2024 pm 04:01 PM
でももしかしたら公園の老人には勝てないかもしれない?パリオリンピックの真っ最中で、卓球が注目を集めています。同時に、ロボットは卓球のプレーにも新たな進歩をもたらしました。先ほど、DeepMind は、卓球競技において人間のアマチュア選手のレベルに到達できる初の学習ロボット エージェントを提案しました。論文のアドレス: https://arxiv.org/pdf/2408.03906 DeepMind ロボットは卓球でどれくらい優れていますか?おそらく人間のアマチュアプレーヤーと同等です: フォアハンドとバックハンドの両方: 相手はさまざまなプレースタイルを使用しますが、ロボットもそれに耐えることができます: さまざまなスピンでサーブを受ける: ただし、ゲームの激しさはそれほど激しくないようです公園の老人。ロボット、卓球用
 初のメカニカルクロー!元羅宝は2024年の世界ロボット会議に登場し、家庭に入ることができる初のチェスロボットを発表した
Aug 21, 2024 pm 07:33 PM
初のメカニカルクロー!元羅宝は2024年の世界ロボット会議に登場し、家庭に入ることができる初のチェスロボットを発表した
Aug 21, 2024 pm 07:33 PM
8月21日、2024年世界ロボット会議が北京で盛大に開催された。 SenseTimeのホームロボットブランド「Yuanluobot SenseRobot」は、全製品ファミリーを発表し、最近、世界初の家庭用チェスロボットとなるYuanluobot AIチェスプレイロボット - Chess Professional Edition(以下、「Yuanluobot SenseRobot」という)をリリースした。家。 Yuanluobo の 3 番目のチェス対局ロボット製品である新しい Guxiang ロボットは、AI およびエンジニアリング機械において多くの特別な技術アップグレードと革新を経て、初めて 3 次元のチェスの駒を拾う機能を実現しました。家庭用ロボットの機械的な爪を通して、チェスの対局、全員でのチェスの対局、記譜のレビューなどの人間と機械の機能を実行します。
 クロードも怠け者になってしまった!ネチズン: 自分に休日を与える方法を学びましょう
Sep 02, 2024 pm 01:56 PM
クロードも怠け者になってしまった!ネチズン: 自分に休日を与える方法を学びましょう
Sep 02, 2024 pm 01:56 PM
もうすぐ学校が始まり、新学期を迎える生徒だけでなく、大型AIモデルも気を付けなければなりません。少し前、レディットはクロードが怠け者になったと不満を漏らすネチズンでいっぱいだった。 「レベルが大幅に低下し、頻繁に停止し、出力も非常に短くなりました。リリースの最初の週は、4 ページの文書全体を一度に翻訳できましたが、今では 0.5 ページの出力さえできません」 !」 https://www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ というタイトルの投稿で、「クロードには完全に失望しました」という内容でいっぱいだった。
 世界ロボット会議で「未来の高齢者介護の希望」を担う家庭用ロボットを囲みました
Aug 22, 2024 pm 10:35 PM
世界ロボット会議で「未来の高齢者介護の希望」を担う家庭用ロボットを囲みました
Aug 22, 2024 pm 10:35 PM
北京で開催中の世界ロボット会議では、人型ロボットの展示が絶対的な注目となっているスターダストインテリジェントのブースでは、AIロボットアシスタントS1がダルシマー、武道、書道の3大パフォーマンスを披露した。文武両道を備えた 1 つの展示エリアには、多くの専門的な聴衆とメディアが集まりました。弾性ストリングのエレガントな演奏により、S1 は、スピード、強さ、正確さを備えた繊細な操作と絶対的なコントロールを発揮します。 CCTVニュースは、「書道」の背後にある模倣学習とインテリジェント制御に関する特別レポートを実施し、同社の創設者ライ・ジエ氏は、滑らかな動きの背後にあるハードウェア側が最高の力制御と最も人間らしい身体指標(速度、負荷)を追求していると説明した。など)、AI側では人の実際の動きのデータが収集され、強い状況に遭遇したときにロボットがより強くなり、急速に進化することを学習することができます。そしてアジャイル
 Li Feifei 氏のチームは、ロボットに空間知能を与え、GPT-4o を統合する ReKep を提案しました
Sep 03, 2024 pm 05:18 PM
Li Feifei 氏のチームは、ロボットに空間知能を与え、GPT-4o を統合する ReKep を提案しました
Sep 03, 2024 pm 05:18 PM
ビジョンとロボット学習の緊密な統合。最近話題の1X人型ロボットNEOと合わせて、2つのロボットハンドがスムーズに連携して服をたたむ、お茶を入れる、靴を詰めるといった動作をしていると、いよいよロボットの時代が到来するのではないかと感じられるかもしれません。実際、これらの滑らかな動きは、高度なロボット技術 + 精緻なフレーム設計 + マルチモーダル大型モデルの成果です。有用なロボットは多くの場合、環境との複雑かつ絶妙な相互作用を必要とし、環境は空間領域および時間領域の制約として表現できることがわかっています。たとえば、ロボットにお茶を注いでもらいたい場合、ロボットはまずティーポットのハンドルを掴んで、お茶をこぼさないように垂直に保ち、次にポットの口がカップの口と揃うまでスムーズに動かす必要があります。 、そしてティーポットを一定の角度に傾けます。これ
 ACL 2024 賞の発表: HuaTech による Oracle 解読に関する最優秀論文の 1 つ、GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 賞の発表: HuaTech による Oracle 解読に関する最優秀論文の 1 つ、GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
貢献者はこの ACL カンファレンスから多くのことを学びました。 6日間のACL2024がタイのバンコクで開催されています。 ACL は、計算言語学と自然言語処理の分野におけるトップの国際会議で、国際計算言語学協会が主催し、毎年開催されます。 ACL は NLP 分野における学術的影響力において常に第一位にランクされており、CCF-A 推奨会議でもあります。今年の ACL カンファレンスは 62 回目であり、NLP 分野における 400 以上の最先端の作品が寄せられました。昨日の午後、カンファレンスは最優秀論文およびその他の賞を発表しました。今回の優秀論文賞は7件(未発表2件)、最優秀テーマ論文賞1件、優秀論文賞35件です。このカンファレンスでは、3 つの Resource Paper Award (ResourceAward) と Social Impact Award (
 宏蒙スマートトラベルS9とフルシナリオ新製品発売カンファレンス、多数の大ヒット新製品が一緒にリリースされました
Aug 08, 2024 am 07:02 AM
宏蒙スマートトラベルS9とフルシナリオ新製品発売カンファレンス、多数の大ヒット新製品が一緒にリリースされました
Aug 08, 2024 am 07:02 AM
今日の午後、Hongmeng Zhixingは新しいブランドと新車を正式に歓迎しました。 8月6日、ファーウェイはHongmeng Smart Xingxing S9およびファーウェイのフルシナリオ新製品発表カンファレンスを開催し、パノラマスマートフラッグシップセダンXiangjie S9、新しいM7ProおよびHuawei novaFlip、MatePad Pro 12.2インチ、新しいMatePad Air、Huawei Bisheng Withを発表しました。レーザー プリンタ X1 シリーズ、FreeBuds6i、WATCHFIT3、スマート スクリーン S5Pro など、スマート トラベル、スマート オフィスからスマート ウェアに至るまで、多くの新しいオールシナリオ スマート製品を開発し、ファーウェイは消費者にスマートな体験を提供するフル シナリオのスマート エコシステムを構築し続けています。すべてのインターネット。宏孟志興氏:スマートカー業界のアップグレードを促進するための徹底的な権限付与 ファーウェイは中国の自動車業界パートナーと提携して、
 AI の使用 | Microsoft CEO のクレイジーなアムウェイ AI ゲームは私を何千回も苦しめた
Aug 14, 2024 am 12:00 AM
AI の使用 | Microsoft CEO のクレイジーなアムウェイ AI ゲームは私を何千回も苦しめた
Aug 14, 2024 am 12:00 AM
Machine Power Report 編集者: Yang Wen 大型モデルや AIGC に代表される人工知能の波は、私たちの生活や働き方を静かに変えていますが、ほとんどの人はまだその使い方を知りません。そこで、直感的で興味深く簡潔な人工知能のユースケースを通じてAIの活用方法を詳しく紹介し、皆様の思考を刺激するコラム「AI in Use」を立ち上げました。また、読者が革新的な実践的な使用例を提出することも歓迎します。なんと、AIは本当に天才になってしまったのです。最近、AIが生成した写真の真贋を見分けるのが難しいと話題になっています。 (詳しくはこちら:AI活用中 | 3ステップでAI美女になり、1秒でAIに元に戻される) インターネット上で人気のAI Google ladyのほかにも、さまざまなFLUXジェネレーターが登場しています。ソーシャルプラットフォーム上に出現した
