
 テクノロジー周辺機器
AI
AIの最下層に侵入せよ! NUS Youyang のチームは拡散モデルを使用してニューラル ネットワーク パラメーターを構築しており、LeCun はそれを気に入っています
テクノロジー周辺機器
AI
AIの最下層に侵入せよ! NUS Youyang のチームは拡散モデルを使用してニューラル ネットワーク パラメーターを構築しており、LeCun はそれを気に入っています
AIの最下層に侵入せよ! NUS Youyang のチームは拡散モデルを使用してニューラル ネットワーク パラメーターを構築しており、LeCun はそれを気に入っています

拡散モデルは、主要な新しいアプリケーションの到来をもたらしました -
Sora がビデオを生成するのと同じように、ニューラル ネットワークのパラメーターを生成し、AI の最下層に直接浸透します。
これは、シンガポール国立大学の You Yang 教授のチームと UCB、メタ AI 研究所、その他の機関による最新のオープンソース研究結果です。

具体的には、研究チームはニューラル ネットワーク パラメーターを生成するための拡散モデル p(arameter)-diff を提案しました。
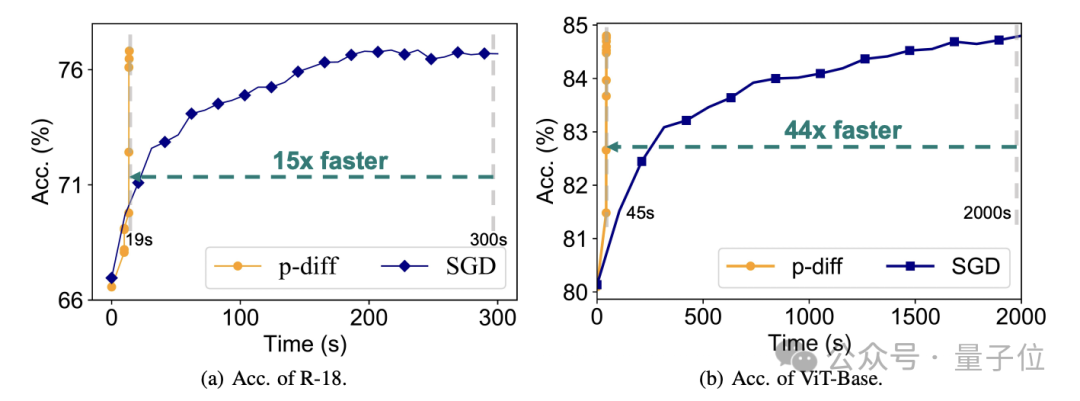
これを使用してネットワーク パラメーターを生成すると、速度は直接トレーニングよりも最大 44 倍速く、パフォーマンスも劣りません。
このモデルがリリースされると、すぐに AI コミュニティで激しい議論が巻き起こり、サークルの専門家たちは、一般の人が Sora を見たときと同じように、このモデルに対して驚くべき態度を示しました。
これは基本的にAIが新しいAIを生み出すのと同じだ、と真っ向から叫ぶ人もいた。

AI の巨人 LeCun も、その結果を見て、本当にかわいいアイデアだと称賛しました。
実は、p-diff も Sora と同じ重要性を持っており、同じ研究室の Fuzhao Xue 博士 (Xue Fuzhao) が詳しく説明しています:
Sora は高次元データ、つまりビデオを生成し、Sora をワールド シミュレーター (1 次元からの AGI に近い) にします。
そして、この取り組みであるニューラル ネットワークの普及は、モデル内でパラメーターを生成することができ、別の新しい重要な次元から AGI に向けて移行する、メタワールドクラスの学習者/オプティマイザーになる可能性を秘めています。

本題に戻りますが、p-diff はどのようにしてニューラル ネットワーク パラメーターを生成するのでしょうか?
オートエンコーダと拡散モデルの組み合わせ
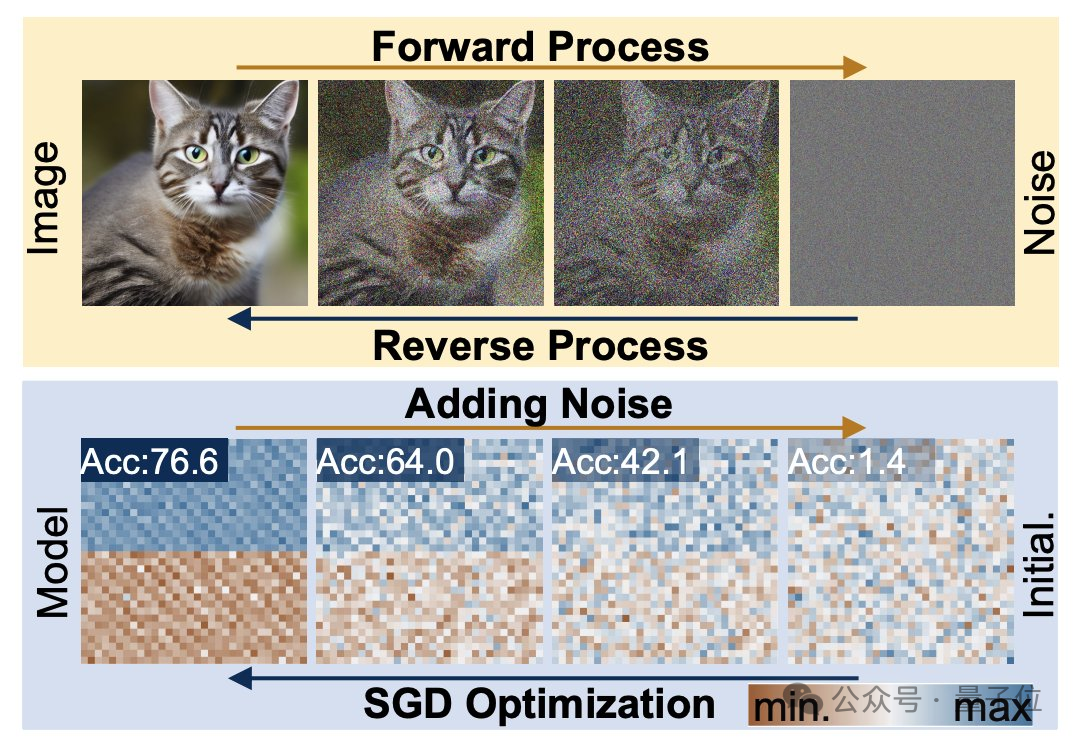
この問題を明確にするには、まず拡散モデルとニューラル ネットワークの動作特性を理解する必要があります。
拡散生成プロセスは、ランダムな分布から高度に特異的な分布への変換であり、複合ノイズの追加により、視覚情報は単純なノイズ分布に削減されます。
ニューラル ネットワークのトレーニングもこの変換プロセスに従い、ノイズの追加によって劣化する可能性があります。この機能に触発されて、研究者は p-diff 法を提案しました。
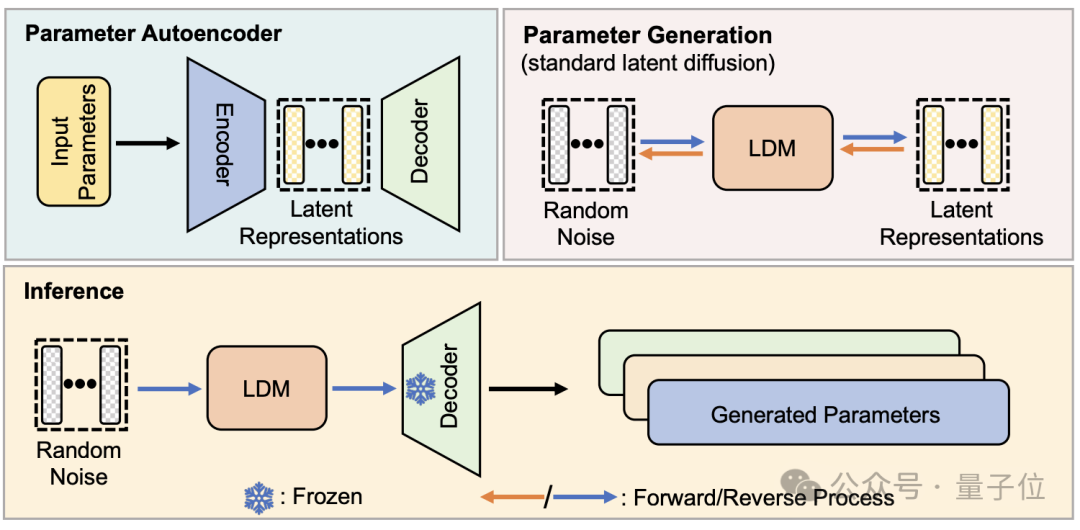
構造的な観点から見ると、p-diff は標準的な潜在拡散モデルに基づいて研究チームによって設計され、オートエンコーダーと組み合わせられています。
研究者はまず、トレーニングされ良好に実行されたネットワーク パラメーターの一部を選択し、それらを 1 次元ベクトル形式に展開します。
次に、オートエンコーダーを使用して、拡散モデルのトレーニング データとして 1 次元ベクトルから潜在表現を抽出します。これにより、元のパラメーターの主要な特徴を捉えることができます。
研究者らは、トレーニング プロセス中に、順方向および逆方向のプロセスを通じて p-diff にパラメータの分布を学習させ、完了後、拡散モデルは、視覚情報を生成するプロセスと同様に、ランダム ノイズからこれらの潜在的な表現を合成します。
最後に、新しく生成された潜在表現は、エンコーダーに対応するデコーダーによってネットワーク パラメーターに復元され、新しいモデルの構築に使用されます。
次の図は、p-diff を通じて 3 つのランダム シードを使用して最初からトレーニングされた ResNet-18 モデルのパラメーター分布であり、異なる層と同じ層間の違いを示しています。 . パラメータ間の分布パターン。

p-diff によって生成されたパラメータの品質を評価するために、研究者らは 8 つのデータセットに対してそれぞれ 2 サイズの 3 種類のニューラル ネットワークを使用してテストを行いました。
以下の表で、各グループの 3 つの数字は、元のモデル、統合モデル、および p-diff で生成されたモデルの評価結果を表します。
結果からわかるように、p-diff によって生成されたモデルのパフォーマンスは、基本的に手動でトレーニングされた元のモデルに近いか、それよりも優れています。
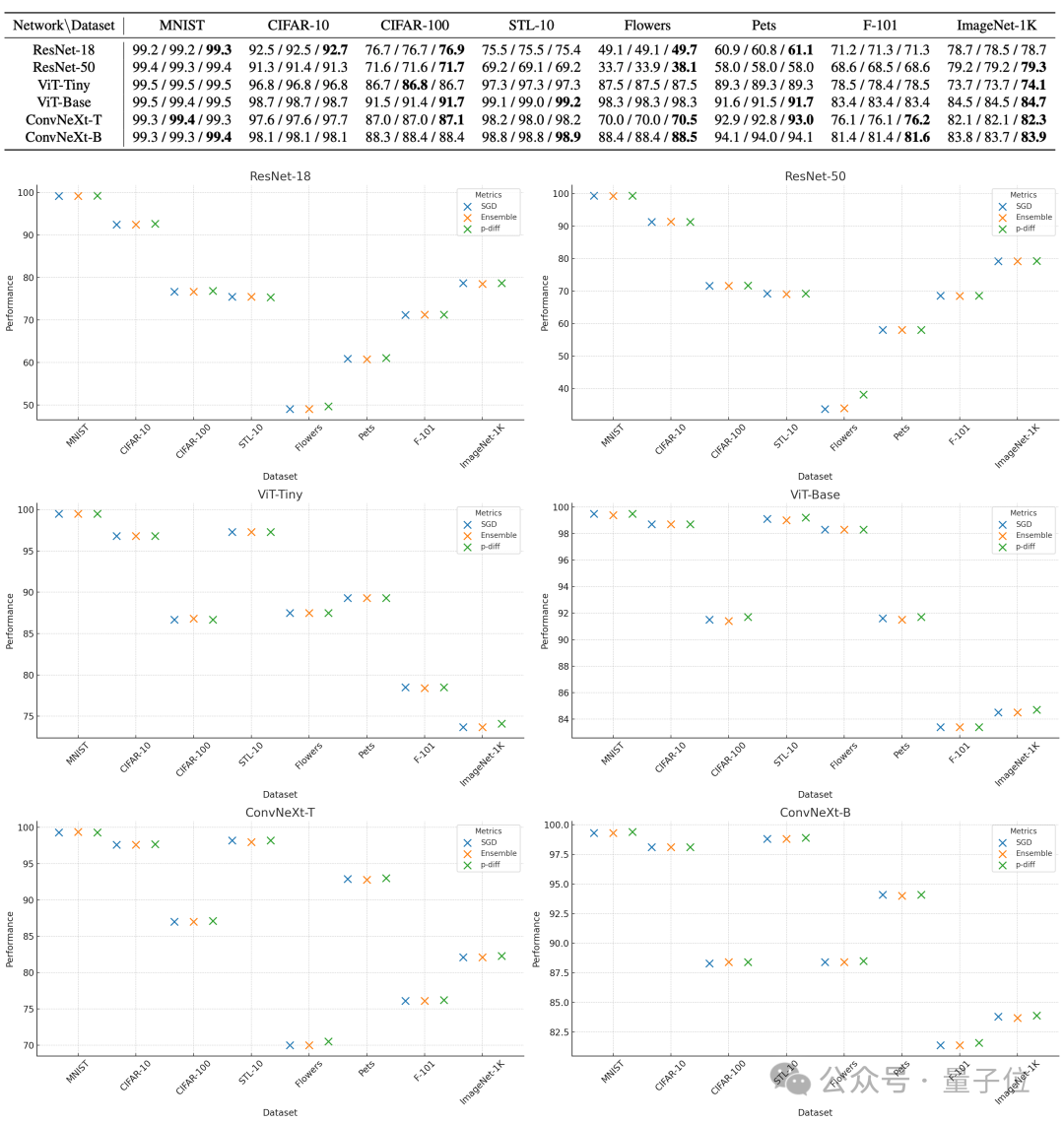
効率という点では、精度を損なうことなく、p-diff は従来のトレーニングよりも 15 倍速く ResNet-18 ネットワークを生成し、44 倍速く Vit-Base を生成します。
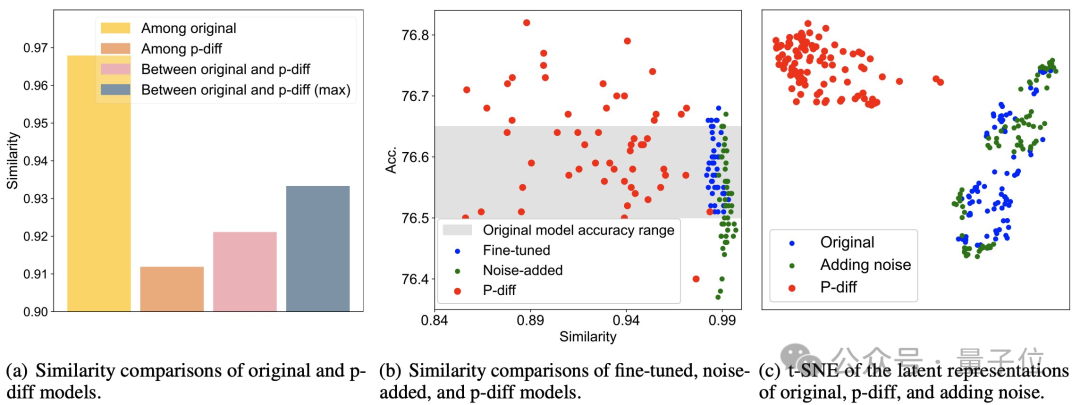
追加のテスト結果は、p-diff によって生成されたモデルがトレーニング データとは大きく異なることを示しています。
下図 (a) からわかるように、p-diff によって生成されたモデル間の類似度は、元のモデル間の類似度、および p-diff と元のモデル間の類似度よりも低くなります。モデル。
(b)と(c)から、微調整やノイズ付加手法と比較して、p-diffの類似性も低いことがわかります。
これらの結果は、p-diff がトレーニング サンプルを単に記憶するのではなく、実際に新しいモデルを生成することを示しており、優れた汎化能力を備えており、トレーニング データとは異なる新しいモデルを生成できることも示しています。
現在、p-diff のコードはオープンソース化されているので、興味のある方は GitHub で確認してみてください。
論文アドレス: https://arxiv.org/abs/2402.13144
GitHub: https ://github.com/NUS-HPC-AI-Lab/Neural-Network-Diffusion
以上がAIの最下層に侵入せよ! NUS Youyang のチームは拡散モデルを使用してニューラル ネットワーク パラメーターを構築しており、LeCun はそれを気に入っていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 MySQLインストール後に開始できないサービスのソリューション
Apr 08, 2025 am 11:18 AM
MySQLインストール後に開始できないサービスのソリューション
Apr 08, 2025 am 11:18 AM
MySQLは開始を拒否しましたか?パニックにならないでください、チェックしてみましょう!多くの友人は、MySQLのインストール後にサービスを開始できないことを発見し、彼らはとても不安でした!心配しないでください、この記事はあなたがそれを落ち着いて対処し、その背後にある首謀者を見つけるためにあなたを連れて行きます!それを読んだ後、あなたはこの問題を解決するだけでなく、MySQLサービスの理解と問題のトラブルシューティングのためのあなたのアイデアを改善し、より強力なデータベース管理者になることができます! MySQLサービスは開始に失敗し、単純な構成エラーから複雑なシステムの問題に至るまで、多くの理由があります。最も一般的な側面から始めましょう。基本知識:サービススタートアッププロセスMYSQLサービススタートアップの簡単な説明。簡単に言えば、オペレーティングシステムはMySQL関連のファイルをロードし、MySQLデーモンを起動します。これには構成が含まれます
