

AI テクノロジーをビジネスに最大限に活用する方法については、ガイドを参照してください。 RAG と CRAG の統合、ベクトル埋め込み、LLM、プロンプト エンジニアリングなどについて学び、責任を持って人工知能を適用しようとしている企業にとって有益です。
at生成AIの導入には、戦略的な管理が必要なビジネスリスクが数多くあります。これらのリスクは相互に関連していることが多く、コンプライアンス問題につながる潜在的な偏見からドメイン知識の欠如まで多岐にわたります。主な問題には、風評被害、法律および規制基準の遵守 (特に顧客とのやり取りに関連する)、知的財産権の侵害、倫理的問題、プライバシーの問題 (特に個人データまたは識別可能なデータを処理する場合) が含まれます。
#これらの課題に対処するために、検索拡張生成 (RAG) などのハイブリッド戦略が提案されています。 RAG テクノロジーは、人工知能によって生成されたコンテンツの品質を向上させ、企業の人工知能計画をより安全で信頼性の高いものにすることができます。この戦略は、知識不足や誤った情報などの問題に効果的に対処すると同時に、法的および倫理的なガイドラインの遵守を確保し、風評被害や法令違反を防止します。
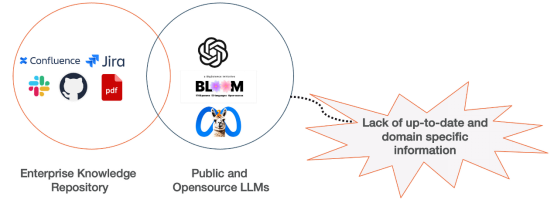
#シェフがさまざまな料理を作れるのと同じように、GPT や LLaMA-2 などの人工知能システムもさまざまなトピックに関するコンテンツを生成できます。しかし、詳細かつ正確な情報を提供する必要があるとき、特に斬新な料理を扱ったり、大量の企業データを閲覧したりするときは、情報の正確さと深さを確保するために特別なツールを利用します。
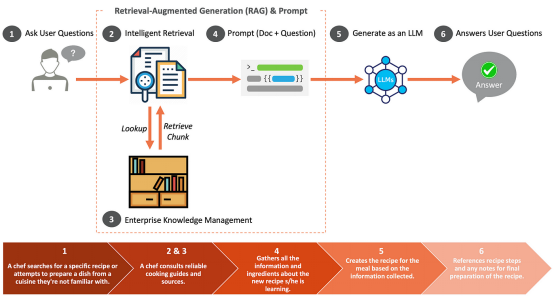 RAG の取得フェーズが不十分な場合はどうなりますか?
RAG の取得フェーズが不十分な場合はどうなりますか?
エンタープライズ レベルで人工知能ソリューションを構築するためのアーキテクチャの考慮事項
という 3 つの核となる柱を中心に構築されています。 ################################################データ# ##PhotographInput:
最初のステップは、会社文書の内容をクエリしやすい形式に変換することです。この変換は、次の一連の操作に従って、埋め込みモデルを使用して行われます。 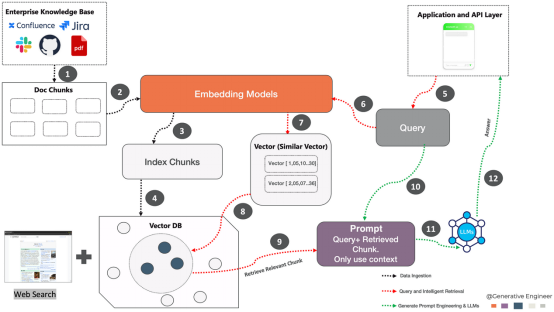
Confluence、Jira、PDF などのエンタープライズ ナレッジ ソースからのさまざまなドキュメントが 抽出され、システムに組み込まれます。このステップでは、ドキュメントを管理可能な部分 (多くの場合「チャンク」と呼ばれます) に分割します。 埋め込みモデル: これらのドキュメント チャンクは、埋め込みモデルに渡されます。埋め込みモデルは、テキストを、テキストのセマンティクスを表す数値形式 (ベクトル) に変換して、機械が理解できるようにするニューラル ネットワークです。
クエリとスマート検索: 推論サーバーはユーザーの質問を受信すると、埋め込みドキュメント内の同じモデルを使用する埋め込みプロセスを通じて、質問をベクトルに変換します。ナレッジベースで。次に、ベクトル データベースが検索されて、ユーザーの意図に密接に関連するベクトルが特定され、大規模言語モデル (LLM) に供給されてコンテキストが強化されます。
5.クエリ: アプリケーション層と API 層からのクエリ。クエリは、ユーザーまたは他のアプリケーションが情報を検索するときに入力するものです。
6.埋め込みクエリの取得: 生成された Vector.Embedding をVector データベース インデックスで検索を開始します。ベクトル データベースから取得するベクトルの数を選択します。この数は、問題を解決するためにコンパイルして使用する予定のコンテキストの数に比例します。
7.ベクトル (類似ベクトル): このプロセスでは、類似ベクトルを識別します。これらのベクトルは、クエリ コンテキストに関連するドキュメントのチャンク を表します。
8.関連ベクトルの取得:
ベクター データベースから関連するベクターを取得します。たとえば、シェフのコンテキストでは、レシピと準備ステップという 2 つの関連するベクトルに相当する可能性があります。対応するフラグメントが収集され、プロンプトとともに提供されます。
9.関連ブロックの取得: システムは、クエリ 関連するベクトルが文書部分と一致します。情報の関連性が評価されると、システムは次のステップを決定します。情報が完全に一致している場合は、重要度に応じてランク付けされます。情報が間違っている場合、システムはその情報を破棄し、オンラインでより適切な情報を探します。 ################################################生成する# ##ヒントエンジンと
LLMs : 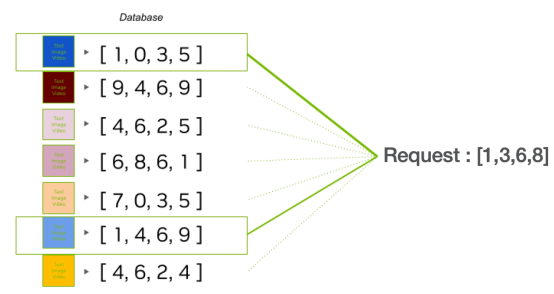
10. プロンプト エンジニアリング: 取得されたチャンクは、元のクエリで使用されてプロンプトが作成されます。このヒントは、クエリ コンテキストを言語モデルに効果的に伝えるように設計されています。 11. LLM (大規模言語モデル): エンジニアリングのヒントは大規模言語モデルによって処理されます。これらのモデルは、受け取った入力に基づいて人間のようなテキストを生成できます。
12. 回答: 最後に、言語モデルは、ヒントと取得したチャンクによって提供されるコンテキストを使用します。クエリに対する回答を生成します。その答えは、アプリケーション層と API 層を通じてユーザーに返されます。
#結論
このブログでは、人工物の使用について調査します。インテリジェンス ソフトウェア開発への統合の複雑なプロセスは、CRAG からインスピレーションを得たエンタープライズ生成 AI プラットフォーム構築の変革の可能性を浮き彫りにします。ジャストインタイム エンジニアリング、データ管理、革新的な検索拡張生成 (RAG) アプローチの複雑さに対処することで、AI テクノロジーをビジネス運営の中核に組み込む方法の概要を示します。今後の議論では、インテリジェント開発のための生成 AI フレームワーク をさらに掘り下げ、AI を最大限に活用してよりスマートな開発を実現するための具体的なツール、技術、戦略を検討します。 、より効率的な開発環境。
出典| https://www.php.cn/link/1f3e9145ab192941f32098750221c602
著者|ヴェンカット・ランガサミー
以上がビジネス AI をマスターする: RAG と CRAG を使用してエンタープライズ グレードの AI プラットフォームを構築するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



