

YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~

今日の深層学習手法は、モデルの予測結果が実際の状況に最も近くなるように、最適な目的関数を設計することに重点を置いています。同時に、予測に十分な情報を取得するには、適切なアーキテクチャを設計する必要があります。既存の方法は、入力データがレイヤーごとの特徴抽出と空間変換を受けると、大量の情報が失われるという事実を無視しています。この記事では、ディープネットワークを介してデータを送信する際の重要な問題、つまり情報のボトルネックと可逆機能について詳しく説明します。これに基づいて、深層ネットワークが複数の目的を達成するために必要なさまざまな変化に対処するために、プログラマブル勾配情報 (PGI) の概念が提案されています。 PGI は、目的関数を計算するためのターゲット タスクに完全な入力情報を提供することで、ネットワークの重みを更新するための信頼できる勾配情報を取得できます。さらに、新しい軽量ネットワーク アーキテクチャである勾配パス プランニングに基づく一般化効率層集約ネットワーク (GELAN) が設計されています。
検証結果は、GELAN アーキテクチャが軽量モデル上の PGI を通じて大きな利点を得たことを示しています。 MS COCO データセットの実験では、GELAN と PGI を組み合わせた方が、従来の畳み込み演算子のみを使用したディープ畳み込みに基づく最先端の方法よりも優れたパラメーター利用率を達成できることが示されています。 PGIの汎用性により、軽量モデルから大型モデルまで幅広く対応します。 PGI では、モデルに十分な情報が与えられるため、大規模なデータセットで事前トレーニングされた最先端のモデルよりも、最初からトレーニングされたモデルを使用した方が、より良い結果を達成することができます。
記事のアドレス: https://arxiv.org/pdf/2402.13616
コードリンク: https://github.com/WongKinYiu/yolov9
素晴らしいパフォーマンス
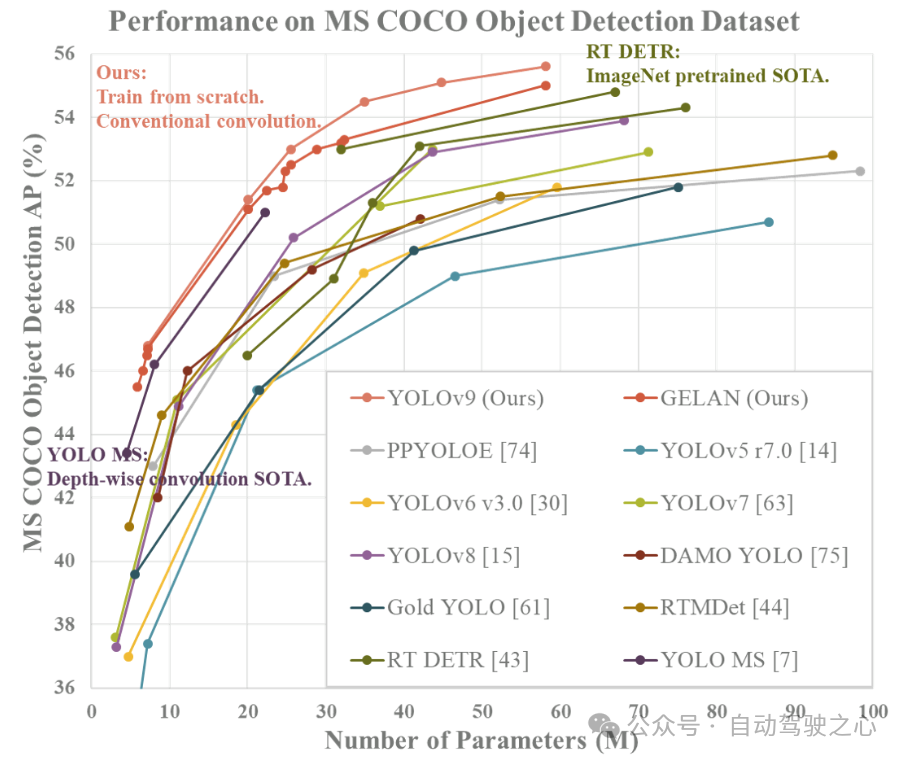
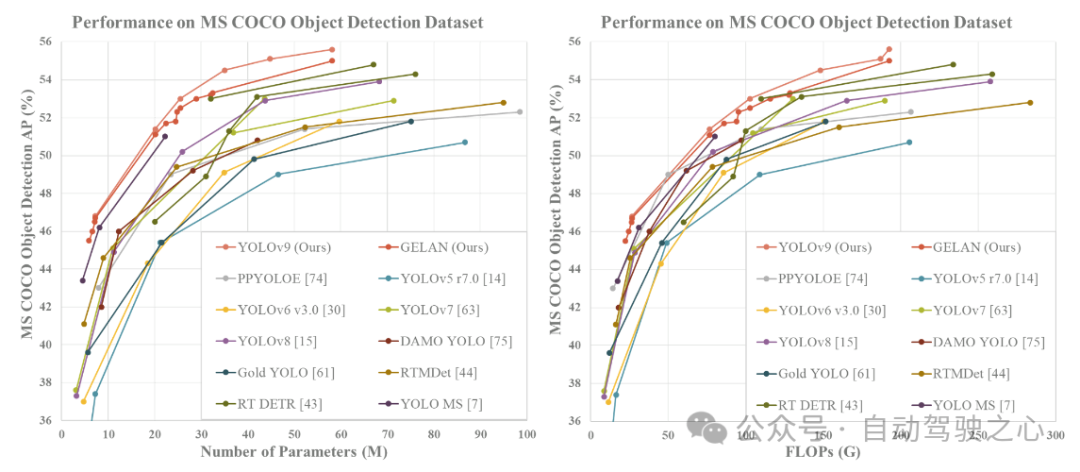
MS COCO データセットでのリアルタイムのターゲット検出器の比較結果によると、GELAN および PGI に基づくターゲット検出方法は、ターゲット検出の点で、最初からトレーニングされた以前の方法よりも大幅に優れています。パフォーマンス。新しい手法は、精度の点で大規模なデータセットの事前トレーニングに依存する RT DETR を上回り、パラメーターの利用の点でもディープ コンボリューション設計に基づく YOLO MS を上回ります。これらの結果は、GELAN および PGI 手法がターゲット検出の分野で潜在的な利点を持っており、将来の研究や応用において重要な技術の選択肢となる可能性があることを示しています。
#この記事の寄稿
- 既存のディープ ニューラル ネットワーク アーキテクチャを可逆関数の観点から理論的に分析します。このプロセスにより、これまで説明が困難であった多くの現象を説明することに成功しました。 PGI および補助可逆分岐もこの分析に基づいて設計され、優れた結果を達成しました。
- によって設計された PGI は、深い監視が非常に深いニューラル ネットワーク アーキテクチャにのみ使用できるという問題を解決し、新しい軽量アーキテクチャを日常業務に真に適用できるようにします。
- 設計された GELAN は、従来の畳み込みのみを使用して、最先端のテクノロジーに基づく深い畳み込み設計よりも高いパラメーターの使用量を実現しながら、軽量、高速、正確であるという大きな利点を示します。
- 提案された PGI と GELAN を組み合わせると、MS COCO データセット上の YOLOv9 の物体検出パフォーマンスは、あらゆる面で既存のリアルタイム物体検出器を大幅に上回ります。
方法
PGI および関連するネットワーク アーキテクチャと方法
下の図に示すように、(a ) パス集約ネットワーク (PAN)、(b) 可逆カラム (RevCol)、(c) 従来の深い監視、および (d) YOLOv9 によって提案されたプログラム可能な勾配情報 (PGI)。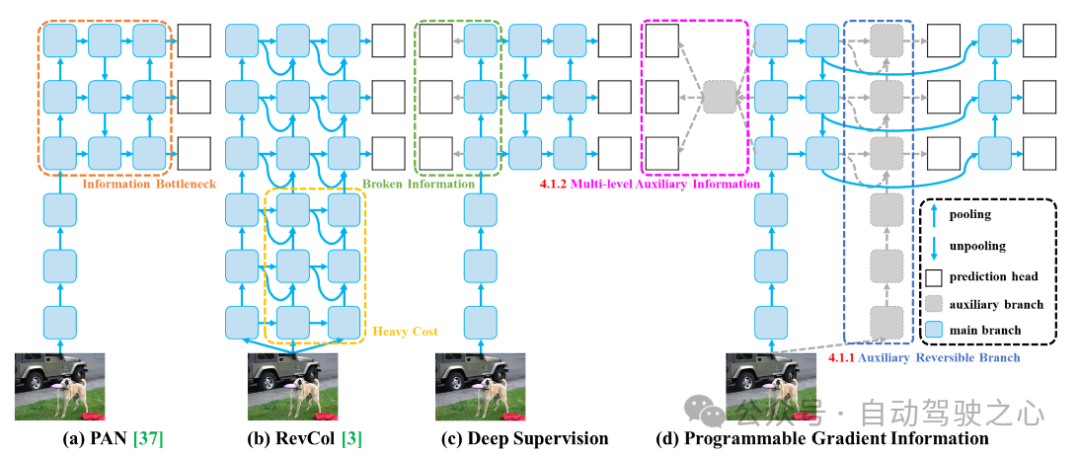
- メイン ブランチ: 推論に使用されるアーキテクチャ;
- 補助可逆ブランチ: メイン ブランチが逆方向に送信するための信頼できる勾配を生成します。
- マルチレベルの補助情報: 計画可能なマルチレベルのセマンティック情報を学習するためにメイン ブランチを制御します。
GELAN のアーキテクチャ
下図に示すように、YOLOv9 が提案する (a) CSPNet、(b) ELAN、(c) GELAN です。 。 CSPNet を模倣し、ELAN を GELAN に拡張し、あらゆるコンピューティング ブロックをサポートできます。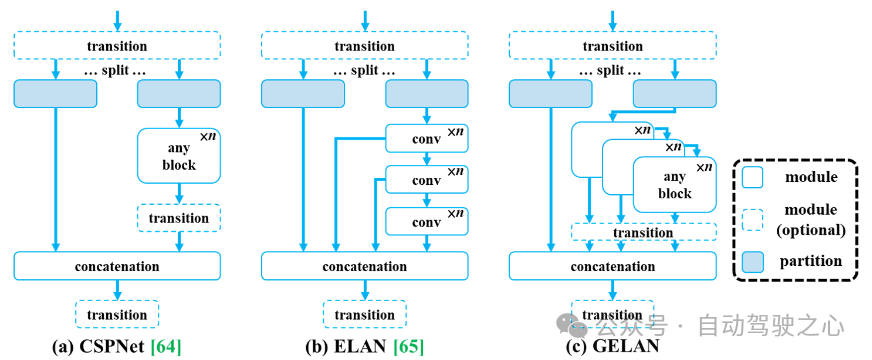
結果の比較
既存技術との比較
次の表に示します。 YOLOv9 と、最初からトレーニングされた他のリアルタイム物体検出器との比較が示されています。全体として、既存の手法の中で最もパフォーマンスが高い手法は、軽量モデルの場合は YOLO MS-S、中型モデルの場合は YOLO MS、一般モデルの場合は YOLOv7 AF、大規模モデルの場合は YOLOv8-X です。 YOLOv9 は軽量モデルや中型モデルの YOLO MS と比較してパラメータが約 10%、計算量が 5 ~ 15% 減少していますが、AP は 0.4 ~ 0.6% 向上しています。 YOLOv7 AF と比較して、YOLOv9-C ではパラメータが 42% 少なく、計算が 21% 少ないにもかかわらず、同じ AP (53%) を達成します。 YOLOv8-X と比較して、YOLOv9-X ではパラメーターが 15% 減少し、計算が 25% 減少し、AP が 1.7% 増加して大幅に改善されました。上記の比較結果は、YOLOv9 があらゆる面で既存の方法に比べて大幅に改善されていることを示しています。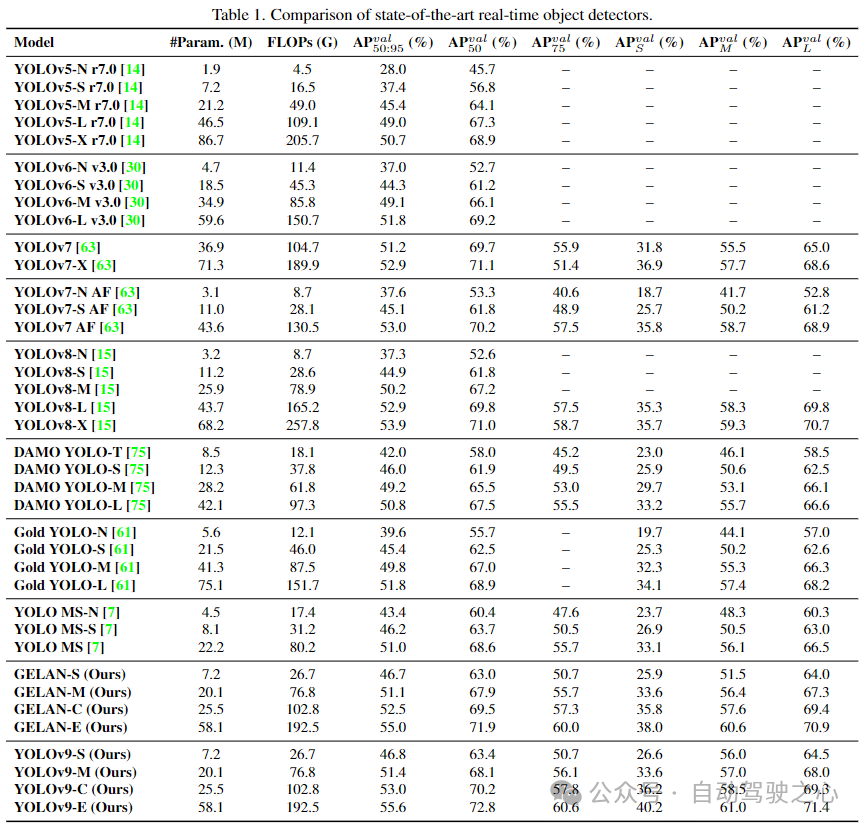
最先端のリアルタイム物体検出器との比較
比較に参加するメソッドはすべて、RT DETR、RTMDet、PP-YOLOE などの ImageNet を事前トレーニングの重みとして使用します。等スクラッチ トレーニング手法を使用した YOLOv9 は、他の手法のパフォーマンスを明らかに上回っています。
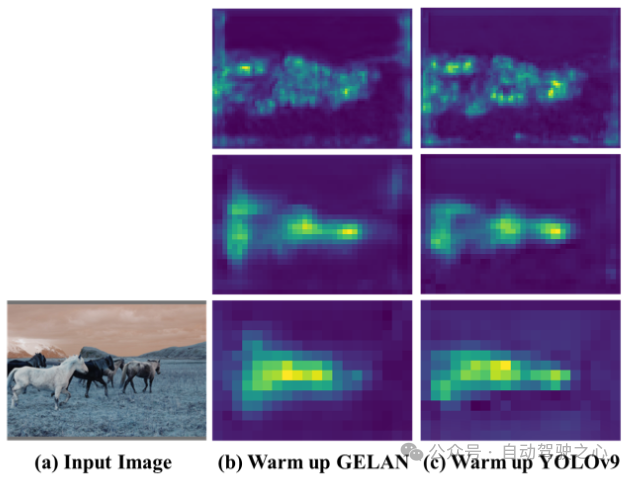
結果の視覚化
機能マップ (結果の視覚化): PlainNet 作成、異なる深さでの ResNet、CSPNet、GELAN のランダムな初期重み出力。 100 層を超えると、ResNet はターゲット情報を混乱させるのに十分なフィードフォワード出力を生成し始めます。ここで提案するGELANは、150層目でもかなり完全な情報を保持でき、200層目でも十分な識別能力を持っている。

GELAN および YOLOv9 (GELAN PGI) の PAN 機能マップ (視覚化結果): バイアス ウォームアップのラウンド後。 GELAN には初期の分岐がいくつかありましたが、PGI の可逆分岐を追加した後は、ターゲット オブジェクトに焦点を当てることができるようになりました。
さまざまなネットワーク アーキテクチャのランダムな初期重み出力特徴マップの視覚化された結果: (a) 入力画像、(b) PlainNet、(c) ResNet、(d) CSPNet、および (e) 提案された GELAN。図からわかるように、アーキテクチャが異なると、目的関数の損失を計算するために提供される情報の程度が異なりますが、私たちのアーキテクチャは、最も完全な情報を保持し、目的関数を計算するための最も信頼できる勾配情報を提供できます。

結論
この論文では、PGI を使用して、情報のボトルネックと、適切ではない深い監視メカニズムの問題を解決することを提案します。軽量ニューラル ネットワークの質問です。効率的で軽量なニューラル ネットワークである GELAN を設計しました。ターゲット検出に関しては、GELAN はさまざまなコンピューティング モジュールと深度設定の下で強力で安定したパフォーマンスを示します。実際、さまざまな推論デバイスに適したモデルに幅広く拡張可能です。上記 2 つの問題に対して、PGI の導入により、軽量モデルと深層モデルの両方で大幅な精度の向上が可能になります。 YOLOv9 は PGI と GELAN を組み合わせて設計されており、強力な競争力を示します。その優れた設計により、ディープ モデルは YOLOv8 と比較してパラメータ数を 49%、計算量を 43% 削減しながらも、MS COCO データ セットで 0.6% の AP 改善を達成しています。
元のリンク: https://mp.weixin.qq.com/s/nP4JzVwn1S-MeKAzbf97uw
以上がYOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7451
7451
 15
1374
52
77
11
14
9
15
1374
52
77
11
14
9

 YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~
Feb 26, 2024 am 11:31 AM
YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~
Feb 26, 2024 am 11:31 AM
現在の深層学習手法は、モデルの予測結果が実際の状況に最も近くなるように、最適な目的関数を設計することに重点を置いています。同時に、予測に十分な情報を取得するには、適切なアーキテクチャを設計する必要があります。既存の方法は、入力データがレイヤーごとの特徴抽出と空間変換を受けると、大量の情報が失われるという事実を無視しています。この記事では、ディープネットワークを介してデータを送信する際の重要な問題、つまり情報のボトルネックと可逆機能について詳しく説明します。これに基づいて、深層ネットワークが複数の目的を達成するために必要なさまざまな変化に対処するために、プログラマブル勾配情報 (PGI) の概念が提案されています。 PGI は、目的関数を計算するためのターゲット タスクに完全な入力情報を提供することで、ネットワークの重みを更新するための信頼できる勾配情報を取得できます。さらに、新しい軽量ネットワーク フレームワークが設計されています。
 GNN の基礎、フロンティア、および応用
Apr 11, 2023 pm 11:40 PM
GNN の基礎、フロンティア、および応用
Apr 11, 2023 pm 11:40 PM
グラフ ニューラル ネットワーク (GNN) は、近年急速かつ驚くべき進歩を遂げています。グラフ ニューラル ネットワークは、グラフ ディープ ラーニング、グラフ表現学習 (グラフ表現学習)、または幾何学的ディープ ラーニングとも呼ばれ、機械学習、特にディープ ラーニングの分野で最も急速に成長している研究トピックです。この共有のタイトルは「GNN の基礎、フロンティア、および応用」です。主に、学者の Wu Lingfei、Cui Peng、Pei Jian、Zhao によって編纂された包括的な書籍「グラフ ニューラル ネットワークの基礎、フロンティア、およびアプリケーション」の一般的な内容を紹介します。梁さん。 1. グラフ ニューラル ネットワークの概要 1. なぜグラフを学ぶのですか?グラフは、複雑なシステムを記述およびモデル化するための汎用言語です。グラフ自体は複雑ではなく、主にエッジとノードで構成されています。ノードを使用してモデル化したい任意のオブジェクトを表現し、エッジを使用して 2 つのオブジェクトを表現できます。
 自動運転用の 3 つの主流チップ アーキテクチャの概要を 1 つの記事でまとめたもの
Apr 12, 2023 pm 12:07 PM
自動運転用の 3 つの主流チップ アーキテクチャの概要を 1 つの記事でまとめたもの
Apr 12, 2023 pm 12:07 PM
現在主流の AI チップは主に GPU、FPGA、ASIC の 3 つのカテゴリに分類されます。 GPU と FPGA はどちらも比較的成熟した初期段階のチップ アーキテクチャであり、汎用チップです。 ASIC は、特定の AI シナリオ向けにカスタマイズされたチップです。業界は、CPU が AI コンピューティングには適していないことを確認していますが、CPU は AI アプリケーションにも不可欠です。 GPU ソリューション アーキテクチャ GPU と CPU の比較 CPU はフォン ノイマン アーキテクチャに従っており、そのコアはプログラム/データのストレージとシリアル シーケンシャル実行です。したがって、CPU アーキテクチャは、記憶装置 (Cache) と制御装置 (Control) を配置するために大きなスペースを必要としますが、演算装置 (ALU) が占める割合は小さいため、CPU は大規模な処理を実行します。並列コンピューティング。
 「Bilibili UP のオーナーは世界初のレッドストーン ベースのニューラル ネットワークの作成に成功しました。これはソーシャル メディアでセンセーションを巻き起こし、Yann LeCun によって賞賛されました。」
May 07, 2023 pm 10:58 PM
「Bilibili UP のオーナーは世界初のレッドストーン ベースのニューラル ネットワークの作成に成功しました。これはソーシャル メディアでセンセーションを巻き起こし、Yann LeCun によって賞賛されました。」
May 07, 2023 pm 10:58 PM
マインクラフトにおいて、レッドストーンは非常に重要なアイテムです。これはゲーム内でユニークなマテリアルであり、スイッチ、レッドストーン トーチ、レッドストーン ブロックは、ワイヤーやオブジェクトに電気のようなエネルギーを供給できます。レッドストーン回路は、他の機械を制御または起動するための構造を構築するために使用できます。回路自体は、プレイヤーによる手動の起動に応答するように設計することも、信号を繰り返し出力したり、クリーチャーの動きなどの非プレイヤーによって引き起こされる変化に応答したりすることもできます落下、植物の成長、昼と夜など。したがって、私の世界では、レッドストーンは、自動ドア、照明スイッチ、ストロボ電源などの単純な機械から、巨大なエレベーター、自動農場、小型ゲームプラットフォーム、さらにはゲーム内マシンに至るまで、非常に多くの種類の機械を制御できます。 。最近はB局UPメイン@
 強風にも耐えられるドローン?カリフォルニア工科大学は 12 分間の飛行データを使用して、ドローンに風に乗って飛行するよう教えています
Apr 09, 2023 pm 11:51 PM
強風にも耐えられるドローン?カリフォルニア工科大学は 12 分間の飛行データを使用して、ドローンに風に乗って飛行するよう教えています
Apr 09, 2023 pm 11:51 PM
傘が飛ばされるほど風が強いとき、ドローンは次のように安定しています: 風に乗って飛行することは、空中で飛行することの一部です。大きなレベルから見ると、パイロットが航空機を着陸させるとき、風速は小規模なレベルでは、強風もドローンの飛行に影響を与える可能性があります。現在、ドローンは無風の制御された条件下で飛行するか、人間がリモコンを使用して操作します。ドローンは研究者によって制御され、大空で編隊を組んで飛行しますが、これらの飛行は通常、理想的な条件と環境の下で行われます。ただし、ドローンが荷物の配達など、必要ではあるが日常的なタスクを自律的に実行するには、風の状況にリアルタイムで適応できなければなりません。風を受けて飛行する際のドローンの操作性を高めるために、カリフォルニア工科大学のエンジニアのチームが
 マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース
May 28, 2023 pm 02:12 PM
マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース
May 28, 2023 pm 02:12 PM
視覚タスク (画像分類など) の深層学習モデルは、通常、単一の視覚領域 (自然画像やコンピューター生成画像など) からのデータを使用してエンドツーエンドでトレーニングされます。一般に、複数のドメインのビジョン タスクを完了するアプリケーションは、個別のドメインごとに複数のモデルを構築し、それらを個別にトレーニングする必要があります。データは異なるドメイン間で共有されません。推論中、各モデルは特定のドメインの入力データを処理します。たとえそれらが異なる分野を指向しているとしても、これらのモデル間の初期層のいくつかの機能は類似しているため、これらのモデルの共同トレーニングはより効率的です。これにより、遅延と消費電力が削減され、各モデル パラメーターを保存するためのメモリ コストが削減されます。このアプローチはマルチドメイン学習 (MDL) と呼ばれます。さらに、MDL モデルは単一モデルよりも優れたパフォーマンスを発揮します。
 AI はあなたをはっきりと認識しました、YOLO+ByteTrack+マルチラベル分類ネットワーク
Apr 14, 2023 pm 06:25 PM
AI はあなたをはっきりと認識しました、YOLO+ByteTrack+マルチラベル分類ネットワーク
Apr 14, 2023 pm 06:25 PM
今日は歩行者属性分析システムについて紹介したいと思います。歩行者はビデオまたはカメラのビデオ ストリームから識別でき、各人の属性をマークできます。特定された属性には次の 10 のカテゴリが含まれます。一部のカテゴリには複数の属性があります。体の向きが前、横、後ろの場合、最終的なトレーニングには 26 の属性が含まれます。このようなシステムを実装するには、次の 3 つの手順が必要です。 YOLOv5 を使用して歩行者を識別する ByteTrack を使用して、同じ人物を追跡およびマークする マルチラベル画像分類ネットワークをトレーニングして、歩行者の 26 の属性を識別する 1. 歩行者の認識と追跡 歩行者の認識は、YOLOv5 ターゲット検出モデルを使用しますモデルを自分でトレーニングすることも、YOLOv5 の事前トレーニング済みモデルを直接使用することもできます。歩行者追跡は、マルチオブジェクト追跡技術(MOT)を使用しています。
 1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
論文のアドレス: https://arxiv.org/abs/2307.09283 コードのアドレス: https://github.com/THU-MIG/RepViTRepViT は、モバイル ViT アーキテクチャで優れたパフォーマンスを発揮し、大きな利点を示します。次に、この研究の貢献を検討します。記事では、主にモデルがグローバル表現を学習できるようにするマルチヘッド セルフ アテンション モジュール (MSHA) のおかげで、軽量 ViT は一般的に視覚タスクにおいて軽量 CNN よりも優れたパフォーマンスを発揮すると述べられています。ただし、軽量 ViT と軽量 CNN のアーキテクチャの違いは十分に研究されていません。この研究では、著者らは軽量の ViT を効果的なシステムに統合しました。
