

ソラのようなモデルをトレーニングしたいですか? You Yang のチーム OpenDiT が 80% の高速化を達成

2024 年初頭のソラの驚異的なパフォーマンスは新たなベンチマークとなり、文生動画を研究しているすべての人々に追いつくために急ぐよう促しています。研究者は皆、ソラの結果を再現することに熱心で、時間との闘いに取り組んでいます。
OpenAI が公開した技術レポートによると、Sora の重要な革新ポイントは、ビジュアル データをパッチの統一表現に変換し、それを Transformer と拡散モデルと組み合わせて実証することです。優れたパフォーマンス、拡張性。このレポートの発表に伴い、Sora の中心開発者である William Peebles とニューヨーク大学コンピューター サイエンス助教授 Xie Saining が共著した論文「Scalable Diffusion Models with Transformers」は研究者から大きな注目を集めています。研究コミュニティは、論文で提案されている DiT アーキテクチャを通じてソラを再現する実現可能な方法を探ることを望んでいます。
最近、シンガポール国立大学の You Yang チームがオープンソース化した OpenDiT と呼ばれるプロジェクトにより、DiT モデルのトレーニングとデプロイのための新しいアイデアが開かれました。
OpenDiT は、DiT アプリケーションのトレーニングと推論の効率を向上させるために設計されたシステムで、操作が簡単なだけでなく、高速でメモリ効率も優れています。このシステムは、テキストからビデオへの生成やテキストから画像への生成などの機能をカバーしており、ユーザーに効率的で便利なエクスペリエンスを提供することを目指しています。
プロジェクトアドレス: https://github.com/NUS-HPC-AI-Lab/OpenDiT
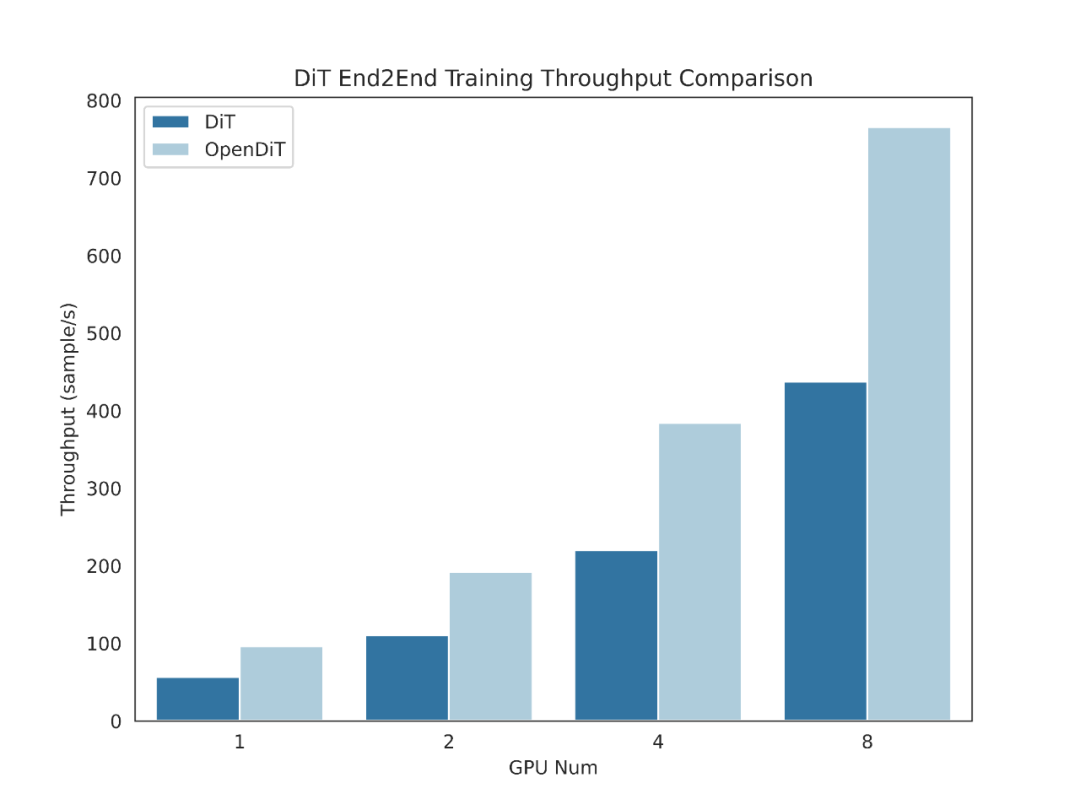
OpenDiT メソッドの紹介
OpenDiT は、Colossal-AI を活用した拡散トランス (DiT) の高性能実装を提供します。トレーニング中に、ビデオと状態の情報が、DiT モデルへの入力としてそれぞれ対応するエンコーダーに入力されます。その後、拡散法によってトレーニングとパラメータの更新が実行され、最後に更新されたパラメータが EMA (指数移動平均) モデルに同期されます。推論段階では、EMA モデルが直接使用され、条件情報を入力として受け取り、対応する結果を生成します。
画像出典: https://www.zhihu.com/people/berkeley-you-yang
OpenDiT は、ZeRO 並列戦略を使用して DiT モデル パラメーターを複数のマシンに分散し、最初にメモリ負荷を軽減します。パフォーマンスと精度のより良いバランスを達成するために、OpenDiT は混合精度トレーニング戦略も採用しています。具体的には、正確な更新を保証するために、モデル パラメーターとオプティマイザーは float32 を使用して保存されます。モデルの計算プロセス中に、研究チームは、モデルの精度を維持しながら計算プロセスを高速化するために、DiT モデル用に float16 と float32 の混合精度手法を設計しました。
DiT モデルで使用される EMA メソッドは、モデル パラメーターの更新をスムーズにするための戦略であり、モデルの安定性と汎化能力を効果的に向上させることができます。ただし、パラメータの追加コピーが生成されるため、ビデオ メモリへの負担が増加します。ビデオ メモリのこの部分をさらに削減するために、研究チームは EMA モデルを断片化し、異なる GPU に保存しました。トレーニング プロセス中、各 GPU は EMA モデル パラメーターの独自の部分を計算して保存し、同期更新の各ステップの後に ZeRO が更新を完了するのを待つだけで済みます。
FastSeq
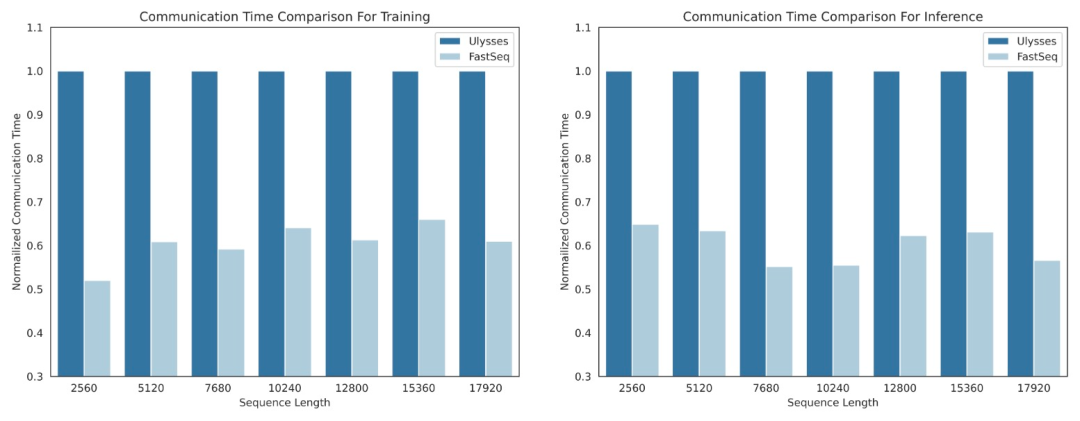
DiT などの視覚生成モデルの分野では、効率的な長いシーケンスを実現するためにシーケンスの並列性が重要です。訓練と遅延の少ない推論が不可欠です。
しかし、DeepSpeed-Ulysses、Megatron-LM シーケンス並列処理などの既存の手法は、そのようなタスクに適用すると制限に直面します。つまり、大量のシーケンス通信が導入されたり、小規模な処理を扱う際に効率が欠如したりすることになります。 -スケール順次並列処理。
この目的を達成するために、研究チームは、大規模なシーケンスと小規模な並列処理に適した新しいシーケンス並列処理である FastSeq を提案しました。 FastSeq は、トランス層あたり 2 つの通信オペレーターのみを使用することでシーケンス通信を最小限に抑え、AllGather を活用して通信効率を向上させ、非同期リングを戦略的に採用して AllGather 通信を qkv 計算とオーバーラップさせてパフォーマンスをさらに最適化します。
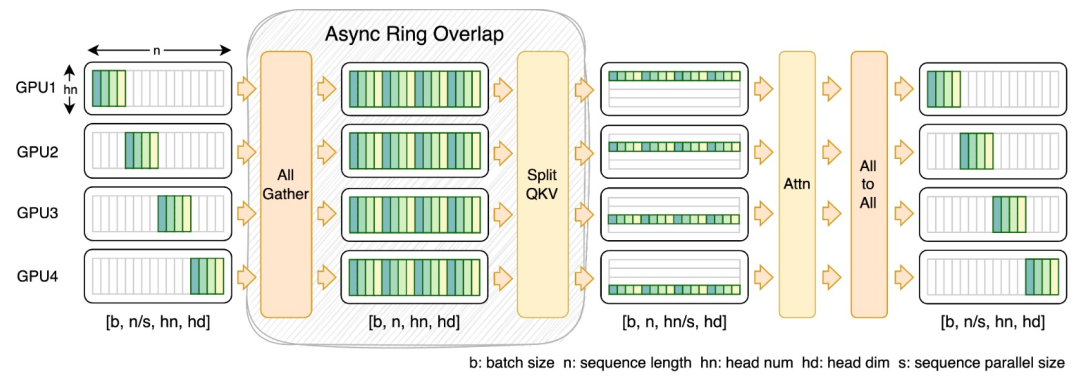
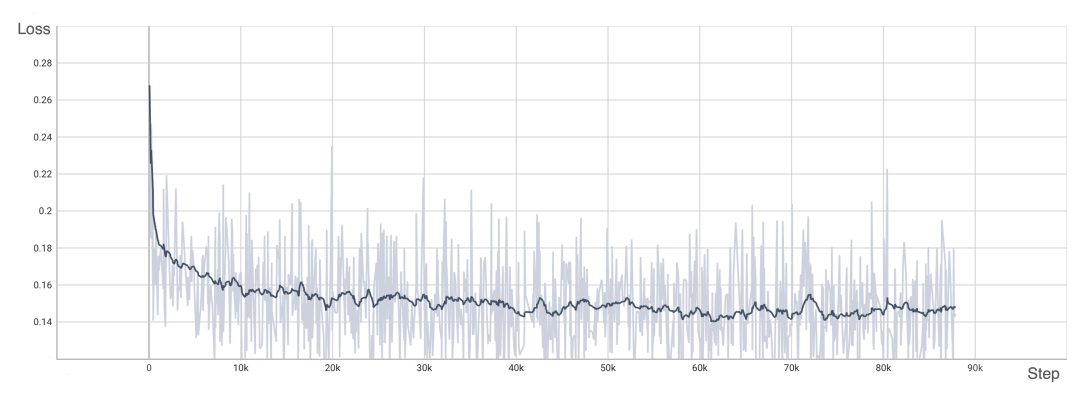
オペレータの最適化# ############################## adaLN モジュールは、条件付き情報をビジュアル コンテンツに統合するために DiT モデルに導入されています。この操作はモデルのパフォーマンスを向上させるために重要ですが、多数の要素ごとの操作も必要になります。モデル内で頻繁に使用される呼び出しにより、全体的なコンピューティング効率が低下します。この問題を解決するために、研究チームは、複数の演算を 1 つに結合する効率的な Fused adaLN カーネルを提案しました。これにより、計算効率が向上し、視覚情報の I/O 消費が削減されます。 画像出典: https://www.zhihu.com/people/berkeley-you-yang 簡単に言うと、OpenDiT には次のようなパフォーマンス上の利点があります: #1. GPU で最大 80% の高速化、50% のメモリ節約 #2. FastSeq: 新しいシーケンス並列メソッド 3. 使いやすい 4. テキストから画像への生成とテキストからビデオへの生成パイプラインの完成 OpenDiT を使用するには、まず前提条件をインストールする必要があります: サンプルを実行するには、Anaconda (Python >= 3.10) を使用して新しい環境を作成することをお勧めします: ColossalAI のインストール: OpenDiT のインストール: (オプションですが推奨) トレーニングと推論を高速化するためにライブラリをインストールします: 画像生成 #次のコマンドを実行して、DiT モデルをトレーニングできます。 #すべてのアクセラレーション メソッドはデフォルトで無効になっています。トレーニング プロセスのいくつかの重要な要素の詳細は次のとおりです。 DiT モデルを推論に使用したい場合は、次のコードを実行できます。チェックポイント パスを独自のトレーニング済みモデルに置き換える必要があります。 视频生成 你可以通过执行以下命令来训练视频 DiT 模型: 使用 DiT 模型执行视频推理的代码如下所示: 为了验证 OpenDiT 的准确性,研究团队使用 OpenDiT 的 origin 方法对 DiT 进行了训练,在 ImageNet 上从头开始训练模型,在 8xA100 上执行 80k step。以下是经过训练的 DiT 生成的一些结果: 损失也与 DiT 论文中列出的结果一致: 要复现上述结果,需要更改 train_img.py 中的数据集并执行以下命令: 感兴趣的读者可以查看项目主页,了解更多研究内容。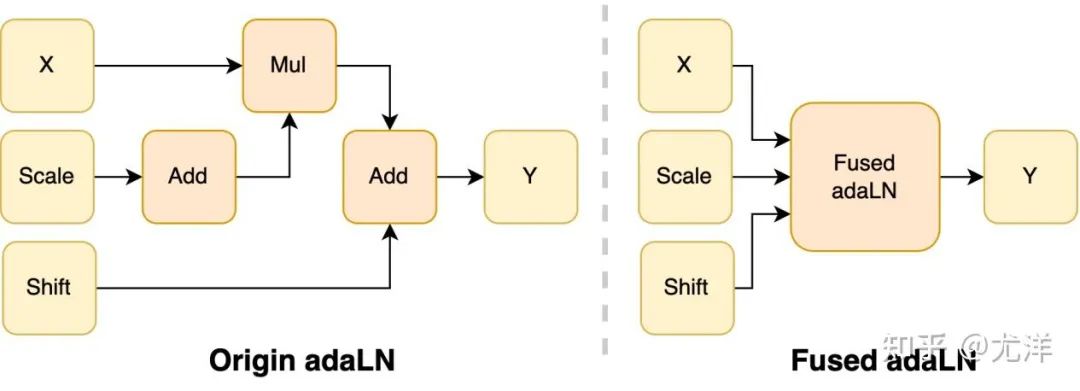
インストールと使用
conda create -n opendit pythnotallow=3.10 -yconda activate opendit
git clone https://github.com/hpcaitech/ColossalAI.gitcd ColossalAIgit checkout adae123df3badfb15d044bd416f0cf29f250bc86pip install -e .
git clone https://github.com/oahzxl/OpenDiTcd OpenDiTpip install -e .
# Install Triton for fused adaln kernelpip install triton# Install FlashAttentionpip install flash-attn# Install apex for fused layernorm kernelgit clone https://github.com/NVIDIA/apex.gitcd apexgit checkout 741bdf50825a97664db08574981962d66436d16apip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-optinotallow=--cpp_ext" --config-settings "--build-optinotallow=--cuda_ext" ./--global-optinotallow="--cuda_ext" --global-optinotallow="--cpp_ext"
# Use scriptbash train_img.sh# Use command linetorchrun --standalone --nproc_per_node=2 train.py \--model DiT-XL/2 \--batch_size 2
# train with sciptbash train_video.sh# train with command linetorchrun --standalone --nproc_per_node=2 train.py \--model vDiT-XL/222 \--use_video \--data_path ./videos/demo.csv \--batch_size 1 \--num_frames 16 \--image_size 256 \--frame_interval 3# preprocess# our code read video from csv as the demo shows# we provide a code to transfer ucf101 to csv formatpython preprocess.py
# Use scriptbash sample_video.sh# Use command linepython sample.py \--model vDiT-XL/222 \--use_video \--ckpt ckpt_path \--num_frames 16 \--image_size 256 \--frame_interval 3
DiT 复现结果

torchrun --standalone --nproc_per_node=8 train.py \--model DiT-XL/2 \--batch_size 180 \--enable_layernorm_kernel \--enable_flashattn \--mixed_precision fp16
以上がソラのようなモデルをトレーニングしたいですか? You Yang のチーム OpenDiT が 80% の高速化を達成の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7477
7477
 15
1377
52
77
11
19
32
15
1377
52
77
11
19
32

 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
 Prometheus MySQL ExporterでMySQLおよびMariadb液滴を監視します
Apr 08, 2025 pm 02:42 PM
Prometheus MySQL ExporterでMySQLおよびMariadb液滴を監視します
Apr 08, 2025 pm 02:42 PM
MySQLおよびMariaDBデータベースの効果的な監視は、最適なパフォーマンスを維持し、潜在的なボトルネックを特定し、システム全体の信頼性を確保するために重要です。 Prometheus MySQL Exporterは、プロアクティブな管理とトラブルシューティングに重要なデータベースメトリックに関する詳細な洞察を提供する強力なツールです。
