

Microsoft の 6 ページの論文は爆発的です: 三元 LLM、とてもおいしいです!

これは、Microsoft と中国科学院大学が最新の研究で提示した結論です。
すべての LLM は 1.58 ビットになります。

具体的には、この研究で提案された手法は BitNet b1.58 と呼ばれるもので、これは、大規模な言語モデル。「パラメーターをオンにして始めます。
16 ビット浮動小数点数 (FP16 や BF16 など) 形式の従来のストレージは、三進数 、つまり に変更されました。 {- 1, 0, 1}。
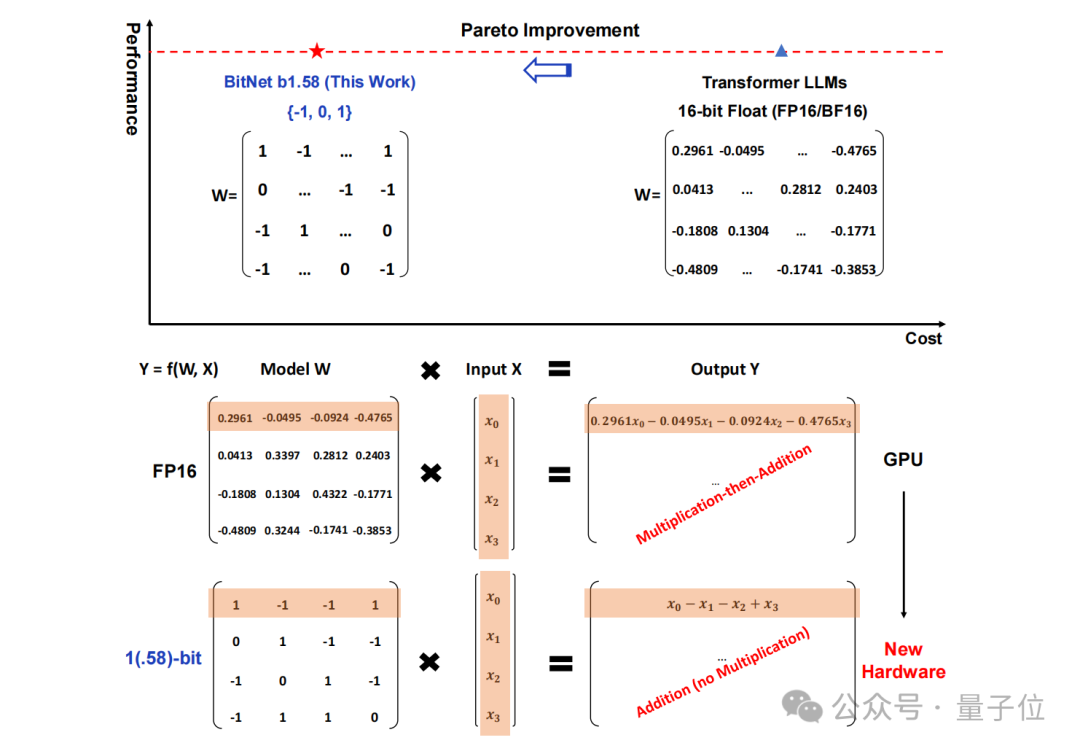
「1.58 ビット」とは、各パラメータが 1.58 バイトの記憶領域を占有することを意味するのではなく、各パラメータが 1.58 ビットの情報を使用できることを意味することに注意してください。
このような変換後、行列の計算には 整数の加算のみが含まれるため、大規模なモデルでは、一定の精度を維持しながら、必要なストレージ スペースとコンピューティング リソースを大幅に削減できます。
たとえば、モデルサイズが 3B の場合に BitNet b1.58 を Llama と比較すると、速度は 2.71 倍向上しますが、GPU メモリ使用量は元のほぼ 4 分の 1 にすぎません。 そして、モデルのサイズが(たとえば、70B) より大きくなると、速度の向上とメモリの節約がより顕著になります。
この伝統に対する破壊的なアイデアは、ネチズンを本当に輝かせます。この論文は X についても高い注目を集めました:
必要なのは 1 ビットだけです。

(トランスフォーマー) に基づいており、nn.Linear を BitLinear に置き換えます。
具体的な最適化については、まず先ほどの「0を足す」、つまり重み量子化(重み量子化)です。
BitNet b1.58 モデルの重みは 3 進値 {-1, 0, 1} に量子化されます。これは、2 進法で各重みを表すのに 1.58 ビットを使用するのと同等です。この定量化方法により、モデルのメモリ フットプリントが削減され、計算プロセスが簡素化されます。
定量関数設計の観点から、重みを-1、0、または1に制限するために、研究者らはA定量化を採用しました。アブ平均と呼ばれる関数。
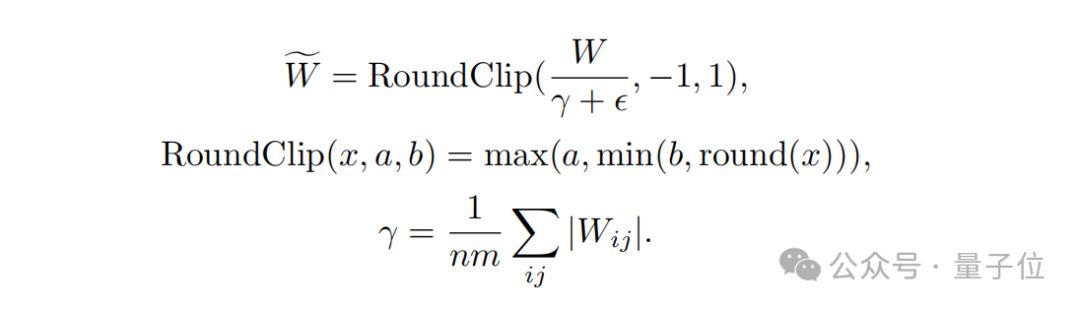
活性化量子化(活性化量子化)です。
アクティベーション値の量子化は BitNet での実装と同じですが、アクティベーション値は非線形関数の前で範囲 [0, Qb] にスケーリングされません。代わりに、アクティベーションは [-Qb, Qb] の範囲にスケーリングされて、ゼロ点量子化が排除されます。BitNet b1.58 をオープンソース コミュニティと互換性を持たせるために、研究チームは RMSNorm、SwiGLU などの LLaMA モデルのコンポーネントを採用し、簡単に統合できるようにしたことは言及する価値があります。主流のオープンソース ソフトウェア。
最後に、実験的なパフォーマンスの比較に関して、チームは、BitNet b1.58 と FP16 LLaMA LLM をさまざまなサイズのモデルで比較しました。
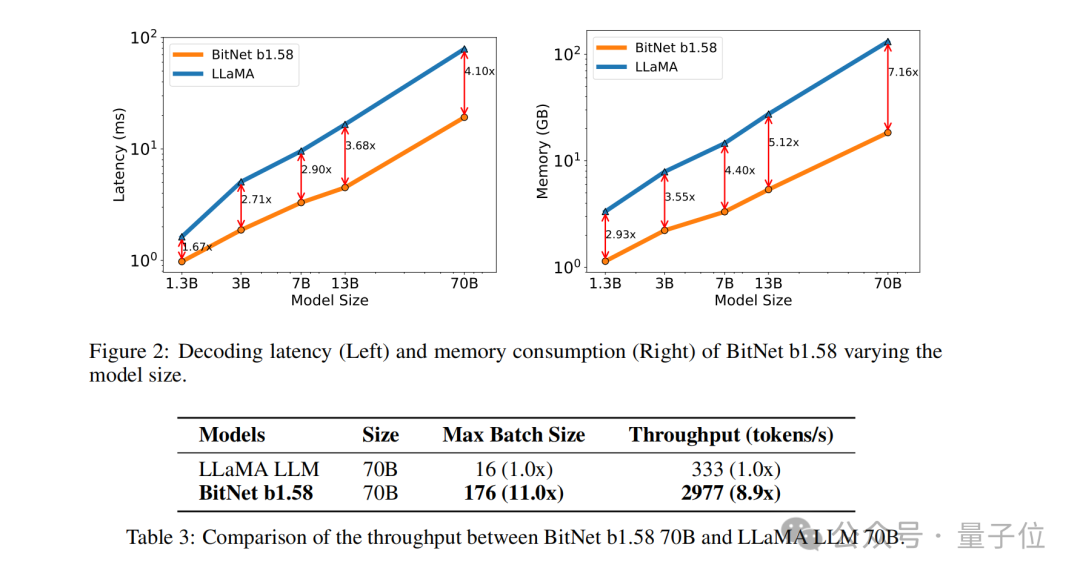
結果は、BitNet b1.58 が 3B モデル サイズでの複雑さにおいて完全精度 LLaMA LLM に匹敵し始め、同時にレイテンシ、メモリ使用量、およびスループットのパフォーマンスが向上していることを示しています。 . 大幅に改善されました。
そして、モデルのサイズが大きくなると、このパフォーマンスの向上はより顕著になります。
ネチズン: 消費者グレードの GPU で 120B の大規模モデルを実行可能
前述したように、この研究のユニークな方法は、インターネット上で多くの激しい議論を引き起こしました。
DeepLearning.scala 作者の Yang Bo 氏は次のように述べています:
オリジナルの BitNet と比較して、BitNet b1.58 の最大の特徴はパラメータが 0 であることです。量子化関数を少し変更することで、パラメータ 0 の割合を制御できるのではないかと思います。 0 パラメータの割合が大きい場合、重みをスパース形式で保存できるため、各パラメータが占める平均ビデオ メモリは 1 ビット未満になります。これは重量レベルの MoE に相当します。通常のMoEよりも上品な印象だと思います。
同時に、彼は BitNet の欠点も提起しました。
BitNet の最大の欠点は、推論中のメモリ オーバーヘッドを削減できるにもかかわらず、オプティマイザーの状態と勾配が依然として浮動小数点数を使用していることです。ポイント番号、トレーニングは依然として非常に多くのメモリを消費します。 BitNet をトレーニング中にビデオ メモリを節約するテクノロジーと組み合わせることができれば、従来の半精度ネットワークと比較して、同じ計算能力とビデオ メモリでより多くのパラメータをサポートできるため、大きな利点が得られると思います。
オプティマイザ状態のグラフィックス メモリのオーバーヘッドを節約する現在の方法は、オフロードです。勾配のメモリ使用量を節約する方法としては、ReLoRA が考えられます。ただし、ReLoRA の論文実験では 10 億のパラメータを持つモデルのみが使用されており、それを数百億、数千億のパラメータを持つモデルに一般化できるという証拠はありません。

 それでは、この新しいアプローチについてどう思いますか?
それでは、この新しいアプローチについてどう思いますか? 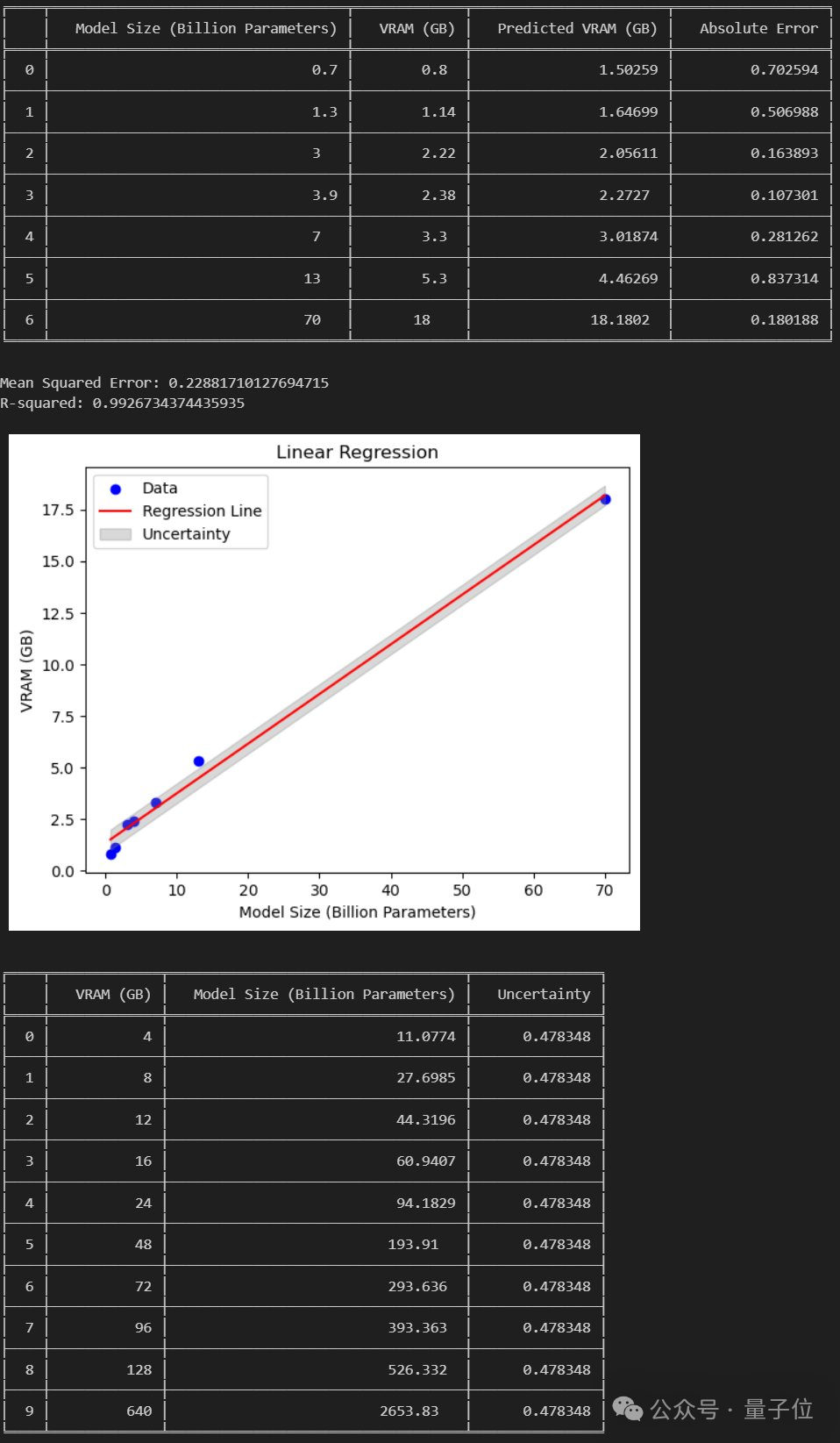
以上がMicrosoft の 6 ページの論文は爆発的です: 三元 LLM、とてもおいしいです!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7515
7515
 15
1378
52
79
11
19
64
15
1378
52
79
11
19
64

 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
この記事では、DebianシステムのApachewebサーバーのロギングレベルを調整する方法について説明します。構成ファイルを変更することにより、Apacheによって記録されたログ情報の冗長レベルを制御できます。方法1:メイン構成ファイルを変更して、構成ファイルを見つけます。Apache2.xの構成ファイルは、通常/etc/apache2/ディレクトリにあります。ファイル名は、インストール方法に応じて、apache2.confまたはhttpd.confである場合があります。構成ファイルの編集:テキストエディターを使用してルートアクセス許可を使用して構成ファイルを開く(nanoなど):sudonano/etc/apache2/apache2.conf
 Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian Systemsでは、OpenSSLは暗号化、復号化、証明書管理のための重要なライブラリです。中間の攻撃(MITM)を防ぐために、以下の測定値をとることができます。HTTPSを使用する:すべてのネットワーク要求がHTTPの代わりにHTTPSプロトコルを使用していることを確認してください。 HTTPSは、TLS(Transport Layer Security Protocol)を使用して通信データを暗号化し、送信中にデータが盗まれたり改ざんされたりしないようにします。サーバー証明書の確認:クライアントのサーバー証明書を手動で確認して、信頼できることを確認します。サーバーは、urlsessionのデリゲート方法を介して手動で検証できます
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
このガイドでは、Debian SystemsでSyslogの使用方法を学ぶように導きます。 Syslogは、ロギングシステムとアプリケーションログメッセージのLinuxシステムの重要なサービスです。管理者がシステムアクティビティを監視および分析して、問題を迅速に特定および解決するのに役立ちます。 1. syslogの基本的な知識Syslogのコア関数には以下が含まれます。複数のログ出力形式とターゲットの場所(ファイルやネットワークなど)をサポートします。リアルタイムのログ表示およびフィルタリング機能を提供します。 2。syslog(rsyslogを使用)をインストールして構成するDebianシステムは、デフォルトでrsyslogを使用します。次のコマンドでインストールできます:sudoaptupdatesud
