

PHP 配列の基礎となる実装ロジックの包括的な分析

はじめに
php エディタ Banana は、PHP 配列の基礎となる実装ロジックを包括的に分析します。 PHP の配列は柔軟で強力なデータ構造ですが、その背後にある実装ロジックは非常に複雑です。この記事では、配列の内部構造、インデックスとハッシュ テーブルの関係、配列の追加、削除、変更、クエリ操作の実装方法など、PHP 配列の基礎となる原則を詳しく説明します。 PHP 配列の基礎となる実装ロジックを理解することで、開発者は重要なデータ構造である配列をより深く理解し、利用できるようになります。
配列の構造
PHP カーネルでは配列はどのように見えるのでしょうか? PHP の ソース コード から構造を次のように確認できます。
<code>// 定义结构体别名为 HashTable
typedef struct _zend_array HashTable;
struct _zend_array {
// <strong class="keylink">GC</strong> 保存引用计数,内存管理相关;本文不涉及
zend_refcounted_h gc;
// u 储存辅助信息;本文不涉及
u<strong class="keylink">NIO</strong>n {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar consistency)
} v;
uint32_t flags;
} u;
// 用于散列函数
uint32_t nTableMask;
// arData 指向储存元素的数组第一个 Bucket,Bucket 为统一的数组元素类型
Bucket *arData;
// 已使用 Bucket 数
uint32_t nNumUsed;
// 数组内有效元素个数
uint32_t nNumOfElements;
// 数组总容量
uint32_t nTableSize;
// 内部指针,用于遍历
uint32_t nInternalPointer;
// 下一个可用数字<strong class="keylink">索引</strong>
zend_long nNextFreeElement;
// 析构函数
dtor_func_t pDestructor;
};</code>##nNum Used
とnNumOfElementsの違い:nNumusedは、arData配列で使用されているBucket番号を参照します。配列は、要素のBucketに対応する値を置き換えるだけであるためです。要素を削除した後、型はIS_UNDEFに設定されます (要素が削除されるたびに配列を移動して再インデックスするのは時間の無駄であるため)、nNumOfElements配列内の実際の要素数に対応します。nTableSize
配列の容量。この値は 2 の累乗です。 PHPの配列は可変長ですが、C言語の配列は固定長です PHPの可変長配列の機能を実現するために、nTableSizeが正しいかどうかを判定する「展開」の仕組みが採用されています。要素が挿入されるたびに決定されるため、保存するだけで十分です。不十分な場合は、nTableSizeの 2 倍のサイズの新しい配列を再適用し、元の配列をコピーします (この時点で、元の配列)とインデックスを再作成します。nNextFreeElement- 次に使用可能な数値インデックスを保存します (PHP など)
$a[] = 1;
この使用法ではインデックスが挿入されます。nNextFreeElementの要素、その後nNextFreeElementが 1 ずつ増加します。_zend_array
Bucket 構造体を見てみましょう:
<code>typedef struct _Bucket {
// 数组元素的值
zval val;
// key 通过 Time 33 <strong class="keylink">算法</strong>计算得到的哈希值或数字索引
zend_ulong h;
// 字符键名,数字索引则为 NULL
zend_string *key;
} Bucket;</code>配列アクセスPHP 配列は一般的なハッシュとは異なり、ハッシュ テーブルに基づいて実装されることがわかります。テーブル 違いは、PHP の配列が要素の順序付けも実装していることです、つまり、挿入された要素はメモリの観点からは連続的であり、順序が乱れていません。この順序付けを実現するために、PHP は「マッピング テーブル」テクノロジを使用します。以下は、PHP 配列 :-D の要素にアクセスする方法を示す図です。
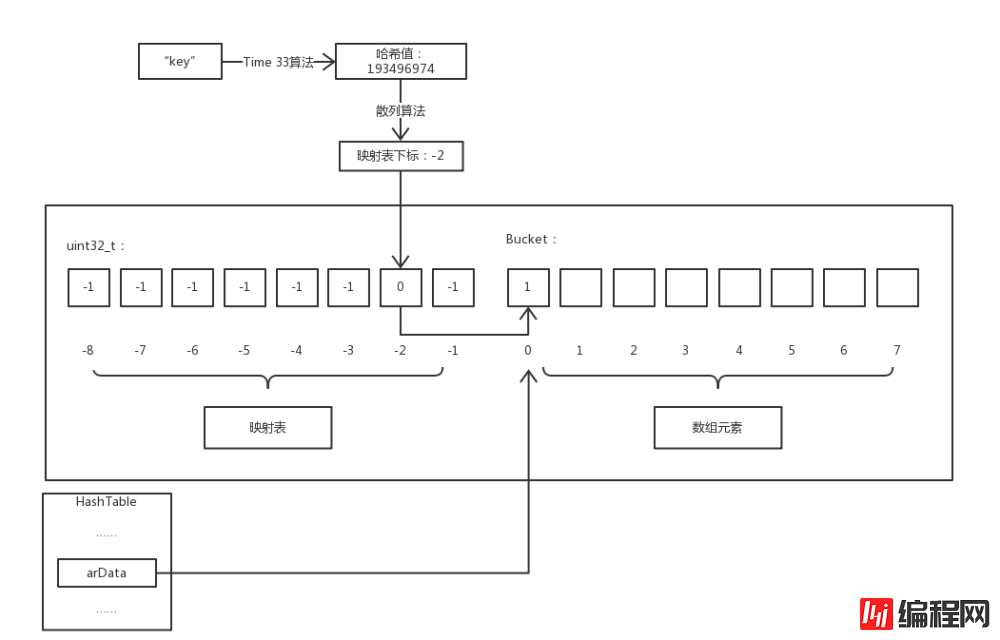 注: マッピング テーブルの添字のキー名は 2 回ハッシュ化されているため、区別するために、この記事では最初のハッシュを参照するためにハッシュを使用します。 . ハッシュは 2 番目のハッシュです。
注: マッピング テーブルの添字のキー名は 2 回ハッシュ化されているため、区別するために、この記事では最初のハッシュを参照するためにハッシュを使用します。 . ハッシュは 2 番目のハッシュです。
図からわかるように、マッピング テーブルと配列要素は同じ連続メモリ上にあります。マッピング テーブルは記憶要素と同じ長さの整数配列です。そのデフォルト値は次のとおりです。 -1 で、有効な値は Bucket
です。配列の添字です。そして、HashTable->arData は、このメモリ内の Bucket 配列の最初の要素を指します。 例:$a['key']
$a 内のキーが key であるメンバーにアクセスします。プロセスは次のようになります。最初のパス Time 33 アルゴリズムは、key のハッシュ値を計算し、マッピング テーブルに保存されている値は Bucket# であるため、ハッシュ アルゴリズムを使用してハッシュ値に対応するマッピング テーブルの添字を計算します。 ## 配列内の添字値。Bucket 配列内の対応する要素を取得できます。 次に、ハッシュ アルゴリズムについて説明します。ハッシュ アルゴリズムは、キー名のハッシュ値を「マッピング テーブル」の添え字にマッピングするアルゴリズムです。実際、これは非常に簡単で、たった 1 行のコードです: <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false"><code>nIndex = h | ht->nTableMask;</code></pre><div class="contentsignin">ログイン後にコピー</div></div> OR ハッシュ値と
を使用して、マッピング テーブルの添字を取得します。ここで、
nTableMask の値は、 は ##nTableSize 这看似与第一张图差不多,但我们同样访问 插入元素的函数 前面将数组结构的时候我们有提到扩容,而在插入元素的代码里有这样一个宏 重新索引的逻辑在 嗯哼,本文就到此结束了,因为自身水平原因不能解释的十分详尽清楚。这算是我写过最难写的内容了,写完之后似乎觉得这篇文章就我自己能看明白/(ㄒoㄒ)/~~因为文笔太辣鸡。想起一句话「如果你不能简单地解释一样东西,说明你没真正理解它。」PHP 的源码里有很多细节和实现我都不算熟悉,这篇文章只是一个我的 PHP 底层学习的开篇,希望以后能够写出真正深入浅出的好文章。 の負の数です。 nTableSize の値は 2 の累乗であるため、h | ht->nTableMask の値の範囲は [-nTableSize, -1] になります。間、マッピング テーブルの添え字の範囲内に正確にあります。なぜ単純な「剰余」演算を使用せず、わざわざ「ビットごとの OR」演算を使用するのでしょうか? 「ビットごとの OR」演算は「剰余」演算よりもはるかに高速であるため、この頻繁に使用される演算については、より複雑な実装によってもたらされる時間 最適化 は価値があると思います。 ハッシュ競合異なるキー名のハッシュ値をハッシュ計算して得られる「マッピングテーブル」の添字が同一である場合があり、ハッシュ競合が発生します。この状況に対して、PHP は「チェーンアドレス方式」を使用して解決します。ハッシュ競合が発生した要素へのアクセスの状況を次の図に示します。$a['key'] 的过程多了一些步骤。首先通过散列运算得出映射表下标为 -2 ,然后访问映射表发现其内容指向 arData 数组下标为 1 的元素。此时我们将该元素的 key 和要访问的键名相比较,发现两者并不相等,则该元素并非我们所想访问的元素,而元素的 val.u2.next 保存的值正是下一个具有相同散列值的元素对应 arData 数组的下标,所以我们可以不断通过 next 的值遍历直到找到键名相同的元素或查找失败。插入元素
_zend_hash_add_or_update_i ,基于 PHP 7.2.9 的代码如下:<code>static zend_always_inline zval *_zend_hash_add_or_update_i(HashTable *ht, zend_string *key, zval *pData, uint32_t flag ZEND_FILE_LINE_DC)
{
zend_ulong h;
uint32_t nIndex;
uint32_t idx;
Bucket *p;
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
if (UNEXPECTED(!(ht->u.flags & HASH_FLAG_INITIALIZED))) { // 数组未初始化
// 初始化数组
CHECK_INIT(ht, 0);
// 跳转至插入元素段
goto add_to_hash;
} else if (ht->u.flags & HASH_FLAG_PACKED) { // 数组为连续数字索引数组
// 转换为关联数组
zend_hash_packed_to_hash(ht);
} else if ((flag & HASH_ADD_NEW) == 0) { // 添加新元素
// 查找键名对应的元素
p = zend_hash_find_bucket(ht, key);
if (p) { // 若相同键名元素存在
zval *data;
if (flag & HASH_ADD) { // 指定 add 操作
if (!(flag & HASH_UPDATE_INDIRECT)) { // 若不允许更新间接类型变量则直接返回
return NULL;
}
// 确定当前值和新值不同
ZEND_ASSERT(&p->val != pData);
// data 指向原数组成员值
data = &p->val;
if (Z_TYPE_P(data) == IS_INDIRECT) { // 原数组元素变量类型为间接类型
// 取间接变量对应的变量
data = Z_INDIRECT_P(data);
if (Z_TYPE_P(data) != IS_UNDEF) { // 该对应变量存在则直接返回
return NULL;
}
} else { // 非间接类型直接返回
return NULL;
}
} else { // 没有指定 add 操作
// 确定当前值和新值不同
ZEND_ASSERT(&p->val != pData);
// data 指向原数组元素值
data = &p->val;
// 允许更新间接类型变量则 data 指向对应的变量
if ((flag & HASH_UPDATE_INDIRECT) && Z_TYPE_P(data) == IS_INDIRECT) {
data = Z_INDIRECT_P(data);
}
}
if (ht->pDestructor) { // 析构函数存在
// 执行析构函数
ht->pDestructor(data);
}
// 将 pData 的值复制给 data
ZVAL_COPY_VALUE(data, pData);
return data;
}
}
// 如果哈希表已满,则进行扩容
ZEND_HASH_IF_FULL_DO_RESIZE(ht);
add_to_hash:
// 数组已使用 Bucket 数 +1
idx = ht->nNumUsed++;
// 数组有效元素数目 +1
ht->nNumOfElements++;
// 若内部指针无效则指向当前下标
if (ht->nInternalPointer == HT_INVALID_IDX) {
ht->nInternalPointer = idx;
}
zend_hash_iterators_update(ht, HT_INVALID_IDX, idx);
// p 为新元素对应的 Bucket
p = ht->arData + idx;
// 设置键名
p->key = key;
if (!ZSTR_IS_INTERNED(key)) {
zend_string_addref(key);
ht->u.flags &= ~HASH_FLAG_STATIC_KEYS;
zend_string_hash_val(key);
}
// 计算键名的哈希值并赋值给 p
p->h = h = ZSTR_H(key);
// 将 pData 赋值该 Bucket 的 val
ZVAL_COPY_VALUE(&p->val, pData);
// 计算映射表下标
nIndex = h | ht->nTableMask;
// 解决冲突,将原映射表中的内容赋值给新元素变量值的 u2.next 成员
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
// 将映射表中的值设为 idx
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx);
return &p->val;
}</code> 扩容
ZEND_HASH_IF_FULL_DO_RESIZE,这个宏其实就是调用了 zend_hash_do_resize 函数,对数组进行扩容并重新索引。注意:并非每次 Bucket 数组满了都需要扩容,如果 Bucket 数组中 IS_UNDEF 元素的数量占较大比例,就直接将 IS_UNDEF 元素删除并重新索引,以此节省内存。下面我们看看 zend_hash_do_resize 函数:zend_hash_rehash 函数中,代码如下: 总结
以上がPHP 配列の基礎となる実装ロジックの包括的な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 Ubuntu および Debian 用の PHP 8.4 インストールおよびアップグレード ガイド
Dec 24, 2024 pm 04:42 PM
Ubuntu および Debian 用の PHP 8.4 インストールおよびアップグレード ガイド
Dec 24, 2024 pm 04:42 PM
PHP 8.4 では、いくつかの新機能、セキュリティの改善、パフォーマンスの改善が行われ、かなりの量の機能の非推奨と削除が行われています。 このガイドでは、Ubuntu、Debian、またはその派生版に PHP 8.4 をインストールする方法、または PHP 8.4 にアップグレードする方法について説明します。
 CakePHP について話し合う
Sep 10, 2024 pm 05:28 PM
CakePHP について話し合う
Sep 10, 2024 pm 05:28 PM
CakePHP は、PHP 用のオープンソース フレームワークです。これは、アプリケーションの開発、展開、保守をより簡単にすることを目的としています。 CakePHP は、強力かつ理解しやすい MVC のようなアーキテクチャに基づいています。モデル、ビュー、コントローラー
 PHP 開発用に Visual Studio Code (VS Code) をセットアップする方法
Dec 20, 2024 am 11:31 AM
PHP 開発用に Visual Studio Code (VS Code) をセットアップする方法
Dec 20, 2024 am 11:31 AM
Visual Studio Code (VS Code とも呼ばれる) は、すべての主要なオペレーティング システムで利用できる無料のソース コード エディター (統合開発環境 (IDE)) です。 多くのプログラミング言語の拡張機能の大規模なコレクションを備えた VS Code は、
 CakePHP クイックガイド
Sep 10, 2024 pm 05:27 PM
CakePHP クイックガイド
Sep 10, 2024 pm 05:27 PM
CakePHP はオープンソースの MVC フレームワークです。これにより、アプリケーションの開発、展開、保守がはるかに簡単になります。 CakePHP には、最も一般的なタスクの過負荷を軽減するためのライブラリが多数あります。
 PHPでHTML/XMLを解析および処理するにはどうすればよいですか?
Feb 07, 2025 am 11:57 AM
PHPでHTML/XMLを解析および処理するにはどうすればよいですか?
Feb 07, 2025 am 11:57 AM
このチュートリアルでは、PHPを使用してXMLドキュメントを効率的に処理する方法を示しています。 XML(拡張可能なマークアップ言語)は、人間の読みやすさとマシン解析の両方に合わせて設計された多用途のテキストベースのマークアップ言語です。一般的にデータストレージに使用されます
 母音を文字列にカウントするPHPプログラム
Feb 07, 2025 pm 12:12 PM
母音を文字列にカウントするPHPプログラム
Feb 07, 2025 pm 12:12 PM
文字列は、文字、数字、シンボルを含む一連の文字です。このチュートリアルでは、さまざまな方法を使用してPHPの特定の文字列内の母音の数を計算する方法を学びます。英語の母音は、a、e、i、o、u、そしてそれらは大文字または小文字である可能性があります。 母音とは何ですか? 母音は、特定の発音を表すアルファベットのある文字です。大文字と小文字など、英語には5つの母音があります。 a、e、i、o、u 例1 入力:string = "tutorialspoint" 出力:6 説明する 文字列「TutorialSpoint」の母音は、u、o、i、a、o、iです。合計で6元があります
 今まで知らなかったことを後悔している 7 つの PHP 関数
Nov 13, 2024 am 09:42 AM
今まで知らなかったことを後悔している 7 つの PHP 関数
Nov 13, 2024 am 09:42 AM
あなたが経験豊富な PHP 開発者であれば、すでにそこにいて、すでにそれを行っていると感じているかもしれません。あなたは、運用を達成するために、かなりの数のアプリケーションを開発し、数百万行のコードをデバッグし、大量のスクリプトを微調整してきました。

