

Chen Danqi チームによる新作: Llama-2 コンテキストが 128k に拡張され、10 倍のスループットに必要なメモリは 1/6 のみ

Chen Danqi チームは、新しい LLMコンテキスト ウィンドウ拡張機能をリリースしました。メソッド:
これは、トレーニングに 8,000 トークン ドキュメントのみを使用し、Llama-2 ウィンドウを次のように拡張できます。 128k。
最も重要なことは、このプロセスでは、モデルは元のメモリ の 1/6 のみを必要とし、モデルは 10 倍のスループットを得ることができるということです。
トレーニング コストを削減することもできます :
この方法を使用して 7B アルパカ 2 をトレーニングします。 A100の一部だけで完成します。 チームは次のように述べています:
この方法が便利で使いやすく、将来の LLM に安価で効果的なロング コンテキスト機能を提供することを願っています。
現在、モデルとコードはHuggingFaceとGitHubで公開されています。
 2 つのコンポーネントを追加するだけです
2 つのコンポーネントを追加するだけです
このメソッドは
CEPEと呼ばれ、正式名は「Parallel Encoding Context Extension#」です。 ##(並列エンコーディングによるコンテキスト拡張)」。 軽量フレームワークとして、事前トレーニングされたディレクティブ微調整 モデルのコンテキスト ウィンドウを拡張するために使用できます。
事前トレーニングされたデコーダー専用言語モデルの場合、CEPE は 2 つの小さなコンポーネントを追加することでそれを拡張します。
1 つは長いエンコーダーです。コンテキストはブロック エンコードされます。
1 つはクロスアテンション モジュール で、エンコーダの表現に焦点を当てるためにデコーダの各層に挿入されます。
完全なアーキテクチャは次のとおりです。
この図では、エンコーダー モデルは、コンテキストの 3 つの追加ブロックを並行してエンコードし、最終的な隠れた表現と連結します。その後、デコーダのクロスアテンション層への入力として使用されます。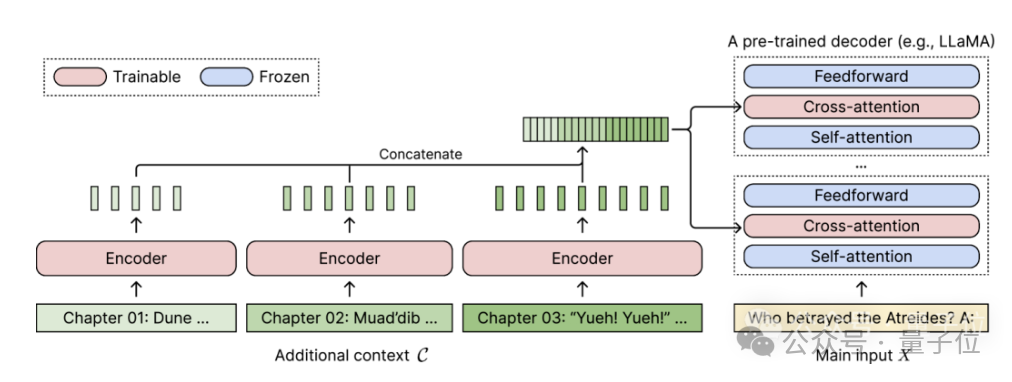 ここで、クロスアテンション層は主に、デコーダ モデルにおけるセルフアテンション層とフィードフォワード層の間のエンコーダ表現に焦点を当てています。
ここで、クロスアテンション層は主に、デコーダ モデルにおけるセルフアテンション層とフィードフォワード層の間のエンコーダ表現に焦点を当てています。
CEPE は、ラベルを付ける必要のないトレーニング データを慎重に選択することで、モデルが長いコンテキスト機能を備え、ドキュメントの検索にも優れています。
著者は、このような CEPE には主に 3 つの大きな利点があると紹介しています。
(1) 長さは一般化できる制約を受けないため位置エンコーディング 代わりに、制約はセグメント内にエンコードされたコンテキストを持ち、各セグメントは独自の位置エンコーディングを持ちます。
(2) 高効率小型エンコーダと並列エンコードを使用してコンテキストを処理すると、計算コストを削減できます。同時に、クロスアテンションはエンコーダーの最後の層の表現のみに焦点を当てているため、デコーダーのみを使用する言語モデルは、各トークンのキーと値のペアをそれぞれのトークンにキャッシュする必要があります。層なので、比較すると、CEPE に必要なメモリが大幅に削減されます。
(3) トレーニング コストの削減
完全な微調整方法とは異なり、CEPE は大規模なデコーダー モデルをフリーズしたまま、エンコーダーとクロスアテンションのみを調整します。 著者は、7B デコーダを 400M エンコーダとクロスアテンション レイヤー (合計 14 億パラメータ) を備えたモデル
チームは CEPE を Llama-2 に適用し、200 億トークンを使用してフィルタリングされたバージョンの RedPajama でトレーニングします (Llama-2 の事前トレーニング予算のみ 1) %)
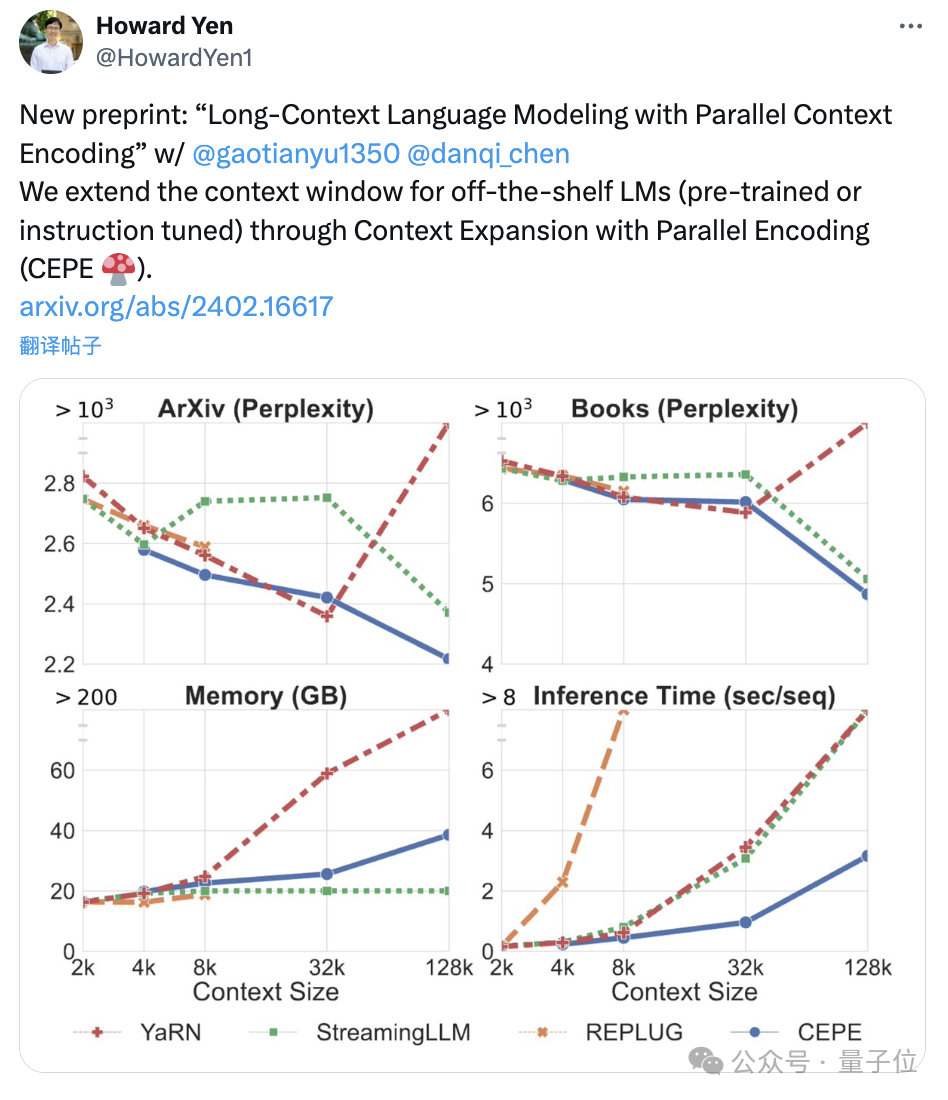
。 まず、完全に微調整された 2 つのモデル、LLAMA2-32K と YARN-64K と比較して、CEPE はすべてのデータセットでより低い、または同等のperplexity## を達成します。メモリ使用量が減り、スループットが向上します。
コンテキストが 128k (トレーニング長の 8k をはるかに超える) に増加すると、低メモリ状態のままで CEPE の複雑さは減少し続けます。
対照的に、Llama-2-32K と YARN-64K は、トレーニング期間を超えて一般化できないだけでなく、メモリ コストの大幅な増加も伴います。 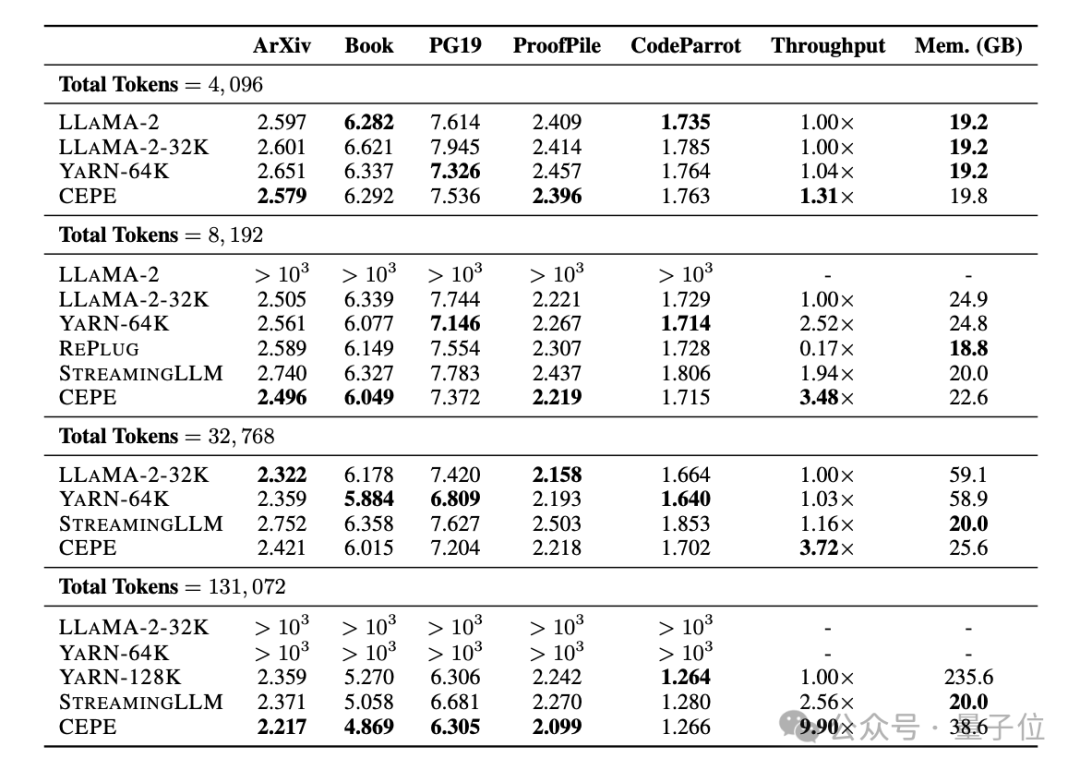
第 2 に、
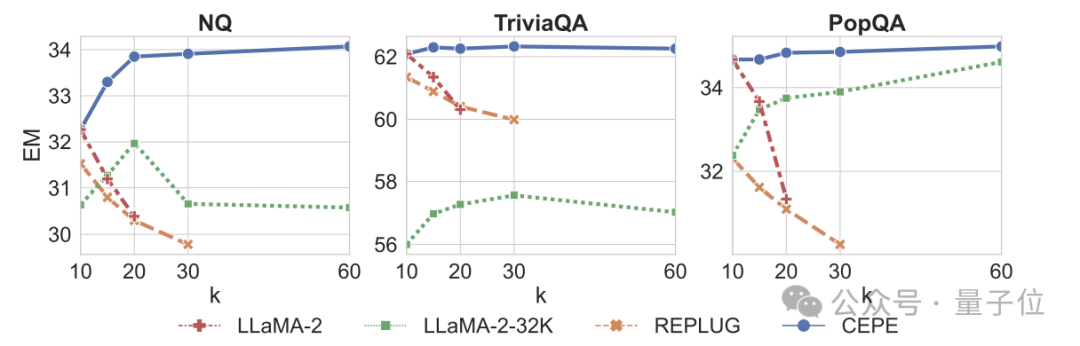
検索機能
が強化されます。 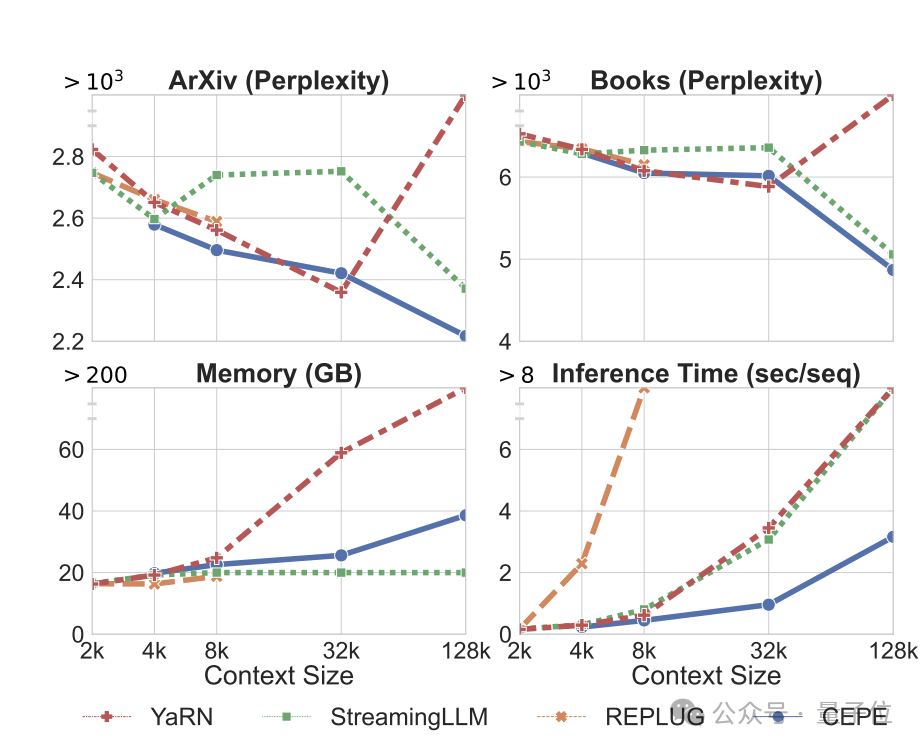
取得したコンテキストを使用することで、CEPE はモデルの複雑さを効果的に改善でき、そのパフォーマンスは RePlug よりも優れています。 段落 k=50 (トレーニングは 60) であっても、CEPE は複雑さを改善し続けることに注目する価値があります。 これは、CEPE が検索拡張設定にうまく移行するのに対し、フルコンテキスト デコーダー モデルではこの機能が低下することを示しています。 3 つ目は、オープン ドメインの質問と回答機能 # が大幅に優れていることです。 下の図に示すように、CEPE はすべてのデータセットと段落 k パラメーターにおいて他のモデルよりも大幅に優れていますが、他のモデルとは異なり、k 値が大きくなるにつれてパフォーマンスが大幅に低下します。 これは、CEPE が多数の冗長または無関係な段落に敏感ではないことも示しています。 要約すると、CEPE は、他のほとんどのソリューションと比較して、メモリと計算コストがはるかに低く、上記のすべてのタスクで優れたパフォーマンスを発揮します。 最後に、これらに基づいて、著者は命令チューニング モデルに特化した CEPE-Distilled (CEPED) を提案しました。 ラベルのないデータのみを使用してモデルのコンテキスト ウィンドウを拡張し、支援された KL 発散損失を通じて元の命令調整モデルの動作を新しいアーキテクチャに抽出し、それによって高価な長いコンテキスト命令を管理する必要性を排除します。追跡データ。 最終的に、CEPED は、命令を理解する能力を維持しながら、Llama-2 のコンテキスト ウィンドウを拡張し、モデルの長いテキストのパフォーマンスを向上させることができます。 CEPEには合計3人の著者がいます。 Yan Heguang(ハワード イェン) は、プリンストン大学のコンピューター サイエンスの修士課程の学生です。 二人目は、同校の博士課程学生で清華大学学士号を取得した高天宇さんです。 彼らは全員、責任著者の陳丹祁氏の生徒です。 原論文:https://arxiv.org/abs/2402.16617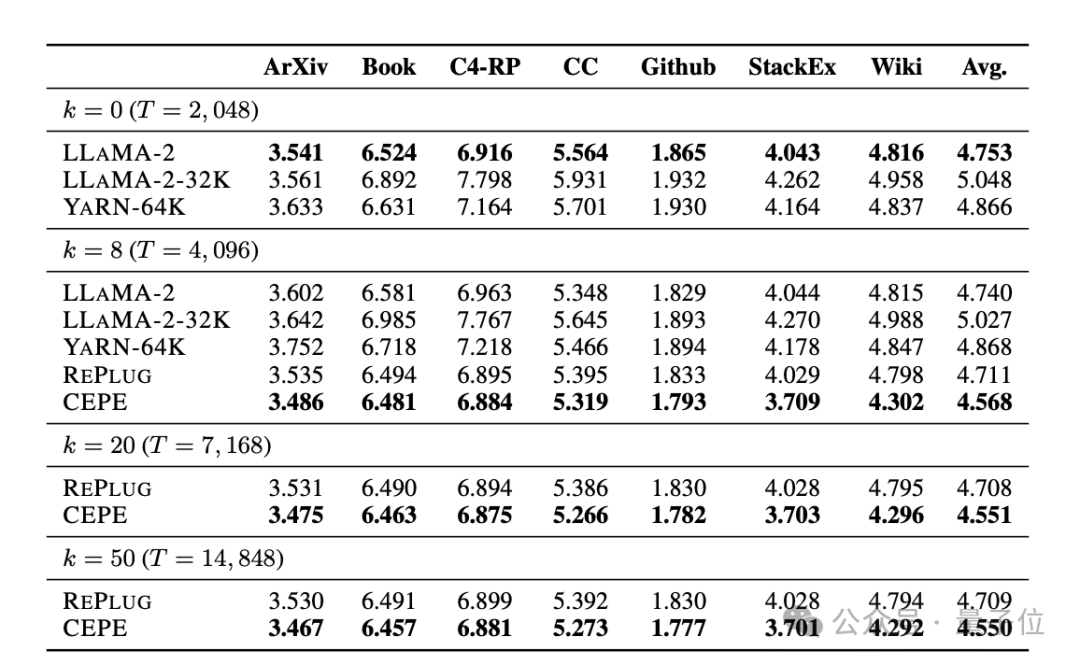
チーム紹介

参考リンク:https://twitter. com/HowardYen1/status/1762474556101661158
以上がChen Danqi チームによる新作: Llama-2 コンテキストが 128k に拡張され、10 倍のスループットに必要なメモリは 1/6 のみの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7328
7328
 9
1626
14
1350
46
1262
25
1209
29
9
1626
14
1350
46
1262
25
1209
29

 文字列を介してオブジェクトを動的に作成し、Pythonでメソッドを呼び出す方法は?
Apr 01, 2025 pm 11:18 PM
文字列を介してオブジェクトを動的に作成し、Pythonでメソッドを呼び出す方法は?
Apr 01, 2025 pm 11:18 PM
Pythonでは、文字列を介してオブジェクトを動的に作成し、そのメソッドを呼び出す方法は?これは一般的なプログラミング要件です。特に構成または実行する必要がある場合は...
 uvicornは、serving_forever()なしでhttpリクエストをどのように継続的に聞いていますか?
Apr 01, 2025 pm 10:51 PM
uvicornは、serving_forever()なしでhttpリクエストをどのように継続的に聞いていますか?
Apr 01, 2025 pm 10:51 PM
UvicornはどのようにしてHTTPリクエストを継続的に聞きますか? Uvicornは、ASGIに基づく軽量のWebサーバーです。そのコア機能の1つは、HTTPリクエストを聞いて続行することです...
 ChatGpt時代には、技術的なQ&Aコミュニティは課題にどのように対応できますか?
Apr 01, 2025 pm 11:51 PM
ChatGpt時代には、技術的なQ&Aコミュニティは課題にどのように対応できますか?
Apr 01, 2025 pm 11:51 PM
ChatGpt時代のテクニカルQ&Aコミュニティ:SegmentFaultの対応戦略StackOverFlow ...
 Pythonマルチプロセスパイプ通信で「パイプ閉じた」エラーを優雅に処理する方法は?
Apr 01, 2025 pm 11:12 PM
Pythonマルチプロセスパイプ通信で「パイプ閉じた」エラーを優雅に処理する方法は?
Apr 01, 2025 pm 11:12 PM
Pythonマルチプロセスパイプエラー「パイプは閉じています」? PythonのMultiprocessing Moduleでパイプメソッドを使用して、親子プロセス通信を使用する場合、遭遇する可能性があります...
 Webページデータを取得するときに動的読み込みコンテンツが欠落の問題を解決する方法は?
Apr 01, 2025 pm 11:24 PM
Webページデータを取得するときに動的読み込みコンテンツが欠落の問題を解決する方法は?
Apr 01, 2025 pm 11:24 PM
リクエストライブラリを使用してWebページのデータをクロールするときに遭遇する問題とソリューション。リクエストライブラリを使用してWebページデータを取得すると、時々遭遇します...
 GoまたはRustを使用してPythonスクリプトを呼び出して、真の並列実行を実現する方法は?
Apr 01, 2025 pm 11:39 PM
GoまたはRustを使用してPythonスクリプトを呼び出して、真の並列実行を実現する方法は?
Apr 01, 2025 pm 11:39 PM
GoまたはRustを使用してPythonスクリプトを呼び出して、真の並列実行を実現する方法は?最近、私はPythonを使用しています...
 セレンでログインした後、404エラーをリダイレクトする理由は何ですか?それを解決する方法は?
Apr 01, 2025 pm 10:54 PM
セレンでログインした後、404エラーをリダイレクトする理由は何ですか?それを解決する方法は?
Apr 01, 2025 pm 10:54 PM
シミュレーションログインの場合にシミュレーションログイン後に404エラーをリダイレクトするための解決策は、シミュレーションログインにSeleniumを使用すると、いくつかの困難な問題に遭遇することがよくあります。 �...
 flask-sqlalchemy ormオブジェクトをシリアル化する方法「タイプユーザーのオブジェクトはjsonシリアル化可能ではない」エラーを回避する方法は?
Apr 01, 2025 pm 10:15 PM
flask-sqlalchemy ormオブジェクトをシリアル化する方法「タイプユーザーのオブジェクトはjsonシリアル化可能ではない」エラーを回避する方法は?
Apr 01, 2025 pm 10:15 PM
Sqlalchemyと組み合わせたPythonflaskフレームワークを使用する場合のFlask-sqlalchemyormオブジェクトのシリアル化の問題の徹底的な分析...
