
 テクノロジー周辺機器
AI
Byte Wanka クラスターの技術詳細が公開: GPT-3 トレーニングは 2 日で完了し、計算能力使用率は NVIDIA Megatron-LM を超えました
テクノロジー周辺機器
AI
Byte Wanka クラスターの技術詳細が公開: GPT-3 トレーニングは 2 日で完了し、計算能力使用率は NVIDIA Megatron-LM を超えました
Byte Wanka クラスターの技術詳細が公開: GPT-3 トレーニングは 2 日で完了し、計算能力使用率は NVIDIA Megatron-LM を超えました

Sora の技術分析が進むにつれて、AI インフラストラクチャ の重要性がますます顕著になります。
Byte と北京大学の新しい論文がこの時点で注目を集めました:
この記事では、Byte によって構築された Wanka クラスター が ## 完全なGPT-3 スケール モデル (175B) を #1.75 日 以内にトレーニングします。
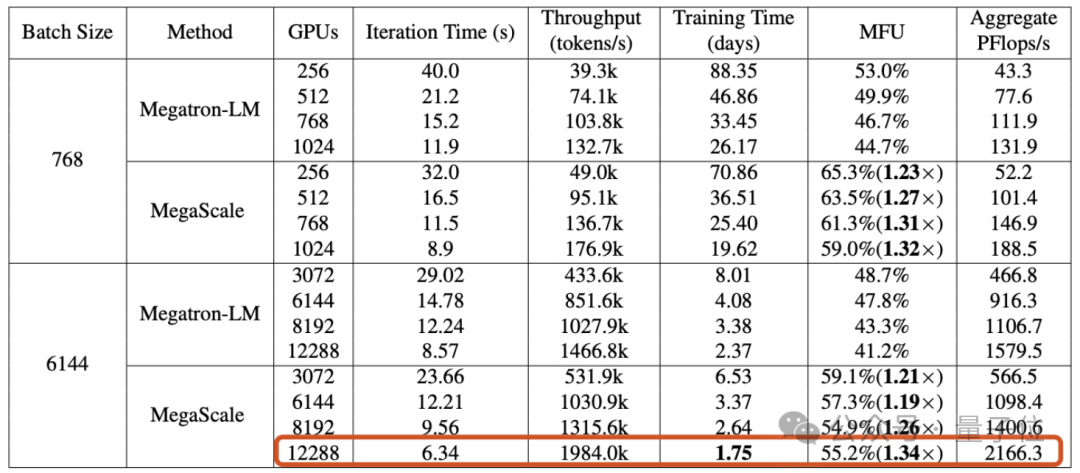
MegaScale と呼ばれる運用システムを提案しました。課題。
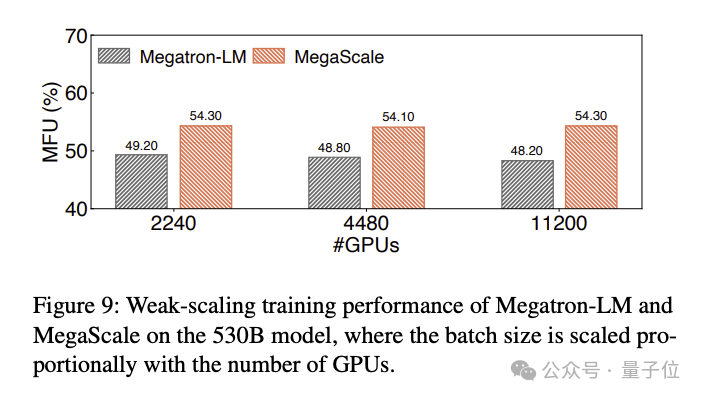
12288 GPU で 1750 億パラメータの大規模言語モデルをトレーニングした場合、MegaScale は 55.2%(MFU) という計算能力使用率を達成しました。これは、NVIDIA Megatron-LM の 1.34 倍です。
この論文は、2023 年 9 月の時点で、Byte が 10,000 枚を超えるカードを備えた Ampere アーキテクチャ GPU(A100/A800) クラスターを確立し、現在大規模なホッパーを構築していることも明らかにしました。アーキテクチャ (H100/H800)クラスター。
Wanka クラスターに適した制作システム大規模モデルの時代において、GPU の重要性はもはや説明する必要はありません。 しかし、カードの数がいっぱいになったときに大規模なモデルのトレーニングを直接開始することはできません。GPU クラスターの規模が「10,000」レベルに達したときに、効率と安定性を実現する方法 自体がエンジニアリング上の困難な問題です。
 #最初の課題: 効率。
#最初の課題: 効率。
大規模な言語モデルのトレーニングは単純な並列タスクではありません。モデルを複数の GPU に分散する必要があり、これらの GPU はトレーニング プロセスを共同で進めるために頻繁に通信する必要があります。通信に加えて、オペレーターの最適化、データの前処理、GPU メモリ消費などの要素はすべて、トレーニング効率を測定する指標である計算能力使用率
(MFU)に影響を与えます。
MFU は、理論上の最大スループットに対する実際のスループットの比率です。2 番目の課題: 安定性。
大規模な言語モデルのトレーニングには非常に長い時間がかかることが多く、これはトレーニング プロセス中の失敗や遅延が珍しくないことも意味します。
障害のコストは高くつくため、障害回復時間をいかに短縮するかが特に重要になります。
これらの課題に対処するために、ByteDance の研究者は MegaScale を構築し、Byte のデータ センターに導入して、さまざまな大規模モデルのトレーニングをサポートしました。
MegaScale は、NVIDIA Megatron-LM に基づいて改良されました。
 具体的な改善には、アルゴリズムとシステム コンポーネントの共同設計、通信と計算の重複の最適化、オペレーターの最適化、データ パイプラインの最適化、ネットワーク パフォーマンスが含まれます。チューニング等:
具体的な改善には、アルゴリズムとシステム コンポーネントの共同設計、通信と計算の重複の最適化、オペレーターの最適化、データ パイプラインの最適化、ネットワーク パフォーマンスが含まれます。チューニング等:
- アルゴリズムの最適化: 研究者は、トレーニングを改善するために、並列化された Transformer ブロック、スライディング ウィンドウ アテンション メカニズム(SWA)、および LAMB をモデル アーキテクチャ オプティマイザーに導入しました。モデルの収束を犠牲にすることなく効率を向上させます。
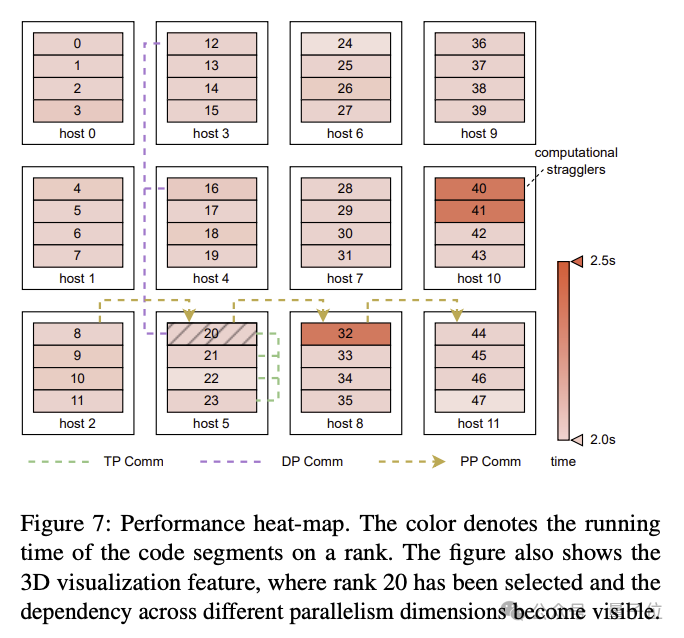
- #通信の重複: 3D 並列処理における各コンピューティング ユニットの動作の詳細な分析に基づく(データ並列処理、パイプライン並列処理、テンソル並列処理) 、研究者らは、非クリティカルな実行パスでの操作によって生じる遅延を効果的に削減し、モデル トレーニングの各ラウンドの反復時間を短縮するための技術戦略を設計しました。
- 効率的な演算子: GEMM 演算子が最適化され、LayerNorm や GeLU などの演算が統合されて、複数のコアの起動に伴うオーバーヘッドが削減され、メモリ アクセス パターンが最適化されました。
- データ パイプラインの最適化: 非同期データの前処理と冗長なデータ ローダーの排除を通じて、データの前処理とロードを最適化し、GPU のアイドル時間を削減します。
- 集団通信グループの初期化: 分散トレーニングにおける NVIDIA マルチカード通信フレームワーク NCCL の初期化プロセスを最適化しました。 最適化を行わない場合、2048 GPU クラスターの初期化時間は 1047 秒ですが、最適化後は 5 秒未満に短縮でき、Wanka GPU クラスターの初期化時間は 30 秒未満に短縮できます。
- ネットワーク パフォーマンス チューニング: 3D 並列処理でマシン間のトラフィックを分析し、ネットワーク トポロジ設計、ECMP ハッシュ競合の削減、輻輳制御など、ネットワーク パフォーマンスを向上させるための技術ソリューションを設計します。および再送信タイムアウトの設定。
- フォールト トレランス: Wanka クラスターでは、ソフトウェアとハードウェアの障害は避けられません。研究者らは、自動障害特定と迅速な回復を実現するためのトレーニング フレームワークを設計しました。具体的には、システムコンポーネントとイベントを監視する診断ツールの開発、チェックポイントの高頻度保存トレーニングプロセスの最適化などが含まれます。

論文アドレス: https://arxiv.org/abs/2402.15627
以上がByte Wanka クラスターの技術詳細が公開: GPT-3 トレーニングは 2 日で完了し、計算能力使用率は NVIDIA Megatron-LM を超えましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1662
1662
 14
1418
52
1311
25
1261
29
1234
24
14
1418
52
1311
25
1261
29
1234
24

 ビットコインの価値はいくらですか
Apr 28, 2025 pm 07:42 PM
ビットコインの価値はいくらですか
Apr 28, 2025 pm 07:42 PM
ビットコインの価格は20,000ドルから30,000ドルの範囲です。 1。ビットコインの価格は2009年以来劇的に変動し、2017年には20,000ドル近くに達し、2021年にはほぼ60,000ドルに達しました。2。価格は、市場需要、供給、マクロ経済環境などの要因の影響を受けます。 3.取引所、モバイルアプリ、ウェブサイトを通じてリアルタイム価格を取得します。 4。ビットコインの価格は非常に不安定であり、市場の感情と外部要因によって駆動されます。 5.従来の金融市場と特定の関係を持ち、世界の株式市場、米ドルの強さなどの影響を受けています。6。長期的な傾向は強気ですが、リスクを慎重に評価する必要があります。
 2025年のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの1つです
Apr 28, 2025 pm 08:12 PM
2025年のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの1つです
Apr 28, 2025 pm 08:12 PM
2025年の世界の上位10の暗号通貨取引所には、Binance、Okx、Gate.io、Coinbase、Kraken、Huobi、Bitfinex、Kucoin、Bittrex、Poloniexが含まれます。これらはすべて、高い取引量とセキュリティで知られています。
 トップ通貨取引プラットフォームは何ですか?トップ10の最新の仮想通貨交換
Apr 28, 2025 pm 08:06 PM
トップ通貨取引プラットフォームは何ですか?トップ10の最新の仮想通貨交換
Apr 28, 2025 pm 08:06 PM
現在、上位10の仮想通貨交換にランクされています。1。Binance、2。Okx、3。Gate.io、4。CoinLibrary、5。Siren、6。HuobiGlobal Station、7。Bybit、8。Kucoin、9。Bitcoin、10。BitStamp。
 復号化GATE.IO戦略のアップグレード:Memebox 2.0でCrypto Asset Managementを再定義する方法は?
Apr 28, 2025 pm 03:33 PM
復号化GATE.IO戦略のアップグレード:Memebox 2.0でCrypto Asset Managementを再定義する方法は?
Apr 28, 2025 pm 03:33 PM
Memebox 2.0は、革新的なアーキテクチャとパフォーマンスのブレークスルーを通じて、暗号資産管理を再定義します。 1)3つの主要な問題点を解決します。資産サイロ、収入の減少、セキュリティと利便性のパラドックスです。 2)インテリジェントアセットハブ、動的リスク管理およびリターンエンハンスメントエンジン、クロスチェーン移動速度、平均降伏率、およびセキュリティインシデント応答速度が向上します。 3)ユーザーに、ユーザー価値の再構築を実現し、資産の視覚化、ポリシーの自動化、ガバナンス統合を提供します。 4)生態学的なコラボレーションとコンプライアンスの革新により、プラットフォームの全体的な有効性が向上しました。 5)将来的には、スマート契約保険プール、予測市場統合、AI主導の資産配分が開始され、引き続き業界の発展をリードします。
 世界のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの最新バージョンです
Apr 28, 2025 pm 08:09 PM
世界のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの最新バージョンです
Apr 28, 2025 pm 08:09 PM
世界の上位10の暗号通貨取引プラットフォームには、Binance、Okx、Gate.io、Coinbase、Kraken、Huobi Global、Bitfinex、Bittrex、Kucoin、Poloniexが含まれます。これらはすべて、さまざまな取引方法と強力なセキュリティ対策を提供します。
 トップ10の仮想通貨取引アプリは何ですか?最新のデジタル通貨交換ランキング
Apr 28, 2025 pm 08:03 PM
トップ10の仮想通貨取引アプリは何ですか?最新のデジタル通貨交換ランキング
Apr 28, 2025 pm 08:03 PM
Binance、OKX、Gate.ioなどの上位10のデジタル通貨交換は、システムを改善し、効率的な多様化したトランザクション、厳格なセキュリティ対策を改善しました。
 推奨される信頼できるデジタル通貨取引プラットフォーム。世界のトップ10のデジタル通貨交換。 2025
Apr 28, 2025 pm 04:30 PM
推奨される信頼できるデジタル通貨取引プラットフォーム。世界のトップ10のデジタル通貨交換。 2025
Apr 28, 2025 pm 04:30 PM
推奨される信頼できるデジタル通貨取引プラットフォーム:1。OKX、2。Binance、3。Coinbase、4。Kraken、5。Huobi、6。Kucoin、7。Bitfinex、8。Gemini、9。Bitstamp、10。Poloniex、これらのプラットフォームは、セキュリティ、ユーザーエクスペリエンス、ユーザーエクスペリエンス、ユーザーエクスペリエンス、ユーザーエクスペリエンスのデジタルエクスペリエンス、デジタルエクスペリエンスのデジタルエクスペリエンス、デジタルエクスペリエンスのために知られています。
 今日のビットコイン価格
Apr 28, 2025 pm 07:39 PM
今日のビットコイン価格
Apr 28, 2025 pm 07:39 PM
今日のビットコインの価格変動は、マクロ経済学、政策、市場感情などの多くの要因の影響を受けています。投資家は、情報に基づいた決定を下すために、技術的および基本的な分析に注意を払う必要があります。
