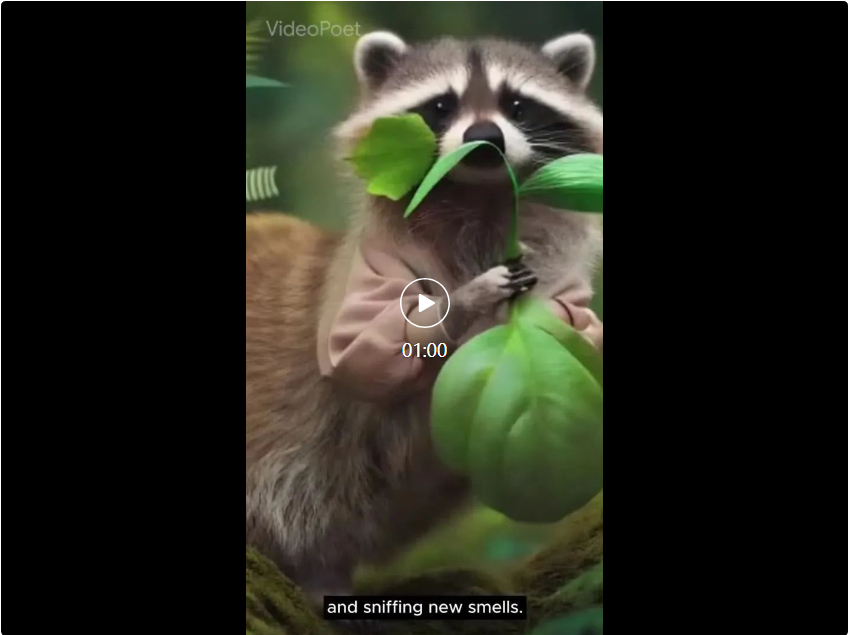
モナリザはあくびをし、ニワトリはアイロンの持ち上げ方を学びます... Google VideoPoet の大型モデルは非常に優れたパフォーマンスを発揮します。
2023 年末、テクノロジー企業は AI ビデオ生成の最後のレベルに影響を与えています。 #火曜日、Google が提案した大規模ビデオ生成モデルがオンラインに公開され、すぐに人々の注目を集めました。 VideoPoet と呼ばれるこの大規模な言語モデルは、革新的なゼロショット ビデオ生成ツールと考えられています。 VideoPoet は、テキストや画像からビデオを生成できるだけでなく、スタイル転送やビデオからスピーチを生成することもできます。結果として、多様でスムーズな動きを構築することができます。 
このニュースが発表されるとすぐに、多くの人がそれを歓迎しました。良好な結果をもたらした現在の少数の完成品を見てみると、大型モデル技術の開発は速すぎます。
この大規模なモデルによって生成されたビデオの長さに驚きを表明した人もいます:
出典: https://twitter.com/cybersphere_ai/status/1737257729167966353#こんなことを言う人もいますこれは革命です セックスの大規模な言語モデル。
#Google に対し、VideoPoet をできるだけ早くオープンソースにするよう呼びかけている人もいます。一般的な傾向は誰も待ってくれません。 生成 AI の進歩に伴い、最近、驚くべき画質を実証する新しいビデオ生成モデルが次々と登場しています。ビデオ生成における現在のボトルネックの 1 つは、一貫した大きな動きを生成することです。しかし、多くの場合、主要なモデルであっても小さなモーションしか生成できなかったり、大きなモーションを生成するときに顕著なアーティファクトが発生したりすることがあります。 動画生成における言語モデルの応用を探るため、Google の研究者は、次のようなさまざまな動画生成タスクを実行できる大規模言語モデル (LLM) VideoPoet を導入しました。テキストからビデオへ、画像からビデオへ、ビデオのスタイル化、ビデオの修復と拡張、ビデオからオーディオへ。 ヒント: 犬は、詳細が豊富な 8K のヘッドフォンで音楽を聴きます。
ヒント (左から右へ): 口からレーザー光線を放つサメ、雨の日に 5 番街を手をつないで歩くテディベア、鉄リフターのひよこ。
キュー (左から右へ): 黄色いタンポポの花びらでできた咆哮するライオン、地表での大爆発、ゴッホの星月夜に疾走する馬。鎧を着たリスがガチョウに乗り、パンダが自撮り写真を撮ります。
#画像からビデオを生成する
画像からビデオへの場合、VideoPoet は入力を受け取ることができます。画像を作成し、プロンプトを使用してアニメーション化します。
#モナリザのあくびを開始するには、画像とプロンプトを入力するだけです: 女性があくびをします。以下のような効果が得られます。 ヒント (左から右へ): 雷雨と稲妻が発生する荒海を航行する船、油絵風、たくさんの星がきらめく星雲の上を飛ぶ、風の強い日に崖の上に杖をついて立つ男性放浪者は眼下に浮かぶ雲海を見下ろした。
##VideoPoet は、テキスト プロンプトに基づいて入力ビデオをスタイル設定することもできます。 。
キュー (左から右へ): テディベアがきれいな氷の湖の上でスケートをし、金属製のライオンが炉の輝きの中で吠えます。
オーディオの生成
VideoPoet はオーディオを生成することもできます。モデルは最初に 2 秒のクリップを生成するように求められ、次にテキストによるガイダンスなしでフレームの音声を予測しようとします。このようにして、VideoPoet は単一のモデルからビデオとオーディオを生成できます。 #長いビデオ##VideoPoet は長いビデオも生成できます。デフォルトは 2 秒です。このプロセスを無限に繰り返すことで、ビデオの最後の 1 秒を調整し、次の 1 秒を予測することで、任意の長さのビデオを生成できます。以下は、テキスト入力から長いビデオを生成する VideoPoet のデモの例です。ヒント: FPV 映像には、明るい青色の川、滝、大きくて垂直に切り立った崖のある、ジャングルの中にある非常に鮮明なエルフストーンの都市が示されています。
ビデオの拡張
ユーザーはプロンプトを変更して、ビデオを拡張できます。松の木に囲まれた山道をバイクに乗る 2 頭のアライグマのオリジナル ビデオ (8k)。拡大されたビデオには、バイクに乗った2頭のアライグマが映っており、アライグマの後ろから隕石が落ち、その隕石が地球に衝突して爆発する様子が映っています。
インタラクティブなビデオ編集
提供された入力ビデオ (左端) については、ユーザーオブジェクトの動きを変更して、さまざまなアクションを実行できます。以下に示すように、真ん中の 3 つはテキスト プロンプトがなく、最後のテキスト プロンプトは「煙の背景で開始」です。
#ビデオ修復
##VideoPoet は、ビデオの不明瞭な部分に詳細を追加できます。テキストガイダンスを通じて修復を選択することもできます。 VideoPoet の機能を実証するために、Google は VideoPoet によって生成された複数の短いクリップで構成されるショート フィルムも作成しました。バードが書いたこの脚本は、旅するアライグマについての短編小説で、シーンごとの詳細と付随するプロンプトリストが含まれています。その後、Google はプロンプトごとにビデオ クリップを生成し、生成されたすべてのクリップをつなぎ合わせて、以下の最終的なビデオを作成しました。
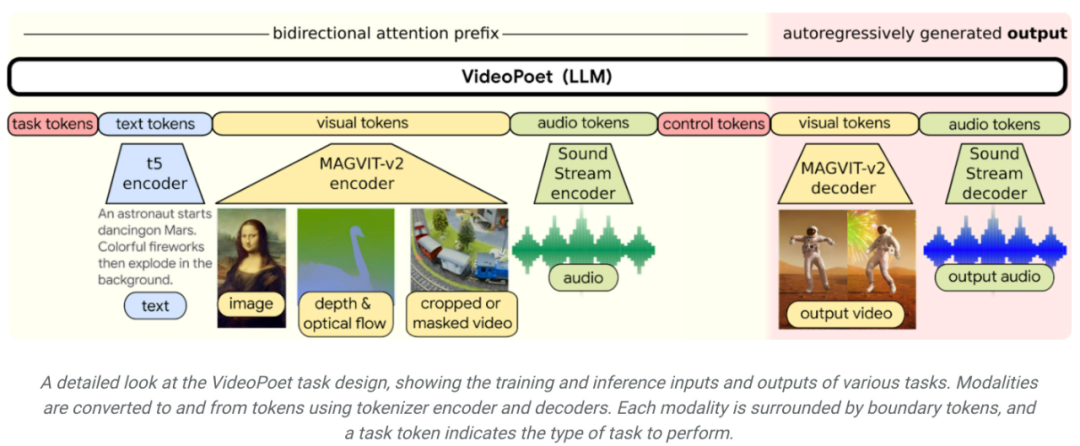
メソッドの紹介下図に示すように、VideoPoet は入力をアニメーション化できます。画像を使用してビデオを生成し、ビデオを編集または拡張できます。
様式化の観点から、モデルは奥行きとオプティカル フローを表すビデオを受け取り、テキスト ガイド スタイルでコンテンツを描画します。 LLM をトレーニングに使用する主な利点は、多くのビデオを再利用できることです。既存の LLM トレーニング インフラストラクチャに導入されたスケーラブルな効率の向上。ただし、LLM は個別のトークンで動作するため、ビデオの生成が困難になります。ビデオおよびオーディオのトークナイザーを使用して、ビデオおよびオーディオ クリップを個別のトークンのシーケンスにエンコードしたり、元の表現に変換して戻すこともできます。 複数のトークナイザー (ビデオと画像には MAGVIT V2、オーディオには SoundStream) を使用することで、VideoPoet は自己回帰言語モデルをトレーニングして、ビデオ、画像、オーディオの複数のモダリティを学習します。文章。モデルが何らかのコンテキストに基づいてトークンを生成すると、トークナイザー デコーダーを使用してトークンを視覚的な表現に変換し直すことができます。
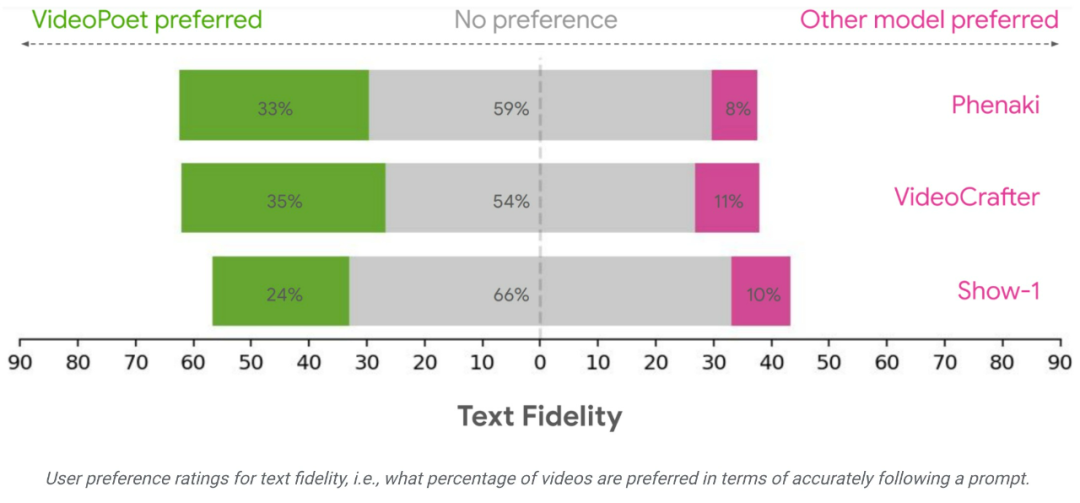
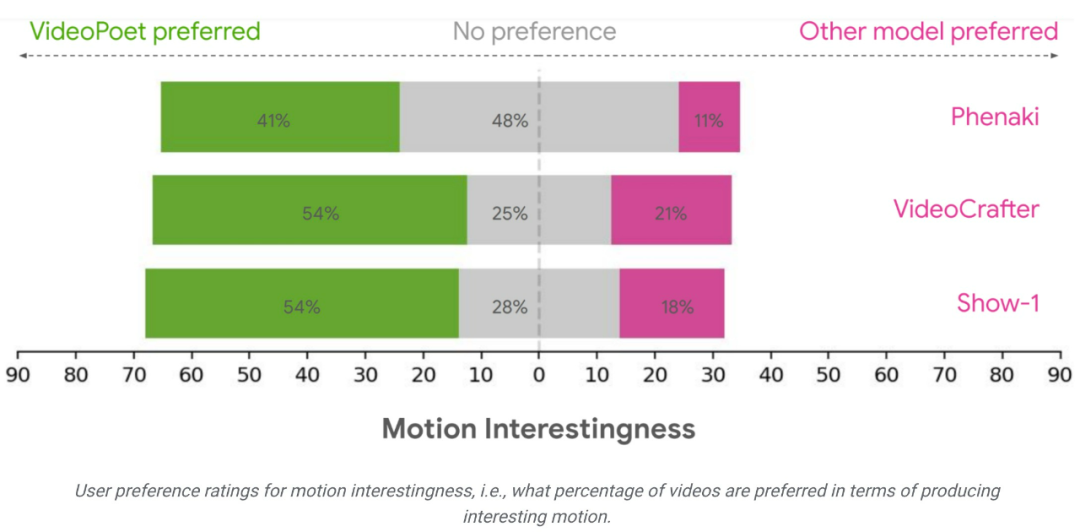
研究チームは、さまざまなベンチマークを使用して、VideoPoet をテキストで評価しました。ビデオ生成のパフォーマンスを他の方法と比較します。中立的な評価を保証するために、この研究では、サンプルを厳選することなく、さまざまなプロンプトの下ですべてのモデルを実行し、人間の評価者に好みの評価を提供するよう依頼しました。
VideoPoet の例の 24 ~ 35% は、次のプロンプトで競合モデルよりも優れていると考えられますが、この比率は競合モデルの場合は 8 ~ 11%。また、評価者は、他のモデルの 11 ~ 21% と比較して、ビデオを生成するアクションがより興味深いため、VideoPoet の例の 41 ~ 54% を好みました。 https://blog.research. google/2023/12/videopoet-large- language-model-for-zero.htmlhttps://sites.research.google/videopoet/stylization /以上がビデオの生成は無限に長くてもよいでしょうか? Google VideoPoet の大型モデルがオンライン、ネチズン: 革新的なテクノロジーの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


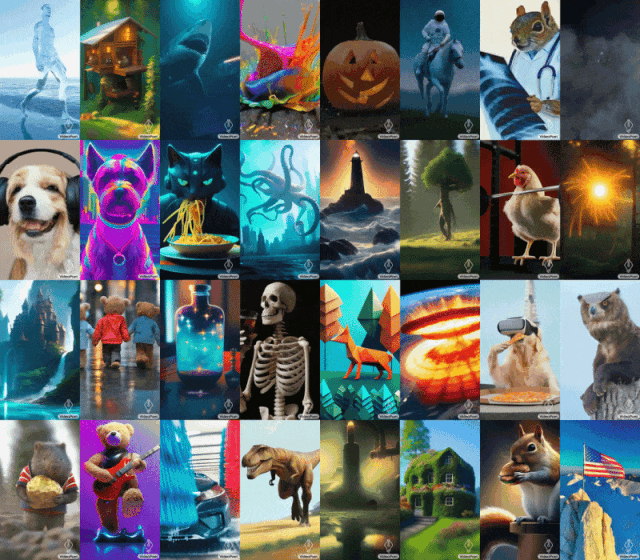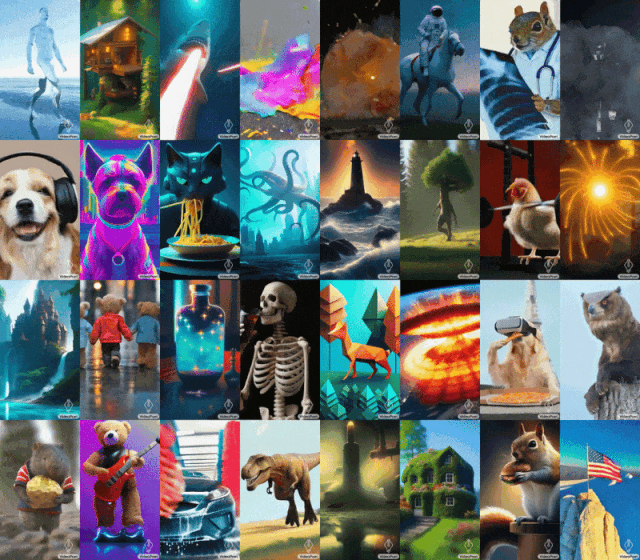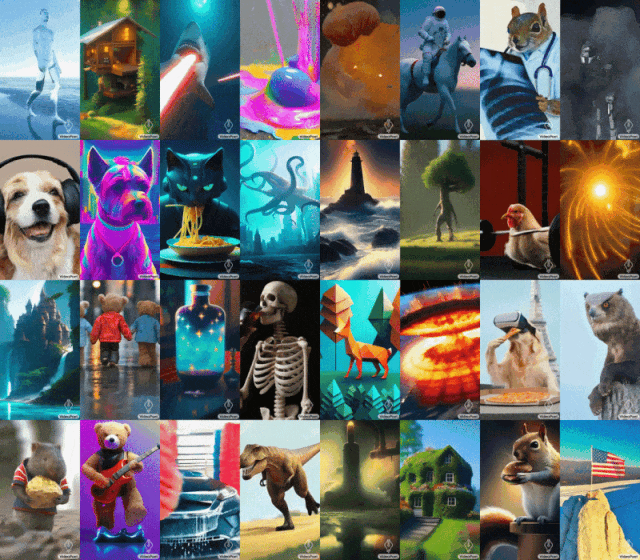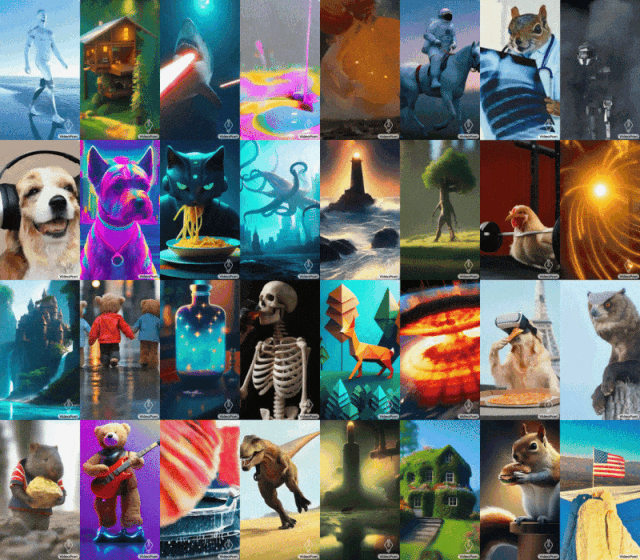






 #長いビデオ
#長いビデオ





















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



