

FAISS ベクトル空間を視覚化し、RAG パラメータを調整して結果の精度を向上させます

オープンソースの大規模言語モデルのパフォーマンスが向上し続けるにつれて、コード、推奨事項、テキストの要約、質問と回答 (QA) のペアの作成と分析のパフォーマンスが大幅に向上しました。しかし、QA に関しては、LLM はトレーニングされていないデータに関連する問題に対応していないことが多く、多くの内部文書はコンプライアンス、企業秘密、またはプライバシーを確保するために社内に保管されています。これらの文書がクエリされると、LLM は幻覚を起こし、無関係なコンテンツ、捏造されたコンテンツ、または矛盾したコンテンツを生成する可能性があります。

#この課題に対処するために考えられる手法の 1 つは、検索拡張生成 (RAG) です。これには、生成の品質と精度を向上させるために、トレーニング データ ソースを超えた信頼できるナレッジ ベースを参照して応答を強化するプロセスが含まれます。 RAG システムは、コーパスから関連する文書フラグメントを取得する検索システムと、取得したフラグメントをコンテキストとして利用して応答を生成する LLM モデルで構成されます。したがって、コーパスの品質とベクトル空間に埋め込まれた表現は、RAG のパフォーマンスにとって非常に重要です。
この記事では、視覚化ライブラリ renumics-spotlight を使用して、FAISS ベクトル空間の多次元埋め込みを 2 次元で視覚化し、特定の主要なベクトル化パラメーターを変更することで改善を模索します。 RAG 応答精度の可能性。私たちが選択した LLM には、Llama 2 と同じアーキテクチャを持つコンパクトなモデルである TinyLlama 1.1B Chat を使用します。精度が比例して低下することなく、リソース フットプリントが小さくなり、実行時間が短縮されるという利点があり、迅速な実験に最適です。
システム設計
QA システムには、図に示すように 2 つのモジュールがあります。
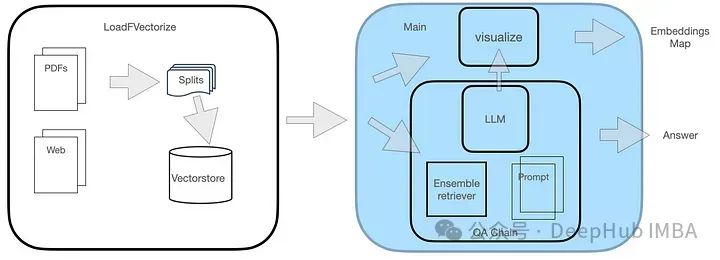
LoadFVectorize モジュールは、PDF または Web ドキュメントをロードし、予備テストと視覚化を実行するために使用されます。別のモジュールは、LLM のロードと FAISS サーチャーのインスタンス化を担当し、LLM、サーチャー、カスタム クエリ プロンプトを含む検索チェーンを構築します。最後に、ベクトル空間を視覚化します。
コードの実装
1. 必要なライブラリをインストールします
renomics-spotlight ライブラリも同様のものを採用していますUmap の視覚化手法は、主要な属性を維持しながら、高次元の埋め込みを管理可能な 2D 視覚化に削減します。以前に umap の使い方を簡単に紹介しましたが、基本的な機能のみでした。今回はシステム設計の一環として実際のプロジェクトに組み込みました。まず、必要なライブラリをインストールする必要があります。
pip install langchain faiss-cpu sentence-transformers flask-sqlalchemy psutil unstructured pdf2image unstructured_inference pillow_heif opencv-python pikepdf pypdf pip install renumics-spotlight CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir
上の最後の行は、Metal サポートを備えた llama-pcp-python ライブラリをインストールすることであり、これは llama-pcp-python ライブラリをロードするために使用されます。 M1 プロセッサーでの Metal サポートにより、ハードウェアでアクセラレートされた TinyLlama。
2. LoadFVectorize モジュール
このモジュールには 3 つの関数が含まれています:
load_doc はオンライン PDF を処理します文書が読み込まれ、各ブロックが 512 文字に分割され、100 文字ずつ重ねられて文書リストが返されます。
vectorize は、上記の関数load_doc を呼び出してドキュメントのブロック リストを取得し、埋め込みを作成してローカル ディレクトリ opdf_index に保存し、FAISS インスタンスを返します。
load_db は、FAISS ライブラリがディスク上のディレクトリ opdf_index にあるかどうかを確認し、ロードを試み、最終的に FAISS オブジェクトを返します。
#このモジュール コードの完全なコードは次のとおりです:
# LoadFVectorize.py from langchain_community.embeddings import HuggingFaceEmbeddings from langchain_community.document_loaders import OnlinePDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.vectorstores import FAISS # access an online pdf def load_doc() -> 'List[Document]':loader = OnlinePDFLoader("https://support.riverbed.com/bin/support/download?did=7q6behe7hotvnpqd9a03h1dji&versinotallow=9.15.0")documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100)docs = text_splitter.split_documents(documents)return docs # vectorize and commit to disk def vectorize(embeddings_model) -> 'FAISS':docs = load_doc()db = FAISS.from_documents(docs, embeddings_model)db.save_local("./opdf_index")return db # attempts to load vectorstore from disk def load_db() -> 'FAISS':embeddings_model = HuggingFaceEmbeddings()try:db = FAISS.load_local("./opdf_index", embeddings_model)except Exception as e:print(f'Exception: {e}\nNo index on disk, creating new...')db = vectorize(embeddings_model)return db3. メイン モジュール
メイン モジュールは、最初に次のテンプレートの TinyLlama プロンプト テンプレートを定義します。
{context}{question}また、TheBloke の TinyLlama の量子化バージョンを使用します。メモリを大幅に削減するために、量子化 LLM を GGUF 形式でロードすることを選択します。
次に、LoadFVectorize モジュールから返された FAISS オブジェクトを使用して FAISS リトリーバーを作成し、RetrievalQA をインスタンス化し、それをクエリに使用します。
# main.py from langchain.chains import RetrievalQA from langchain.prompts import PromptTemplate from langchain_community.llms import LlamaCpp from langchain_community.embeddings import HuggingFaceEmbeddings import LoadFVectorize from renumics import spotlight import pandas as pd import numpy as np # Prompt template qa_template = """ You are a friendly chatbot who always responds in a precise manner. If answer is unknown to you, you will politely say so. Use the following context to answer the question below: {context} {question} """ # Create a prompt instance QA_PROMPT = PromptTemplate.from_template(qa_template) # load LLM llm = LlamaCpp(model_path="./models/tinyllama_gguf/tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf",temperature=0.01,max_tokens=2000,top_p=1,verbose=False,n_ctx=2048 ) # vectorize and create a retriever db = LoadFVectorize.load_db() faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000) # Define a QA chain qa_chain = RetrievalQA.from_chain_type(llm,retriever=faiss_retriever,chain_type_kwargs={"prompt": QA_PROMPT} ) query = 'What versions of TLS supported by Client Accelerator 6.3.0?' result = qa_chain({"query": query}) print(f'--------------\nQ: {query}\nA: {result["result"]}') visualize_distance(db,query,result["result"])ベクトル空間の視覚化自体は、上記のコードの Visualize_ distance の最後の行で処理されます:
visualize_ distance access FAISS オブジェクトの属性 __dict__、index_to_docstore_id 自体は値 docstore-ids のキー インデックス ディクショナリであり、ベクトル化に使用されるドキュメントの総数はインデックス オブジェクトの属性 ntotal で表されます。 #
vs = db.__dict__.get("docstore")index_list = db.__dict__.get("index_to_docstore_id").values()doc_cnt = db.index.ntotal#
embeddings_vec = db.index.reconstruct_n()
doc_list = list() for i,doc-id in enumerate(index_list):a_doc = vs.search(doc-id)doc_list.append([doc-id,a_doc.metadata.get("source"),a_doc.page_content,embeddings_vec[i]])df = pd.DataFrame(doc_list,columns=['id','metadata','document','embedding'])
在继续进行可视化之前,还需要将问题和答案结合起来,我们创建一个单独的问题以及答案的DF,然后与上面的df进行合并,这样能够显示问题和答案出现的地方,在可视化时我们可以高亮显示:
# add rows for question and answerembeddings_model = HuggingFaceEmbeddings()question_df = pd.DataFrame({"id": "question","question": question,"embedding": [embeddings_model.embed_query(question)],})answer_df = pd.DataFrame({"id": "answer","answer": answer,"embedding": [embeddings_model.embed_query(answer)],})df = pd.concat([question_df, answer_df, df])这里使用使用np.linalg.norm在文件和问题嵌入上的进行距离大小的计算:
question_embedding = embeddings_model.embed_query(question)# add column for vector distancedf["dist"] = df.apply( lambda row: np.linalg.norm(np.array(row["embedding"]) - question_embedding),axis=1,)
因为spotlight可以对df进行可视化,所有我们直接调用即可
spotlight.show(df)
このステップでは、ブラウザ ウィンドウで Spotlight が起動します。
テストを実行します
1. 基本テスト
以下はサンプル質問です。選択済み:
Client Accelerator 6.3.0 でサポートされている TLS のバージョンは何ですか?
正解は:
Client Accelerator 6.3.0 は TLS 1.1 または 1.2 をサポートします。
次の追加情報が応答に含まれる場合があります。 。
クライアント アクセラレータで次の CLI コマンドを使用して、この機能を有効にする必要があります:(config) #policy id
ssl backend client-tls-1.2Evenこのコマンドの構文では TLS 1.1 については言及されていませんが、このコマンドを使用すると、TLS 1.1 と 1.2 の両方のサポートが自動的に有効になります。
次に、次に対する TinyLlama の応答を見てみましょう。上記の問題 回答:
Client Accelerator 6.3.0 は、Client Accelerator でサポートされるデフォルトの TLS バージョンとして TLS 1.1 または 1.2 をサポートします。次の CLI コマンドを使用してこの機能を有効にする必要があります。クライアント アクセラレータ:```(config) # ポリシー ID
ssl backend client -tlss1.2```このコマンドは TLS 1.1 または TLS 1.2 にのみ適用されることに注意してください。古いバージョンをサポートする必要がある場合は、 TLS バージョンでは、代わりに client-tlss1.0 または client-tlss1.1 オプション を指定して ssl バックエンド コマンドを使用できます。
は実際の答えと非常に似ています。 、ただし、これらの TLS バージョンはデフォルトではないため、完全に正しいわけではありません。
それでは、彼が答えを見つけた文章を見てみましょう。
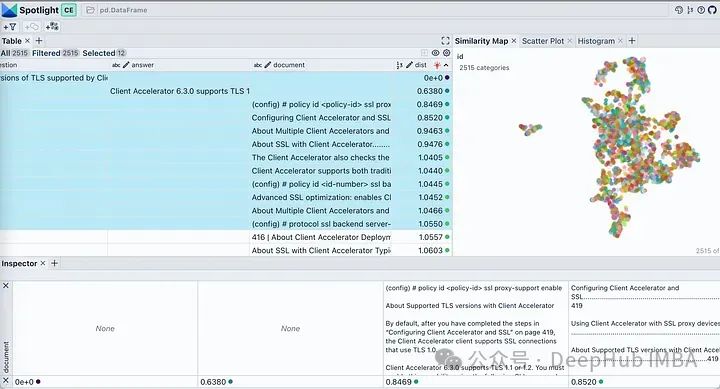
#スポットライトに表示されているボタンを使用して、表示される列を制御します。テーブルを「dist」で並べ替えて、質問、回答、および最も関連性の高いドキュメントのスニペットを上部に表示します。ドキュメントの埋め込みを見ると、ドキュメントのほぼすべてのチャンクが単一のクラスターとして記述されています。これは合理的です。なぜなら、当社のオリジナルの PDF は特定の製品の導入ガイドであるため、クラスターとみなされても問題ありません。
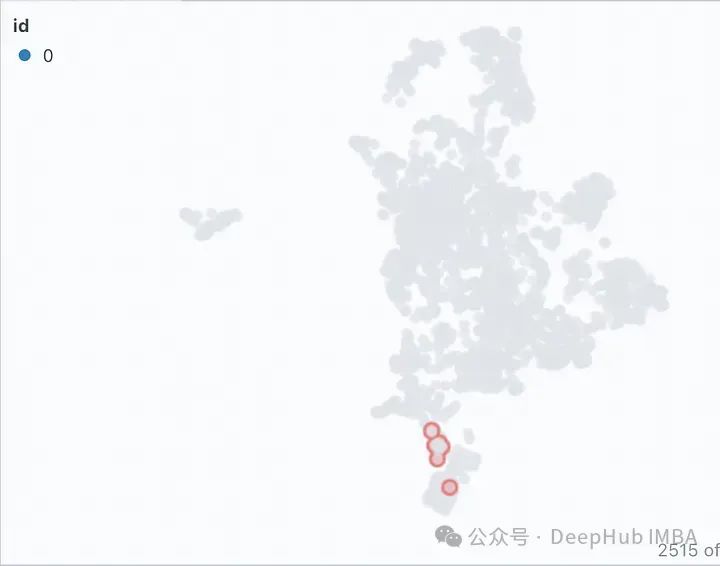
[類似性マップ] タブのフィルター アイコンをクリックすると、密にクラスター化された選択したドキュメント リストのみが強調表示され、以下に示すように残りはグレー表示になります。
2. ブロック サイズとオーバーラップ パラメーターのテスト
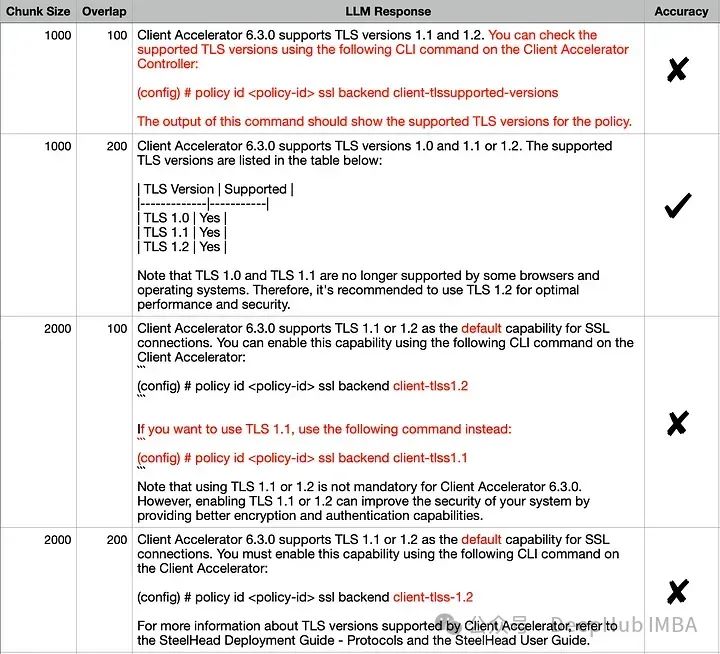
取得者は RAG に影響を与える鍵であるため、パフォーマンス要因、埋め込み空間に影響を与えるいくつかのパラメーターを見てみましょう。 TextSplitter のチャンク サイズ (1000、2000) および/またはオーバーラップ (100、200) パラメーターは、ドキュメントの分割中に異なります。
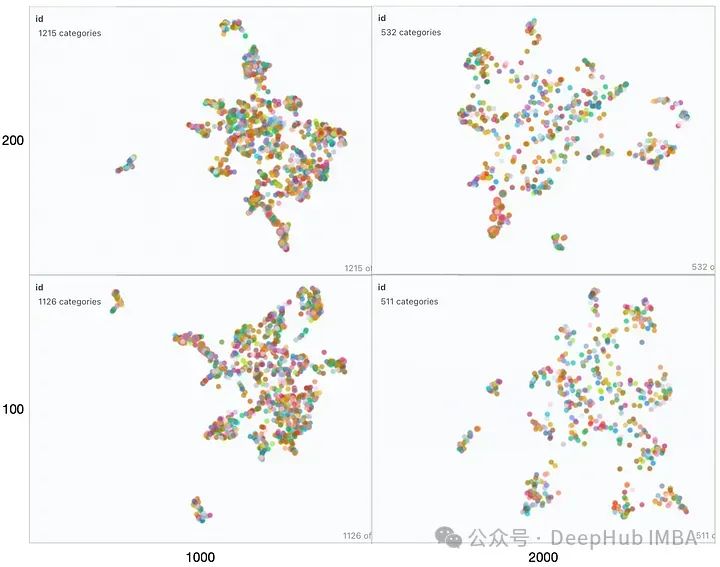
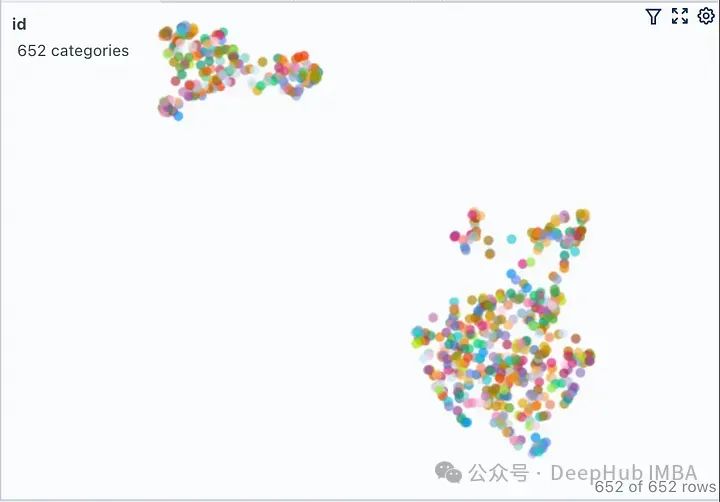
如果查询位于簇中心等位置时由于最近邻可能不同,在这些参数发生变化时响应很可能会发生显著变化。如果RAG应用程序无法提供预期答案给某些问题,则可以通过生成类似上述可视化图表并结合这些问题进行分析,可能找到最佳划分语料库以提高整体性能方面优化方法。 为了进一步说明,我们将两个来自不相关领域(Grammy Awards和JWST telescope)的维基百科文档的向量空间进行可视化展示。 只修改了上面代码其余的代码保持不变。运行修改后的代码,我们得到下图所示的向量空间可视化。 这里有两个不同的不重叠的簇。如果我们要在任何一个簇之外提出一个问题,那么从检索器获得上下文不仅不会对LLM有帮助,而且还很可能是有害的。提出之前提出的同样的问题,看看我们LLM产生什么样的“幻觉” Client Accelerator 6.3.0 supports the following versions of Transport Layer Security (TLS): 这里我们使用FAISS用于向量存储。如果你正在使用ChromaDB并想知道如何执行类似的可视化,renumics-spotlight也是支持的。 检索增强生成(RAG)允许我们利用大型语言模型的能力,即使LLM没有对内部文档进行训练也能得到很好的结果。RAG涉及从矢量库中检索许多相关文档块,然后LLM将其用作生成的上下文。因此嵌入的质量将在RAG性能中发挥重要作用。 在本文中,我们演示并可视化了几个关键矢量化参数对LLM整体性能的影响。并使用renumics-spotlight,展示了如何表示整个FAISS向量空间,然后将嵌入可视化。Spotlight直观的用户界面可以帮助我们根据问题探索向量空间,从而更好地理解LLM的反应。通过调整某些矢量化参数,我们能够影响其生成行为以提高精度。def load_doc():loader = WebBaseLoader(['https://en.wikipedia.org/wiki/66th_Annual_Grammy_Awards','https://en.wikipedia.org/wiki/James_Webb_Space_Telescope'])documents = loader.load()...
总结
以上がFAISS ベクトル空間を視覚化し、RAG パラメータを調整して結果の精度を向上させますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99

 Chrome ブラウザがクラッシュするのはなぜですか? Google Chromeを開くときにクラッシュする問題を解決するにはどうすればよいですか?
Mar 13, 2024 pm 07:28 PM
Chrome ブラウザがクラッシュするのはなぜですか? Google Chromeを開くときにクラッシュする問題を解決するにはどうすればよいですか?
Mar 13, 2024 pm 07:28 PM
Google Chromeは高いセキュリティと強力な安定性を備えており、大多数のユーザーに愛用されています。ただし、一部のユーザーは、Google Chrome を開くとすぐにクラッシュしてしまいます。何が起こっているのでしょうか?開いているタブが多すぎるか、ブラウザのバージョンが古すぎる可能性がありますので、以下で具体的な解決策を見てみましょう。 Google Chromeのクラッシュ問題を解決するにはどうすればよいですか? 1. 不要なタブをいくつか閉じる 開いているタブが多すぎる場合は、不要なタブをいくつか閉じてみると、Google Chrome のリソース負荷が効果的に軽減され、クラッシュの可能性が減ります。 2. Google Chrome をアップデートする Google Chrome のバージョンが古すぎると、クラッシュなどのエラーが発生する可能性もありますので、最新バージョンにアップデートすることをお勧めします。右上の[カスタマイズと制御]-[設定]をクリックします。
 Ollama 上の Windows: 大規模言語モデル (LLM) をローカルで実行するための新しいツール
Feb 28, 2024 pm 02:43 PM
Ollama 上の Windows: 大規模言語モデル (LLM) をローカルで実行するための新しいツール
Feb 28, 2024 pm 02:43 PM
最近、OpenAITranslator と NextChat の両方が、Ollama でローカルに実行される大規模な言語モデルをサポートし始めました。これは、「初心者」愛好家に新しい遊び方を提供します。さらに、Windows での Ollama (プレビュー バージョン) のリリースは、Windows デバイスでの AI 開発のやり方を完全に覆し、AI 分野の探索者と一般の「水のテストを行うプレイヤー」に明確な道を導きました。オラマとは何ですか? Ollama は、AI モデルの開発と使用を大幅に簡素化する画期的な人工知能 (AI) および機械学習 (ML) ツール プラットフォームです。技術コミュニティにおいて、AIモデルのハードウェア構成と環境構築は常に悩ましい問題でした。
 pycharmクラッシュを解決する方法
Apr 25, 2024 am 05:09 AM
pycharmクラッシュを解決する方法
Apr 25, 2024 am 05:09 AM
PyCharm クラッシュの解決策としては、PyCharm のメモリ使用量を確認し、PyCharm を最新バージョンに更新するか、PyCharm 設定を無効にするか、サポート スタッフに問い合わせてください。助けのために。
 大規模な言語モデルがアクティベーション関数として SwiGLU を使用するのはなぜですか?
Apr 08, 2024 pm 09:31 PM
大規模な言語モデルがアクティベーション関数として SwiGLU を使用するのはなぜですか?
Apr 08, 2024 pm 09:31 PM
大規模な言語モデルのアーキテクチャに注目している場合は、最新のモデルや研究論文で「SwiGLU」という用語を見たことがあるかもしれません。 SwiGLUは大規模言語モデルで最もよく使われるアクティベーション関数と言えますので、この記事で詳しく紹介します。実はSwiGLUとは、2020年にGoogleが提案したSWISHとGLUの特徴を組み合わせたアクティベーション関数です。 SwiGLU の正式な中国語名は「双方向ゲート線形ユニット」で、SWISH と GLU の 2 つの活性化関数を最適化して組み合わせ、モデルの非線形表現能力を向上させます。 SWISH は大規模な言語モデルで広く使用されている非常に一般的なアクティベーション関数ですが、GLU は自然言語処理タスクで優れたパフォーマンスを示しています。
 Groq Llama 3 70B をローカルで使用するためのステップバイステップ ガイド
Jun 10, 2024 am 09:16 AM
Groq Llama 3 70B をローカルで使用するためのステップバイステップ ガイド
Jun 10, 2024 am 09:16 AM
翻訳者 | Bugatti レビュー | Chonglou この記事では、GroqLPU 推論エンジンを使用して JanAI と VSCode で超高速応答を生成する方法について説明します。 Groq は AI のインフラストラクチャ側に焦点を当てているなど、誰もがより優れた大規模言語モデル (LLM) の構築に取り組んでいます。これらの大型モデルがより迅速に応答するためには、これらの大型モデルからの迅速な応答が鍵となります。このチュートリアルでは、GroqLPU 解析エンジンと、API と JanAI を使用してラップトップ上でローカルにアクセスする方法を紹介します。この記事では、これを VSCode に統合して、コードの生成、コードのリファクタリング、ドキュメントの入力、テスト ユニットの生成を支援します。この記事では、独自の人工知能プログラミングアシスタントを無料で作成します。 GroqLPU 推論エンジン Groq の概要
 よりスムーズなおすすめの Android エミュレータ (使用したい Android エミュレータを選択してください)
Apr 21, 2024 pm 06:01 PM
よりスムーズなおすすめの Android エミュレータ (使用したい Android エミュレータを選択してください)
Apr 21, 2024 pm 06:01 PM
ユーザーにより良いゲーム体験と使用体験を提供できます Android エミュレータは、コンピュータ上で Android システムの実行をシミュレートできるソフトウェアです。市場にはさまざまな種類の Android エミュレータがあり、その品質も異なります。読者が自分に合ったエミュレータを選択できるように、この記事ではいくつかのスムーズで使いやすい Android エミュレータに焦点を当てます。 1. BlueStacks: 高速な実行速度 優れた実行速度とスムーズなユーザー エクスペリエンスを備えた BlueStacks は、人気のある Android エミュレーターです。ユーザーがさまざまなモバイル ゲームやアプリケーションをプレイできるようにし、非常に高いパフォーマンスでコンピュータ上で Android システムをシミュレートできます。 2. NoxPlayer: 複数のオープニングをサポートし、ゲームをより楽しくプレイできます。複数のエミュレーターで同時に異なるゲームを実行できます。
 WPS フォームの応答が遅い場合はどうすればよいですか? WPS フォームがスタックして応答が遅いのはなぜですか?
Mar 14, 2024 pm 02:43 PM
WPS フォームの応答が遅い場合はどうすればよいですか? WPS フォームがスタックして応答が遅いのはなぜですか?
Mar 14, 2024 pm 02:43 PM
WPS フォームの応答が非常に遅い場合はどうすればよいですか?ユーザーは、他のプログラムを終了したり、ソフトウェアを更新して操作を実行したりすることができますが、このサイトでは、WPS フォームの応答が遅い理由をユーザーに丁寧に紹介します。 WPS テーブルの応答が遅いのはなぜですか? 1. 他のプログラムを閉じる: 実行中の他のプログラム、特に多くのシステム リソースを消費するプログラムを閉じます。これにより、WPS Office により多くのコンピューティング リソースが提供され、ラグや遅延が軽減されます。 2. WPSOffice を更新します。最新バージョンの WPSOffice を使用していることを確認します。 WPSOffice の公式 Web サイトから最新バージョンをダウンロードしてインストールすると、いくつかの既知のパフォーマンスの問題を解決できる場合があります。 3. ファイルサイズを小さくする
 GPU ハードウェア アクセラレーションを有効にする必要がありますか?
Feb 26, 2024 pm 08:45 PM
GPU ハードウェア アクセラレーションを有効にする必要がありますか?
Feb 26, 2024 pm 08:45 PM
ハードウェア アクセラレーション GPU を有効にする必要がありますか?テクノロジーの継続的な開発と進歩に伴い、コンピューター グラフィックス処理の中核コンポーネントとして GPU (グラフィックス プロセッシング ユニット) が重要な役割を果たしています。ただし、ハードウェア アクセラレーションをオンにする必要があるかどうかについて疑問を抱くユーザーもいるかもしれません。この記事では、GPU のハードウェア アクセラレーションの必要性と、ハードウェア アクセラレーションをオンにした場合のコンピューターのパフォーマンスとユーザー エクスペリエンスへの影響について説明します。まず、ハードウェア アクセラレーションによる GPU がどのように動作するかを理解する必要があります。 GPUは特化型
