

VPR 2024 満点用紙! Meta は EfficientSAM を提案しています。すべてを素早く分割します。

EfficientSAM この作品は 5/5/5 の満点を獲得して CVPR 2024 に掲載されました。以下の図に示すように、著者はソーシャル メディアで結果を共有しました。
LeCun Turing Award 受賞者もこの作品を強く推奨しました。

最近の研究で、メタ研究者は、SAM マスキングを使用する新しい改良された方法を提案しました。 (サミ)。このアプローチでは、MAE 事前トレーニング技術と SAM モデルを組み合わせて、高品質の事前トレーニングされた ViT エンコーダーを実現します。 SAMI を通じて、研究者はモデルのパフォーマンスと効率を向上させ、視覚タスクにより良いソリューションを提供しようとしています。この手法の提案は、コンピューター ビジョンとディープ ラーニングの分野をさらに探索し、発展させるための新しいアイデアと機会をもたらします。さまざまな事前トレーニング手法とモデル構造を組み合わせることで、研究者は

- #論文リンク: https://arxiv.org/pdf/2312.00863
- ##コード: github.com/yformer/EfficientSAM
- ホームページ: https://yformer.github.io/efficient-sam/
このアプローチの有効性を検証するために、研究者らはマスクされた画像で事前トレーニングされた転移学習設定を使用しました。具体的には、彼らはまず、画像解像度 224×224 の ImageNet データセット上で再構成損失を含むモデルを事前トレーニングしました。次に、ターゲット タスクからの教師付きデータを使用してモデルを微調整します。この転移学習手法は、モデルが事前トレーニング段階を通じて元のデータから特徴を抽出することを学習しているため、モデルが迅速に学習し、新しいタスクのパフォーマンスを向上させるのに役立ちます。この転移学習戦略は、大規模なデータセットで学習した知識を効果的に利用し、モデルをさまざまなタスクに適応させることを容易にします。 、ViT-Tiny/-Small/-Base などの ImageNet-Train モデルで 1K で使用でき、汎化パフォーマンスが向上します。 ViT-Small モデルの場合、ImageNet-1K で 100 回の微調整を行った後、研究者らは 82.7% のトップ 1 精度を達成しました。これは、他の最先端の画像事前トレーニング ベースラインよりも優れています。
研究者らは、ターゲットの検出、インスタンスのセグメンテーション、セマンティック セグメンテーションに関して事前トレーニングされたモデルを微調整しました。これらすべてのタスクにおいて、私たちの方法は他の事前トレーニングされたベースラインよりも優れた結果を達成し、さらに重要なことに、小さなモデルで大幅な向上を達成します。
この論文の著者である Yunyang Xiong 氏は、「この記事で提案されている EfficientSAM パラメータは 20 分の 1 に削減されていますが、実行時間は 20 倍高速です。オリジナルとの違い」と述べています。 SAM モデルはわずか 2 パーセント ポイント以内であり、MobileSAM/FastSAM よりも大幅に優れています。
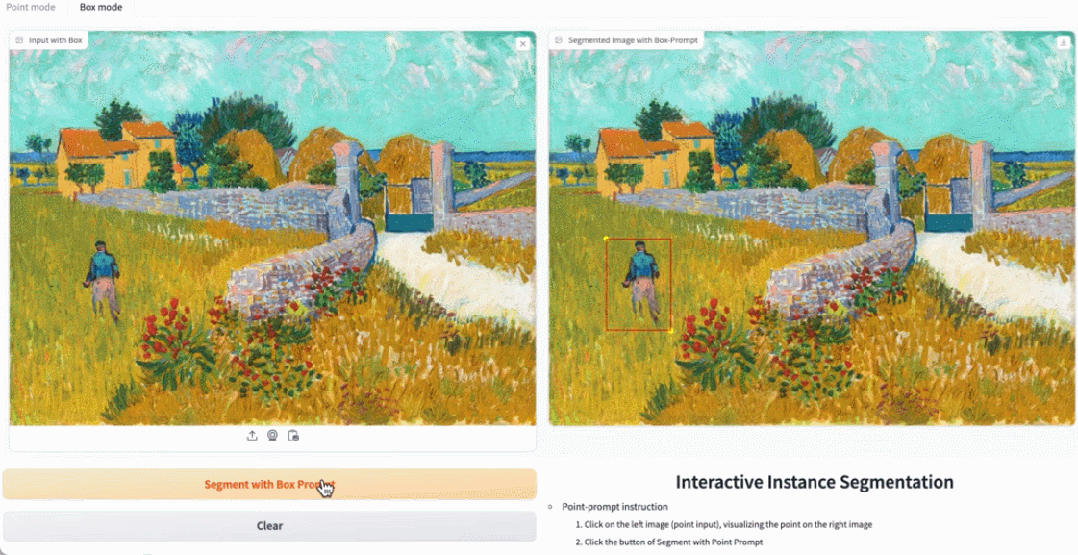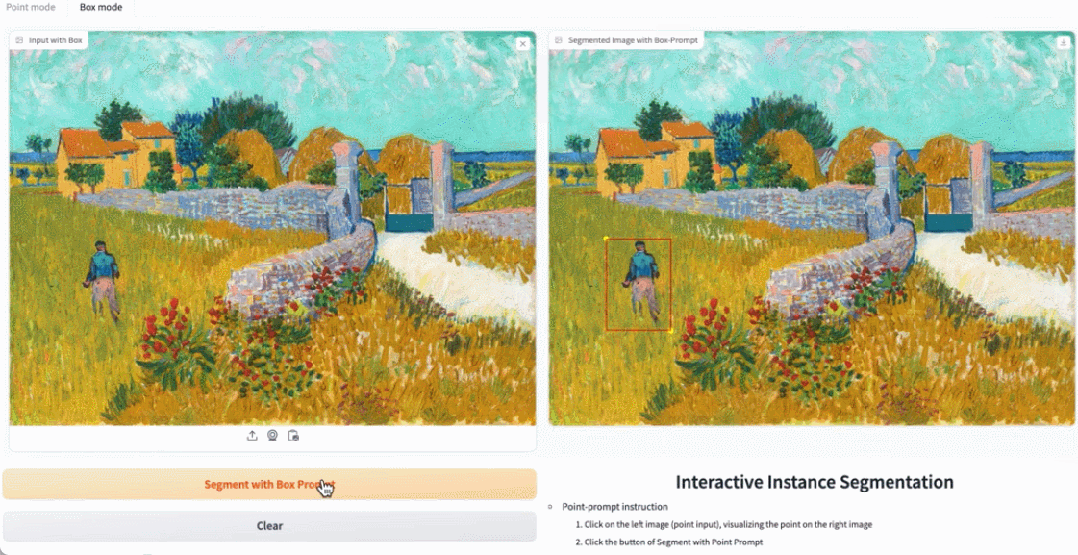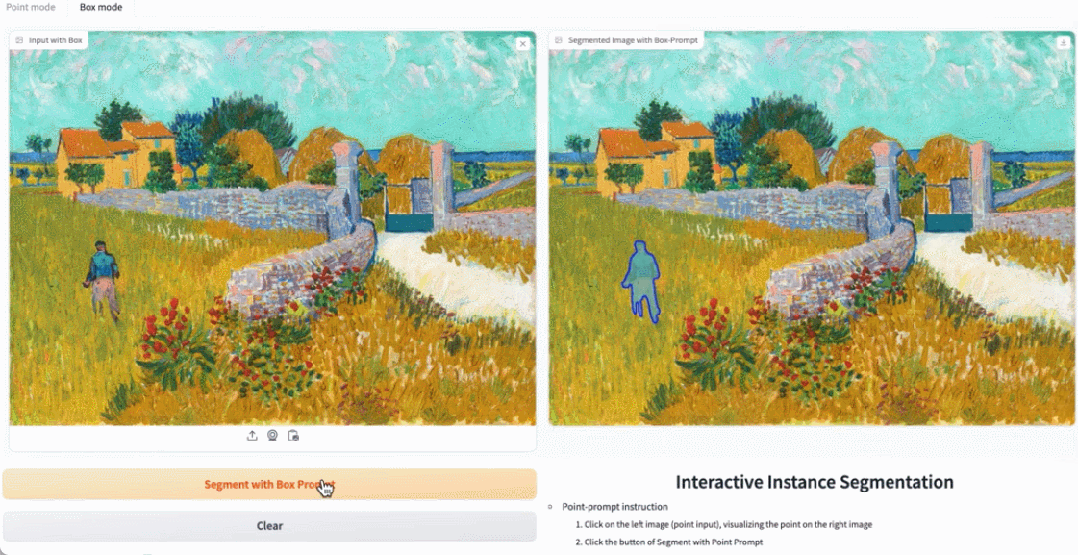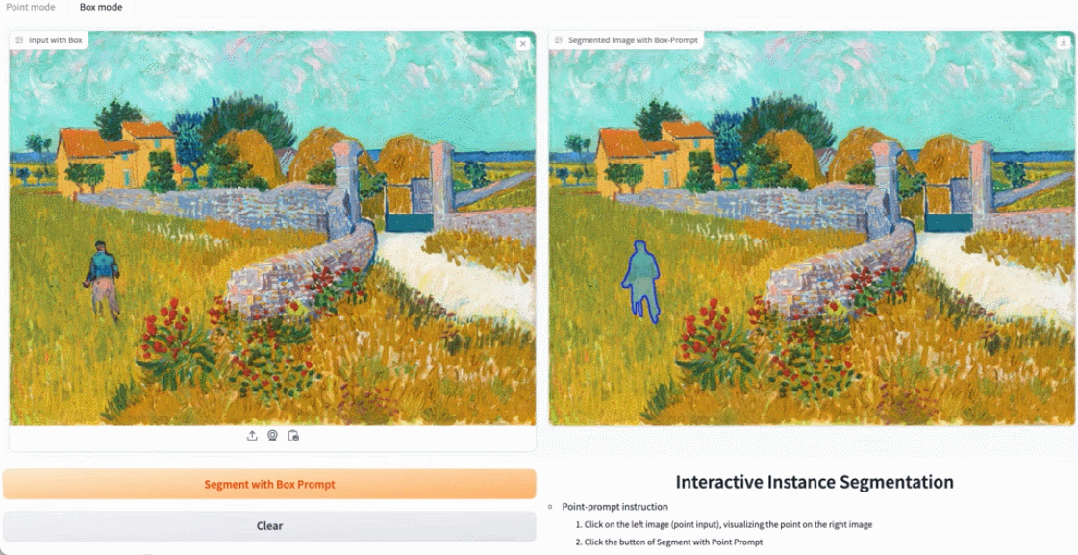
#デモ デモンストレーションでは、写真内の動物をクリックすると、EfficientSAM がオブジェクトをすばやくセグメント化できます。

EfficientSAM は、写真内の人物を正確に識別することもできます:

トライアル アドレス: https: //ab348ea7942fe2af48.gradio.live/
 メソッド
メソッド
EfficientSAM には 2 つのステージが含まれています。1) ImageNet での SAMI の事前トレーニング (上)。 2) SA-1B で SAM を微調整します (下)。
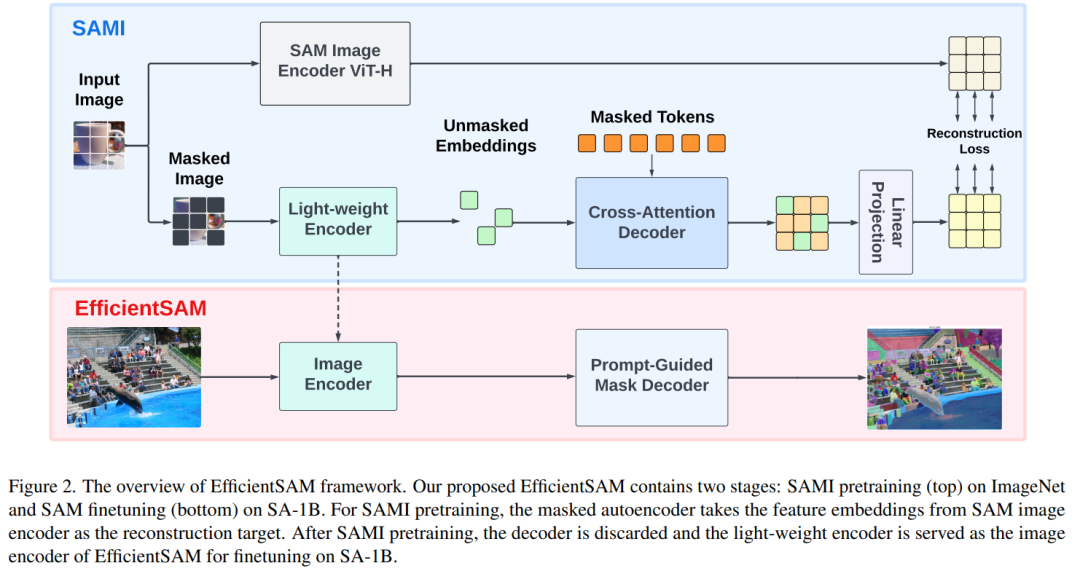
EfficientSAM には主に次のコンポーネントが含まれています:
クロスアテンション デコーダ: SAM 機能の監視の下で、この文書では次のことが観察されます。マスク トークンのみがデコーダによって再構築される必要があり、エンコーダの出力は再構築プロセス中にアンカーとして機能します。クロスアテンション デコーダーでは、クエリはマスクされたトークンから取得され、キーと値はエンコーダーからのマスクされていない特徴とマスクされた特徴から導出されます。この論文では、クロスアテンション デコーダーのマスクされたトークンからの出力特徴と、MAE 出力埋め込み用のエンコーダーからのマスクされていないトークンの出力特徴をマージします。これらの結合された特徴は、最終的な MAE 出力内の入力画像トークンの元の位置に並べ替えられます。
リニアプロジェクションヘッド。次に、エンコーダとクロスアテンション デコーダを通じて取得した画像出力を小さなプロジェクト ヘッドに入力し、SAM 画像エンコーダの機能を調整しました。簡単にするために、このペーパーでは、SAM 画像エンコーダーと MAE 出力の間の特徴寸法の不一致を解決するために線形投影ヘッドのみを使用します。
復興損失。各トレーニング反復では、SAMI には、SAM 画像エンコーダーからの前方特徴抽出と、MAE の順方向および逆方向伝播プロセスが含まれます。 SAM 画像エンコーダと MAE 線形投影ヘッドからの出力を比較して、再構成損失を計算します。
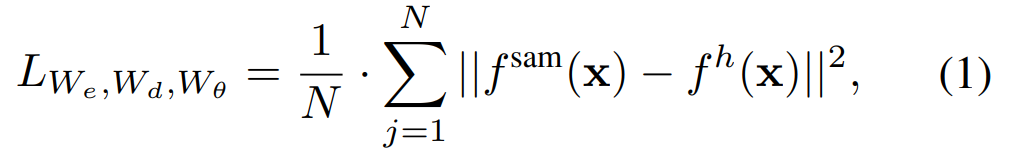
事前トレーニング後、エンコーダーはさまざまな視覚的タスクの特徴表現を抽出でき、デコーダーも破棄されます。特に、任意のセグメンテーション タスク用の効率的な SAM モデルを構築するために、この論文では、EfficientSAM の画像エンコーダおよび SAM のデフォルト マスク デコーダとして、SAMI の事前トレーニング済み軽量エンコーダ (ViT-Tiny や ViT-Small など) を採用します。 、図 2 (下) に示すように。この論文では、SA-1B データセット上の EfficientSAM モデルを微調整して、あらゆるタスクのセグメンテーションを実現します。
実験
画像分類。画像分類タスクにおけるこの方法の有効性を評価するために、研究者らは SAMI のアイデアを ViT モデルに適用し、ImageNet-1K でのパフォーマンスを比較しました。
#表 1 に示すように、SAMI は、MAE、iBOT、CAE、BEiT などの事前トレーニング手法、および DeiT や SSTA などの蒸留手法と比較されています。
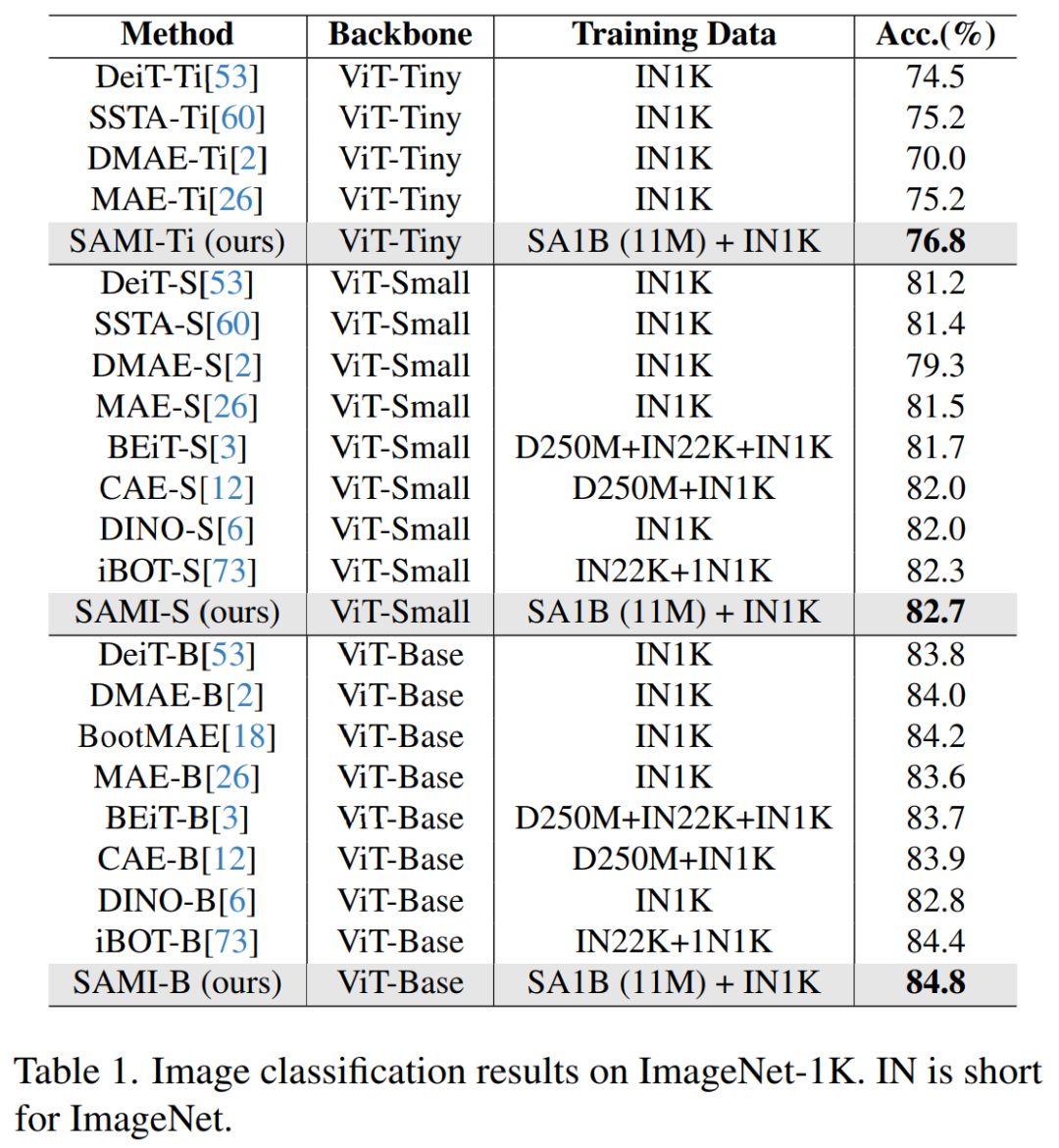
SAMI-B のトップ 1 精度は 84.8% に達し、事前トレーニングされたベースライン、MAE、DMAE、iBOT、CAE、BEiT よりも高くなっています。 SAMI は、DeiT や SSTA などの蒸留法と比較して大きな改善も示しています。 ViT-Tiny や ViT-Small などの軽量モデルの場合、SAMI の結果は、DeiT、SSTA、DMAE、MAE と比較して大幅な向上を示しています。
オブジェクトの検出とインスタンスのセグメンテーション。この論文では、SAMI で事前トレーニングされた ViT バックボーンをダウンストリームのオブジェクト検出タスクとインスタンス セグメンテーション タスクまで拡張し、それを COCO データセットで事前トレーニングされたベースラインと比較します。表 2 に示すように、SAMI は他のベースラインのパフォーマンスを常に上回っています。
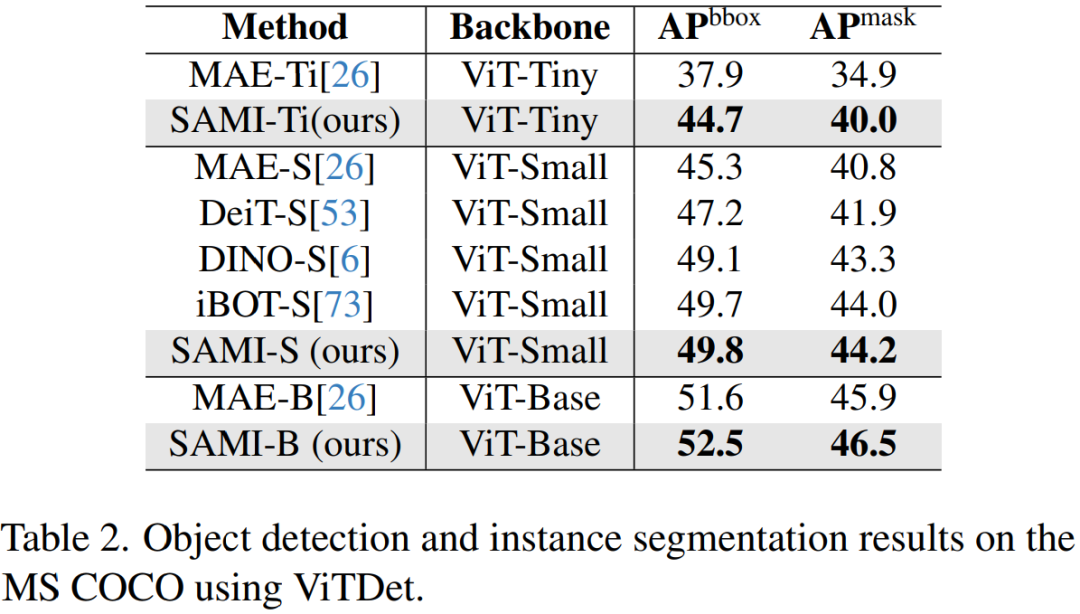
セマンティック セグメンテーション。このペーパーでは、事前トレーニングされたバックボーンをさらにセマンティック セグメンテーション タスクに拡張して、その有効性を評価します。結果を表 3 に示します。SAMI の事前トレーニングされたバックボーンを使用した Mask2former は、MAE の事前トレーニングされたバックボーンを使用した場合よりも、ImageNet-1K 上でより優れた mIoU を達成します。これらの実験結果は、この論文で提案された技術がさまざまな下流タスクにうまく一般化できることを証明しています。
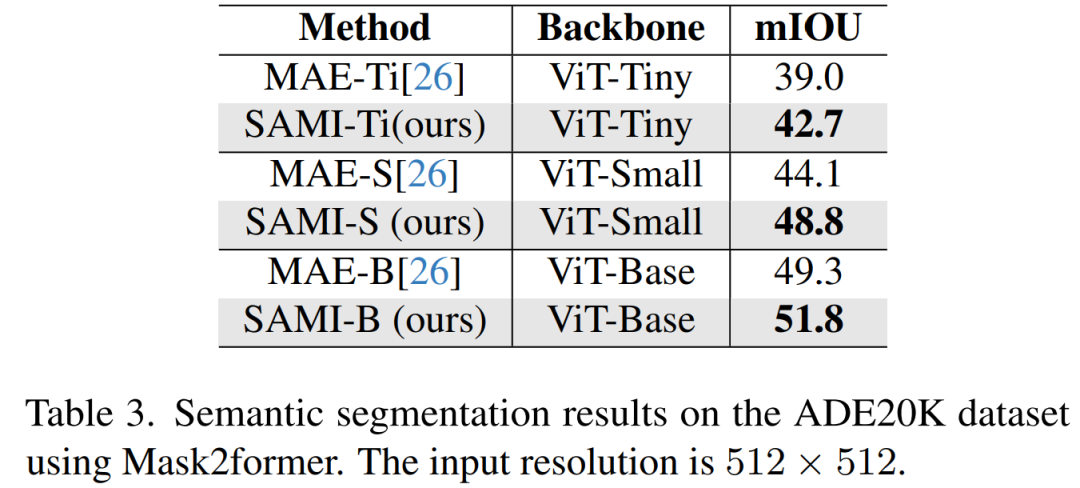 #表 4 では、EfficientSAM と SAM、MobileSAM、および SAM-MAE-Ti を比較しています。 COCO では、EfficientSAM-Ti が MobileSAM を上回ります。 EfficientSAM-Ti には SAMI で事前トレーニングされた重みがあり、MAE で事前トレーニングされた重みよりも優れたパフォーマンスを発揮します。
#表 4 では、EfficientSAM と SAM、MobileSAM、および SAM-MAE-Ti を比較しています。 COCO では、EfficientSAM-Ti が MobileSAM を上回ります。 EfficientSAM-Ti には SAMI で事前トレーニングされた重みがあり、MAE で事前トレーニングされた重みよりも優れたパフォーマンスを発揮します。
さらに、EfficientSAM-S は、COCO ボックスの SAM よりも 1.5 mIoU 低いだけで、LVIS ボックスの SAM より 3.5 mIoU 低く、パラメーターが 20 分の 1 です。この論文では、EfficientSAM が MobileSAM や SAM-MAE-Ti と比較して、複数のクリックでも優れたパフォーマンスを示していることもわかりました。
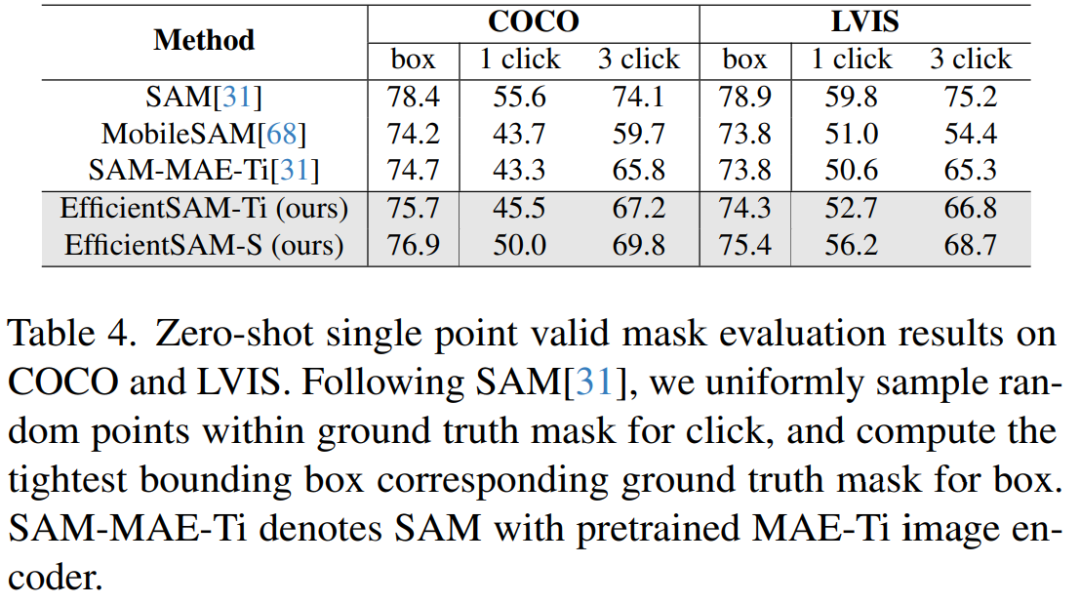
#表 5 に、ゼロショット インスタンス セグメンテーションの AP、APS、APM、および APL を示します。研究者らは EfficientSAM を MobileSAM および FastSAM と比較しました。その結果、FastSAM と比較して、EfficientSAM-S は COCO で 6.5 を超える AP、LVIS で 7.8 AP を超える AP を獲得したことがわかります。 EffidientSAM-Ti の場合、FastSAM よりも大幅に優れており、COCO では 4.1 AP、LVIS では 5.3 AP ですが、MobileSAM では COCO では 3.6 AP、LVIS では 5.5 AP です。
さらに、EfficientSAM は FastSAM よりもはるかに軽量であり、efficientSAM-Ti のパラメータは 9.8M であるのに対し、FastSAM のパラメータは 68M です。
図 3、4、および 5 は、読者が EfficientSAM のインスタンス セグメンテーション機能を補足的に理解できるように、定性的な結果をいくつか示しています。


 ##研究の詳細については、元の論文を参照してください。
##研究の詳細については、元の論文を参照してください。
以上がVPR 2024 満点用紙! Meta は EfficientSAM を提案しています。すべてを素早く分割します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1657
1657
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 エンコーダ/デコーダ アーキテクチャを放棄し、より効果的なエッジ検出に拡散モデルを使用する 国立防衛工科大学は DiffusionEdge を提案しました
Feb 07, 2024 pm 10:12 PM
エンコーダ/デコーダ アーキテクチャを放棄し、より効果的なエッジ検出に拡散モデルを使用する 国立防衛工科大学は DiffusionEdge を提案しました
Feb 07, 2024 pm 10:12 PM
現在のディープ エッジ検出ネットワークは通常、エンコーダ/デコーダ アーキテクチャを採用しています。このアーキテクチャには、マルチレベルの特徴をより適切に抽出するためのアップ サンプリング モジュールとダウン サンプリング モジュールが含まれています。ただし、この構造では、ネットワークが正確かつ詳細なエッジ検出結果を出力することが制限されます。この問題に対して、AAAI2024 に関する論文は新しい解決策を提供しています。論文のタイトル: DiffusionEdge:DiffusionProbabilisticModelforCrispEdgeDetection 著者: Ye Yunfan (国立国防技術大学)、Xu Kai (国立国防技術大学)、Huang Yuxing (国立国防技術大学)、Yi Renjiao (国立国防技術大学)、Cai Zhiping (防衛工科大学) 論文リンク:https://ar
 Tongyi Qianwen が再びオープンソースになり、Qwen1.5 では 6 つのボリューム モデルが提供され、そのパフォーマンスは GPT3.5 を超えます
Feb 07, 2024 pm 10:15 PM
Tongyi Qianwen が再びオープンソースになり、Qwen1.5 では 6 つのボリューム モデルが提供され、そのパフォーマンスは GPT3.5 を超えます
Feb 07, 2024 pm 10:15 PM
春節に合わせて、Tongyi Qianwen Model (Qwen) のバージョン 1.5 がオンラインになりました。今朝、新しいバージョンのニュースが AI コミュニティの注目を集めました。大型モデルの新バージョンには、0.5B、1.8B、4B、7B、14B、72Bの6つのモデルサイズが含まれています。その中でも最強バージョンの性能はGPT3.5やMistral-Mediumを上回ります。このバージョンには Base モデルと Chat モデルが含まれており、多言語サポートを提供します。アリババの同義前文チームは、関連技術が同義前文公式ウェブサイトと同義前文アプリでもリリースされたと述べた。さらに、本日の Qwen 1.5 リリースには、32K のコンテキスト長のサポート、Base+Chat モデルのチェックポイントのオープン、および 32K のコンテキスト長のサポートなどのハイライトもあります。
 大規模なモデルもスライスでき、Microsoft SliceGPT により LLAMA-2 の計算効率が大幅に向上します。
Jan 31, 2024 am 11:39 AM
大規模なモデルもスライスでき、Microsoft SliceGPT により LLAMA-2 の計算効率が大幅に向上します。
Jan 31, 2024 am 11:39 AM
大規模言語モデル (LLM) には通常、数十億のパラメーターがあり、数兆のトークンでトレーニングされます。ただし、このようなモデルのトレーニングとデプロイには非常にコストがかかります。計算要件を軽減するために、さまざまなモデル圧縮技術がよく使用されます。これらのモデル圧縮技術は一般に、蒸留、テンソル分解 (低ランク因数分解を含む)、枝刈り、および量子化の 4 つのカテゴリに分類できます。プルーニング手法は以前から存在していましたが、多くはパフォーマンスを維持するためにプルーニング後にリカバリ微調整 (RFT) を必要とするため、プロセス全体のコストが高くつき、拡張が困難になります。チューリッヒ工科大学とマイクロソフトの研究者は、この問題に対する SliceGPT と呼ばれる解決策を提案しました。この方法の中心となるアイデアは、重み行列の行と列を削除することでネットワークの埋め込みを減らすことです。
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 Gemini Pro に追いつき、推論機能と OCR 機能を向上させた LLaVA-1.6 は強力すぎます
Feb 01, 2024 pm 04:51 PM
Gemini Pro に追いつき、推論機能と OCR 機能を向上させた LLaVA-1.6 は強力すぎます
Feb 01, 2024 pm 04:51 PM
昨年 4 月、ウィスコンシン大学マディソン校、マイクロソフト リサーチ、コロンビア大学の研究者が共同で LLaVA (Large Language and Vision Assistant) をリリースしました。 LLaVA は小規模なマルチモーダル命令データセットでのみトレーニングされていますが、一部のサンプルでは GPT-4 と非常によく似た推論結果を示します。その後 10 月に、オリジナルの LLaVA に簡単な変更を加えて 11 のベンチマークの SOTA を更新した LLaVA-1.5 をリリースしました。このアップグレードの結果は非常に刺激的で、マルチモーダル AI アシスタントの分野に新たなブレークスルーをもたらします。研究チームは、推論、OCR、および
 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
何?ズートピアは国産AIによって実現するのか?ビデオとともに公開されたのは、「Keling」と呼ばれる新しい大規模な国産ビデオ生成モデルです。 Sora も同様の技術的ルートを使用し、自社開発の技術革新を多数組み合わせて、大きく合理的な動きをするだけでなく、物理世界の特性をシミュレートし、強力な概念的結合能力と想像力を備えたビデオを制作します。データによると、Keling は、最大 1080p の解像度で 30fps で最大 2 分の超長時間ビデオの生成をサポートし、複数のアスペクト比をサポートします。もう 1 つの重要な点は、Keling は研究所が公開したデモやビデオ結果のデモンストレーションではなく、ショートビデオ分野のリーダーである Kuaishou が立ち上げた製品レベルのアプリケーションであるということです。さらに、主な焦点は実用的であり、白紙小切手を書かず、リリースされたらすぐにオンラインに移行することです。Ke Ling の大型モデルは Kuaiying でリリースされました。
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
