

流通・サービスERPシステムの構築

当初はデータ量が多くなかったのでシステムパフォーマンスはかなり良く、各種リストクエリ、レポートクエリ、Excelデータエクスポート機能などもスムーズに利用できました。しかし、会社のビジネスが発展し、注文量が日に日に蓄積され、後期にはさまざまな事業部門からのレポート クエリやデータ エクスポートの需要が増加し続けるにつれて、システムの動作が徐々に遅くなっていると感じていました。したがって、最初に考えられる解決策は、システムのボトルネック データベースを最適化することです。考えられる試みの 1 つは、データベースをサーバー上に個別に配置してデータベースとアプリケーションを分離したり、さまざまなデータベース テーブルのインデックスを確立したり、プログラム コードを最適化したりすることです。このような調査と最適化の後、システムの一部の機能のパフォーマンスは確かに大幅に改善される可能性がありますが、データ クエリと一部の機能リストのエクスポートが依然として非常に遅いことがわかりました。または、データ量が蓄積し続けると、元々高速だったリストエクスポート機能もどんどん遅くなってきています。さまざまな方法を試しましたが、最終的には理想的なシステムパフォーマンス速度を達成できませんでした。
システムのパフォーマンスを向上させるために、高同時実行性、高性能、ビッグデータ、読み書き分離、その他のソリューションなど、一部のインターネット企業の技術的経験から率先して学ぶこともありますが、始める方法がありません。システムのビジネス特性が異なると考えられます。 ERP システムの同時実行性は、主にビジネスの複雑さにより高くありません。さまざまなビジネスの結合度がインターネット アプリケーションよりもはるかに高く、分割が困難です。データ クエリ ロジックはそれよりもはるかに複雑です。インターネット システムのリスト ページからクエリされたデータは、4 つまたは 5 つのテーブルを関連付けることによって得られる結果を必要とすることがよくあります。一部のレポートではさらに多くのことが報告されています。さまざまな業務運営のトランザクションの性質と高いデータ整合性要件が相まって、私たちは不意を突かれてシステムをさらに最適化できないことがよくありました。
昔、ERP システムは非常に特殊で治らないものだと考えて、何らかの理由でイライラしていましたが、後になってしまいました。 。 。
もうそうは思わない、新しい解決策がありそうだO(∩_∩)Oはは~
具体的な計画を説明する前に、まず私の考えを述べさせていただきます。まず、ERP システムを構築する前に、今日のインターネットの考え方が必要だと思います。私たちはもはや統一システムを構築したいとは思っていません。大規模なシステムを小さなシステムに分割する必要があります。これらの小さなシステムは、システム インターフェイスを通じて相互に通信できるようになります。これは大きなシステム、特に「分散型」および「サービス指向」のインターネットの考え方を形成します。システムは、アーキテクチャ設計の観点から本質的に高い拡張性をサポートするシステムとします。
###どうやってするの?具体的には、受注管理、商品管理、生産・調達、倉庫管理、物流管理、財務管理をサブシステムに分割する必要があります。これらのサブシステムは独立して設計および開発でき、他のさまざまなサブシステムに必要なデータ インターフェイスを外部に公開できます。各サブシステムには個別のデータベースがあります。これらのサブシステムであっても、異なる技術システムや異なるデータベースを使用して、異なるチームが開発および保守することができます。以前と同じ大規模で包括的なシステム、つまり大規模で包括的なデータベースに統合されるのではありません。新しいアーキテクチャ システムの利点は何ですか?
最初に最も重要なことは、システムのパフォーマンスの問題を解決することです。以前はデータベース インスタンスが 1 つしかなく、パフォーマンスが制限されている場合にデータベース インスタンスを追加して負荷分散を実現するために複数のインスタンスに拡張することはできませんでした。読み書き分離ソリューションを使用できると言う人もいるかもしれませんが、ERP システムの特性により、このソリューションは多くの場合非現実的です。たとえば、インベントリを操作する場合、読み取りライブラリからインベントリを読み取り、書き込みライブラリにインベントリを書き込むことはできません。マスター/スレーブ レプリケーションは時間に依存するため、書き込まれたインベントリをスレーブ データベースにすぐに書き込むことはできません。 ERP にはそのようなシナリオがたくさんあります。さらに、書き込みライブラリは拡張できず、1 つしか存在できません。新しい設計ソリューションは、書き込みライブラリを分離し、各サブシステムが独自のデータベースを持つことです。
第二に、更新が非常に便利で、各サブシステムはバックグラウンド マイクロサービスとして存在します。フロントエンドには別の Web プロジェクトがあり、この Web プロジェクトはバックエンドでこれらのサブシステムのサービス インターフェイスを呼び出します。この設計により、特定の業務サブシステムを更新する必要がある場合、独立して更新できます。以前の単一プロセス アーキテクチャとは異なり、小規模な更新ではシステム全体の再起動が必要となり、ユーザー セッションが失われ、ユーザーは再度ログインする必要がありました。現在の設計ではこの問題は発生しません。
システムの物理的な展開ビュー
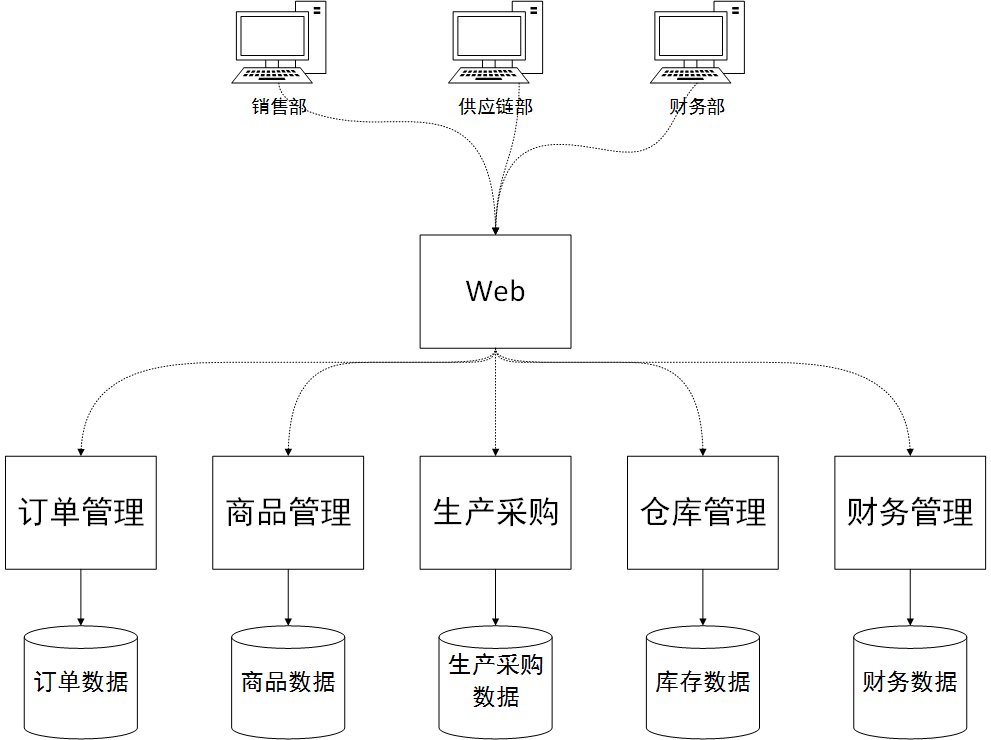
アプリケーション層の分割は、「マイクロサービス」アーキテクチャの概念を実装することです。元の大規模で包括的な単一プロセス アーキテクチャをビジネス モジュールに応じて独立して展開可能なアプリケーションに分割することで、スムーズなシステムの更新とアップグレードを実現し、負荷の拡張を容易にします。具体的には、技術的には、Restfull スタイルのインターフェイスを使用することも、Java の Dubbo などのフレームワークを使用して、開発の複雑さを簡素化することもできます。 ERP Web クライアントまたはその他のモバイル クライアントも、プレゼンテーション層として機能する別個のアプリケーションです。これは非常に薄く、単にパラメータを受け取り、バックグラウンドで他のさまざまなマイクロサービス プログラムのインターフェイスを呼び出して、表示する必要のあるデータを取得します。マイクロサービスはビジネス ロジック層として機能し、各マイクロサービスは独立して展開できるプログラムであり、外部データ アクセス インターフェイスを提供します。
マイクロサービスは、複数の呼び出しプロトコル (Http、TCP など) をサポートできる dubbo などのさまざまな一般的な RPC フレームワークを使用できます。これらのフレームワークにより、コーディングが容易になります。フレームワークは、基礎となるデータ通信の詳細をカプセル化し、クライアントがリモート メソッドを実行するようにします。ネイティブのメソッドも同様に簡単です。
Dubbo マイクロサービス アーキテクチャは、サービス ガバナンス、負荷分散、その他の機能もサポートしています。これにより、システムの可用性が向上するだけでなく、システム アプリケーション層のパフォーマンスも動的に向上します。たとえば、倉庫管理では、倉庫業務が非常に忙しく、多くの CPU とメモリ リソースを消費するため、別のマシンを追加して、別個の倉庫管理サービスを展開できます。これにより、システム全体で 2 つの倉庫管理サービスを同時に動作させて負荷のバランスをとることができます。これらはすべて、Zookeeper などのサービス登録センターで自動的に行われます。
マイクロサービス構造は、システムの更新とアップグレードの操作を自然にサポートします。たとえば、財務モジュールに新しい要件があり、オンラインにする必要がある場合、財務モジュールのサービスを置き換えて再起動するだけで済みます。すでにシステムにログインしているユーザーには大きな影響はなく、再度システムにログインする必要はなく、他のモジュール サービスの使用にも影響はありません。
データベースのボトルネックは、ERP システムに永久的なダメージを与えます。大量の複雑なデータ クエリ テーブル接続ロジックがシステム全体にあふれています。データベースの垂直分割を成功させる鍵は、システム データ層のさまざまなモジュールの相互結合をどのように再設計するかです。この問題を解決できれば永久的なダメージは解決できます。
まず、典型的なデータ層モジュールの結合問題を見てみましょう。要件は、材料在庫を表示することです。リストフィールド: 材料番号、材料名、カテゴリ、倉庫、数量
材料リスト:
在庫テーブル:
カテゴリとウェアハウスのテーブルは省略されています。 。 。
明らかに、従来のデータベースでは、これら 2 つのテーブルを関連付け、カテゴリ テーブルとウェアハウス テーブルを関連付けて必要なデータをクエリするための単純な結合操作のみが必要です。しかし、現在のアーキテクチャでは、材料テーブルと製品テーブルが同じデータベース インスタンス内になく、結合操作を使用できません。
新しいアーキテクチャでは、相手のサービス インターフェイスを介してのみデータを取得でき、相手のサービスのプライベート データベースと直接関連付けることはできません。少なくともアーキテクチャの観点、サービス指向の観点から見ると、相手のサービスのデータベースに直接アクセスすることはできません。この場合、Web モジュール サブシステムがデータを取得するためにウェアハウス サブシステムを呼び出すと仮定すると、データを組み立てるためのサービス メソッドをウェアハウス モジュール内に作成する必要があります。その後、Web サブシステムに返されます。倉庫管理メソッドは、下図に示すように、まず現地在庫テーブルの資材コードと倉庫テーブルの倉庫名フィールド情報を取得し、ページングを経て、最終的に20個のデータをWebモジュールに返す準備が整います。これら 20 個のデータの素材 ID は商品モジュール サブシステムに要求するパラメータとして、商品サブシステムはこれら 20 個の素材 ID に関連する商品情報を倉庫管理モジュールに返し、倉庫管理モジュールは 2 つのフィールド データを再組み立てします。最終要件を達成するために上のリストに必要な材料名とカテゴリのデータが Web サブシステムに返されます。
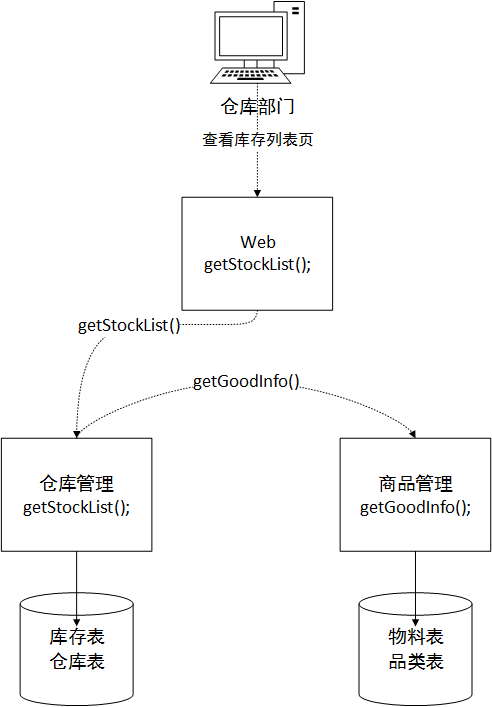
面倒すぎると思われるかもしれませんが、この方法のパフォーマンスは直接結合に比べて決して高くはなく、パフォーマンスの問題を解決することはできません。と思われるかもしれませんが、よく考えてみると、システムの同時実行性が低く、データ量が少なく、ビジネスが忙しくない環境では、パフォーマンスは確かに従来の結合ほど速くありません。メソッドを 1 つのデータにまとめます。でも、後で考えましょう!現在のアーキテクチャ設計では、1 つのデータベースを複数のデータベースに分割し、各データベースを個別のサーバーで実行できるため、将来データベースに負荷がかかる可能性があります。全体として、これにより、将来ビジネスが多忙になったときにデータベースがパフォーマンスのボトルネックになるのを防ぐことができます。考えるだけでワクワクしますよね。
このとき、将来的にシステムのデータ量や業務が大きくなり、複数のデータベースに分割しても足りなかったらどうするのか、と改めて疑問に思う人もいるでしょう。私の方法は分割データベースに基づいており、各ライブラリは読み取りと書き込みを分離したり、キャッシュを使用したりできます。サブシステムを再び複数のサブシステムに分割し続けることもできます。それはビジネス モジュールがどれだけビジーであるかによって異なります。
また質問する人もいるかもしれませんが、一部のリスト クエリ ロジックは非常に複雑で、10 を超えるテーブルに関連付けられています。上記の方法に従ってデータが分割されると、大惨事になります。はい、その通りです。この場合、私の計画では、このより複雑なレポート レベルのデータ クエリを使用して要件を表示し、別のレポート システムを構築することができます。レポート データベースの設計には、データ ウェアハウスのアプローチが採用されています。読み取りパフォーマンスを向上させるために、データベース テーブルを多くの冗長フィールドに設計することができます。これはアンチパラダイム設計であり、結合されたインデックスを多数作成します。
このシステムの成功の鍵は、データとメイン ERP システム ビジネス ライブラリの同期です。一般に、スケジュールされた同期プログラムを作成して、ERP メイン ビジネス システム内のデータの選択、変換などを通じてレポート ビューに必要な最終データまたは中間データを直接生成し、関連するクエリを簡素化できます。レポート システムは、マイクロサービス アーキテクチャを使用して設計することもできます。以下に示すように:
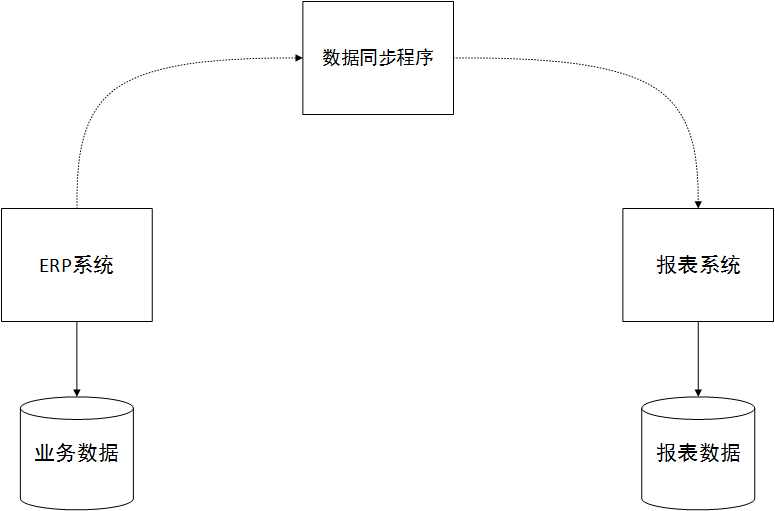
レポートに必要なデータがリアルタイムである必要がある場合、ERP システムが業務運営中にデータ同期リクエストをトリガーし、それをレポート ライブラリにリアルタイムで同期できるようにすることができます。
もしかしたら、誰かがもう一度質問したかもしれませんが、ERP システムの多くの操作にはトランザクション性が必要です。システムを分割した後、どのようにトランザクション性を実現し、データの一貫性を確保しますか?
これは良い質問であり、この記事を書く前に私が考えた最後の質問でもあります。マイクロサービス アーキテクチャでは、少なくともローカル データベース トランザクションを使用するローカル アプリケーションほど便利ではないものの、効率的なパフォーマンスと優れたデータ一貫性を備えたサービスを実装するのは簡単ではありません。
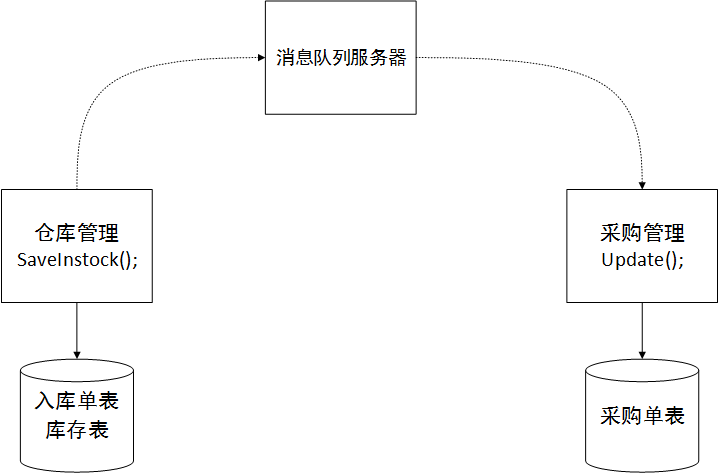
分散トランザクションという概念について聞いたことがあるかもしれません。シナリオは 2 つあり、1 つは 1 つのアプリケーションで複数のデータベースを使用する場合で、データの一貫性を確保するには、分散トランザクションを使用する必要があります。私たちのアーキテクチャに特有の状況がもう 1 つあります。具体的には、マイクロサービス環境における分散トランザクションがこれに似ています。倉庫管理サービスでは、購買と倉庫の運用を設計します。倉庫保管後、調達サブシステムの発注書の倉庫数量を更新する必要があります。このプロセスではデータの一貫性が必要です。つまり、発注書が倉庫に正常に投入された後、在庫テーブルの数量が在庫テーブルに書き込まれ、発注書テーブルの数量も同時に更新される必要があります。倉庫サービスから調達サービスのデータベースに直接アクセスすることはできないため、調達サービスが提供するサービス インターフェイスを使用する必要があります。もしそうなら、データの一貫性をどのように確保できるでしょうか?在庫テーブルは正常に書き込まれても、発注書データを書き込むための調達サービスの呼び出しが失敗する可能性が非常に高いためです。ネットワークの問題が原因でデータが不整合になっている可能性があります。
分散トランザクション テクノロジでは、究極の一貫性を実現するというものがあります。つまり、両側のデータが最終的に一貫していることを保証できる限り、トランザクションを使用する必要はありません。そこで計画があります。たとえば、倉庫サブシステムが購入と倉庫保管を処理する場合、倉庫注文データを追加し、在庫データやその他のテーブルを更新する必要があります。これらの複数のテーブルはすべてウェアハウス サブシステム内にあり、ローカル トランザクションを使用してウェアハウス サブシステム内のテーブル データの一貫性を確保できます。次に、調達サブシステムを呼び出して、発注書の倉庫数量を更新します。このプロセスが突然中断されて呼び出しが失敗することを防ぐために、ActiveMQ などのメッセージ キュー ミドルウェアを追加することを検討します。インターフェースが戻らない場合は、MQ に処理要求を書き込み、調達サブシステムが正常に戻った後、MQ は更新操作を処理するように調達サブシステムに通知します。メッセージが消費された後はそれ以上通知はないため、調達サブシステムの処理中に例外が発生し、更新が失敗しました。その後の補償のために管理者に通知するには、問題をローカル ログ ライブラリに書き込む必要があります。処理。このように、さまざまな方法を使用して、データの最終的な一貫性を実現できます。少しわかりにくいように思えますが、これが解決策です。他にこれより良いものはありません。または、更新が失敗した後、倉庫サブシステムを再度呼び出して倉庫入庫データと在庫データをロールバックし、最終的な整合性を実現します。写真が示すように:
知識や経験を皆さんと共有できることをとても光栄に思います。皆さんが無私に共有するからこそ、私たちは成長し進歩することができます。ここ数年はほとんど物事を共有していません。時々、とても忙しいからです。仕事中なので書く時間がありません。場合によっては、私が怠けていたり、みんなと共有する新しいものがなかったりすることがあります。最後に、皆さんが私の共有における欠点を批判して修正し、一緒に進歩できることを願っています。
以上が流通・サービスERPシステムの構築の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7513
7513
 15
1378
52
79
11
19
64
15
1378
52
79
11
19
64

 Apacheを始める方法
Apr 13, 2025 pm 01:06 PM
Apacheを始める方法
Apr 13, 2025 pm 01:06 PM
Apacheを開始する手順は次のとおりです。Apache(コマンド:sudo apt-get install apache2または公式Webサイトからダウンロード)をインストールします(linux:linux:sudo systemctl start apache2; windows:apache2.4 "serviceを右クリックして「開始」を右クリック) (オプション、Linux:Sudo SystemCtl
 Apache80ポートが占有されている場合はどうすればよいですか
Apr 13, 2025 pm 01:24 PM
Apache80ポートが占有されている場合はどうすればよいですか
Apr 13, 2025 pm 01:24 PM
Apache 80ポートが占有されている場合、ソリューションは次のとおりです。ポートを占有するプロセスを見つけて閉じます。ファイアウォールの設定を確認して、Apacheがブロックされていないことを確認してください。上記の方法が機能しない場合は、Apacheを再構成して別のポートを使用してください。 Apacheサービスを再起動します。
 DebianのNginx SSLパフォーマンスを監視する方法
Apr 12, 2025 pm 10:18 PM
DebianのNginx SSLパフォーマンスを監視する方法
Apr 12, 2025 pm 10:18 PM
この記事では、Debianシステム上のNginxサーバーのSSLパフォーマンスを効果的に監視する方法について説明します。 Nginxexporterを使用して、NginxステータスデータをPrometheusにエクスポートし、Grafanaを介して視覚的に表示します。ステップ1:NGINXの構成最初に、NGINX構成ファイルのSTUB_STATUSモジュールを有効にして、NGINXのステータス情報を取得する必要があります。 NGINX構成ファイルに次のスニペットを追加します(通常は/etc/nginx/nginx.confにあるか、そのインクルードファイルにあります):location/nginx_status {stub_status
 Debianシステムでリサイクルビンをセットアップする方法
Apr 12, 2025 pm 10:51 PM
Debianシステムでリサイクルビンをセットアップする方法
Apr 12, 2025 pm 10:51 PM
この記事では、デビアンシステムでリサイクルビンを構成する2つの方法を紹介します:グラフィカルインターフェイスとコマンドライン。方法1:Nautilusグラフィカルインターフェイスを使用して、ファイルマネージャーを開きます。デスクトップまたはアプリケーションメニューでNautilusファイルマネージャー(通常は「ファイル」と呼ばれる)を見つけて起動します。リサイクルビンを見つけてください:左ナビゲーションバーのリサイクルビンフォルダーを探してください。見つからない場合は、「他の場所」または「コンピューター」をクリックして検索してみてください。リサイクルビンプロパティの構成:「リサイクルビン」を右クリックし、「プロパティ」を選択します。プロパティウィンドウで、次の設定を調整できます。最大サイズ:リサイクルビンで使用可能なディスクスペースを制限します。保持時間:リサイクルビンでファイルが自動的に削除される前に保存を設定します
 ネットワーク監視におけるDebian Snifferの重要性
Apr 12, 2025 pm 11:03 PM
ネットワーク監視におけるDebian Snifferの重要性
Apr 12, 2025 pm 11:03 PM
検索結果は「DebiansNiffer」とネットワークモニタリングにおけるその特定のアプリケーションに直接言及するわけではありませんが、「Sniffer」はネットワークパケットキャプチャ分析ツールを指し、Debianシステムでのアプリケーションは他のLinux分布と本質的に違いはありません。ネットワークの監視は、ネットワークの安定性を維持し、パフォーマンスを最適化するために重要であり、パケットキャプチャ分析ツールが重要な役割を果たします。以下は、ネットワーク監視ツールの重要な役割(Debianシステムで実行されるSnifferなど)を説明しています。ネットワーク監視ツールの価値:高速障害場所:帯域幅の使用状況、遅延、パケット損失率など、ネットワーク障害の根本原因を迅速に特定し、トラブルシューティング時間を短縮できるようなネットワークメトリックのリアルタイム監視。
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Apacheサーバーを再起動する方法
Apr 13, 2025 pm 01:12 PM
Apacheサーバーを再起動する方法
Apr 13, 2025 pm 01:12 PM
Apacheサーバーを再起動するには、次の手順に従ってください。Linux/MacOS:sudo systemctl restart apache2を実行します。 Windows:Net Stop apache2.4を実行し、ネット開始apache2.4を実行します。 Netstat -A |を実行しますサーバーのステータスを確認するには、STR 80を見つけます。
 Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
このガイドでは、Debian SystemsでSyslogの使用方法を学ぶように導きます。 Syslogは、ロギングシステムとアプリケーションログメッセージのLinuxシステムの重要なサービスです。管理者がシステムアクティビティを監視および分析して、問題を迅速に特定および解決するのに役立ちます。 1. syslogの基本的な知識Syslogのコア関数には以下が含まれます。複数のログ出力形式とターゲットの場所(ファイルやネットワークなど)をサポートします。リアルタイムのログ表示およびフィルタリング機能を提供します。 2。syslog(rsyslogを使用)をインストールして構成するDebianシステムは、デフォルトでrsyslogを使用します。次のコマンドでインストールできます:sudoaptupdatesud
