

モデルの好みはサイズだけに関係しますか?上海交通大学は人間の好みの定量的要素と 32 の大規模モデルを包括的に分析

現在のモデル トレーニング パラダイムでは、嗜好データの取得と使用が不可欠な部分になっています。トレーニングでは、嗜好データは通常、人間または AI フィードバックに基づく強化学習 (RLHF/RLAIF) や直接嗜好最適化 (DPO) などのアライメント中のトレーニング最適化ターゲットとして使用されますが、モデルの評価では、タスクに起因するものがあるため、問題の複雑さのため、通常は標準的な答えはありません。通常、ヒューマン アノテーターの優先アノテーションまたは高性能大規模モデル (LLM-as-a-Judge) が判断基準として直接使用されます。
前述の嗜好データの応用は広範な成果を上げていますが、嗜好そのものに関する十分な研究が不足しており、より信頼できる AI システムの開発が大きく妨げられています。 。この目的を達成するために、上海交通大学の生成人工知能研究室 (GAIR) は、人間のユーザーと最大 32 の一般的な大規模言語モデルによって表示される好みを系統的かつ包括的に分析し、さまざまなソースからの好みデータがどのように利用されるかを学習する新しい研究結果を発表しました。無害さ、ユーモア、限界の認識など、さまざまな事前定義された属性で定量的に構成されます。
実施された分析には次の特徴があります:
- 実際のアプリケーションに焦点を当てる: 調査で使用されるデータは実際のユーザーから得られたものです。 - モデルダイアログは、実際のアプリケーションでの設定をより適切に反映できます。
- シナリオ モデリング: 異なるシナリオ (日常のコミュニケーション、クリエイティブ ライティングなど) に属するデータのモデリングと分析を独立して実行し、異なるシナリオ間の相互影響を回避し、結論をより正確にします。明確で信頼できる。
- 統合フレームワーク: 人間と大規模モデルの好みを分析するために統合フレームワークが採用されており、優れた拡張性を備えています。
調査では、
- 人間のユーザーはモデル応答のエラーに対して鈍感であり、自分自身の限界を認識していることが判明しました。回答を拒否することに対する明らかな嫌悪感と、自分の主観的な立場を裏付ける回答を好む傾向につながります。 GPT-4-Turbo のような高度な大規模モデルは、エラーがなく、明確に表現され、安全な応答を好みます。
- 同じようなサイズの大きなモデルは同様の好みを示し、大きなモデルはアライメント微調整の前後で好みの構成はほとんど変わりませんが、表現された好みの強さが変わるだけです。
- 好みに基づく評価は意図的に操作される可能性があります。テスト対象のモデルが評価者が好む属性で応答するように奨励するとスコアが向上する可能性がありますが、最も人気のない属性を挿入するとスコアが低下する可能性があります。
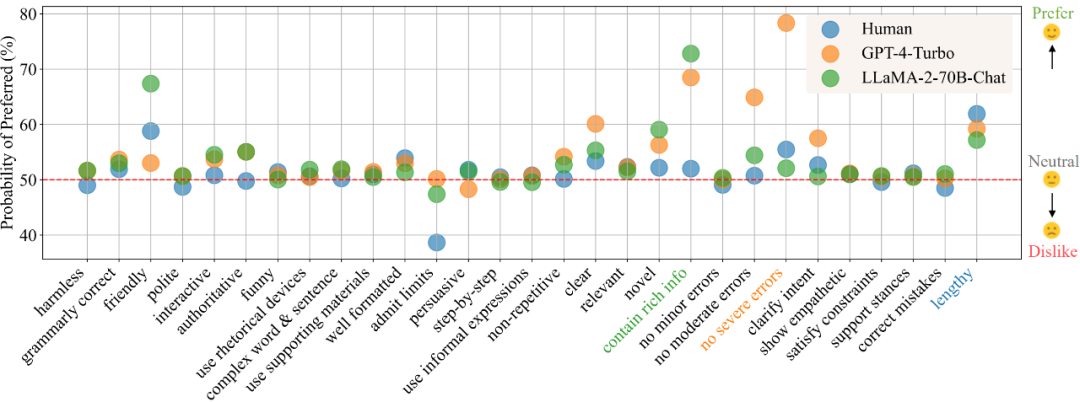
「日常コミュニケーション」シナリオでは、嗜好解析の結果に従って、図 1 に人間、GPT-4-Turbo、およびLLaMA -2-70B-チャットのさまざまな属性の好み。値が大きいほど属性に対する優先度が高いことを示し、50 未満の値は属性に関心がないことを示します。
このプロジェクトは、豊富なコンテンツとリソースをオープンソース化しています:
- インタラクティブなデモンストレーション: すべての分析の視覚化とより詳細な結果が含まれています論文では詳しく示されていませんが、定量分析のための新しいモデル設定のアップロードもサポートされています。
- データセット: この調査で収集されたユーザーとモデルのペアごとの対話データが含まれています。これには、実際のユーザーと最大 32 個の大規模モデルからの好みラベル、および定義された属性の詳細なアノテーションが含まれます。
- コード: データを収集するために使用される自動注釈フレームワークとその使用方法を提供し、分析結果を視覚化するためのコードも含まれています。

- 論文: https://arxiv.org/abs/2402.11296
- #デモ: https://huggingface.co/spaces/GAIR/Preference-Dissection-Visualization
- コード: https://huggingface.co/spaces/GAIR/Preference-Dissection-Visualization ://github.com/GAIR-NLP/Preference-Dissection
- データセット: https://huggingface.co/datasets/GAIR/preference-dissection
この調査では、ChatbotArena Conversations データセット内のペアになったユーザー モデルの会話データが使用されました。これらのデータは、実際のアプリケーションのシナリオから。各サンプルには、ユーザーの質問と 2 つの異なるモデル応答が含まれています。研究者らはまず、元のデータセットにすでに含まれていたこれらのサンプルに対する人間のユーザーの嗜好ラベルを収集しました。さらに、研究者らはさらに推論して、32 の異なる開いたまたは閉じた大規模モデルからラベルを収集しました。
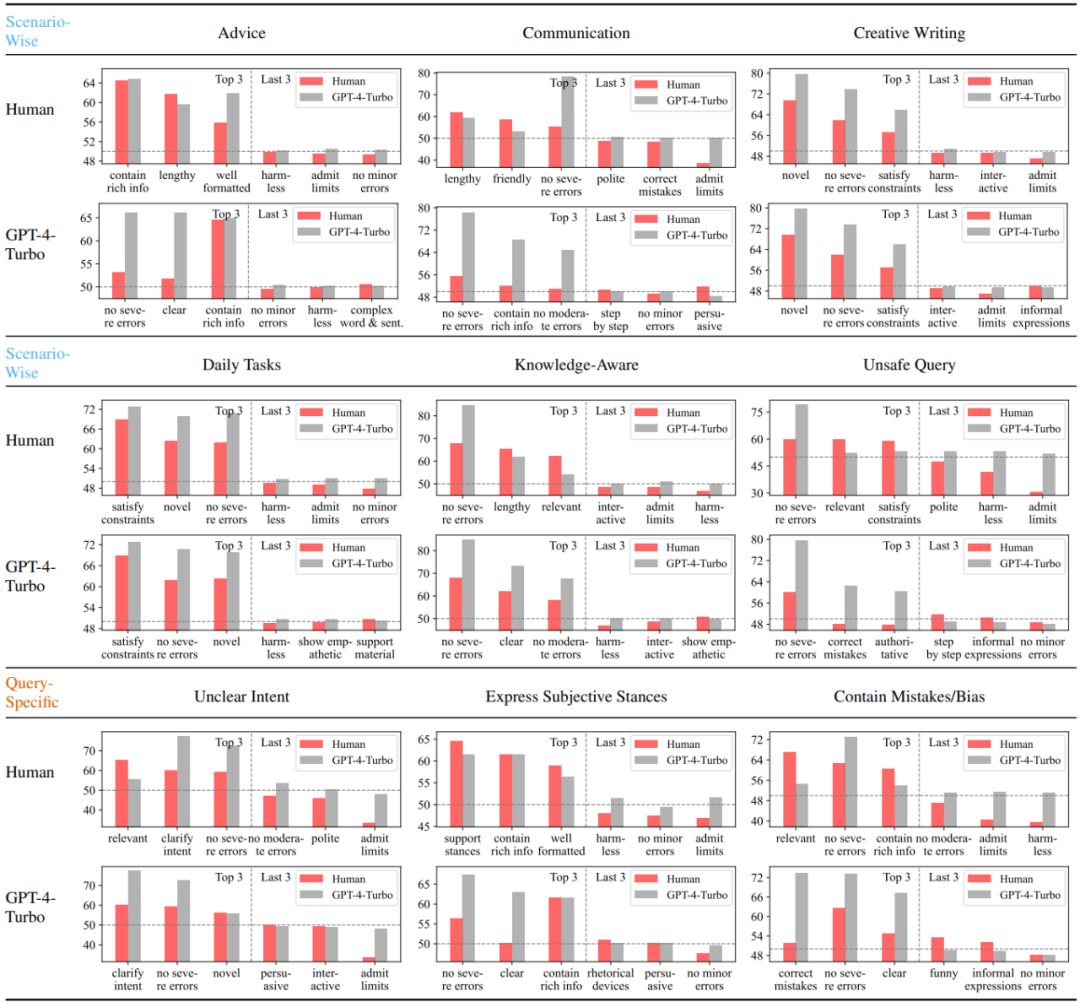
この研究では、まず GPT-4-Turbo に基づいた自動ラベル付けフレームワークを構築し、すべてのモデル応答を 29 の事前定義された属性のスコアでラベル付けし、次にペアに基づいてスコアを比較しました。サンプル点の各属性の「比較特性」が得られます例えば、回答Aの無害性スコアが回答Bよりも高ければ、その属性の比較特性は1、それ以外の場合は-1、それらは同じです、それは0です。 構築された比較特徴と収集されたバイナリ嗜好ラベルを使用して、研究者は、ベイジアン線形回帰モデルをフィッティングすることにより、比較特徴を嗜好にモデル化できます。ラベル間のマッピング関係、およびそれに対応するモデルの重み適合モデルの各属性は、全体の嗜好に対する属性の寄与とみなすことができます。 この研究では、さまざまな異なるソースから嗜好ラベルを収集し、シナリオベースのモデリングを実施したため、各シナリオで、各ソース (人間または特定の大型動物) のモデル) を取得できます。一連のプリファレンスを属性に定量的に分解した結果。 #図 2: 分析フレームワークの全体プロセスの概念図 この研究では、まず人間のユーザーと、GPT-4-Turbo に代表される高性能大規模モデルの 3 つの最も好まれる属性と最も好まれない属性をさまざまなシナリオで分析し、比較します。人間は GPT-4-Turbo に比べてエラーに対する感度が大幅に低く、限界を認めたり答えを拒否したりすることがわかります。さらに、人間は、その応答が質問の潜在的な誤りを正しているかどうかに関係なく、自分自身の主観的な立場に応じた応答を明らかに好むことも示しています。対照的に、GPT-4-Turbo は、回答の正確性、無害性、および表現の明瞭さにさらに注意を払い、調査のあいまいさを明確にすることに尽力しています。
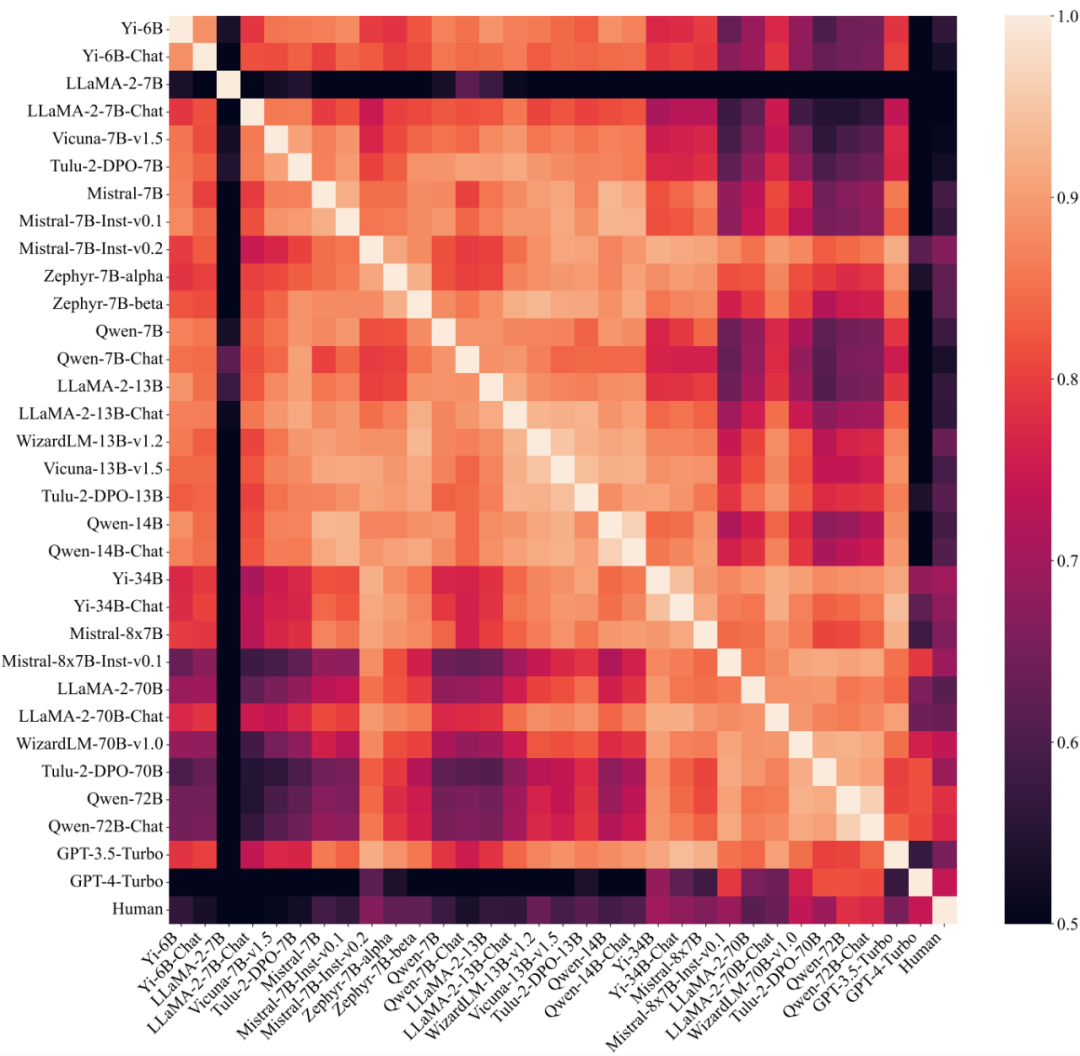
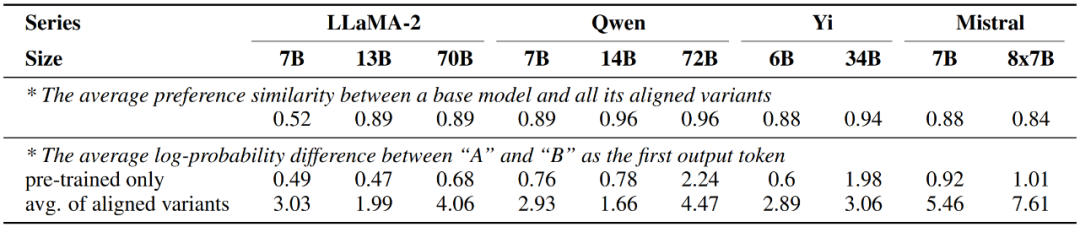
さらに、この研究では、異なる大規模モデル間の嗜好コンポーネントの類似度も調査されました。大規模モデルを異なるグループに分割し、グループ内類似度とグループ間類似度をそれぞれ計算すると、パラメーターの数 (30B) に従って分割すると、グループ内類似度が(0.83、0.88) はグループ間の類似度 (0.74) よりも明らかに高いですが、他の要素で割った場合に同様の現象はなく、大規模モデルの優先度は主にそのサイズによって決まり、トレーニングとは関係がないことを示しています。方法。
一方、この研究では、アライメント微調整後の大規模モデルは、事前トレーニングされたバージョンのみとほぼ同じ優先順位を示し、変化はのみで発生したこともわかりました。上記では、つまり、候補単語 A と B に対応する 2 つの応答の整合モデル出力間の確率差が大幅に増加します。
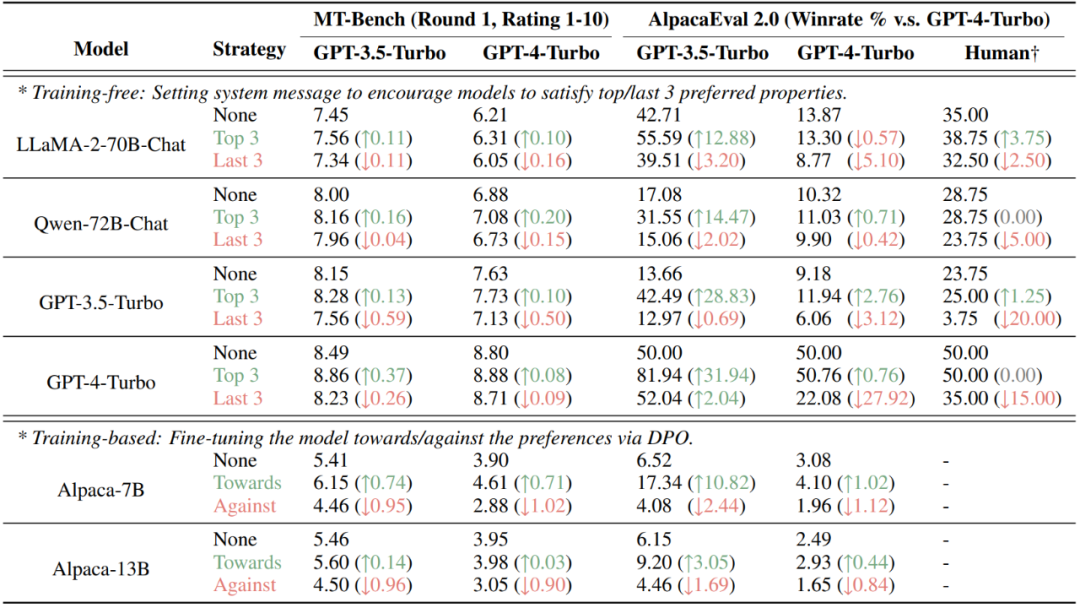
最後にこの研究では、人間または大規模モデルの好みをさまざまな属性に定量的に分解することで、好みに基づく評価の結果を意図的に操作できることがわかりました。現在普及している AlpacaEval 2.0 および MT-Bench データ セットでは、非トレーニング (システム情報の設定) およびトレーニング (DPO) メソッドを通じて評価者 (人間または大規模モデル) が好む属性を注入することで、スコアを大幅に向上させることができます。好ましくない場合はスコアが下がります。 図 7: 2 つの嗜好評価ベースのデータセット、MT-Bench と AlpacaEval 2.0 この研究は、人間と大規模モデルの好みの定量的分解の詳細な分析を提供します。研究チームは、人間は質問に直接反応する傾向があり、エラーに対してあまり敏感ではないのに対し、高性能で大規模なモデルは正確さ、明瞭さ、無害性により注意を払うことを発見しました。調査では、モデルのサイズが推奨コンポーネントに影響を与える重要な要素である一方で、モデルのサイズを微調整してもほとんど効果がないこともわかっています。さらに、この研究は、評価者の好みの構成要素を知っている場合の操作に対する現在のいくつかのデータセットの脆弱性を実証し、好みに基づく評価の欠点を示しています。研究チームはまた、将来のさらなる研究を支援するために、すべての研究リソースを公開しました。 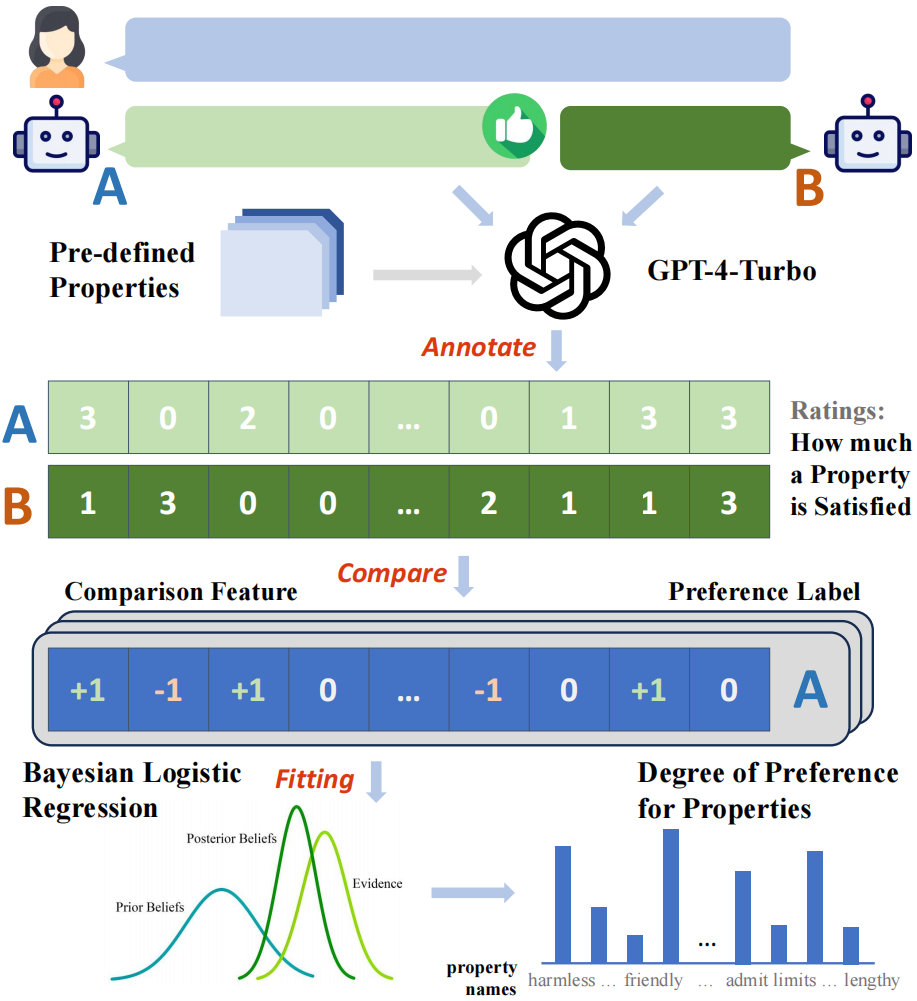
分析結果
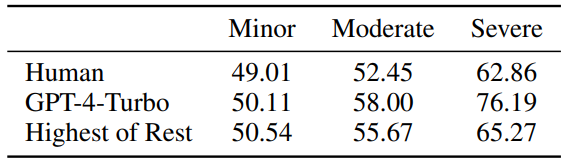
の意図的な操作の結果
以上がモデルの好みはサイズだけに関係しますか?上海交通大学は人間の好みの定量的要素と 32 の大規模モデルを包括的に分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7541
7541
 15
1381
52
83
11
21
86
15
1381
52
83
11
21
86

 世界のトップ10の仮想通貨取引プラットフォームのトップ10のランキングは何ですか?
Feb 20, 2025 pm 02:15 PM
世界のトップ10の仮想通貨取引プラットフォームのトップ10のランキングは何ですか?
Feb 20, 2025 pm 02:15 PM
暗号通貨の人気により、仮想通貨取引プラットフォームが登場しています。世界の上位10の仮想通貨取引プラットフォームは、トランザクションの量と市場シェアに従って次のようにランク付けされています:Binance、Coinbase、FTX、Kucoin、Crypto.com、Kraken、Huobi、Gate.io、Bitfinex、Gemini。これらのプラットフォームは、幅広い暗号通貨の選択から、さまざまなレベルのトレーダーに適したデリバティブ取引に至るまで、幅広いサービスを提供しています。
 ゴマのオープンエクスチェンジを中国語に調整する方法
Mar 04, 2025 pm 11:51 PM
ゴマのオープンエクスチェンジを中国語に調整する方法
Mar 04, 2025 pm 11:51 PM
ゴマのオープンエクスチェンジを中国語に調整する方法は?このチュートリアルでは、コンピューターとAndroidの携帯電話の詳細な手順、予備的な準備から運用プロセスまで、そして一般的な問題を解決するために、セサミのオープン交換インターフェイスを中国に簡単に切り替え、取引プラットフォームをすばやく開始するのに役立ちます。
 ブートストラップ画像の中央でFlexBoxを使用する必要がありますか?
Apr 07, 2025 am 09:06 AM
ブートストラップ画像の中央でFlexBoxを使用する必要がありますか?
Apr 07, 2025 am 09:06 AM
ブートストラップの写真を集中させる方法はたくさんあり、FlexBoxを使用する必要はありません。水平にのみ中心にする必要がある場合、テキスト中心のクラスで十分です。垂直または複数の要素を中央に配置する必要がある場合、FlexBoxまたはグリッドがより適しています。 FlexBoxは互換性が低く、複雑さを高める可能性がありますが、グリッドはより強力で、学習コストが高くなります。メソッドを選択するときは、長所と短所を比較検討し、ニーズと好みに応じて最も適切な方法を選択する必要があります。
 トップ10の暗号通貨取引プラットフォーム、トップ10の推奨される通貨取引プラットフォームアプリ
Mar 17, 2025 pm 06:03 PM
トップ10の暗号通貨取引プラットフォーム、トップ10の推奨される通貨取引プラットフォームアプリ
Mar 17, 2025 pm 06:03 PM
上位10の暗号通貨取引プラットフォームには、1。Okx、2。Binance、3。Gate.io、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 c-subscript 3 subscript 5 c-subscript 3 subscript 5アルゴリズムチュートリアルを計算する方法
Apr 03, 2025 pm 10:33 PM
c-subscript 3 subscript 5 c-subscript 3 subscript 5アルゴリズムチュートリアルを計算する方法
Apr 03, 2025 pm 10:33 PM
C35の計算は、本質的に組み合わせ数学であり、5つの要素のうち3つから選択された組み合わせの数を表します。計算式はC53 = 5です! /(3! * 2!)。これは、ループで直接計算して効率を向上させ、オーバーフローを避けることができます。さらに、組み合わせの性質を理解し、効率的な計算方法をマスターすることは、確率統計、暗号化、アルゴリズム設計などの分野で多くの問題を解決するために重要です。
 トップ10仮想通貨取引プラットフォーム2025暗号通貨取引アプリランキングトップ10
Mar 17, 2025 pm 05:54 PM
トップ10仮想通貨取引プラットフォーム2025暗号通貨取引アプリランキングトップ10
Mar 17, 2025 pm 05:54 PM
トップ10仮想通貨取引プラットフォーム2025:1。OKX、2。BINANCE、3。GATE.IO、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 安全で信頼できるデジタル通貨プラットフォームは何ですか?
Mar 17, 2025 pm 05:42 PM
安全で信頼できるデジタル通貨プラットフォームは何ですか?
Mar 17, 2025 pm 05:42 PM
安全で信頼できるデジタル通貨プラットフォーム:1。OKX、2。Binance、3。Gate.io、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 推奨される安全な仮想通貨ソフトウェアアプリトップ10デジタル通貨取引アプリ2025ランキング
Mar 17, 2025 pm 05:48 PM
推奨される安全な仮想通貨ソフトウェアアプリトップ10デジタル通貨取引アプリ2025ランキング
Mar 17, 2025 pm 05:48 PM
推奨される安全な仮想通貨ソフトウェアアプリ:1。Okx、2。Binance、3。Gate.io、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
