

比類のない UniVision: BEV 検出と Occ 統合統合フレームワーク、デュアル SOTA!

正面からの記述と個人的な理解
近年、自動運転技術における視覚中心の 3D 認識が急速に進歩しています。さまざまな 3D 認識モデルには多くの構造的および概念的な類似点がありますが、特徴の表現、データ形式、および目標には依然としていくつかの違いがあり、統一された効率的な 3D 認識フレームワークの設計に課題をもたらしています。したがって、研究者たちは、より完全で効率的な 3D 認識システムを構築するために、さまざまなモデル間の違いをより適切に統合するためのソリューションを見つけるために懸命に取り組んでいます。この種の取り組みにより、自動運転の分野により信頼性が高く先進的な技術がもたらされ、複雑な環境、特に BEV での検出タスクや占有タスクでの能力が向上すると期待されています。これは依然として非常に難しく、不安定性と制御不能な影響により、多くのアプリケーションにとって頭痛の種となっています。 UniVision は、視覚中心の 3D 認識における 2 つの主要なタスク、つまり占有予測とオブジェクト検出を統合するシンプルで効率的なフレームワークです。コアポイントは、相補的な 2D-3D 特徴変換のための明示的-暗黙的ビュー変換モジュールであり、UniVision は、効率的かつ適応的なボクセルと BEV 特徴抽出、強化、およびインタラクションのためのローカルおよびグローバル特徴抽出および融合モジュールを提案しています。
データ強化の部分では、UniVision は、マルチタスク フレームワーク トレーニングの効率と安定性を向上させるために、共同占有検出データ強化戦略と段階的な減量調整戦略も提案しました。シーンフリー LIDAR セグメンテーション、シーンフリー検出、OpenOccupancy、Occ3D を含む 4 つの公開ベンチマークで、さまざまな認識タスクに関する広範な実験が行われています。 UniVision は、各ベンチマークでそれぞれ 1.5 mIoU、1.8 NDS、1.5 mIoU、および 1.8 mIoU のゲインで SOTA を達成しました。 UniVision フレームワークは、統合されたビジョン中心の 3D 認識タスクの高性能ベースラインとして機能します。
BEV および占有タスクに詳しくない場合は、
BEV 知覚チュートリアルおよび 占有占有ネットワーク チュートリアル をさらに学習して、技術的な詳細を学ぶこともできます。 !
3D 認識分野の現状3D 認識は自動運転システムの主なタスクであり、一連のセンサー (LIDAR など) を利用することを目的としています。 、レーダー、カメラ)取得されたデータは、走行シーンを総合的に把握し、その後の計画や意思決定に活用することができます。これまで、3D 認識の分野は、点群データから得られた正確な 3D 情報により、LIDAR ベースのモデルが主流でした。ただし、LIDAR ベースのシステムは高価で、悪天候の影響を受けやすく、導入が不便です。対照的に、ビジョンベースのシステムには、低コスト、簡単な導入、優れた拡張性など、多くの利点があります。したがって、視覚を中心とした三次元認識は研究者の間で広く注目を集めています。
最近、ビジョンベースの 3D 検出は、特徴表現変換、時間融合、教師あり信号設計を通じて大幅に改善され、LIDAR ベースのモデルとのギャップを継続的に狭めています。さらに、視覚ベースの占有タスクは近年急速に発展しています。一部のオブジェクトを表すために 3D ボックスを使用するのとは異なり、占有は、運転シーンのジオメトリとセマンティクスをより包括的に記述することができ、オブジェクトの形状やカテゴリに限定されません。
検出方法と占有方法には多くの構造的および概念的な類似点がありますが、両方のタスクを同時に処理し、それらの相互関係を調査することについては十分に研究されていません。占有モデルと検出モデルは、多くの場合、異なる特徴表現を抽出します。占有予測タスクでは、さまざまな空間位置での徹底的な意味論的および幾何学的判断が必要となるため、きめの細かい 3D 情報を保存するためにボクセル表現が広く使用されています。検出タスクでは、ほとんどのオブジェクトが同じ水平面上にあり、重なりが小さいため、BEV 表現が推奨されます。
BEV 表現と比較すると、ボクセル表現は優れていますが、効率は劣ります。さらに、多くの高度なオペレータは主に 2D フィーチャ向けに設計および最適化されているため、3D ボクセル表現との統合はそれほど単純ではありません。 BEV 表現は時間とメモリの効率が高くなりますが、高さ次元の構造情報が失われるため、密な空間予測には最適ではありません。特徴の表現に加えて、認識タスクが異なれば、データ形式と目標も異なります。したがって、マルチタスク 3D 認識フレームワークのトレーニングの均一性と効率を確保することは、大きな課題です。
UniVision ネットワーク構造UniVision フレームワークの全体構造を図 1 に示します。このフレームワークは、周囲の N 台のカメラからのマルチビュー画像を入力として受け取り、画像特徴抽出ネットワークを通じて画像特徴を抽出します。次に、深度ガイドによる明示的な特徴強調とクエリによる暗黙的な特徴サンプリングを組み合わせた Ex-Im ビュー変換モジュールを使用して、2D 画像特徴が 3D ボクセル特徴にアップグレードされます。ボクセル特徴は、ローカル グローバル特徴抽出および融合ブロックによって処理され、ローカル コンテキスト認識ボクセル特徴とグローバル コンテキスト認識 BEV 特徴がそれぞれ抽出されます。その後、相互表現特徴相互作用モジュールを通じて、さまざまな下流の知覚タスクのためにボクセル特徴と BEV 特徴の間で情報が交換されます。トレーニング段階では、UniVision フレームワークは、Occ-Det データ強化と損失重みの段階的な調整を組み合わせて効果的にトレーニングする戦略を採用します。
1) Ex-Im View Transform
深度指向の明示的な機能強化。ここでは LSS アプローチに従います:
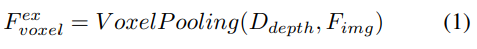
#2) クエリガイドによる暗黙的な特徴サンプリング。ただし、3D 情報の表現にはいくつかの欠点があります。の精度は、推定された深度分布の精度と高い相関があります。さらに、LSS によって生成されるポイントは均一に分配されません。ポイントはカメラの近くでは密集しており、遠くでは疎になります。したがって、クエリガイドによる特徴サンプリングをさらに使用して、上記の欠点を補います。
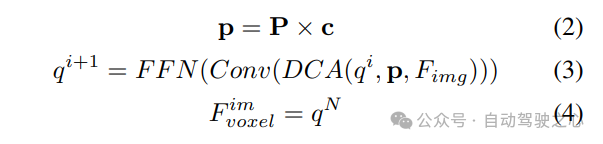
LSS から生成されたポイントと比較して、ボクセル クエリは 3D 空間に均一に分散されており、すべてのトレーニング サンプルの統計的特性から学習されます。これは深度に一致します。 LSS で使用される事前情報は無関係です。したがって、相互に補完し、ビュー変換モジュールの出力特徴としてそれらを接続します。
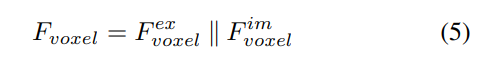
#2) ローカルおよびグローバル特徴の抽出と融合
与えられた入力ボクセル特徴を、最初に Z 軸上に特徴をオーバーレイし、畳み込み層を使用してチャネルを削減し、BEV 特徴を取得します。
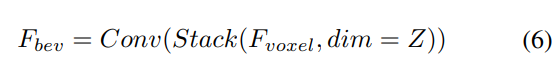
次に、モデル特徴抽出と拡張のために 2 つの並列ブランチに分割されます。ローカル特徴抽出、グローバル特徴抽出、そして最後の相互表現特徴相互作用!図 1(b) に示すように。
#3) 損失関数と検出ヘッド
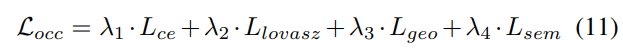
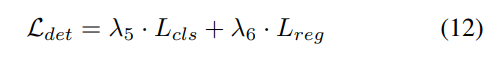
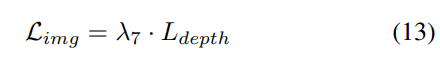
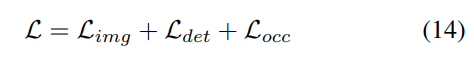
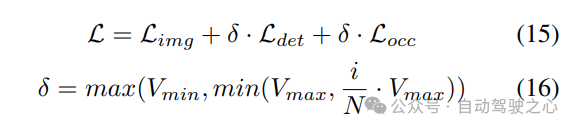
4) 結合された Occ-Det 空間データ強化
3D 検出タスクでは、一般的な画像レベルのデータ強化に加えて、空間レベルのデータ強化もモデルのパフォーマンスを向上させるのに効果的です。ただし、占有タスクに空間レベルの強化を適用するのは簡単ではありません。データ拡張 (ランダムなスケーリングや回転など) を個別の占有ラベルに適用する場合、結果として得られるボクセルのセマンティクスを判断するのは困難です。したがって、既存の方法では、占有タスクにおけるランダムな反転などの単純な空間拡張のみが適用されます。この問題を解決するために、UniVision は、フレームワーク内の 3D 検出タスクと占有タスクの同時強化を可能にする共同 Occ-Det 空間データ強化を提案しています。 3D ボックスのラベルは連続値であり、強化された 3D ボックスはトレーニング用に直接計算できるため、検出には BEVDet の強化方法に従います。占有ラベルは離散的で操作が困難ですが、ボクセル フィーチャは連続的なものとして扱うことができ、サンプリングや補間などの操作を通じて処理できます。したがって、データ拡張のために占有ラベルを直接操作するのではなく、ボクセル フィーチャを変換することをお勧めします。
具体的には、まず空間データ拡張がサンプリングされ、対応する 3D 変換行列が計算されます。占有ラベルとそのボクセル インデックス について、その 3 次元座標を計算します。次に、それを適用して正規化して、拡張ボクセル機能のボクセル インデックスを取得します :
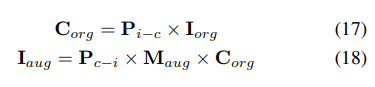
#実験結果の比較
検証には、NuScenes LiDAR セグメンテーション、NuScenes 3D オブジェクト検出、OpenOccupancy、Occ3D の複数のデータ セットを使用しました。 NuScenes LiDAR セグメンテーション: 最近の OccFormer および TPVFormer によると、カメラ画像は LIDAR セグメンテーション タスクの入力として使用され、LIDAR データは出力フィーチャをクエリするための 3D 位置を提供するためにのみ使用されます。評価指標として mIoU を使用します。 NuScenes 3D オブジェクト検出: 検出タスクには、nuScenes の公式メトリックである nuScene 検出スコア (NDS) を使用します。これは、平均 mAP と、平均変換誤差 (ATE) を含むいくつかのメトリックの加重合計です。平均スケール誤差 (ASE)、平均配向誤差 (AOE)、平均速度誤差 (AVE)、および平均属性誤差 (AAE)。 OpenOccupancy: OpenOccupancy ベンチマークは nuScenes データセットに基づいており、512×512×40 の解像度でセマンティック占有ラベルを提供します。ラベル付けされたクラスは、評価指標として mIoU を使用する LIDAR セグメンテーション タスクのクラスと同じです。 Occ3D: Occ3D ベンチマークは nuScenes データセットに基づいており、200×200×16 解像度でセマンティック占有ラベルを提供します。 Occ3D はさらに、トレーニングと評価用の可視マスクを提供します。ラベル付けされたクラスは、評価指標として mIoU を使用する LIDAR セグメンテーション タスクのクラスと同じです。1) Nuscenes LiDAR セグメンテーション
表 1 は、nuScenes LiDAR セグメンテーション ベンチマークの結果を示しています。 UniVision は、最先端のビジョンベース手法である OccFormer を 1.5% mIoU 上回り、リーダーボードにおけるビジョンベースのモデルの新記録を樹立しました。特に、UniVision は、PolarNe や DB-UNet などの一部の LIDAR ベースのモデルよりも優れたパフォーマンスを発揮します。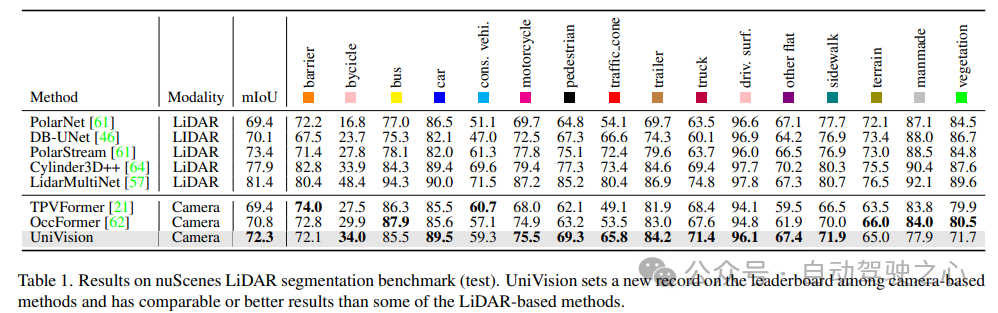
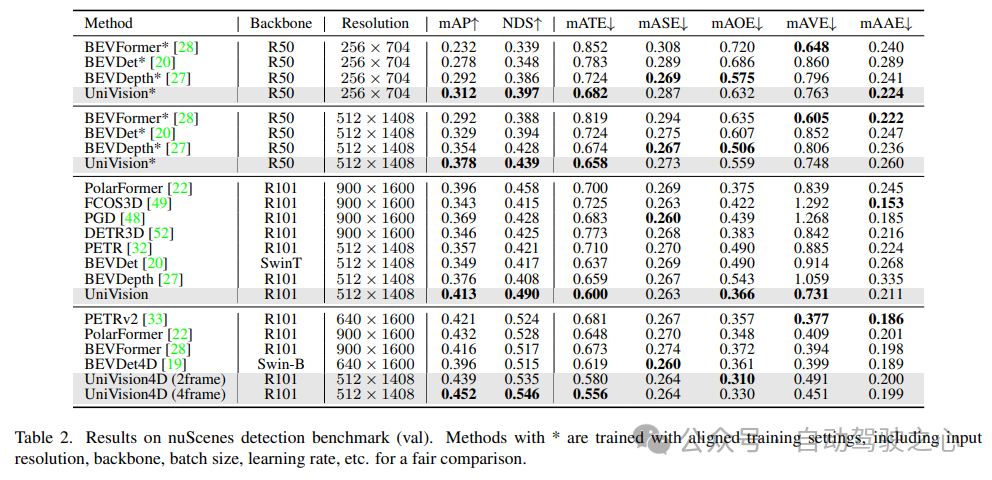
表 2 に示すように、公平な比較に同じトレーニング設定を使用する場合、 UniVision は他の方法よりも優れたパフォーマンスを発揮することが示されました。 512×1408 の画像解像度での BEVDepth と比較して、UniVision は mAP と NDS でそれぞれ 2.4% と 1.1% の向上を達成します。モデルをスケールアップし、UniVision を時間入力と組み合わせると、SOTA ベースの時間検出器を大幅に上回ります。 UniVision は、CBGS を使用せず、より小さい入力解像度でこれを実現します。
OpenOccupancy ベンチマーク テストの結果を表 3 に示します。 UniVision は、MonoScene、TPVFormer、C-CONet などの最近のビジョンベースの占有方法よりも、mIoU の点でそれぞれ 7.3%、6.5%、1.5% 大幅に優れています。さらに、UniVision は、LMSCNet や JS3C-Net などの LIDAR ベースのメソッドよりも優れたパフォーマンスを発揮します。
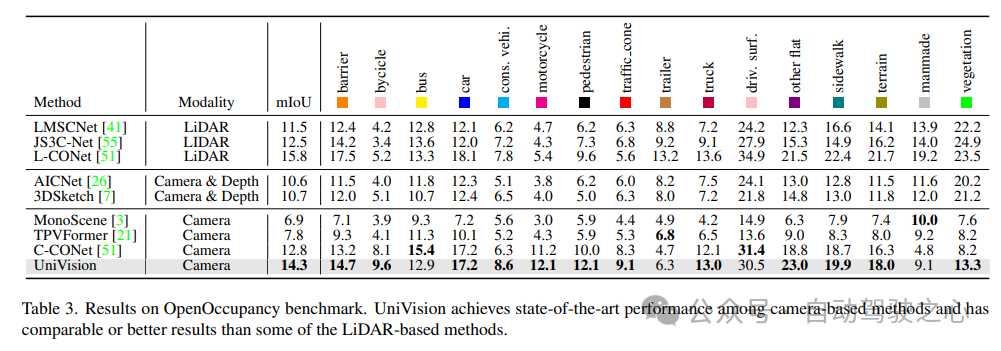
表 4 に、Occ3D ベンチマーク テストの結果を示します。 UniVision は、さまざまな入力画像解像度での mIoU の点で、最近のビジョンベースの手法よりも、それぞれ 2.7% および 1.8% 以上大幅に優れています。 BEVFormer と BEVDet-stereo は、事前にトレーニングされた重みをロードし、推論で時間入力を使用しますが、UniVision はそれらを使用しませんが、それでもより良いパフォーマンスを達成することに注目する価値があります。
5) 検出タスクにおけるコンポーネントの有効性
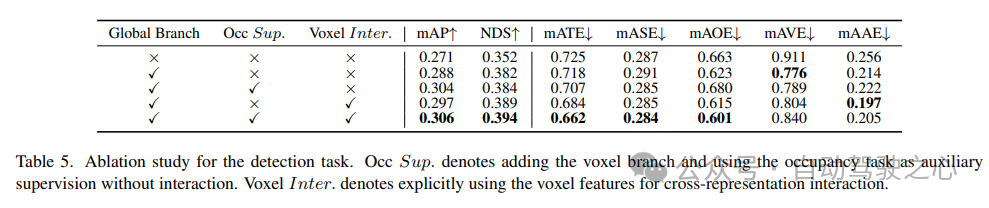
検出タスクに関するアブレーション研究を表 5 に示します。 BEV ベースのグローバル特徴抽出ブランチがベースライン モデルに挿入されると、パフォーマンスは mAP で 1.7%、NDS で 3.0% 向上します。ボクセルベースの占有タスクが補助タスクとして検出器に追加されると、モデルの mAP ゲインは 1.6% 増加します。相互表現相互作用がボクセル特徴から明示的に導入されると、モデルは最高のパフォーマンスを達成し、ベースラインと比較して mAP と NDS をそれぞれ 3.5% と 4.2% 改善します;
6) 占有タスクにおけるコンポーネントの有効性
占有タスクのアブレーション研究を表 6 に示します。ボクセルベースのローカル特徴抽出ネットワークにより、ベースライン モデルに対して 1.96% の mIoU ゲインの向上がもたらされます。検出タスクが補助監視信号として導入されると、モデルのパフォーマンスは 0.4%mIoU 向上します。

7) その他
表 5 と表 6 は、UniVision フレームワークにおいて、検出タスクと占有タスクが相互に補完していることを示しています。の。検出タスクの場合、占有監視により mAP および mATE メトリクスが改善され、ボクセルのセマンティック学習により、オブジェクトの幾何学形状、つまり中心性とスケールに対する検出器の認識が効果的に向上することが示されています。占有タスクの場合、検出監視により前景カテゴリ (つまり、検出カテゴリ) のパフォーマンスが大幅に向上し、全体的な向上が得られます。
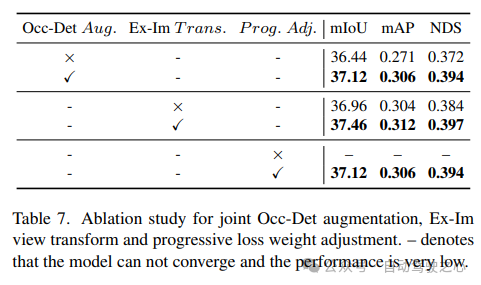
Occ-Det 空間強調、Ex-Im ビュー変換モジュール、および漸進的損失重量調整戦略を組み合わせた効果を表 7 に示します。提案された空間拡張と提案されたビュー変換モジュールにより、mIoU、mAP、NDS メトリックに関する検出タスクと占有タスクが大幅に改善されました。減量調整戦略は、マルチタスク フレームワークを効果的にトレーニングできます。これがないと、統合フレームワークのトレーニングは収束できず、パフォーマンスが非常に低くなります。
参考
紙のリンク: https://arxiv.org/pdf/2401.06994.pdf
論文のタイトル: UniVision: ビジョン中心の 3D 認識のための統合フレームワーク
以上が比類のない UniVision: BEV 検出と Occ 統合統合フレームワーク、デュアル SOTA!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1663
1663
 14
1419
52
1313
25
1264
29
1237
24
14
1419
52
1313
25
1264
29
1237
24

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
原題: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving 論文リンク: https://arxiv.org/pdf/2402.02519.pdf コードリンク: https://github.com/HKUST-Aerial-Robotics/SIMPL 著者単位: 香港科学大学DJI 論文のアイデア: この論文は、自動運転車向けのシンプルで効率的な動作予測ベースライン (SIMPL) を提案しています。従来のエージェントセントとの比較
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
