

Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?

Stable Diffusion 3 の論文がついに登場しました!
このモデルは2週間前にリリースされ、Soraと同じDiT (Diffusion Transformer) アーキテクチャを採用しており、リリースと同時に大きな話題を呼びました。
以前のバージョンと比較して、Stable Diffusion 3 で生成される画像の品質が大幅に向上し、マルチテーマのプロンプトをサポートし、テキストの書き込み効果も向上しました。文字化けもなくなりました。
安定性 AI は、Stable Diffusion 3 が 800M から 8B の範囲のパラメーター サイズを持つ一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、大規模な AI モデルを使用するための敷居を大幅に下げます。
新しくリリースされた論文の中で、Stability AI は、人間の好みに基づく評価において、Stable Diffusion 3 は、次のような現在の最先端のテキストから画像への生成システムよりも優れたパフォーマンスを示したと述べています。 DALL・E 3. Midjourney v6 および Ideogram v1。間もなく、研究の実験データ、コード、モデルの重みが公開される予定です。
論文の中で、Stability AI は Stable Diffusion 3 の詳細を明らかにしました。

- 論文タイトル: 高解像度画像合成のための整流変圧器のスケーリング
- ##論文リンク: https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable Diffusion 3 Paper.pdf ##アーキテクチャの詳細
テキストから画像への生成では、Stable Diffusion 3 モデルはテキスト モードと画像モードの両方を考慮する必要があります。したがって、論文の著者は、複数のモダリティを処理できるこの新しいアーキテクチャを MMDiT と呼んでいます。以前のバージョンの Stable Diffusion と同様に、作成者は事前トレーニングされたモデルを使用して、適切なテキストおよび画像表現を導き出します。具体的には、3 つの異なるテキスト埋め込みモデル (2 つの CLIP モデルと T5) を使用してテキスト表現をエンコードし、改良された自動エンコーディング モデルを使用して画像トークンをエンコードしました。
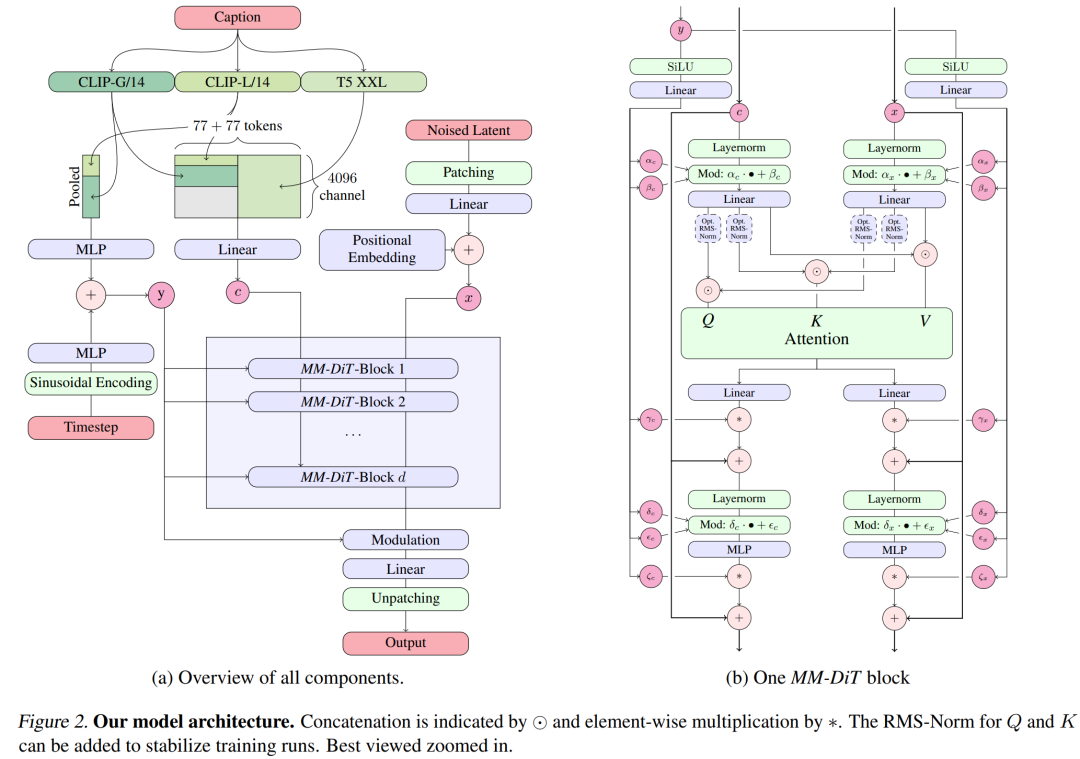 安定した Diffusion 3 モデル アーキテクチャ。
安定した Diffusion 3 モデル アーキテクチャ。
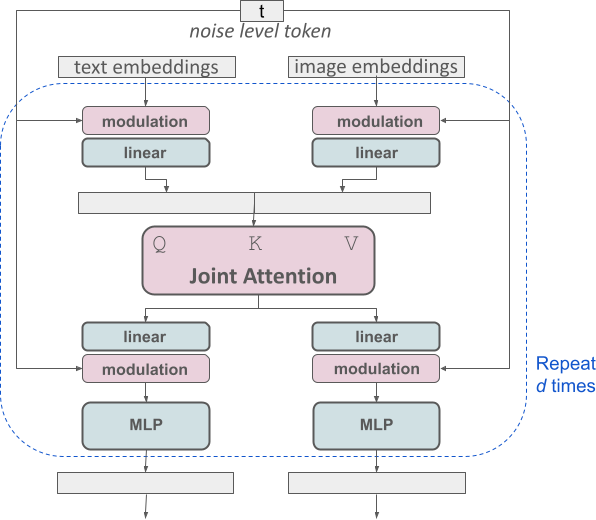 改良されたマルチモーダル拡散トランス: MMDiT ブロック。
改良されたマルチモーダル拡散トランス: MMDiT ブロック。
SD3 アーキテクチャは、Sora のコア研究開発メンバーである William Peebles とニューヨーク大学コンピュータ サイエンスの助教授である Xie Saining によって提案された DiT に基づいています。テキストの埋め込みと画像の埋め込みは概念的に大きく異なるため、SD3 の作成者は 2 つのモダリティに対して 2 つの異なる重みセットを使用しています。上の図に示すように、これはモダリティごとに 2 つの独立したトランスフォーマーを設定することに相当しますが、注意操作のために 2 つのモダリティのシーケンスを組み合わせて、両方の表現が独自の空間で機能できるようにします。別の表現も考慮されます。 。
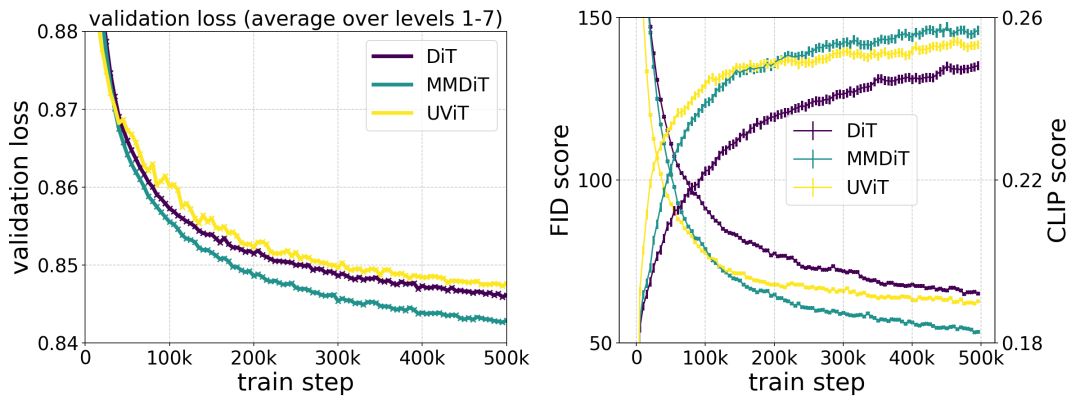 著者が提案した MMDiT アーキテクチャは、画像バックボーンに対する視覚的な忠実度やテキストの配置をトレーニング中に測定する際に、UViT や DiT などの成熟したテキスト フレームワークよりも優れています。
著者が提案した MMDiT アーキテクチャは、画像バックボーンに対する視覚的な忠実度やテキストの配置をトレーニング中に測定する際に、UViT や DiT などの成熟したテキスト フレームワークよりも優れています。
このようにして、画像トークンとテキスト トークンの間で情報をやり取りできるため、モデルの全体的な理解が向上し、生成された出力のタイポグラフィーが向上します。論文で説明したように、このアーキテクチャはビデオなどの複数のモダリティにも簡単に拡張できます。
 Stable Diffusion 3 の改善されたプロンプト追従機能のおかげで、新しいモデルは、さまざまなテーマや品質に焦点を当てた画像を生成する機能を備えています。 , 同時に、画像自体のスタイルも高い柔軟性で扱うことができます。
Stable Diffusion 3 の改善されたプロンプト追従機能のおかげで、新しいモデルは、さまざまなテーマや品質に焦点を当てた画像を生成する機能を備えています。 , 同時に、画像自体のスタイルも高い柔軟性で扱うことができます。

再重み付けによる整流の改善
Stable Diffusion 3 は整流 (RF) 式を使用します。 , データとノイズは直線的な軌跡で結ばれます。これにより、推論パスがより直線になり、サンプリング ステップが削減されます。さらに、著者らはトレーニング プロセス中に新しい軌道サンプリング スキームも導入しています。彼らは、軌道の中間部分ではより困難な予測タスクが課せられるだろうと仮説を立て、そのため、このスキームでは軌道の中間部分により多くの重みを与えました。彼らは、複数のデータセット、メトリクス、サンプラー設定を使用して比較し、LDM、EDM、ADM などの他の 60 の拡散軌跡に対して提案された方法をテストしました。結果は、以前の RF 配合のパフォーマンスはサンプリング ステップが少ないと向上しますが、ステップ数が増えると相対的なパフォーマンスが低下することを示しています。対照的に、著者らが提案した再重み付けされた RF バリアントは一貫してパフォーマンスを向上させます。
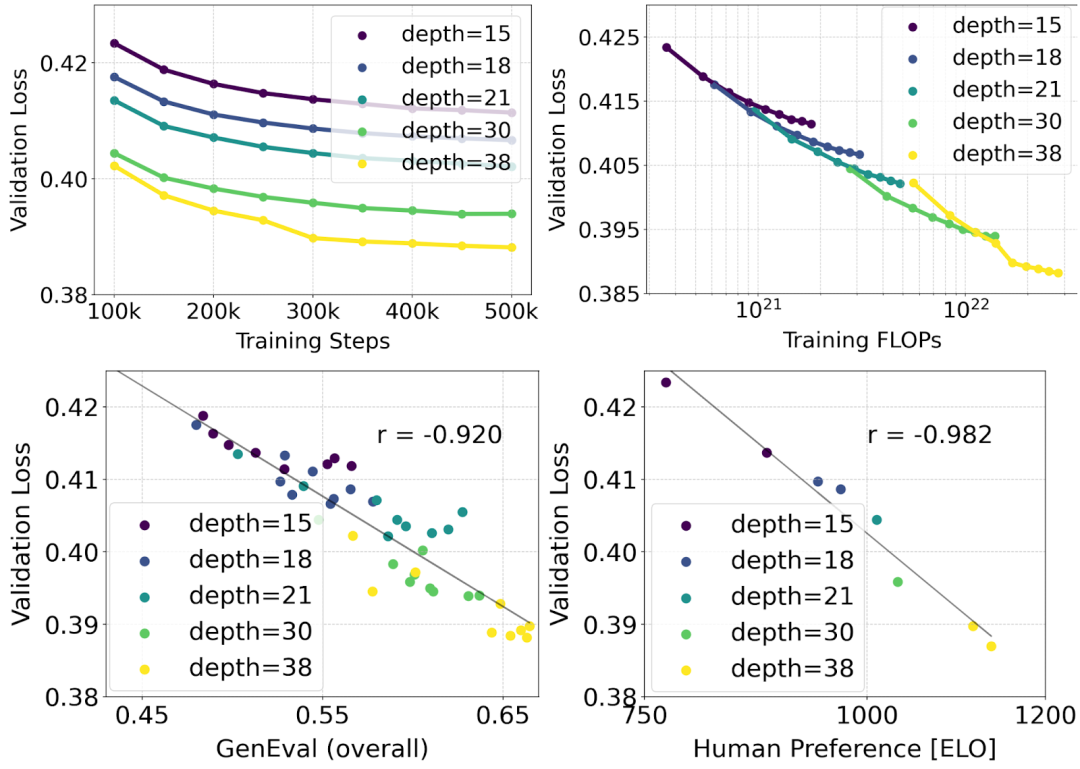
拡張整流変圧器モデル
著者は、再重み付けされた整流式と MMDiT バックボーン ペアを使用しています。テキストと画像の合成はスケーリングで研究されます。彼らは、4 億 5,000 万個のパラメータを持つ 15 ブロックから 8B パラメータを持つ 38 ブロックまでの範囲のモデルをトレーニングし、モデル サイズとトレーニング ステップが増加するにつれて検証損失が滑らかに減少することを観察しました (上の図の最初の部分は OK)。これがモデル出力の有意義な改善につながったかどうかを調べるために、著者らは自動画像位置合わせメトリクス (GenEval) と人間の好みのスコア (ELO) (上の 2 行目) も評価しました。結果は、これらのメトリクスと検証損失の間に強い相関関係があることを示しており、後者がモデルの全体的なパフォーマンスの優れた予測因子であることを示唆しています。さらに、スケーリングの傾向には飽和の兆候が見られないため、著者らは将来的にモデルのパフォーマンスを改善し続けることについて楽観的になっています。
柔軟なテキスト エンコーダ
メモリを大量に消費する推論用の 4.7B パラメータ T5 テキスト エンコーダを削除することで、最小限のパフォーマンスで SD3 メモリ需要を大幅に削減できます。損失。示されているように、このテキスト エンコーダーを削除しても、見た目の美しさには影響がなく (T5 なしの勝率 50%)、テキストの一貫性がわずかに低下するだけです (勝率 46%)。ただし、著者らは、SD3 のパフォーマンスを最大限に活用するために、書かれたテキストを生成するときに T5 を追加することを推奨しています。これは、次の図に示すように、T5 を追加しないと組版生成のパフォーマンスがさらに低下する (勝率 38%) ことが観察されたためです。

推論のために T5 を削除しても、多くの詳細または大量のテキストが含まれる非常に複雑なプロンプトを表示する場合、パフォーマンスが大幅に低下するだけです。上の画像は、各例の 3 つのランダムなサンプルを示しています。
モデルのパフォーマンス
著者は、Stable Diffusion 3 の出力イメージを他のさまざまなオープンソース モデル (SDXL、SDXL Turbo、Stable など) と比較しました。 Cascade、Playground v2.5、Pixart-α)、および DALL-E 3、Midjourney v6、Ideogram v1 などのクローズドソース モデルを比較して、人間のフィードバックに基づいてパフォーマンスを評価しました。これらのテストでは、人間の評価者に各モデルからの出力例が与えられ、モデルの出力が指定されたプロンプトのコンテキストにどの程度準拠しているか (プロンプト追従)、テキストがプロンプトに従ってどの程度適切にレンダリングされているか (タイポグラフィ) について判断されます。画像 最良の結果を得るには、視覚的に優れた画像が選択されます。
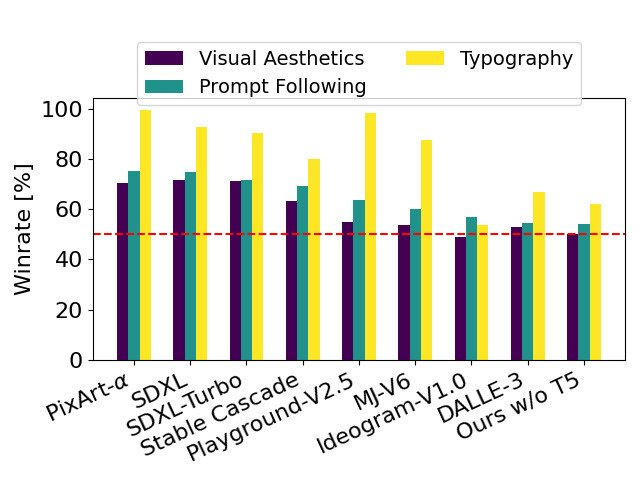
#SD3 をベンチマークとして使用し、このグラフは、視覚的な美しさ、プロンプトのフォロー、テキスト レイアウトに関する人間の評価に基づいた勝率の概要を示しています。
テスト結果から、著者は Stable Diffusion 3 が現在の最先端のテキストから画像への生成システムと同等かそれ以上であることを発見しました。上記の側面。
コンシューマ ハードウェアでの初期の最適化されていない推論テストでは、最大の 8B パラメータの SD3 モデルが RTX 4090 の 24GB VRAM に適合し、50 のサンプリング ステップを使用して 1024x1024 の解像度の画像を生成するのに 34 秒かかりました。

さらに、初期リリースでは、ハードウェアの障壁をさらに排除するために、Stable Diffusion 3 は 800m から 8B パラメトリック モデルまでの複数のバリエーションで利用可能になります。


#詳細については、元の論文を参照してください。
参考リンク:https://stability.ai/news/stable-diffusion-3-research-paper
以上がStable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7474
7474
 15
1377
52
77
11
19
31
15
1377
52
77
11
19
31

 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 バングラ部分モデル検索のlaravelEloquent orm)
Apr 08, 2025 pm 02:06 PM
バングラ部分モデル検索のlaravelEloquent orm)
Apr 08, 2025 pm 02:06 PM
LaravelEloquentモデルの検索:データベースデータを簡単に取得するEloquentormは、データベースを操作するための簡潔で理解しやすい方法を提供します。この記事では、さまざまな雄弁なモデル検索手法を詳細に紹介して、データベースからのデータを効率的に取得するのに役立ちます。 1.すべてのレコードを取得します。 ALL()メソッドを使用して、データベーステーブルですべてのレコードを取得します:useapp \ models \ post; $ post = post :: all();これにより、コレクションが返されます。 Foreach Loopまたはその他の収集方法を使用してデータにアクセスできます。
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
