

Googleが最新の「画面読み上げ」AIを公開! PaLM 2-S はデータを自動的に生成し、複数の理解タスクが SOTA を更新します

誰もが望む大きなモデルは、真にインテリジェントなモデルです...
Google チームは強力な「スクリーン リーディング」を開発しますあい。
研究者らはこれを ScreenAI と呼んでおり、ユーザー インターフェイスとインフォグラフィックスを理解するための新しい視覚言語モデルです。

論文アドレス: https://arxiv.org/pdf/2402.04615.pdf
ScreenAIその中心となるのは、UI 要素のタイプと位置を認識する新しいスクリーンショット テキスト表現メソッドです。
研究者らは、Google 言語モデル PaLM 2-S を使用して合成トレーニング データを生成しました。このデータは、画面情報、画面ナビゲーション、画面コンテンツに関連する質問に答えるようにモデルをトレーニングするために使用されました。概要、質問。この方法は、画面関連のタスクを処理する際のモデルのパフォーマンスを向上させるための新しいアイデアを提供することは注目に値します。

たとえば、音楽 APP ページを開いた場合、「30 秒未満の曲は何曲ありますか?」と尋ねることができます。
ScreenAI はシンプルな答えを出しました: 1.
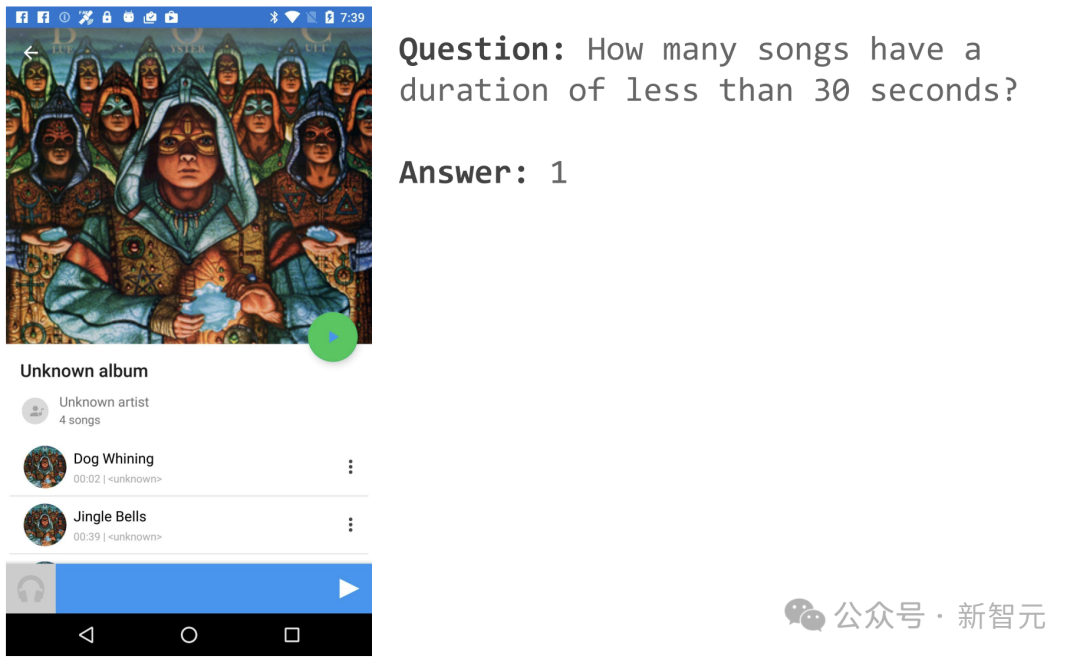
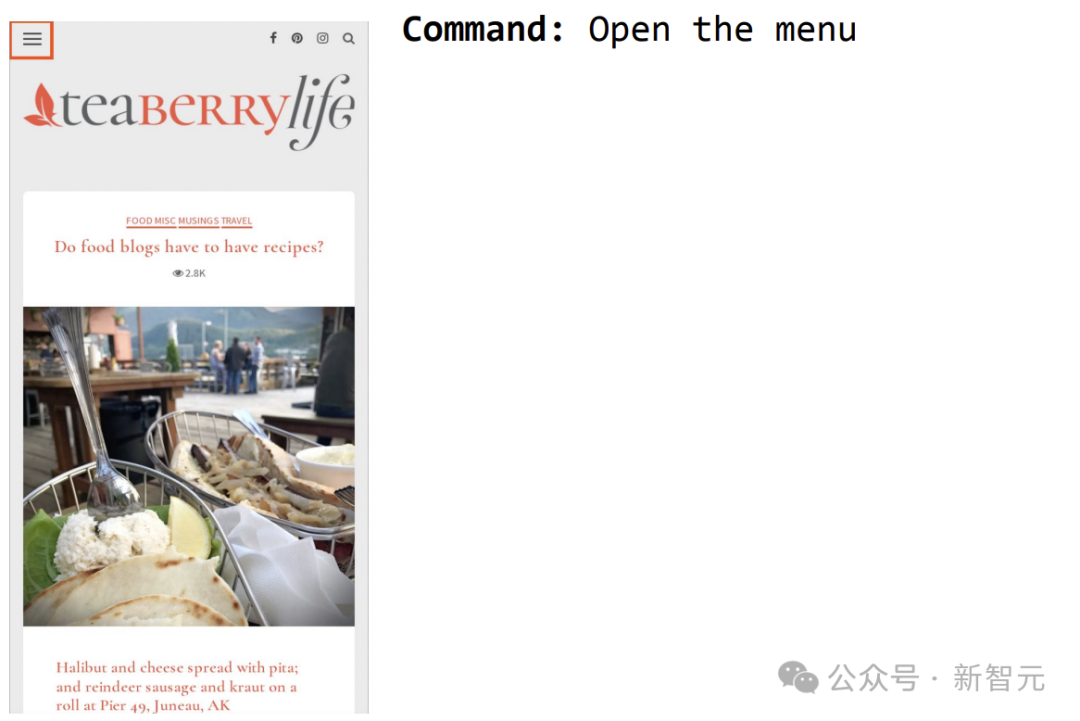
もう 1 つの例は、ScreenAI にメニューを開くように命令し、それを選択できるようにすることです。
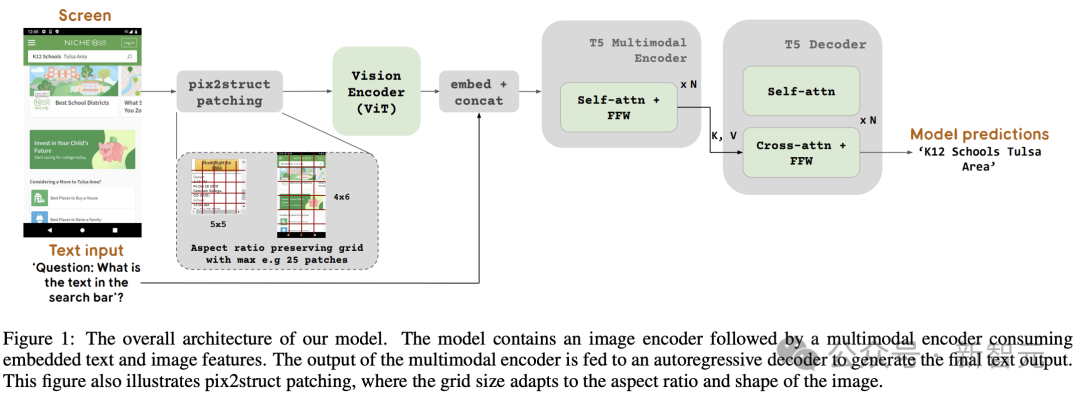
# アーキテクチャのインスピレーションの源 - PaLI
図 1 は、ScreenAI モデルのアーキテクチャを示しています。研究者らは、マルチモーダル エンコーダー ブロックで構成される PaLI モデル ファミリのアーキテクチャにインスピレーションを受けました。
エンコーダー ブロックには、ViT のようなビジュアル エンコーダーと、画像とテキスト入力を使用する mT5 言語エンコーダーと、それに続く自己回帰デコーダーが含まれています。
入力画像はビジュアル エンコーダーによって一連の埋め込みに変換され、入力テキストの埋め込みと結合されて mT5 言語エンコーダーに供給されます。
エンコーダーの出力はデコーダーに渡され、テキスト出力が生成されます。
この一般化された定式化では、同じモデル アーキテクチャを使用して、さまざまな視覚的タスクやマルチモーダル タスクを解決できます。これらのタスクは、テキスト画像 (入力) からテキスト (出力) への問題として再定式化できます。
テキスト入力と比較して、画像の埋め込みはマルチモーダル エンコーダーへの入力長の重要な部分を占めます。
つまり、このモデルは画像エンコーダーと言語エンコーダーを使用して画像とテキストの特徴を抽出し、その 2 つを融合してデコーダーに入力してテキストを生成します。
#この構築方法は、画像理解などのマルチモーダルなタスクに広く適用できます。
元の PaLI アーキテクチャは、入力画像を処理するために固定グリッド パターンの画像パッチのみを受け入れます。ただし、スクリーン関連分野の研究者は、さまざまな解像度とアスペクト比にわたるデータに遭遇します。
単一のモデルをすべての画面形状に適応させるには、さまざまな形状の画像に機能するタイリング戦略を使用する必要があります。
この目的を達成するために、Google チームは Pix2Struct で導入されたテクノロジーを借用しました。これにより、入力画像の形状と事前定義された最大ブロック数に基づいて、任意のグリッド形状の画像ブロックを生成できます。 、図 1 に示すように。
これにより、形状を固定するために画像をパディングしたり引き伸ばしたりすることなく、さまざまな形式とアスペクト比の入力画像に適応できるため、モデルの汎用性が高まり、動きを同時に処理できるようになります 画像形式デバイス (つまり、縦向き) とデスクトップ (つまり、横向き) の場合。
#モデル構成
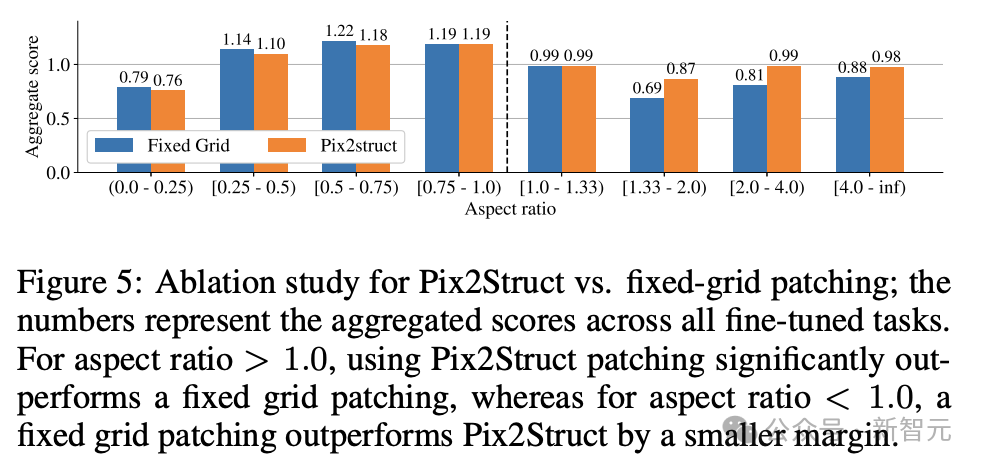
研究者らは、670M、2B、および 5B のパラメーターを含む、異なるサイズの 3 つのモデルをトレーニングしました。 670M および 2B パラメータ モデルの場合、研究者は、ビジュアル エンコーダおよびエンコーダ デコーダ言語モデル用の事前トレーニング済みのユニモーダル チェックポイントから開始しました。 5B パラメーター モデルの場合は、PaLI-3 のマルチモーダル事前トレーニング チェックポイントから開始します。ここでは、ViT が UL2 ベースのエンコーダー/デコーダー言語モデルでトレーニングされます。 視覚モデルと言語モデル間のパラメータ分布を表 1 に示します。 自動データ生成 研究者によると、モデルの事前作成は次のとおりです。開発 トレーニング段階は、大規模で多様なデータセットへのアクセスに大きく依存します。 ただし、大規模なデータセットに手動でラベルを付けるのは現実的ではないため、Google チームの戦略はデータを自動的に生成することです。 このアプローチでは、専門化された小規模モデルを利用しており、それぞれのモデルはデータを効率的かつ高精度で生成してラベル付けすることに優れています。 手動アノテーションと比較して、この自動化されたアプローチは効率的で拡張性があるだけでなく、一定レベルのデータの多様性と複雑性も保証します。 最初のステップは、テキスト要素、さまざまな画面コンポーネント、およびそれらの全体的な構造と階層をモデルに包括的に理解させることです。この基本的な理解は、モデルがさまざまなユーザー インターフェイスを正確に解釈して操作できるようにするために重要です。 ここでは、研究者がアプリケーションや Web ページをクロールして、デスクトップ、モバイル デバイス、タブレットなどのさまざまなデバイスから大量のスクリーンショットを収集しました。 これらのスクリーンショットには、UI 要素、その空間的関係、その他の説明情報を説明する詳細なタグが付けられます。 さらに、事前トレーニング データにさらに多様性を注入するために、研究者らは言語モデル、特に PaLM 2-S の力を活用して、2 段階で QA ペアを生成しました。 まず、前述の画面モードを生成します。次に、作成者は、言語モデルが合成データを生成するようにガイドするための画面パターンを含むプロンプトを設計します。 数回繰り返した後、付録 C に示すように、必要なタスクを効果的に生成するヒントを特定できます。 #これらの生成された応答の品質を評価するために、研究者は、応答のサブセットに対して手動検証を実行しました。データを使用して、所定の品質要件が満たされていることを確認します。 この方法を図 2 で説明します。これにより、事前トレーニング データセットの深さと幅が大幅に向上します。 これらのモデルの自然言語処理機能を活用し、構造化された画面パターンと組み合わせることで、さまざまなユーザー インタラクションやシナリオをシミュレートできます。 次に、研究者は、次の 2 つの異なるタスクのセットを定義しました。モデル タスク: 事前トレーニング タスクの初期セットとその後の微調整タスクのセット。 これら 2 つのグループの違いは、主に 2 つの側面にあります。 - 実際のデータのソース: 微調整タスクの場合、ラベルは次のとおりです。人間の評価者による評価 提供または検証します。事前トレーニング タスクの場合、ラベルは自己教師あり学習方法を使用して推論されるか、他のモデルを使用して生成されます。 #- データセットのサイズ: 通常、事前トレーニング タスクには大量のサンプルが含まれているため、これらのタスクは、より拡張された一連のステップを通じてモデルをトレーニングするために使用されます。 混合データでは、データセットはそのサイズに比例して重み付けされ、各タスクに許可される最大重みが決まります。 言語処理から視覚的理解、Web ページのコンテンツ分析まで、マルチモーダル ソースをマルチタスク トレーニングに組み込むことで、モデルがさまざまなシナリオを効果的に処理できるようになり、モデル全体が強化されます。多用途性とパフォーマンス。 研究者は、さまざまなタスクとベンチマークを使用して、微調整中のモデルの品質を推定します。表 3 は、既存のプライマリ画面、インフォグラフィック、および文書理解のベンチマークを含む、これらのベンチマークをまとめたものです。 図 4 は、ScreenAI モデルのパフォーマンスを示し、さまざまなモデルと比較しています。画面上の最新の SOT 結果とインフォグラフィック関連タスクが比較されます。 ScreenAI がさまざまなタスクで優れたパフォーマンスを達成していることがわかります。 表 4 では、研究者らは OCR データを使用した単一タスクの微調整の結果を示しています。 QA タスクの場合、OCR を追加するとパフォーマンスが向上します (例: Complex ScreenQA、MPDocVQA、InfoVQA で最大 4.5%)。 ただし、OCR を使用すると入力長がわずかに増加するため、全体的なトレーニングが遅くなります。また、推論時に OCR 結果を取得する必要もあります。 さらに、研究者らは、6 億 7,000 万パラメータ、20 億パラメータ、50 億パラメータのモデル サイズを使用してシングルタスク実験を実施しました。 図 4 では、すべてのタスクでモデル サイズを増やすとパフォーマンスが向上し、最大規模での向上はまだ飽和していないことがわかります。 より複雑なビジュアル テキストと算術推論を必要とするタスク (InfoVQA、ChartQA、Complex ScreenQA など) の場合、20 億パラメータ モデルと 50 億パラメータ モデルの間で大幅な改善が見られます。 6.7 を超える 1 億パラメータ モデルと 20 億パラメータ モデル。 最後に、図 5 は、アスペクト比が 1.0 を超える画像 (ランドスケープ モード画像) の場合、pix2struct セグメンテーション戦略が固定グリッドよりも大幅に優れていることを示しています。セグメンテーション。 ポートレート モード画像の場合、傾向は逆ですが、固定グリッド セグメンテーションの方がわずかに優れているだけです。 研究者らは、ScreenAI モデルがさまざまなアスペクト比の画像で動作することを望んでいたため、pix2struct セグメンテーション戦略を使用することを選択しました。 Google の研究者らは、ScreenAI モデルも、GPT-4 や Gemini などのより大きなモデルにスケールダウンするには、いくつかのタスクについてさらなる研究が必要であると述べています。 。 
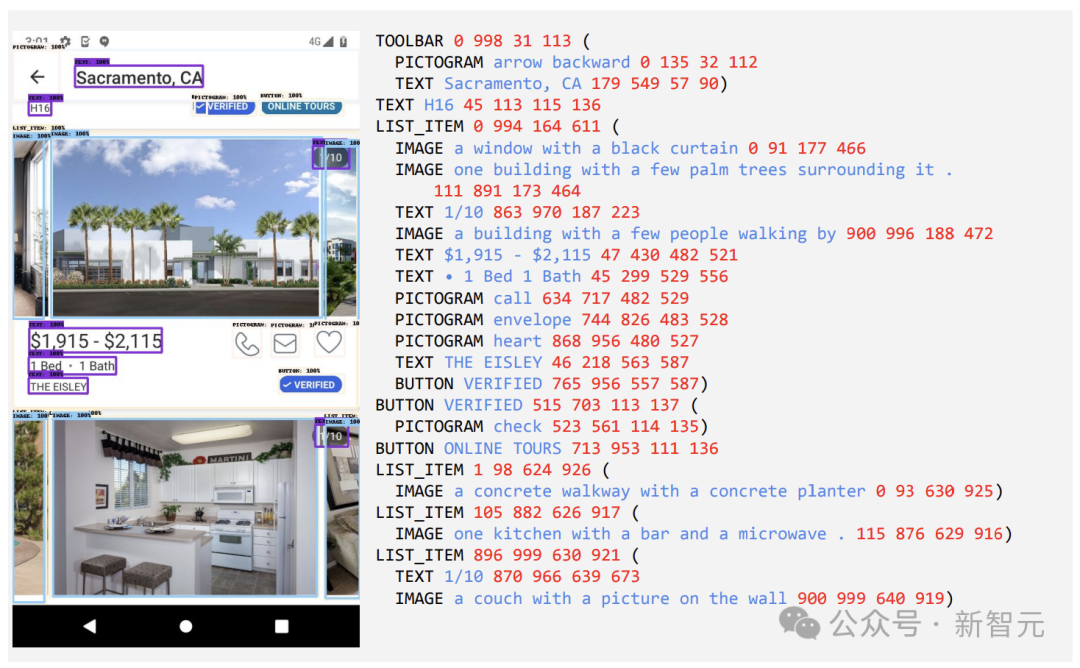
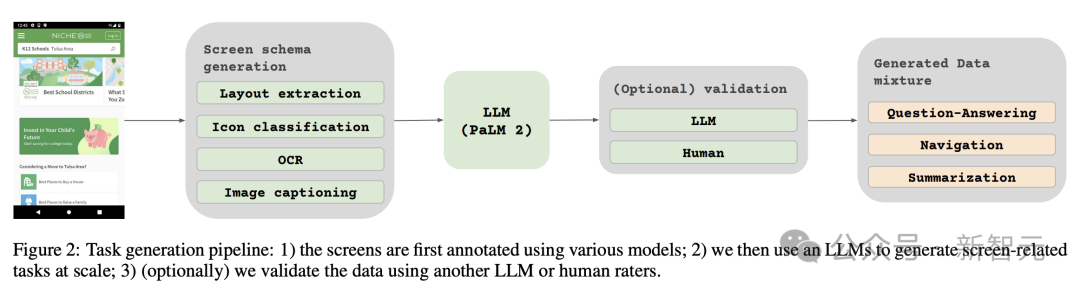
2 つの異なるタスクのセット



#実験結果
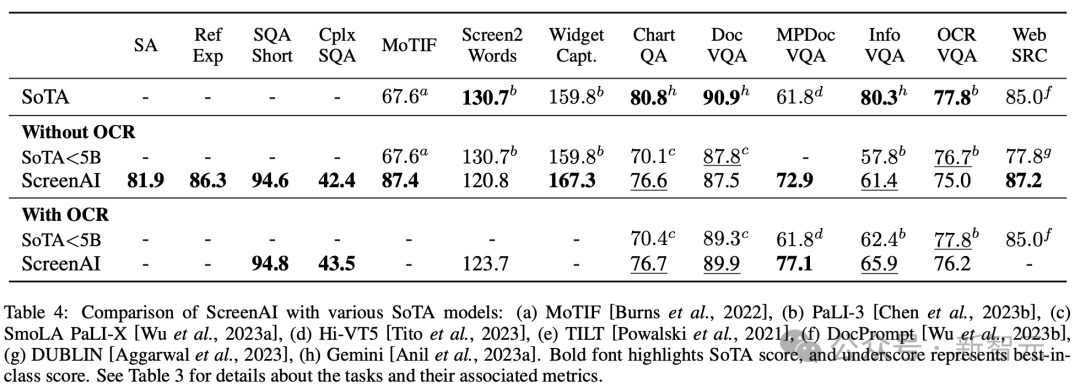
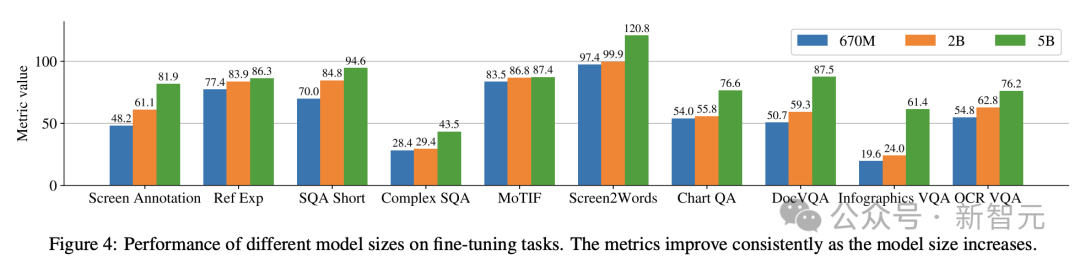
以上がGoogleが最新の「画面読み上げ」AIを公開! PaLM 2-S はデータを自動的に生成し、複数の理解タスクが SOTA を更新しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7530
7530
 15
1379
52
82
11
21
77
15
1379
52
82
11
21
77

 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
この記事では、DebianシステムのApachewebサーバーのロギングレベルを調整する方法について説明します。構成ファイルを変更することにより、Apacheによって記録されたログ情報の冗長レベルを制御できます。方法1:メイン構成ファイルを変更して、構成ファイルを見つけます。Apache2.xの構成ファイルは、通常/etc/apache2/ディレクトリにあります。ファイル名は、インストール方法に応じて、apache2.confまたはhttpd.confである場合があります。構成ファイルの編集:テキストエディターを使用してルートアクセス許可を使用して構成ファイルを開く(nanoなど):sudonano/etc/apache2/apache2.conf
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Debian OpenSSLでデジタル署名検証を実行する方法
Apr 13, 2025 am 11:09 AM
Debian OpenSSLでデジタル署名検証を実行する方法
Apr 13, 2025 am 11:09 AM
Debianシステムでのデジタル署名検証にOpenSSLを使用すると、次の手順に従うことができます。OpenSSL:Debianシステムがインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoaptupdatesudoaptinInstallopensslslに公開キーを取得できます。デジタル署名検証には、署名者の公開キーが必要です。通常、公開キーは、public_key.peなどのファイルの形で提供されます
 Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian Systemsでは、OpenSSLは暗号化、復号化、証明書管理のための重要なライブラリです。中間の攻撃(MITM)を防ぐために、以下の測定値をとることができます。HTTPSを使用する:すべてのネットワーク要求がHTTPの代わりにHTTPSプロトコルを使用していることを確認してください。 HTTPSは、TLS(Transport Layer Security Protocol)を使用して通信データを暗号化し、送信中にデータが盗まれたり改ざんされたりしないようにします。サーバー証明書の確認:クライアントのサーバー証明書を手動で確認して、信頼できることを確認します。サーバーは、urlsessionのデリゲート方法を介して手動で検証できます
