

Anything in Any Scene: リアルなオブジェクトの挿入 (さまざまな走行データの合成を支援するため)

元のタイトル: Anything in Any Scene: Photorealistic Video Object Insertion
論文リンク: https://arxiv.org/pdf/2401.17509.pdf
コード リンク: https ://github.com/AnythingInAnyScene/anything_in_anyscene
著者の所属: Xpeng Motors

#論文のアイデア
#Realisticビデオ シミュレーションは、仮想現実から映画制作に至るまでのアプリケーションにおいて大きな可能性を示しています。特に、現実世界でビデオをキャプチャすることが非現実的であるか、費用がかかる場合はそうです。ビデオ シミュレーションの既存の方法では、照明環境を正確にモデル化したり、オブジェクトのジオメトリを表現したり、高レベルのフォトリアリズムを達成したりできないことがよくあります。この論文は、既存のダイナミック ビデオに任意のオブジェクトをシームレスに挿入し、物理的なリアリズムを強調できる、斬新で多用途なリアル ビデオ シミュレーション フレームワークであるAnything in Any Scene を提案します。この論文で提案する全体的なフレームワークには、3 つの重要なプロセスが含まれています: 1) 現実のオブジェクトを特定のシーン ビデオに統合し、それらを適切な位置に配置して幾何学的なリアリズムを確保する; 2) 空と周囲の照明分布を推定し、実際の影をシミュレートして光のリアリズムを強化する; 3) スタイル転送ネットワークを使用して最終的なビデオ出力を調整し、写真のリアリズムを最大限に高めます。この記事では、Anything in Any Scene フレームワークが優れた幾何学的リアリズム、照明リアリズム、フォト リアリズムを備えたシミュレーション ビデオを生成できることを実験的に証明します。ビデオ データ生成に関連する課題を大幅に軽減することで、当社のフレームワークは、高品質のビデオを取得するための効率的でコスト効率の高いソリューションを提供します。さらに、そのアプリケーションはビデオ データの拡張をはるかに超えて拡張されており、仮想現実、ビデオ編集、その他のさまざまなビデオ中心のアプリケーションにおいて有望な可能性を示しています。
主な貢献
この論文では、あらゆるオブジェクトをあらゆる動的なシーン ビデオに統合できる、斬新で拡張可能な Anything in Any Scene ビデオ シミュレーション フレームワークを紹介します。 この記事は独自に構成されており、出力結果の高品質と信頼性を確保するために、ビデオ シミュレーションにおけるジオメトリ、ライティング、フォトリアリズムを維持することに重点を置いています。 広範な検証の結果、このフレームワークには非常に現実的なビデオ シミュレーションを生成する機能があり、この分野の適用範囲と開発の可能性が大幅に拡大されることがわかりました。論文デザイン
画像とビデオのシミュレーションは、仮想現実から映画制作に至るまで、さまざまなアプリケーションで成功を収めています。フォトリアリスティックな画像とビデオのシミュレーションを通じて多様で高品質のビジュアル コンテンツを生成できる機能は、これらの分野を進歩させ、新しい可能性とアプリケーションを導入する可能性を秘めています。現実世界で撮影された画像やビデオの信頼性は非常に貴重ですが、ロングテール配信によって制限されることがよくあります。これにより、一般的なシナリオが過剰に表現され、まれではあるが重大な状況が過小評価されることになり、分布外問題として知られる課題が生じます。ビデオのキャプチャと編集を通じてこれらの制限に対処する従来の方法は、考えられるすべてのシナリオをカバーすることが困難であるため、非現実的であるか、または法外なコストがかかることが判明しました。これらの課題を克服するには、特に既存のビデオと新しく挿入されたオブジェクトを統合することによるビデオ シミュレーションの重要性が重要になります。ビデオ シミュレーションは、大規模で多様かつリアルなビジュアル コンテンツを生成することで、仮想現実、ビデオ編集、およびビデオ データ拡張におけるアプリケーションの拡張に役立ちます。 しかし、物理的なリアリズムを考慮したリアルなシミュレーション ビデオを生成することは、依然として困難な未解決の問題です。既存の方法は、特定の設定、特に屋内環境に焦点を当てているため、制限が生じることがよくあります [9、26、45、46、57]。これらの方法では、さまざまな照明条件や高速で移動する物体などの屋外シーンの複雑さに十分に対処できない場合があります。 3D モデルの登録に依存する方法は、オブジェクトの限られたクラスの統合に限定されます [12、32、40、42]。多くの方法では、照明環境のモデリング、正しいオブジェクトの配置、リアリズムの達成などの重要な要素が無視されています [12、36]。失敗したケースを図 1 に示します。したがって、これらの制限により、自動運転やロボット工学など、拡張性が高く、幾何学的に一貫性があり、現実的なシーンのビデオ シミュレーションが必要な分野での応用が大幅に制限されます。 このペーパーでは、これらの課題に対処する、Anything in Any Scene にフォトリアリスティックなビデオ オブジェクトを挿入するための包括的なフレームワークを提案します。このフレームワークは多用途で屋内および屋外のシーンに適するように設計されており、幾何学的なリアリズム、照明のリアリズム、フォトリアリズムの点で物理的な精度を保証します。この論文の目標は、機械学習における視覚データの拡張に役立つだけでなく、仮想現実やビデオ編集などのさまざまなビデオ アプリケーションにも適したビデオ シミュレーションを作成することです。この記事の Anything in Any Scene フレームワークの概要を図 2 に示します。このペーパーでは、セクション 3 でシーン ビデオとオブジェクト メッシュの多様なアセット ライブラリを構築するための斬新でスケーラブルなパイプラインについて詳しく説明します。この文書では、説明的なキーワードを使用してビジュアル クエリから関連するビデオ クリップを効率的に取得するように設計されたビジュアル データ クエリ エンジンを紹介します。次に、この論文では、既存の 3D アセットとマルチビュー画像再構成を活用して 3D メッシュを生成する 2 つの方法を提案します。これにより、たとえそれが非常に不規則であったり、意味的に弱い場合でも、任意の目的のオブジェクトを無制限に挿入できます。セクション 4 では、物理的なリアリズムの維持に焦点を当て、オブジェクトを動的なシーン ビデオに統合する方法について詳しく説明します。この論文では、挿入されたオブジェクトが連続するビデオ フレームに安定して固定されるように、セクション 4.1 で説明されているオブジェクトの配置と安定化の方法を設計します。リアルな照明と影の効果を作成するという課題に対処するために、このペーパーでは、セクション 4.2 で説明されているように、空と環境の照明を推定し、レンダリング中にリアルな影を生成します。生成されたシミュレートされたビデオ フレームには、ノイズ レベル、色の忠実度、シャープネスなどの画質の違いなど、実際にキャプチャされたビデオとは異なる非現実的なアーチファクトが必然的に含まれます。この論文では、セクション 4.3 でスタイル転送ネットワークを使用して写真のリアリズムを強化します。
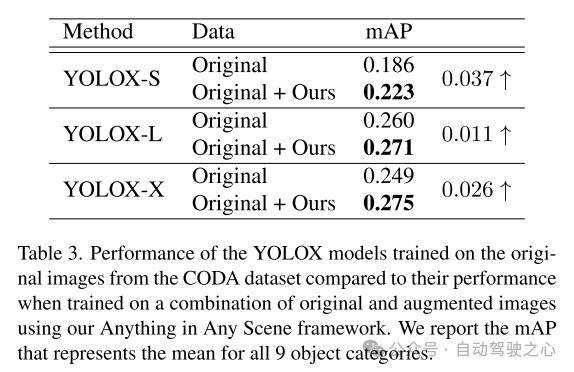
セクション 5.3 で示したように、この論文で提案したフレームワークから生成されたシミュレーション ビデオは、高度な照明リアリズム、幾何学的リアリズム、フォト リアリズムを実現し、質と量の両方で他のビデオを上回っています。この記事では、セクション 5.4 の知覚アルゴリズムのトレーニングにおけるこの記事のシミュレーション ビデオの適用をさらに実証し、その実用的な価値を検証します。 Anything in Any Scene フレームワークを使用すると、時間効率と現実的な視覚品質を備えたデータ拡張のための大規模で低コストのビデオ データセットの作成が可能になり、これによりビデオ データ生成の負担が軽減され、ロングテールとアウトオブビデオが改善される可能性があります。配布の課題。一般的なフレームワーク設計により、Anything in Any Scene フレームワークは、改良された 3D メッシュ再構成方法などの改良されたモデルと新しいモジュールを簡単に統合して、ビデオ シミュレーションのパフォーマンスをさらに向上させることができます。
 図 1. 照明環境の推定が不正確、オブジェクトの配置が不正確、テクスチャ スタイルが非現実的であるシミュレートされたビデオ フレームの例 これらの問題により、画像に物理的なリアリズムが欠けています。
図 1. 照明環境の推定が不正確、オブジェクトの配置が不正確、テクスチャ スタイルが非現実的であるシミュレートされたビデオ フレームの例 これらの問題により、画像に物理的なリアリズムが欠けています。 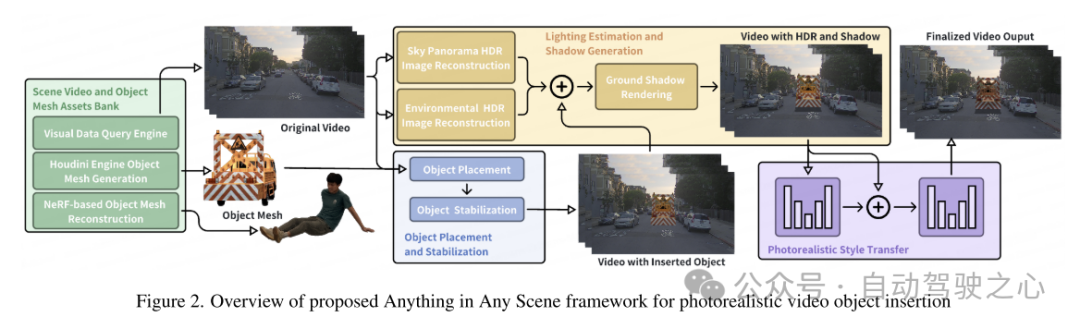 図 2. フォトリアリスティックなビデオ オブジェクト挿入のための Anything in Any Scene フレームワークの概要
図 2. フォトリアリスティックなビデオ オブジェクト挿入のための Anything in Any Scene フレームワークの概要  図 3. オブジェクト配置のための運転シーン ビデオの例。各画像内の赤い点は、オブジェクトが挿入された場所です。
図 3. オブジェクト配置のための運転シーン ビデオの例。各画像内の赤い点は、オブジェクトが挿入された場所です。
実験結果

図 4. 元の空の画像、再構成された HDR 画像、およびそれらに関連する太陽照度分布マップの例

図 5. 元の HDR 環境パノラマ画像と再構築された HDR 環境のパノラマ画像の例

図 6. 挿入されたオブジェクトの影の例

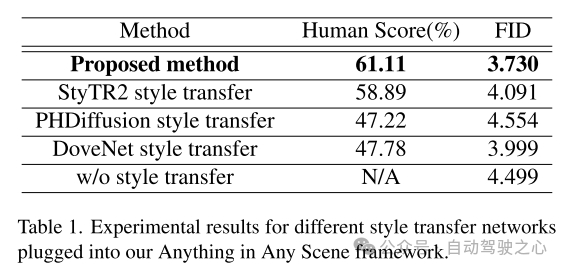
# 図 7. さまざまなスタイルの転送ネットワークを使用して PandaSet データセットからシミュレートされたビデオ フレームの定性的比較。

図 8. さまざまなレンダリング条件下で PandaSet データセットからシミュレートされたビデオ フレームの定性的比較。
要約:
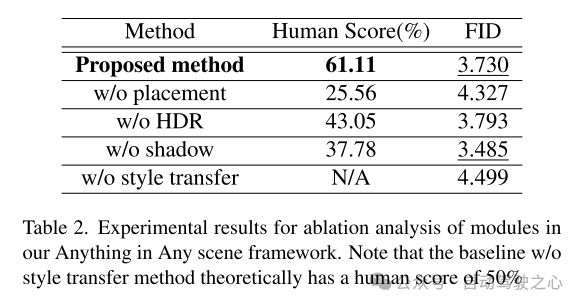
この文書では、リアルなビデオ シミュレーションとデザインのために設計された、革新的で拡張可能なフレームワーク「あらゆるシーンのあらゆるもの」を提案します。この論文で提案されているフレームワークは、さまざまなオブジェクトをさまざまなダイナミック ビデオにシームレスに統合し、幾何学的なリアリズム、照明のリアリズム、写真のリアリズムを確実に維持します。このペーパーでは、広範なデモンストレーションを通じて、ビデオ データの収集と生成に関連する課題を軽減する有効性を示し、さまざまなシナリオに対して費用対効果が高く、時間を節約できるソリューションを提供します。私たちのフレームワークを適用すると、下流の認識タスク、特に物体検出におけるロングテール分布問題の解決において大幅な改善が見られます。当社のフレームワークの柔軟性により、各モジュールの改善されたモデルを直接統合することができ、当社のフレームワークは、リアルなビデオ シミュレーションの分野における将来の探求と革新のための強固な基盤を築きます。
引用:
Bai C、Shao Z、Zhang G、他、「Anything in Any Scene: Photorealistic Video Object Insertion」[J]、arXiv プレプリント arXiv:2401.17509 、2024.
以上がAnything in Any Scene: リアルなオブジェクトの挿入 (さまざまな走行データの合成を支援するため)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7767
7767
 15
1644
14
1399
52
1293
25
1234
29
15
1644
14
1399
52
1293
25
1234
29

 OPPO Phoneで画面ビデオを録画する方法(簡単な操作)
May 07, 2024 pm 06:22 PM
OPPO Phoneで画面ビデオを録画する方法(簡単な操作)
May 07, 2024 pm 06:22 PM
ゲームのスキルや指導のデモンストレーションなど、日常生活では、操作手順を示すために携帯電話を使用して画面ビデオを録画する必要がよくあります。画面録画機能も非常に優れており、OPPO携帯電話は強力なスマートフォンです。録画タスクを簡単かつ迅速に完了できるように、この記事では、OPPO 携帯電話を使用して画面ビデオを録画する方法を詳しく紹介します。準備 - 録音の目標を決定する 開始する前に、録音の目標を明確にする必要があります。ステップバイステップのデモビデオを録画したいですか?それともゲームの素晴らしい瞬間を記録したいですか?それとも教育ビデオを録画したいですか?録音プロセスをより適切に調整し、明確な目標を設定することによってのみ可能です。 OPPO 携帯電話の画面録画機能を開き、ショートカット パネルで見つけます。 画面録画機能はショートカット パネルにあります。
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 Adobe After Effects cs6 (Ae cs6) で言語を切り替える方法 Ae cs6 で中国語と英語を切り替える詳細な手順 - ZOL ダウンロード
May 09, 2024 pm 02:00 PM
Adobe After Effects cs6 (Ae cs6) で言語を切り替える方法 Ae cs6 で中国語と英語を切り替える詳細な手順 - ZOL ダウンロード
May 09, 2024 pm 02:00 PM
1. まず、AMTLanguages フォルダーを見つけます。 AMTLanguages フォルダーにいくつかのドキュメントが見つかりました。簡体字中国語をインストールすると、zh_CN.txt テキスト ドキュメントが作成されます (テキストの内容は zh_CN)。英語でインストールした場合は、テキスト ドキュメント en_US.txt が作成されます (テキストの内容は en_US)。 3. したがって、中国語に切り替えたい場合は、AdobeAfterEffectsCCSupportFilesAMTLanguages パスの下に zh_CN.txt (テキストの内容: zh_CN) の新しいテキストドキュメントを作成する必要があります。 4. 逆に、英語に切り替えたい場合は、
 TikTokで動画を撮影するにはどうすればよいですか?ビデオ撮影時にマイクをオンにするにはどうすればよいですか?
May 09, 2024 pm 02:40 PM
TikTokで動画を撮影するにはどうすればよいですか?ビデオ撮影時にマイクをオンにするにはどうすればよいですか?
May 09, 2024 pm 02:40 PM
現在最も人気のあるショートビデオ プラットフォームの 1 つである Douyin のビデオの品質と効果は、ユーザーの視聴エクスペリエンスに直接影響します。では、TikTokで高品質のビデオを撮影するにはどうすればよいでしょうか? 1.Douyinでビデオを撮影するにはどうすればよいですか? 1. Douyin APPを開き、下部中央の「+」ボタンをクリックしてビデオ撮影ページに入ります。 2. Douyin は、通常撮影、スローモーション、ショートビデオなどのさまざまな撮影モードを提供します。ニーズに応じて適切な撮影モードを選択してください。 3. 撮影ページで、画面下部の「フィルター」ボタンをクリックしてさまざまなフィルター効果を選択し、ビデオをよりカスタマイズします。 4. 露出やコントラストなどのパラメータを調整する必要がある場合は、画面の左下隅にある「パラメータ」ボタンをクリックして設定できます。 5. 撮影中に、画面左側の をクリックします。
 総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
大規模言語モデル (LLM) を人間の価値観や意図に合わせるには、人間のフィードバックを学習して、それが有用で、正直で、無害であることを確認することが重要です。 LLM を調整するという点では、ヒューマン フィードバックに基づく強化学習 (RLHF) が効果的な方法です。 RLHF 法の結果は優れていますが、最適化にはいくつかの課題があります。これには、報酬モデルをトレーニングし、その報酬を最大化するためにポリシー モデルを最適化することが含まれます。最近、一部の研究者はより単純なオフライン アルゴリズムを研究しており、その 1 つが直接優先最適化 (DPO) です。 DPO は、RLHF の報酬関数をパラメータ化することで、選好データに基づいてポリシー モデルを直接学習するため、明示的な報酬モデルの必要性がなくなります。この方法は簡単で安定しています
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
 LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
上記と著者の個人的な理解: この論文は、自動運転アプリケーションにおける現在のマルチモーダル大規模言語モデル (MLLM) の主要な課題、つまり MLLM を 2D 理解から 3D 空間に拡張する問題の解決に特化しています。自動運転車 (AV) は 3D 環境について正確な決定を下す必要があるため、この拡張は特に重要です。 3D 空間の理解は、情報に基づいて意思決定を行い、将来の状態を予測し、環境と安全に対話する車両の能力に直接影響を与えるため、AV にとって重要です。現在のマルチモーダル大規模言語モデル (LLaVA-1.5 など) は、ビジュアル エンコーダーの解像度制限や LLM シーケンス長の制限により、低解像度の画像入力しか処理できないことがよくあります。ただし、自動運転アプリケーションには次の要件が必要です。
