

ポートレートタグシステム構築と応用実践

1. イメージタグシステム
Qunar は、事業開発プロセスごとに独立したイメージタグシステムを構築しました。会社が成長を続けるにつれて、各事業のポートレート ラベリング システムを統合する必要があります。技術的な観点から見ると、統合プロセスは比較的単純ですが、ビジネス レベルでの統合はより複雑です。各ラベルは異なるビジネスで異なる定義を持っているため、統合の難しさが増します。統合ラベル システムが企業全体の戦略により適切に機能するようにするには、各ラベルのロジックと一貫性を確保するために、綿密なキーワードの抽出と最適化が必要です。

1. ポートレート タグとは
ユーザー行動とは、ユーザーがポートレート タグで行うことを指します。ビジネス ログは、クリック、注文、検索動作など、サーバー側でユーザーによって生成されたデータを指します。ポートレートタグは、ルール統計とマイニングアルゴリズムを通じてユーザーの行動とビジネスデータを分析することによって取得されるユーザーの多次元データです。ユーザーの行動とビジネスデータを分析することで、ユーザーの好みやニーズをより深く理解し、よりパーソナライズされた正確なサービスをユーザーに提供できます。これらのユーザー ポートレート タグは、企業がターゲット ユーザー グループをより適切に特定し、ターゲットを絞ったマーケティング戦略を策定し、ユーザー エクスペリエンスを向上させるのに役立ちます。ユーザーの行動とビジネス データを詳細に分析することで、企業はユーザーの行動パターンをより深く理解し、より良い製品とサービスをユーザーに提供できるため、ユーザーの満足度とロイヤルティが向上します。
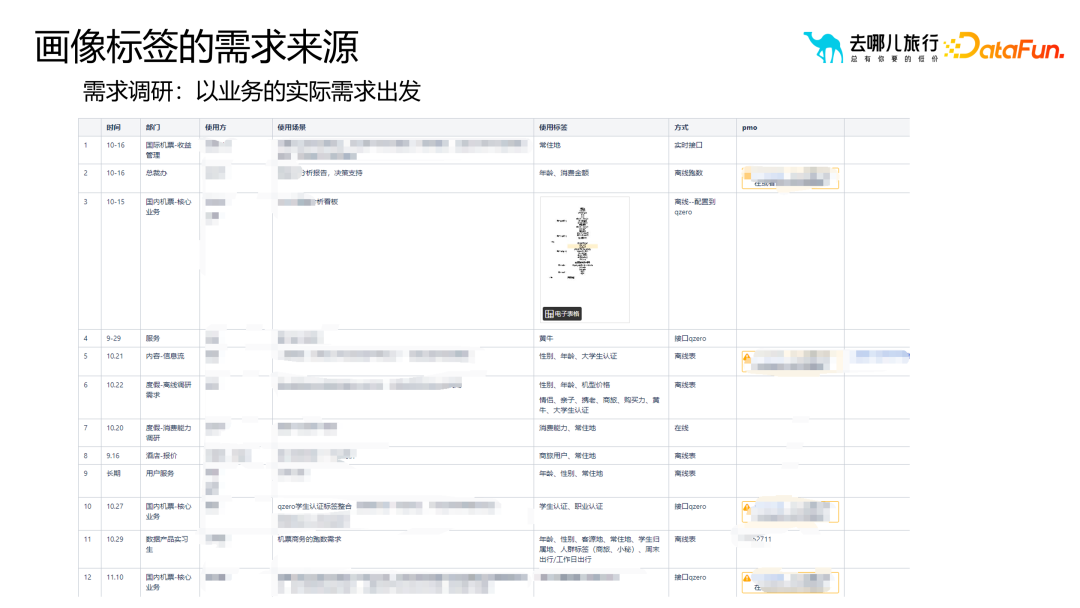
2. ポートレート タグの需要のソース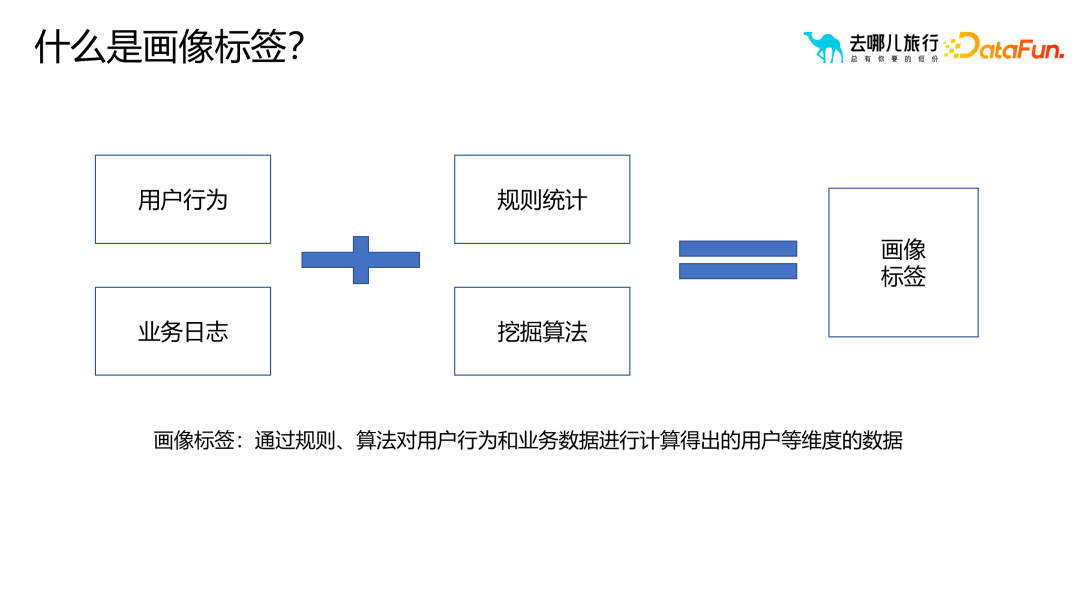
各事業部門が独自のポートレート タグ プラットフォームを構築する場合、目的が異なるため、ニーズも異なります。航空券ビジネスは通常マーケティングをターゲットにし、ホテルビジネスは通常サービスをターゲットとします。実際のビジネスニーズから始めて、企業経営陣、インターン、その他のさまざまなレベルの担当者を含むさまざまな部門とコミュニケーションを取り、徹底した需要調査を実施して、統合ラベルシステムがビジネスニーズをより適切に満たすことができるようにする必要があります。統合プロセス中、ユーザー ポートレート ラベルの要件は主に、マーケティング リスク コントロール、社内ビジネス分析アプリケーション、およびユーザーの説明の 3 つのカテゴリに分類されます。
マーケティング リスク コントロール: ユーザー マーケティング、パーソナライズされた推奨事項、正確な広告、ユーザー リスク コントロール。
- ビジネス分析: ビジネス最適化分析、多次元ビジネス指標の監視、および新しいビジネス製品設計に関するガイダンス。
- #ユーザーについて説明します: 単一ユーザーの定義、プラットフォーム ユーザーの位置付け、業界レポート。
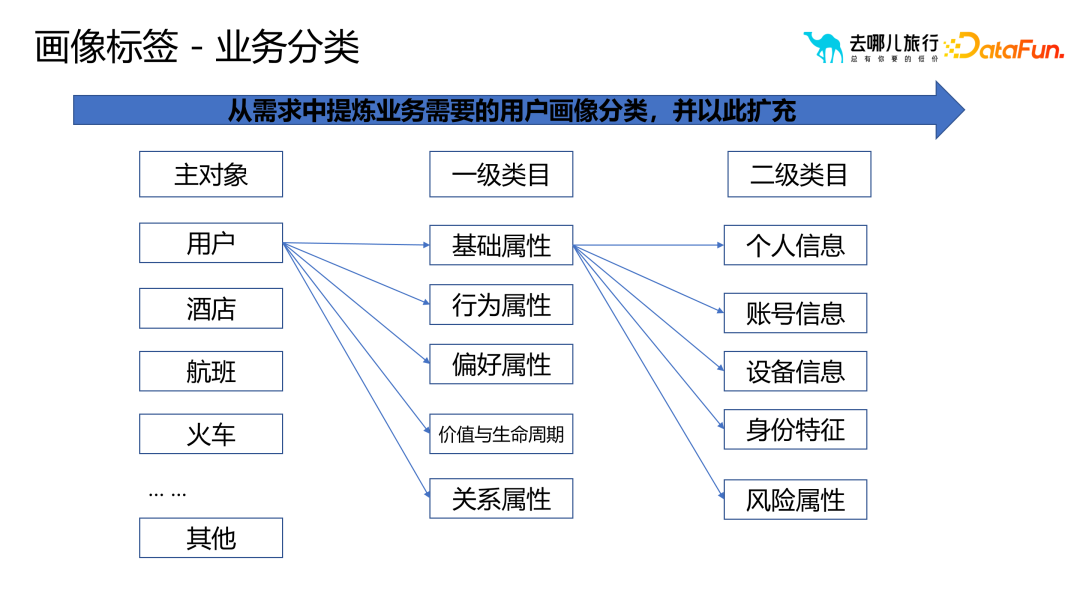
はポートレート タグから構成されますこのプロセスは、事業分類と技術分類に分かれています。
ビジネスプロセスを主な分類基準として、主に第1層、第2層のカテゴリーに基づいて、ユーザーニーズからビジネスに必要なユーザー像の分類を抽出し、継続します。を拡張し、改善します。
#さらに、さまざまな技術要件に応じて、ポートレート タグを生成、保存、呼び出しするための適切なテクノロジー スタックを選択する必要があります。
まず、どのテクノロジーを使用する必要があるかを決定するために、ポートレート タグの定義と目的を明確にする必要があります。次に、タグの更新サイクルとアクセス方法を考慮する必要があります。これにより、タグをオンラインで処理する必要があるかオフラインで処理する必要があるか、およびどのストレージ リソースを選択するかが決まります。最後に、これらの要素に基づいて、ポートレート ラベリング システムを実装し、システムのパフォーマンスと安定性を確保するために適切なテクノロジー スタックを選択できます。このような技術的な分類を通じて、ポートレート タグ システムの管理と維持を改善し、その拡張性と使いやすさを向上させることができます。
(1) 構築方法
- 統計クラス:SQL依存で完成します。
- ルール クラス: データ アナリスト、ビジネス アナリスト、プロダクト オペレーターなど、特定のビジネス バックグラウンドを持つ人々が、ビジネスの理解に基づいていくつかのルール クラスを構築する場合ラベルはビジネス理解の変化に基づいて変更されます。
- #モデル クラス: このタイプのラベルでは、アルゴリズム チームが複雑な計算を実行するか、サンプル データが必要です。一部の基本的なラベルとは異なり、モデル ラベルは精度に課題がある可能性があり、100% 正確であることはできません。場合によっては、取得するサンプルの数が非常に限られており、高レベルのラベル精度を維持することが困難になるためです。したがって、モデル クラス ラベルについては、精度と使いやすさを向上させるために他の方法やテクニックを見つける必要があるかもしれません。
(2) 更新サイクル
すでにリストされている時間ごと、週ごと、月ごとの更新サイクルに加えて、現在、ストリーミング更新に近い、リアルタイムのラベル更新も実装しています。
(3) アクセス方法
ポートレートラベリングプラットフォームは大量のデータとユーザーリクエストを処理する必要があるため、バックグラウンド技術スタックに基づいて適切なものを選択します。 アクセス方法。一部の大企業では、ユーザーとデータの数が非常に多いため、タグを効果的に保存および呼び出す方法を検討する必要があります。一部のタグはオフラインでのみ構築する必要がある場合がありますが、他のタグはオンラインで呼び出す必要がある場合があります。オフライン タグの場合は、Redis や HBase にデータを保存するなど、ストレージ コストが高くならないリソースを選択できます。オンラインタグでは、ユーザーのリクエストに迅速に対応し、安定したサービスを提供できるシステムが必要です。したがって、アクセス方法を選択するときは、システムのパフォーマンスと安定性を確保するために、実際の状況に基づいてトレードオフと選択を行う必要があります。
4. ポートレートラベルシステムの構築プロセス
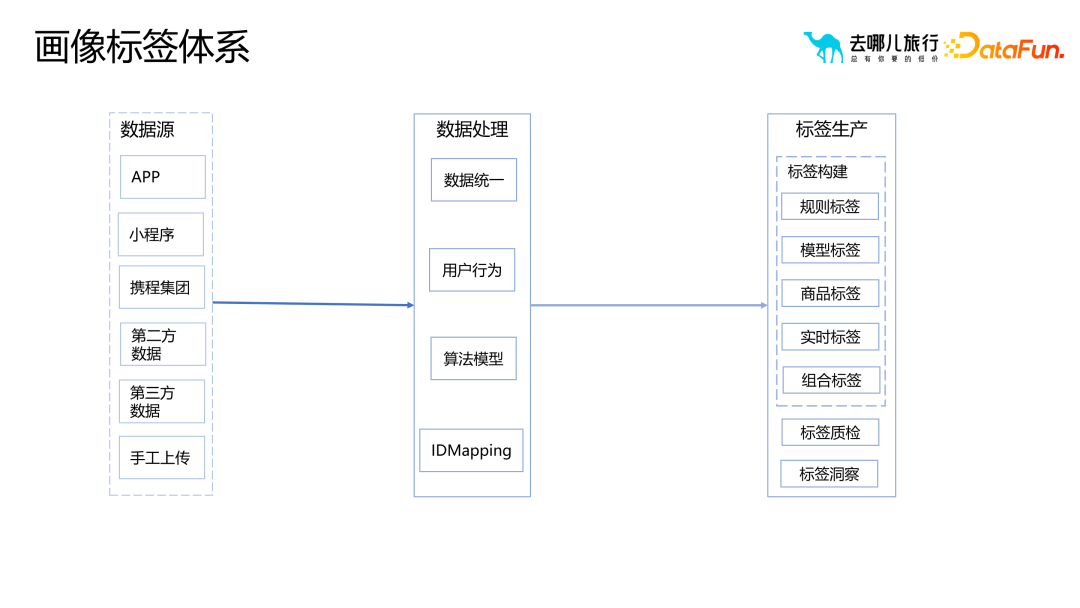
ポートレートの制作過程ラベルシステムでは、最終的にラベルを生成するには、さまざまなデータソースに対して一連の処理が必要です。その中でも、ID マッピングは重要なリンクです。 ID マッピングの目的は、特に初期段階の企業において、さまざまな登録方法により、同じユーザーに複数の ID が対応する可能性がある、異なる ID が同じユーザーを指すという問題を解決することです。たとえば、ユーザーはメールで登録した後に携帯電話番号をバインドまたは変更したり、ログインせずに携帯電話の使用を許可したりできます。これらの状況では、同じユーザーに複数の ID が対応する可能性があります。
この問題を解決するために、ID マッピングはマルチデバイスの関連付けを実現するタスクを担当します。さらに、ID マッピングはリスク管理の重要な基本ステップでもあります。 ID マッピングを通じて、さまざまなデバイスのユーザーをより適切に識別して関連付けることができるため、より適切なリスク制御とセキュリティ管理が可能になります。合理的な ID マッピングの設計と管理を通じて、ポートレート ラベリング システムの精度と信頼性を向上させながら、ユーザーのプライバシーとデータ セキュリティをより適切に保護できます。
2. ポートレート タグ プラットフォーム
ポートレート タグ プラットフォームとも呼ばれます似顔絵ラベル制作、データ分析、業務アプリケーション、効果分析などのサービスを含むCDPプラットフォームです。以下の図は、Qunar CDP プラットフォームの機能アーキテクチャを示しています。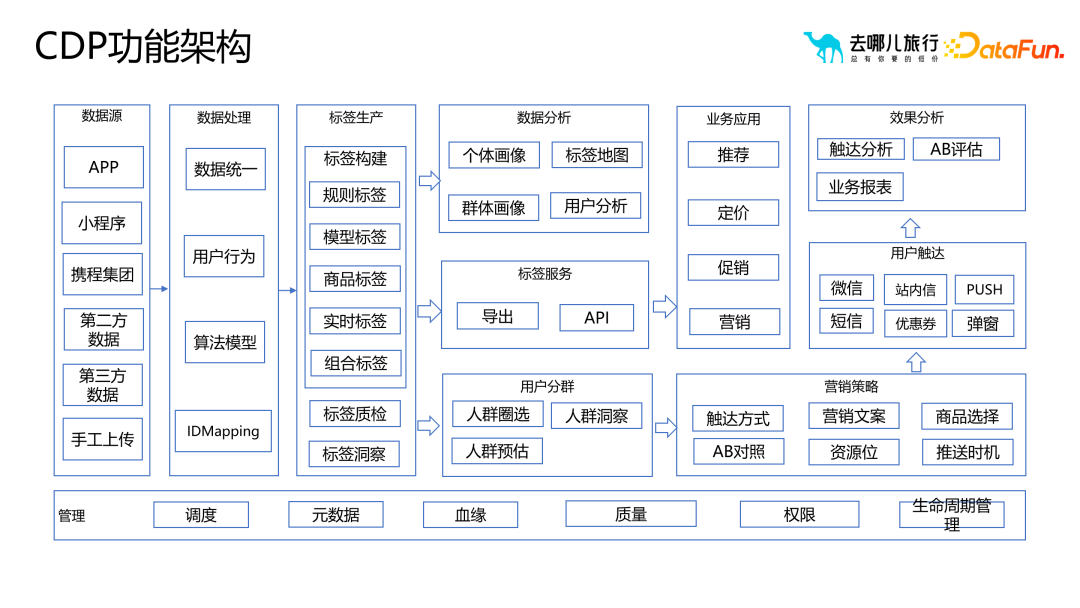

3. 一般的なアルゴリズム ポートレート タグ
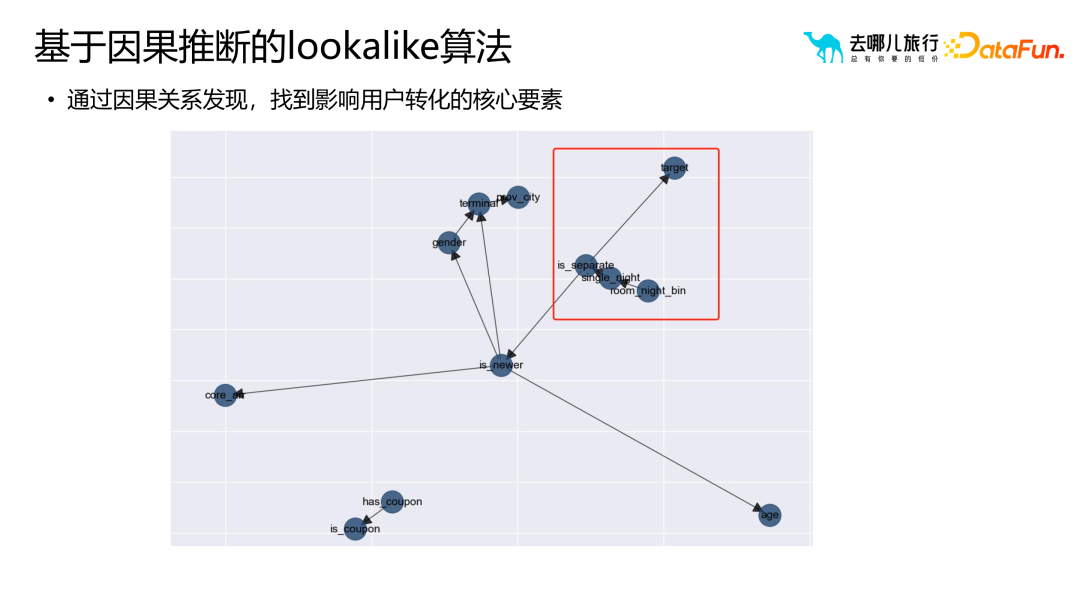
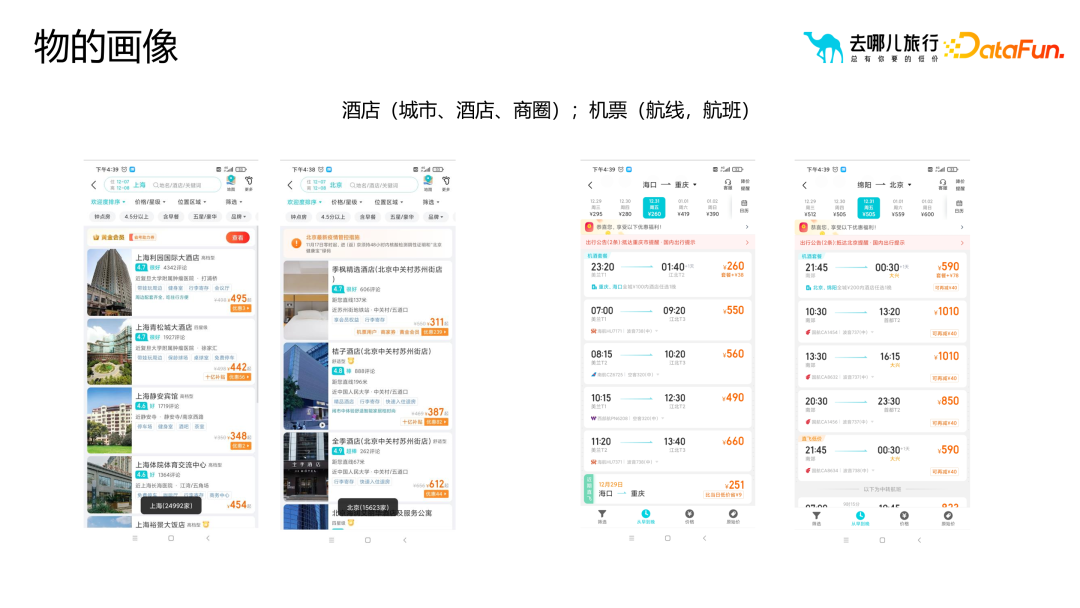
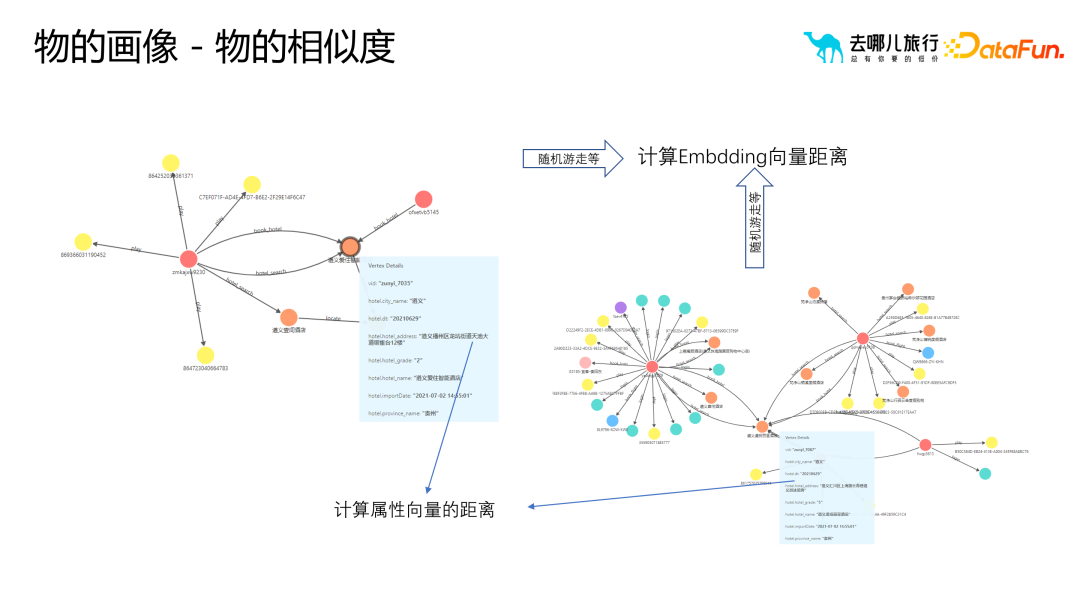
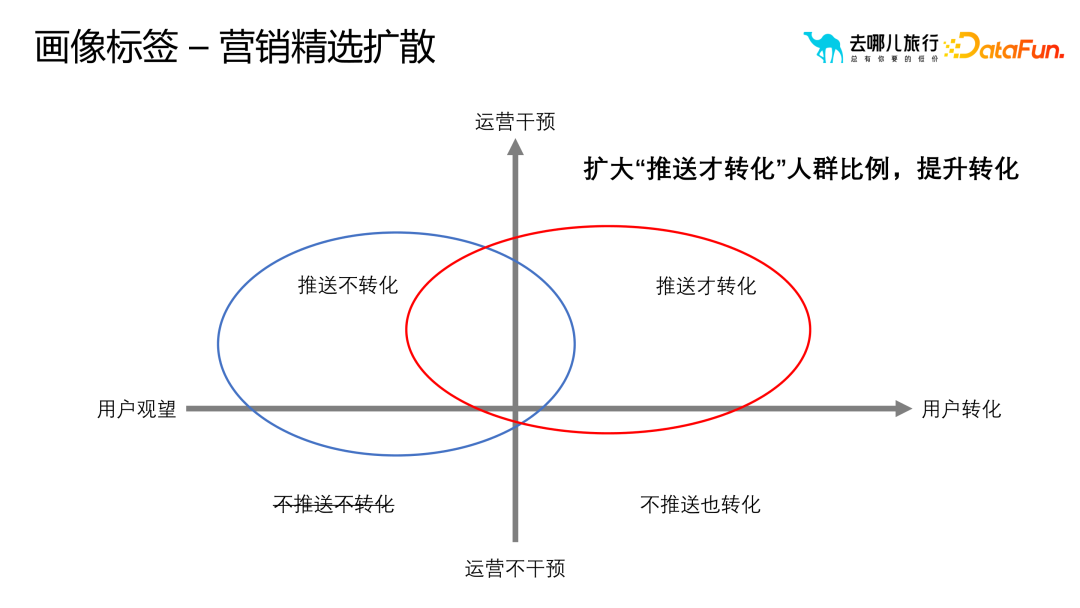
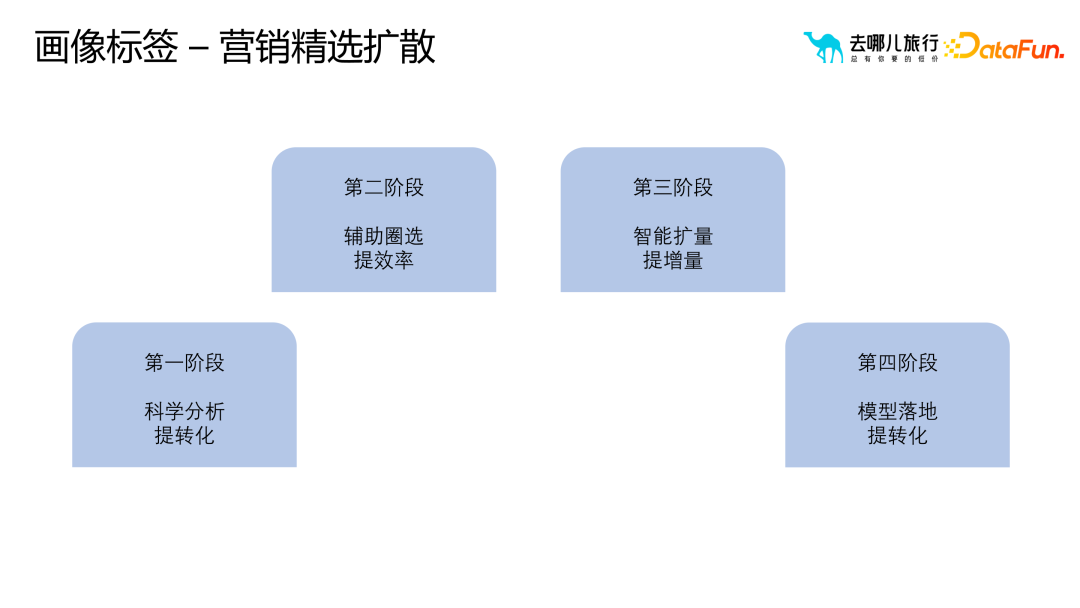
##1. 一般的なモデル クラス ラベルの一般的なアルゴリズム タイプ実際には、サンプルとテクノロジー スタックに基づいて、モデル クラス ラベルの一般的なアルゴリズムは次のように分類できます。いくつかのカテゴリ: (1) 分類アルゴリズム: ビジネス プロセスでのサークル選択とビジネス フィルタリングに予測クラス ラベルを使用するには、モデルのトレーニングと最適化に十分なサンプル データが必要であり、これにより予測精度が向上します。 。予測タグには注文支払い予測に限定されず、検索支払い予測、検索予測、詳細ページ予測なども含めることができます。 (2) レコメンデーションアルゴリズム: 並べ替えと優先順位付けに関連し、幅広い最先端の知識と技術スタックが必要です。推奨アルゴリズムの目的は、リコール セットから適切なホテルの部屋タイプをユーザーに推奨することです。たとえば、親子旅行シナリオの場合、推奨アルゴリズムは、ツインルームやスイートなどの適切なホテルの部屋タイプをユーザーに推奨できます。 (3) ナレッジ グラフ: グラフ データベース テクノロジを使用して、ユーザーとその周囲の関係をより適切に明らかにします。異常なユーザーを特定し、悪意のあるユーザーであるかどうかを判断するなど、リスク管理シナリオには多くのアプリケーションがあります。 (4) 因果推論: ユーザーへのテキスト メッセージやプッシュ メッセージの送信がマーケティング効果に及ぼす影響を説明するために例が使用されますが、これにはコストの問題が含まれます。 (5) グラフィックスと画像: グラフィックスと画像処理テクノロジを組み合わせて、グラフィックスと画像をマークします。これには画像のセグメンテーション、認識、その他のテクノロジーが含まれますが、多くの場合、ユーザー タグを介して画像のラベル付けに逆に適用されます。たとえば、不適切なコメントを投稿したユーザーのラベルが抽出され、グラフィック イメージのラベル付けアルゴリズムに適用され、ラベル付けの効率と精度が向上します。 (6) NLP ロボット (7) 類似マーケティング アルゴリズム: シード ユーザーを介した拡大マーケティングのためのアルゴリズム。 需要タイプに基づいてさまざまな分類方法があります: フィルタリングでポートレート タグのみに依存すると、次のような問題が発生する可能性があります。ニーズに合わないターゲットユーザーをいかに選別するかが難しい問題となっている。価値やアクティビティなどに基づく並べ替えなどの従来の方法では、選択したユーザーがターゲット ユーザー グループに最も類似していることを確認するのが困難です。ナレッジ グラフや頻繁に発生するパターンを通じて、ユーザー間の類似性を測定できます。この類似性は定量化可能で拡張可能です。関係レベルを通じて、アルゴリズムはターゲット ユーザーに類似したユーザー グループをより正確に見つけることができます。 従来の相関ルールやポートレートタグと比較して、因果推論はより深い質問を解決できます。アソシエーション ルールとポートレート ラベルは主に、「ビールを購入するユーザーはおむつも購入する可能性がある」などの相関関係の問題を解決しますが、なぜこの相関関係が存在するのかを説明することはできません。この相関関係は、異なる文化や市場では当てはまらない場合があります。したがって、履歴データとモデルによる因果推論を通じて、ユーザーの行動とコンバージョンに影響を与える主要な要因を見つけることができます。これらの重要な要素は関係の発見を通じて見つけることができ、これはユーザーの行動やビジネス プロセスをより深く理解するのに役立ちます。 たとえば、右上隅の赤い部分は、より多くのユーザーを拡大するために、ビジネスの理解を通じてビジネス プロセスをよりよく反映する部分をフィルタリングします。 オブジェクトのポートレート ポートレートを構築するプロセスでは、ホテルのポートレートに含まれる都市、ビジネス地区、ルート、フライトなどのオブジェクトの属性と特性に主に焦点を当てます。これらのプロパティは、オブジェクトをより正確に説明および理解するのに役立ち、ポートレートに豊富なコンテンツを提供します。 #ユーザー ポートレートと比較して、オブジェクト ポートレートはオブジェクト間の類似性を強調します。実際には、通常、オブジェクトの類似性を推奨やランキングなどの操作に使用します。オブジェクト間の類似性を測定するには、属性ベクトルや埋め込みなどのさまざまな方法を使用できます。これらのメソッドはオブジェクトをベクトルとして表現し、これらのベクトルを使用して類似度の計算を実行できます。オブジェクト ポートレートを構築するプロセスはユーザー ポートレートを構築するプロセスと似ていますが、実際のアプリケーションでは、ビジネス ニーズとシナリオに基づいて適切な調整と最適化を行う必要があることに注意してください。同時に、オブジェクト間の関係と階層構造を詳細に分析して、オブジェクトのポートレートがビジネス ニーズを正確に反映していることを確認することも必要です。 さらに、オブジェクトのイメージを構築するプロセスでは、いくつかの重要な問題にも注意する必要があります。 (1) 類似性は類似性を意味しません。たとえば、埋め込み手法を使用する場合、価値の高いユーザー グループが 5 つ星ホテルを検索している場合、これらの 5 つ星ホテル間の相関は強い可能性があります。ただし、一部のビジネス シナリオでは、この相関関係が当てはまらない場合があります。したがって、特定のビジネス シナリオに基づいてオブジェクトの類似性を慎重に検討する必要があります。 (2) コールドスタートの問題。たとえば、ホテルのプロファイリングでは、新しいホテルがオンラインになったときに、ユーザーの行動データが不足している可能性があります。この問題を解決するには、属性距離を使用して大次元のラベル属性を抽出し、使いやすいポートレート ラベルを構築し、このラベルを使用して類似度の計算を実行します。 (3) 解釈可能性 ##4. ポートレート タグの適用シナリオ #ポートレートタグはマーケティングの選択と普及のプロセスにおいて重要な役割を果たします。ポートレートタグを合理的に使用することで、オペレーターは、選択したユーザーグループをより詳細に分析およびスクリーニングすることができ、最初に選択したユーザーグループが大きすぎる、または小さすぎる、またはマーケティング効果をさらに拡大または最適化する必要があると感じた場合に、より良いマーケティング結果を達成するために、ポートレートタグを通じて拡散または再選択することができます。 しかし、ポートレートタグを選択して広める際に最も一般的な問題は、ユーザーコンバージョンと運用介入の 4 つの象限です。これら 4 つの象限はそれぞれ、さまざまなユーザー コンバージョン状態と運用介入戦略を表しており、さまざまな状況に対してさまざまな対応が必要です。たとえば、コンバージョンが高く介入が少ないユーザーに対しては現状を維持する戦略を採用し、コンバージョンが低く介入が少ないユーザーに対してはコンバージョンを促進する戦略を採用することができます。 ポートレート タグの適用プロセスにおけるマーケティングの選択と普及の 4 つの段階は次のとおりです。 科学的分析: ユーザー データを深く掘り下げ、ターゲット グループを正確に特定します。コンバージョン効果を向上させるため。 補助サークルの選択: タグを使用してターゲット ユーザーを効率的にフィルタリングし、マーケティング活動の適切性と効率を向上させます。 インテリジェントな拡張: アルゴリズムとモデルに基づいて、ユーザー グループをインテリジェントに分類および拡張し、マーケティング対象範囲を拡大します。 モデルの実装: 実際のマーケティング活動と組み合わせて、ポートレート タグと戦略を最適化し、最高のマーケティング結果を達成します。
A1: ユーザー行動データは主に、クリックなどのアプリ側でのユーザーのインタラクティブな行動を記録します。これらのデータは主にユーザーのインタラクションプロセスを反映します。ビジネスデータには、エージェントの接続プロセスや物流情報など、バックグラウンドで処理されるさまざまな情報が含まれます。これらのデータはユーザーには見えませんが、ビジネスプロセス全体を理解し、ユーザーエクスペリエンスを向上させるためにも重要です。実際の運用では、ユーザーの行動とビジネスプロセスをよりよく分析して理解するために、これらのデータをポートレートタグシステムに組み込む必要があります。たとえば、電子商取引プラットフォームの場合、一部のデータはユーザーに関係しない可能性がありますが、一部のデータはユーザーエクスペリエンスやビジネスプロセスに関係するため、適切な審査と処理が必要です。 A2: ストリーミング タグは、Flink などのツールを使用するなど、ストリーミング コンピューティングを通じて実装できます。ユーザーは、定義されたデータをドラッグ アンド ドロップして、ストリーミング計算を通じてラベルを計算できます。同時に、カスタマイズされた計算用の Python コードまたは SQL コードをアップロードすることもできます。さらに、Spark やその他の方法でもサポートできます。ストリーミング タグでは、さまざまなニーズを満たすために、計算の量と時間枠を制限する必要があります。 ストリーミング タグは、複雑なタグ ルールをサポートできます。ユーザーは、Python コードまたは SQL コードをアップロードすることで、より複雑なラベル計算を実装できます。 ストリーミング タグは、データ開発とビジュアル構成の 2 つの方法で実装できます。 Qunar プラットフォームでは、ユーザーは定義されたデータをドラッグ アンド ドロップしてストリーミング コンピューティングを通じてラベルを計算したり、カスタマイズされた計算のために Python コードまたは SQL コードをアップロードしたりできます。 A3: リアルタイム タグとは、ユーザーの行動やビジネス イベントが発生したときにリアルタイムで計算されて適用されるタグを指します。たとえば、ユーザーがフロントエンド インターフェイスで苦情を送信すると、システムはユーザーの要求と注文の問題をリアルタイムで分析し、対応するリアルタイム ラベルでユーザーにラベルを付けます。この種のリアルタイムのラベル付けは、ユーザーのニーズと問題を迅速に反映し、タイムリーな処理と最適化を実現します。リアルタイム タグの定義は企業によって異なります。Qunar の場合、3 秒以内はリアルタイムとみなされますが、数時間は非リアルタイム シナリオとみなされます。 A4:モバイル インターネットの普及に伴い、携帯電話番号をユーザーの一意の識別子として使用する企業が増えています。ワンクリック ログインは業界で一般的になり、ユーザーは簡単にログインしてアプリケーションを使用できるようになりました。 Qunar のようなプラットフォームでは、一意のユーザー ID として携帯電話番号も使用します。ほとんどの場合、携帯電話番号はユーザーの一意の識別子として扱われます。ただし、いくつかの特殊なケースでは、ユーザーが携帯電話番号を変更するシナリオも考慮し、それに応じて処理します。また、ユーザーの管理と識別をより適切に行うため、同じ携帯電話番号で 2 台のデバイスにログインしている場合、ユーザーのデバイスの保持状況を一連の判定によって判断します。ユーザーが一時的にデバイスにログインした場合はビジターとみなされ、ユーザーがデバイスを長期間保持した場合はホルダーとみなされます。 #A5: 最も一般的なのは製品の価格設定です。製品の価格をパーソナライズするには、製品タグを使用する必要があります。これらのラベルは、内部および外部要因の特定の数値に基づいて計算されます。内部要因が適切に整理されていない場合、外部要因の影響が誇張される可能性があります。 は総当たり解法と同じように理解できますが、あらゆる要素を入れて試してみて、各要素がどれだけ影響を与えるかを見て、各要素に相関関係があるのか因果関係があるのかを判断します。 Q7: タグのライフサイクルを管理するにはどうすればよいですか? A8: 中小企業ではトラフィックが不十分な可能性があります。最小サンプル サイズを達成したい場合、運用レベルでは達成できないため、ある程度のトラフィックが必要です。最小サンプルサイズに達していない場合、実験の効果を迅速かつ大まかに推測できます。 #A9: すべての企業が異なることを示してください。ストレージの観点から見ると、Qunar には複数のストレージ方法があります。主に高速リアルタイム応答のために、一部のデータの冗長ストレージを許容できます。つまり、タグにアクセスするときは、アクセスに時間がかからない 1 つの方法を使用するよう最善を尽くします。 A10: 実際、Qunar での私の現在の業務を通じて、大規模なモデルがアルゴリズムのラベル付けに広く使用されています。まず、最も単純な例です。ユーザーのポートレートを作成するときに、POI ランドマーク データに遭遇することがよくあります。ランドマーク データは、いくつかのドキュメントから抽出されます。おそらく、これが使用される大規模なモデルです。この場所の精度は正直です。いくつかのサイトよりもはるかに優れています。過去に自分たちで作ったモデル。そして、ナレッジ グラフを構築するとき、エンティティの曖昧さの解消、エンティティのマージなどに遭遇することになります。 A11: いいえ、この推奨事項はエンジニアを推奨するものですが、推奨アルゴリズムはポートレート エンジニアの結果を使用する必要があります。ポートレート エンジニアは、品質と品質を明確に区別する必要があります。ポートレートラベルとアプリケーションシナリオの説明であり、レコメンデーションソートエンジニアがより使いやすくなるように説明されています。 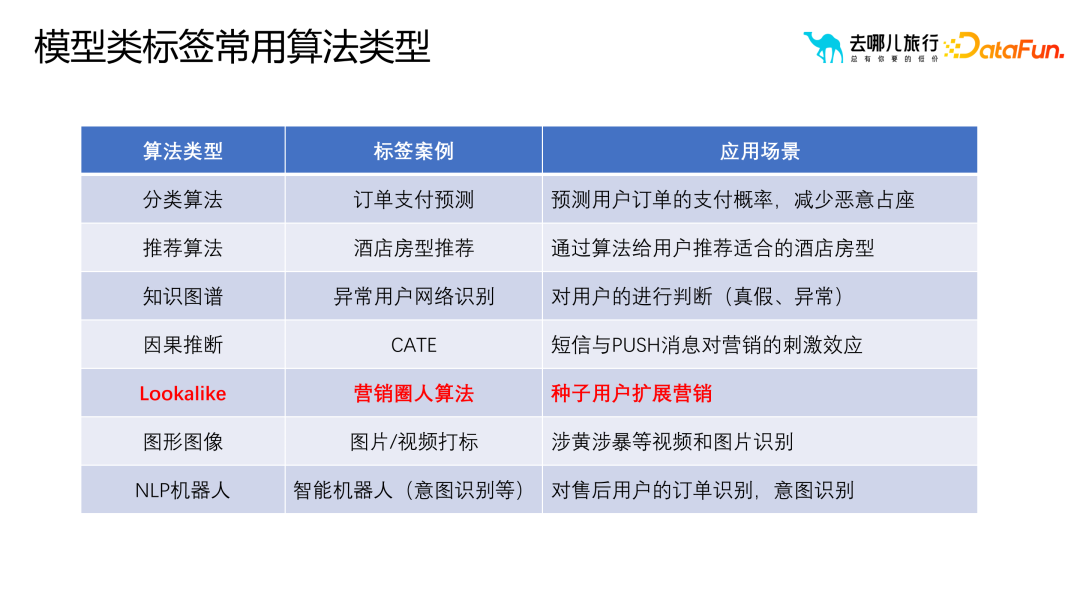
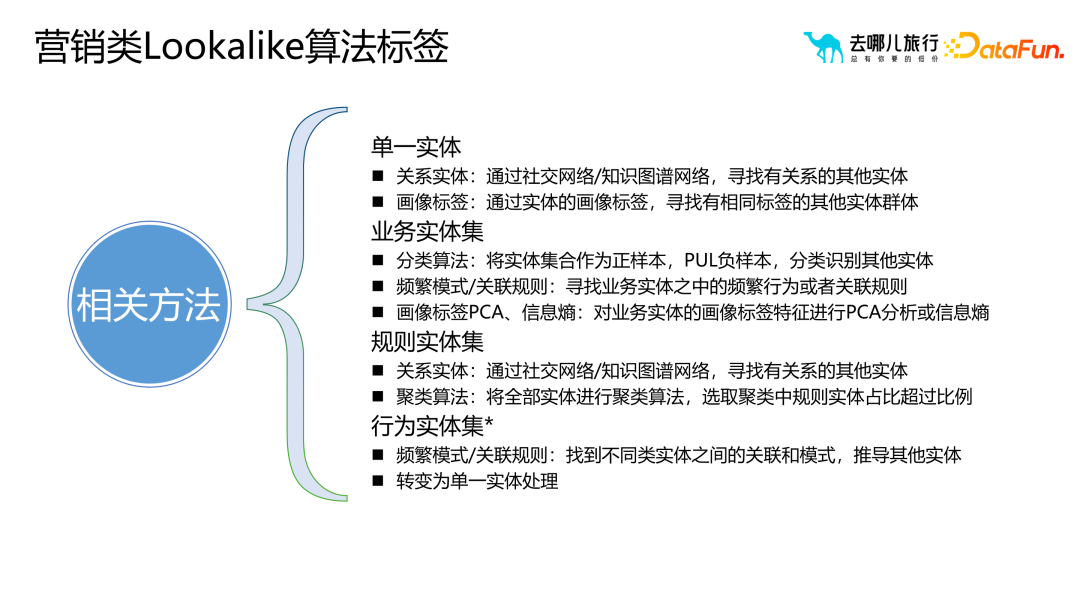
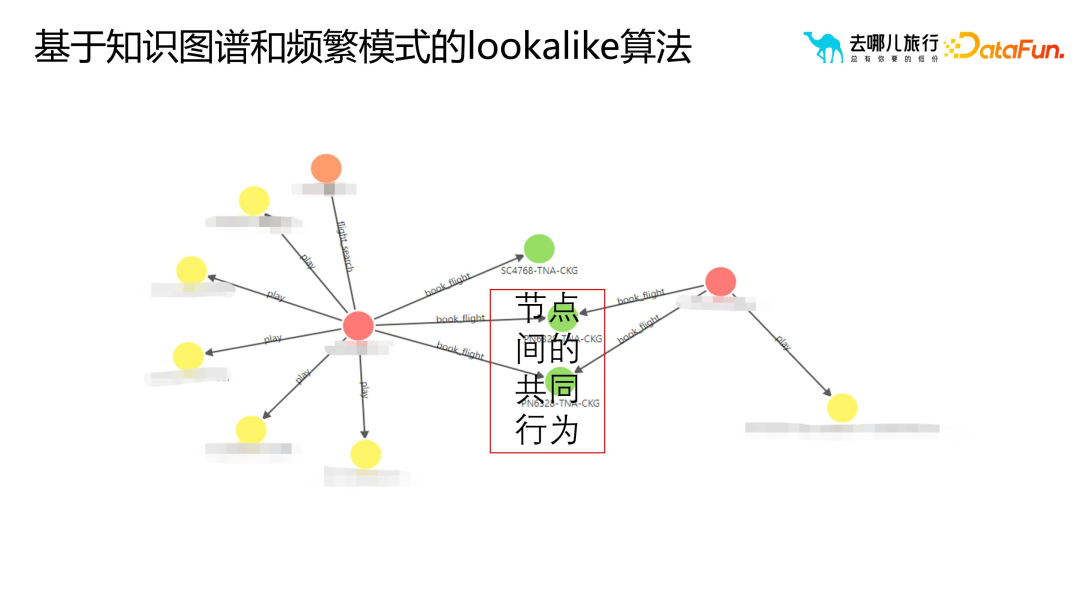
2. ナレッジ グラフと頻繁なパターンに基づく類似アルゴリズム
3. 因果推論に基づく類似アルゴリズム
4. オブジェクトのポートレート


アプリケーション 1: マーケティング群衆の選択と拡散
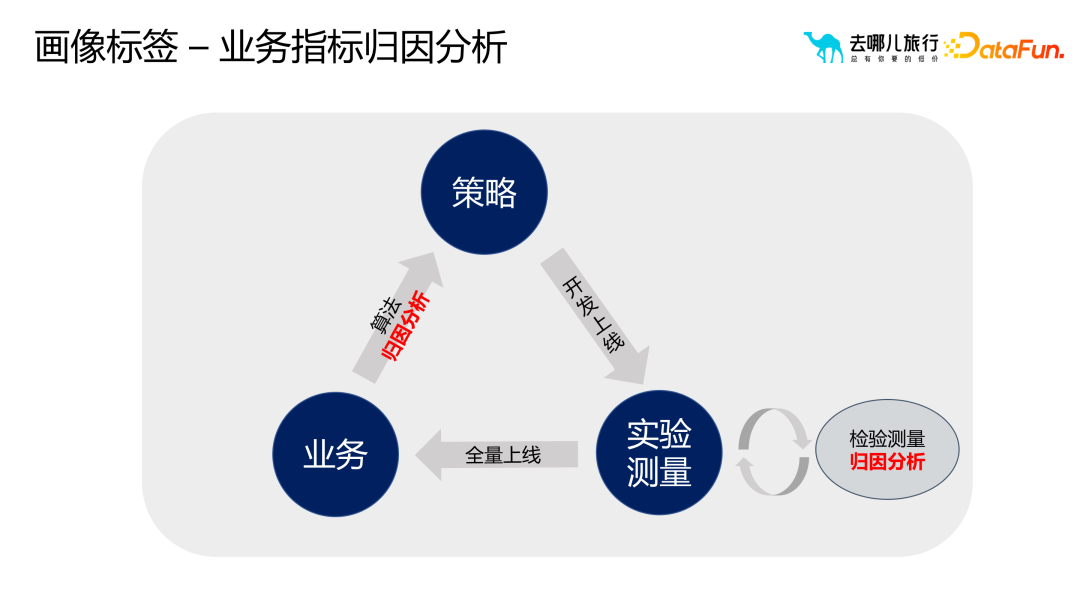
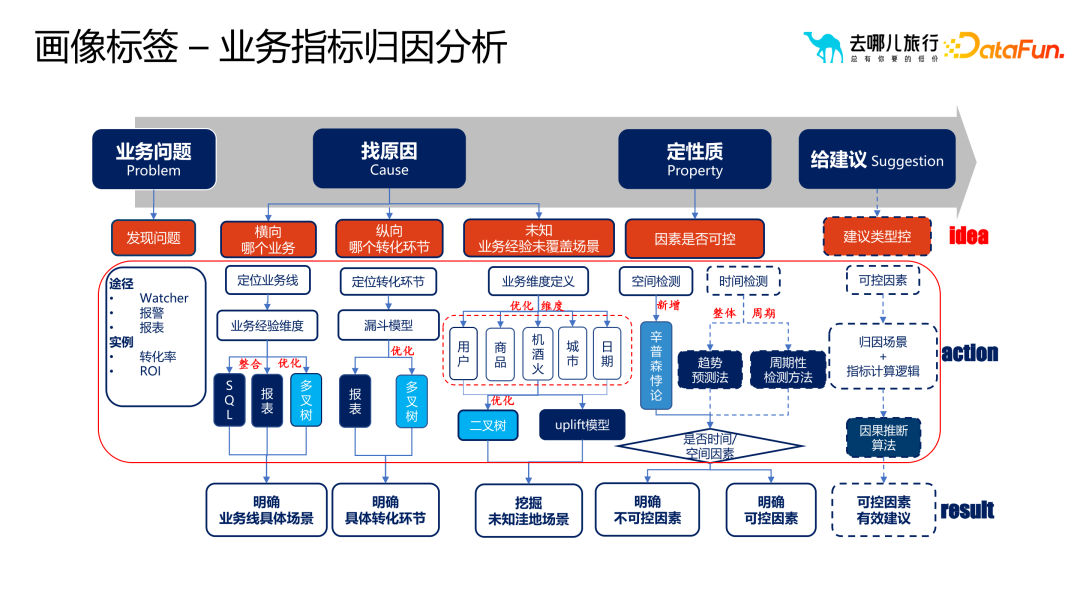
#アプリケーション 2: ビジネス指標の属性分析
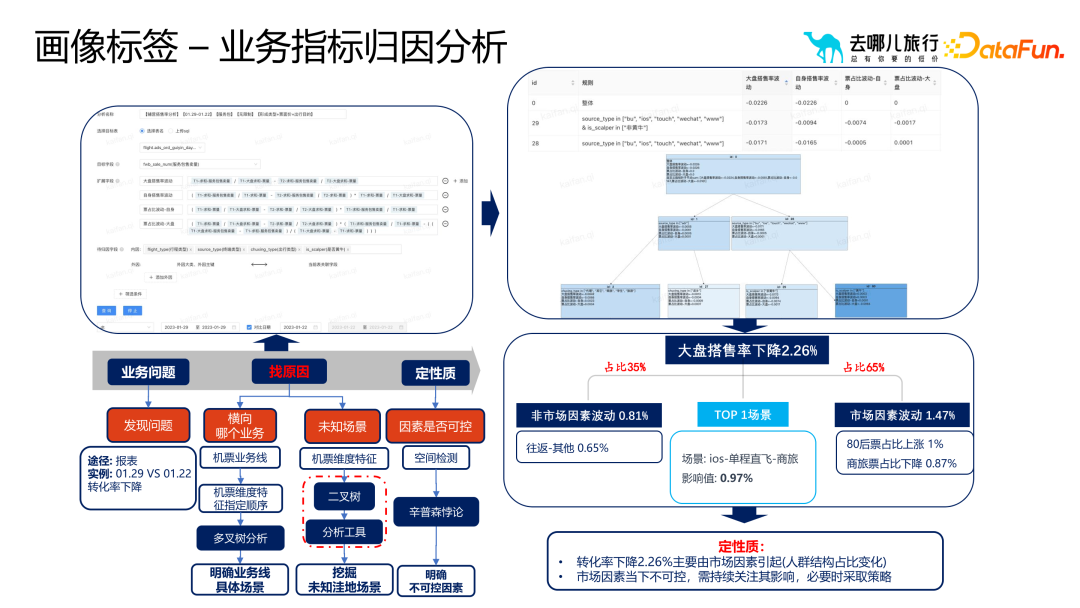
アプリケーション 3: AB 実験パフォーマンス分析

5. 質疑応答セッション
Q1: ユーザーの行動と業務ログの違いは何ですか?
Q2: ストリーミングのラベル付けは現在どのように行われていますか?より複雑なタグ ルールをサポートできますか?データから開発されていますか、それとも視覚的に構成されていますか?
Q3: リアルタイムタグとは何ですか?
Q4: ID マッピングは、複数の携帯電話番号/デバイス番号を一意の ID に識別しますか? それとも、各ユーザーが一意の ID を持つことを許可しますか?たとえば、ある携帯電話番号が 2 つのデバイスにログインしており、そのうちの 1 つのデバイスが別の携帯電話番号にログインしています。それは 1 つだけですか、それとも 3 つですか?
Q5: 製品ラベルの適用シナリオは何ですか?
A6: リアルタイム タグが構築された後、開発レベルを通じて基本的な統計を通じて取得できるいくつかのリアルタイム タグを使い果たすよう最善を尽くしました。ルールやモデルなどのリアルタイムタグについては、カスタマイズして開発する必要があります。
A7: 設立当初は使い捨てのタグがいくつかありますが、使用後は使用できなくなります。
Q8: AB 実験の最小サンプル サイズを決定するために、いくつかの統計的手法を使用できますか? AB 実験には標準的な計算プロセスがありますが、統計的に有意な効果を達成するために必要なおおよそのサンプル サイズを知ることができますか?
Q9: ユーザー キャリバー ポートレートのキャリバー タイプはどのように保存および表示されますか?ユーザーのポートレートには、単一のタグに加えて、ユーザーの好みの観点を形成するための複数のタグもあります。これら 2 種類のタグをより適切に保存するにはどうすればよいでしょうか?
Q10: ソリューション ラベルの構築におけるモデルの応用は何ですか?
Q11: プロファイリング アルゴリズム エンジニアもランキングの推奨事項を実装する必要がありますか?
以上がポートレートタグシステム構築と応用実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7737
7737
 15
1643
14
1397
52
1290
25
1233
29
15
1643
14
1397
52
1290
25
1233
29

 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の最下層はマージ ソートを使用し、その複雑さは O(nlogn) で、クイック ソート、ヒープ ソート、安定したソートなど、さまざまなソート アルゴリズムの選択肢を提供します。
 人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能 (AI) と法執行機関の融合により、犯罪の予防と検出の新たな可能性が開かれます。人工知能の予測機能は、犯罪行為を予測するためにCrimeGPT (犯罪予測技術) などのシステムで広く使用されています。この記事では、犯罪予測における人工知能の可能性、その現在の応用、人工知能が直面する課題、およびこの技術の倫理的影響について考察します。人工知能と犯罪予測: 基本 CrimeGPT は、機械学習アルゴリズムを使用して大規模なデータセットを分析し、犯罪がいつどこで発生する可能性があるかを予測できるパターンを特定します。これらのデータセットには、過去の犯罪統計、人口統計情報、経済指標、気象パターンなどが含まれます。人間のアナリストが見逃す可能性のある傾向を特定することで、人工知能は法執行機関に力を与えることができます
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 Jiuzhang Yunji DataCanvas マルチモーダル大規模モデル プラットフォームの実践と考察
Oct 20, 2023 am 08:45 AM
Jiuzhang Yunji DataCanvas マルチモーダル大規模モデル プラットフォームの実践と考察
Oct 20, 2023 am 08:45 AM
1. マルチモーダル大型モデルの発展の歴史 上の写真は、1956 年に米国のダートマス大学で開催された最初の人工知能ワークショップです。このカンファレンスが人工知能開発の始まりとも考えられています。記号論理学の先駆者たち(前列中央の神経生物学者ピーター・ミルナーを除く)。しかし、この記号論理理論は長い間実現できず、1980 年代と 1990 年代に最初の AI の冬の到来さえもたらしました。最近の大規模な言語モデルが実装されて初めて、ニューラル ネットワークが実際にこの論理的思考を担っていることがわかりました。神経生物学者ピーター ミルナーの研究は、その後の人工ニューラル ネットワークの開発に影響を与えました。彼が参加に招待されたのはこのためです。このプロジェクトでは。
 58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
1. 58 Portraits プラットフォーム構築の背景 まず、58 Portraits プラットフォーム構築の背景についてお話ししたいと思います。 1. 従来のプロファイリング プラットフォームの従来の考え方ではもはや十分ではありません。ユーザー プロファイリング プラットフォームを構築するには、複数のビジネス分野からのデータを統合して、ユーザーの行動や関心を理解するためのデータ マイニングも必要です。最後に、ユーザー プロファイル データを効率的に保存、クエリ、共有し、プロファイル サービスを提供するためのデータ プラットフォーム機能も必要です。自社構築のビジネス プロファイリング プラットフォームとミドルオフィス プロファイリング プラットフォームの主な違いは、自社構築のプロファイリング プラットフォームは単一のビジネス ラインにサービスを提供し、オンデマンドでカスタマイズできることです。ミッドオフィス プラットフォームは複数のビジネス ラインにサービスを提供し、複雑な機能を備えていることです。モデリングを提供し、より一般的な機能を提供します。 2.58 中間プラットフォームのポートレート構築の背景のユーザーのポートレート 58
 SOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。
Mar 14, 2024 pm 11:50 PM
SOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。
Mar 14, 2024 pm 11:50 PM
上記と著者の個人的な理解は、自動運転システムにおいて、認識タスクは自動運転システム全体の重要な要素であるということです。認識タスクの主な目的は、自動運転車が道路を走行する車両、路側の歩行者、運転中に遭遇する障害物、道路上の交通標識などの周囲の環境要素を理解して認識できるようにすることで、それによって下流のシステムを支援できるようにすることです。モジュール 正しく合理的な決定と行動を行います。自動運転機能を備えた車両には、通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなど、さまざまな種類の情報収集センサーが装備されており、自動運転車が正確に認識し、認識できるようにします。周囲の環境要素を理解することで、自動運転車が自動運転中に正しい判断を下せるようになります。頭
